「Pythonにおける顧客セグメント分析:実践的なアプローチ」
「Pythonを使った顧客セグメント分析:実践的なアプローチ」
顧客セグメンテーションは、企業がマーケティング活動をカスタマイズし、顧客満足度を向上させるのに役立ちます。 ここではその方法をご説明します。
顧客セグメンテーションの機能では、共有の特徴や行動に基づいて顧客ベースを明確なグループやセグメントに分割することが含まれます。 各セグメントのニーズと好みを理解することにより、企業はよりパーソナライズされた効果的なマーケティングキャンペーンを提供し、顧客の維持と収益の向上を図ることができます。
このチュートリアルでは、 RFM(Recency、Frequency、Monetary)分析 と K-Meansクラスタリング を組み合わせてPythonで顧客セグメンテーションを探求します。 RFM分析は顧客行動を評価するための構造化されたフレームワークを提供し、K-meansクラスタリングはデータ駆動型のアプローチによって顧客を意味のあるセグメントにグループ化します。 このチュートリアルでは、小売業界の実データセットで作業します:UCIマシンラーニングリポジトリの オンライン小売データセット。
- 「分類メトリックの理解:モデルの精度評価ガイド」
- ソフトウェア開発のパラダイムシフト:GPTConsoleの人工知能AIエージェントが新たな地平を開く
- 「Dockerが「Docker AI」を発表:コンテキスト認識自動化が開発者の生産性に革新をもたらす」
データの前処理からクラスタ分析、視覚化まで、各ステップをコードによって進めていきましょう。 では、始めましょう!
私たちのアプローチ: RFM分析とK-Meansクラスタリング
まず、目標を述べて始めましょう:このデータセットにRFM分析とK-Meansクラスタリングを適用することで、顧客の行動と好みに関する洞察を得たいと思います。
RFM分析は、顧客行動を数量化するためのシンプルでパワフルな方法です。 それは顧客を3つのキーディメンションに基づいて評価します:
- 最新性(R) :特定の顧客が最近にどのくらいの頻度で購入したか?
- 頻度(F) :彼らはどのくらいの頻度で購入しますか?
- 金銭価値(M) :彼らはどれくらいの金額を使いますか?
データセット内の情報を使用して、最新性、頻度、および金銭価値を計算します。 次に、これらの値を通常使用されるRFMスコアのスケール(1-5)にマッピングします。
ご希望の場合、これらのRFMスコアを使用してさらに探索や分析を行うことができます。 ただし、似たようなRFM特性を持つ顧客セグメントを特定しようとします。 そして、これには似たようなデータポイントをクラスタにグループ化する無指導学習アルゴリズムであるK-Meansクラスタリングを使用します。
では、コーディングを始めましょう!
ステップ1–必要なライブラリとモジュールをインポートする
まず、必要なライブラリと必要に応じて特定のモジュールをインポートしましょう:
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansデータの探索と可視化にはpandasとmatplotlibが必要ですし、K-Meansクラスタリングを実行するためにscikit-learnのクラスタモジュールからのKMeansクラスも必要です。
ステップ2 – データセットの読み込み
前述のように、オンライン小売データセットを使用します。 このデータセットには顧客の記録が含まれており、購入日、数量、価格、および顧客IDなどのトランザクション情報が含まれています。
URLから元のExcelファイルにあるデータをpandasのデータフレームに読み込みましょう。
# UCIリポジトリからデータセットを読み込むurl = "https://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"data = pd.read_excel(url)または、 データセットをダウンロード し、Excelファイルをpandasのデータフレームに読み込むこともできます。
ステップ3 – データセットの探索とクリーニング
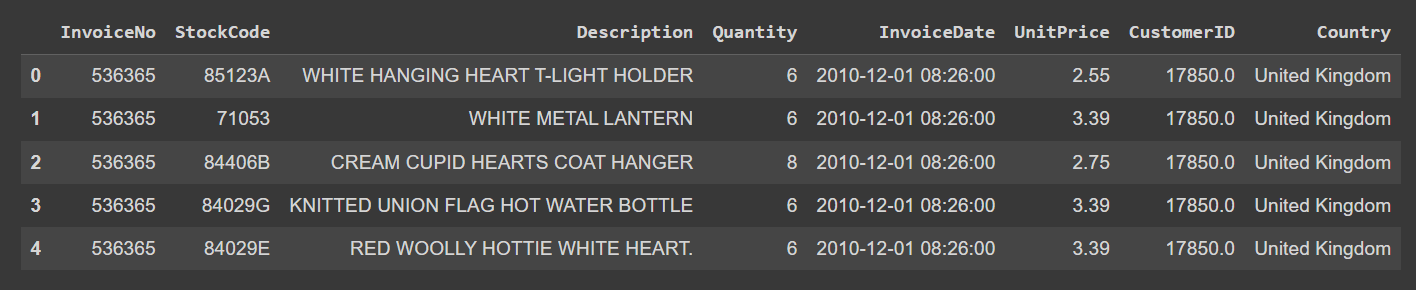
さあ、データセットの探索を始めましょう。最初の数行を見てみましょう:
data.head()
次に、データフレーム上でdescribe()メソッドを呼び出して、数値的な特徴をより詳しく理解します:
data.describe()
現在のデータセットの”CustomerID”列が浮動小数点値であることがわかります。データをクリーンアップする際に、整数にキャストします: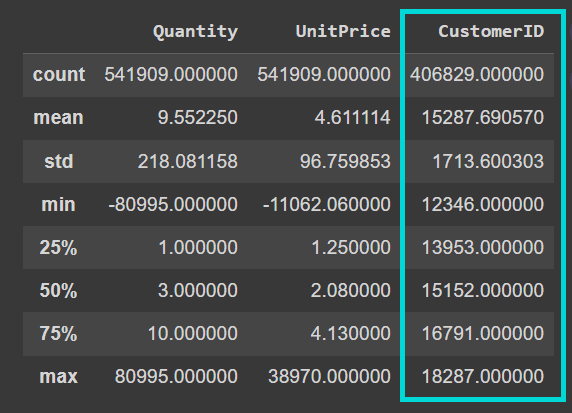
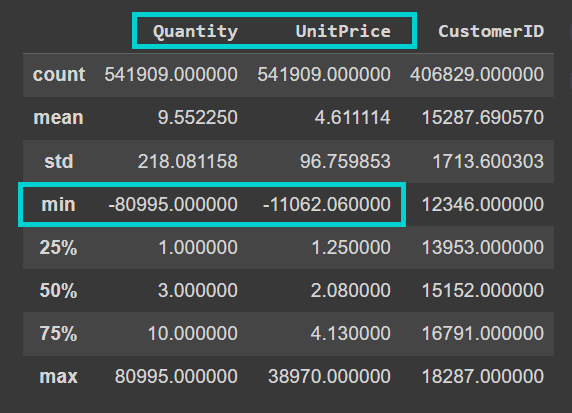
また、データセットにはかなりのノイズがあることにも注意してください。”Quantity”および”UnitPrice”列には負の値が含まれています:
それでは、列とデータ型を詳しく見てみましょう:
data.info()
データセットには541K以上のレコードがあり、”Description”および”CustomerID”列に欠損値が含まれていることがわかります: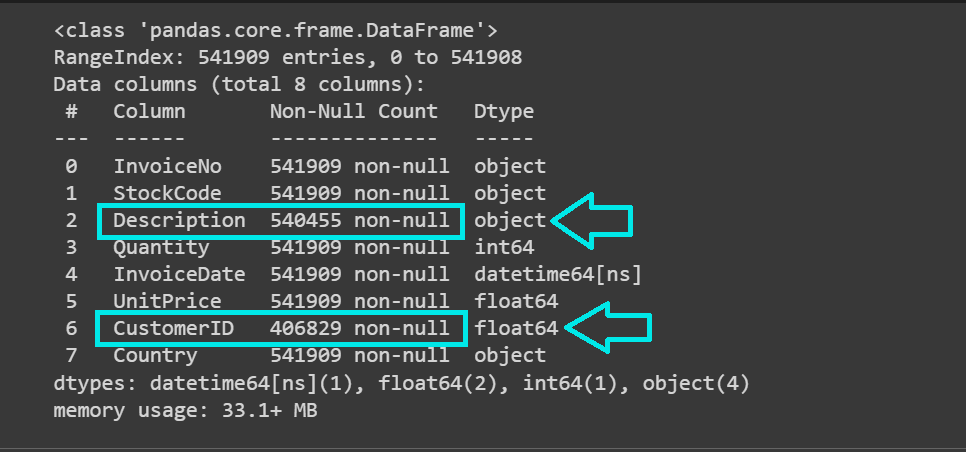 各列の欠損値の数を調べましょう:
各列の欠損値の数を調べましょう:
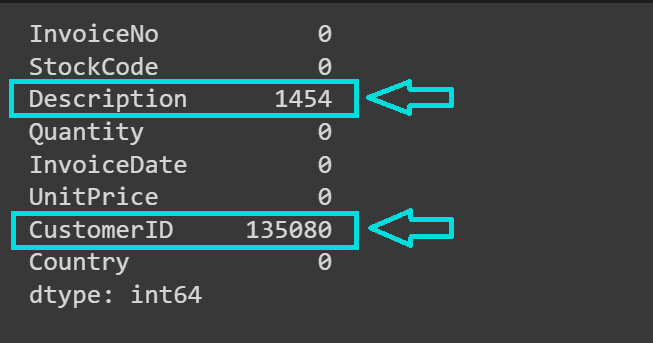
# 各列の欠損値をチェックmissing_values = data.isnull().sum()print(missing_values)
予想通り、”CustomerID”および”Description”の列には欠損値が含まれています:
分析では、”Description”列に含まれる製品の説明は必要ありませんが、次の分析ステップで”CustomerID”が必要です。なので、”CustomerID”の欠損値を持つレコードを削除しましょう:
# 欠損値を持つCustomerIDの行を削除data.dropna(subset=['CustomerID'], inplace=True)
また、「Quantity」と「UnitPrice」の値は厳密に非負であるべきです。しかし、負の値が含まれています。そのため、「Quantity」と「UnitPrice」の負の値を持つレコードも削除しましょう:
# 負のQuantityおよびPriceの行を削除data = data[(data['Quantity'] > 0) & (data['UnitPrice'] > 0)]
「CustomerID」を整数型に変換しましょう:
data['CustomerID'] = data['CustomerID'].astype(int)# データ型の変換を確認print(data.dtypes) 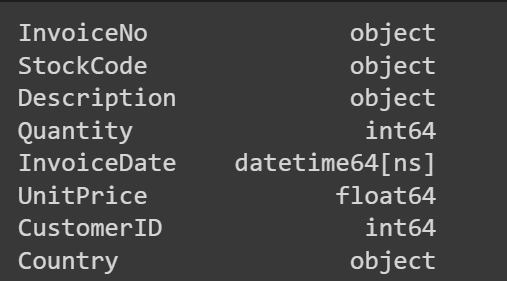
ステップ4 – 最終購入日、購入頻度、および金額の計算
まず、「InvoiceDate」列の最新日付から1日後の参照日snapshot_dateを定義しましょう:
snapshot_date = max(data['InvoiceDate']) + pd.DateOffset(days=1)
次に、「Total」列を作成しましょう。この列には全レコードに対して”Quantity” * “UnitPrice”の計算結果が含まれます:
data['Total'] = data['Quantity'] * data['UnitPrice']
次に、「Recency」、「Frequency」、および「MonetaryValue」を計算しますが、これは「CustomerID」ごとに計算します:
- 「Recency」は、最新の購入日と参照日(
snapshot_date)の差を計算します。これによって、顧客の最後の購入からの日数が得られます。値が小さいほど、顧客が最近購入を行ったことを示します。しかし、Recencyスコアについて話すときに、最近購入した顧客のほうが高いRecencyスコアを持っている方が良いでしょう。次のステップでこれを処理します。 - 「Frequency」は、顧客が購入を行う頻度を測定するため、各顧客が行った一意の請求書または取引の合計数を計算します。
- 「Monetary value」は、顧客がどれだけの金額を使っているかを定量化します。そのため、取引全体の金銭的な価値の平均を見つけます。
rfm = data.groupby('CustomerID').agg({ 'InvoiceDate': lambda x: (snapshot_date - x.max()).days, 'InvoiceNo': 'nunique', 'Total': 'sum'})
可読性のために、列の名前を変更しましょう:
rfm.rename(columns={'InvoiceDate': 'Recency', 'InvoiceNo': 'Frequency', 'Total': 'MonetaryValue'}, inplace=True)rfm.head() 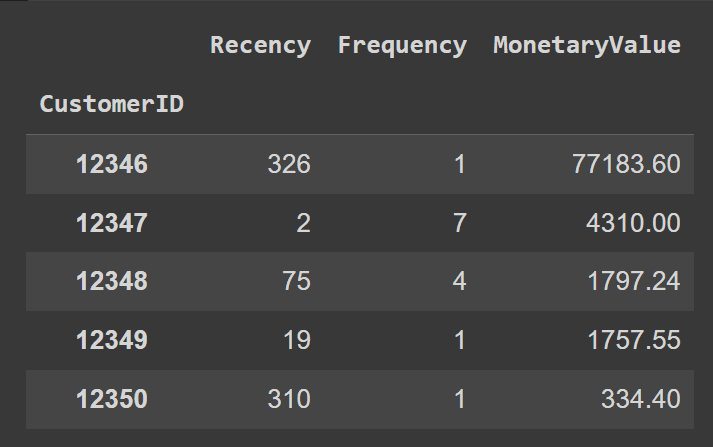
ステップ5 – RFM値を1~5のスケールにマッピングする
次に、「Recency」、「Frequency」、「MonetaryValue」の列を1~5のスケールにマッピングしましょう。
実質的には、5つの異なるビンに値を割り当て、各ビンを1つの値にマッピングします。ビンの境界を修正するために、「Recency」、「Frequency」、「MonetaryValue」のパーセンタイル値を使用しましょう:
rfm.describe()
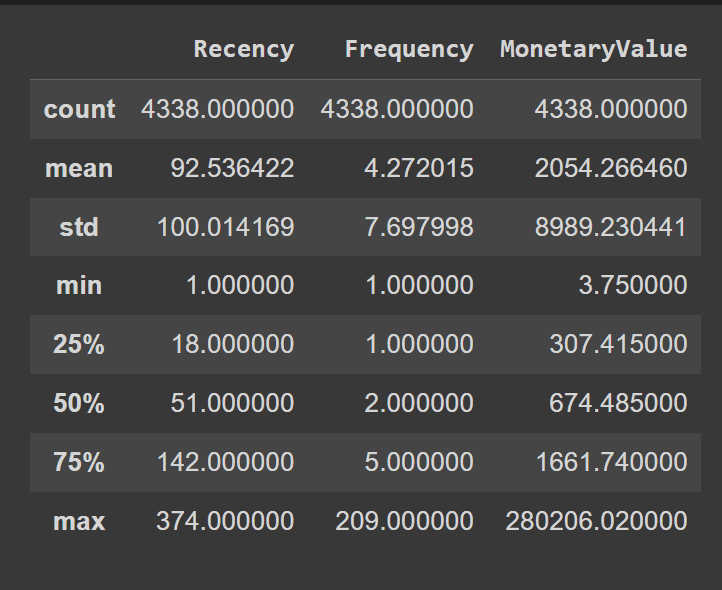
こちらがカスタムビンの境界を定義する方法です:
# Recency、Frequency、Monetaryスコアのカスタムビンの境界を計算するrecency_bins = [rfm['Recency'].min()-1, 20, 50, 150, 250, rfm['Recency'].max()]frequency_bins = [rfm['Frequency'].min() - 1, 2, 3, 10, 100, rfm['Frequency'].max()]monetary_bins = [rfm['MonetaryValue'].min() - 3, 300, 600, 2000, 5000, rfm['MonetaryValue'].max()]
ビンの境界を定義したので、スコアを1から5の対応するラベルにマップしましょう:
# Recencyスコアをカスタムビンに基づいて計算する rfm['R_Score'] = pd.cut(rfm['Recency'], bins=recency_bins, labels=range(1, 6), include_lowest=True)# Recencyスコアを反転させて、より高い値がより最近の購入を示すようにするrfm['R_Score'] = 5 - rfm['R_Score'].astype(int) + 1# FrequencyとMonetaryスコアをカスタムビンに基づいて計算するrfm['F_Score'] = pd.cut(rfm['Frequency'], bins=frequency_bins, labels=range(1, 6), include_lowest=True).astype(int)rfm['M_Score'] = pd.cut(rfm['MonetaryValue'], bins=monetary_bins, labels=range(1, 6), include_lowest=True).astype(int)
ビンに基づいたR_Scoreは、ビンに基づいて最近の購入には1で、250日以上前に行われた購入には5です。しかし、最も最近の購入にはR_Scoreが5で、250日以上前に行われた購入にはR_Scoreが1になるようにしたいです。
このようなマッピングを実現するためには、5 - rfm['R_Score'].astype(int) + 1を行います。
R_Score、F_Score、M_Scoreの最初の数行を表示しましょう:
# スコアが正しく計算されていることを確認するためにRFM DataFrameの最初の数行を表示するprint(rfm[['R_Score', 'F_Score', 'M_Score']].head(10))
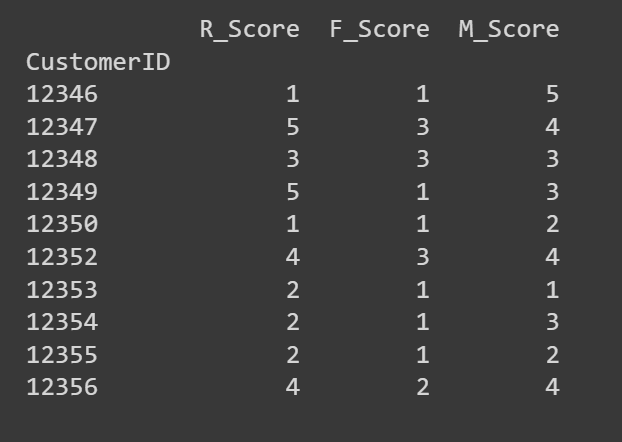
必要に応じて、これらのR、F、Mスコアを使用して詳細な分析を行うか、クラスタリングを使用して類似したRFM特性のセグメントを特定することができます。私たちは後者を選びます!
ステップ6 – K-Meansクラスタリングを実行する
K-Meansクラスタリングは特徴のスケールに敏感です。R、F、およびMの値はすべて同じスケールであるため、特徴をさらにスケーリングせずにクラスタリングを実行できます。
R、F、およびMのスコアを抽出して、K-Meansクラスタリングを実行しましょう:
# K-meansクラスタリングのためにRFMスコアを抽出X = rfm[['R_Score', 'F_Score', 'M_Score']]
次に、最適なクラスタ数を見つける必要があります。これには、さまざまなK値でK-Meansアルゴリズムを実行し、エルボー法を使用して最適なKを選択します:
# 異なるK値のための慣性(二乗距離の合計)を計算するinertia = []for k in range(2, 11): kmeans = KMeans(n_clusters=k, n_init= 10, random_state=42) kmeans.fit(X) inertia.append(kmeans.inertia_)# エルボーカーブをプロットplt.figure(figsize=(8, 6),dpi=150)plt.plot(range(2, 11), inertia, marker='o')plt.xlabel('クラスタ数 (k)')plt.ylabel('慣性')plt.title('K-Meansクラスタリングのエルボーカーブ')plt.grid(True)plt.show()
この曲線が4つのクラスタでエルボーを形成していることがわかります。したがって、顧客基盤を4つのセグメントに分割しましょう。
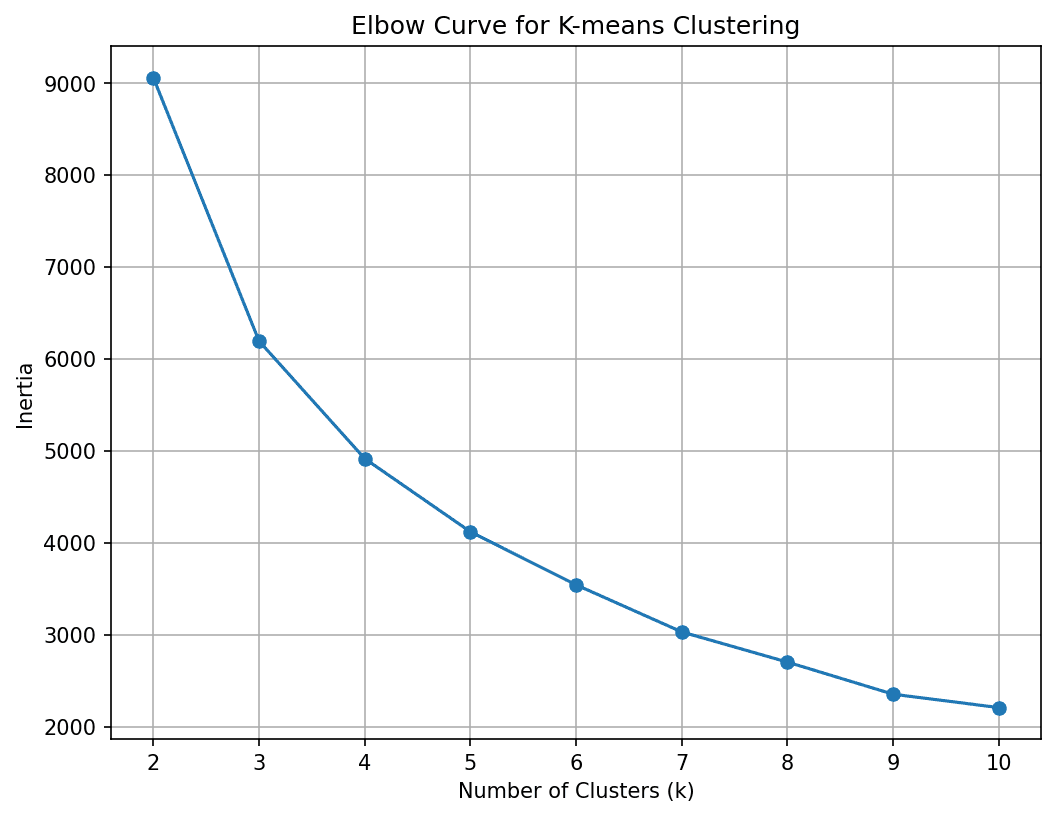
Kを4に固定したので、データセット内のすべてのポイントに対するクラスタの割り当てを取得するためにK-Meansアルゴリズムを実行しましょう:
# 最適なKでK-meansクラスタリングを実行best_kmeans = KMeans(n_clusters=4, n_init=10, random_state=42)rfm['Cluster'] = best_kmeans.fit_predict(X)
ステップ7 – クラスタを解釈して顧客セグメントを特定する
クラスタがあるので、RFMスコアに基づいてそれらを特徴付けしましょう。
# クラスタごとにグループ化し、平均値を計算するcluster_summary = rfm.groupby('Cluster').agg({ 'R_Score': 'mean', 'F_Score': 'mean', 'M_Score': 'mean'}).reset_index()
各クラスタの平均R、F、およびMのスコアは、特性について既にアイデアを与えるはずです。
print(cluster_summary)
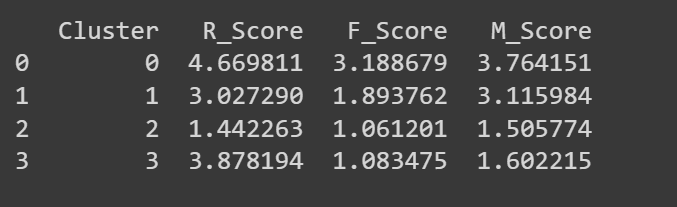
しかし、クラスタの平均R、F、およびMのスコアを可視化して解釈しやすくしましょう:
colors = ['#3498db', '#2ecc71', '#f39c12','#C9B1BD']# 各クラスタの平均RFMスコアをプロットplt.figure(figsize=(10, 8),dpi=150)# 平均Recencyをプロットplt.subplot(3, 1, 1)bars = plt.bar(cluster_summary.index, cluster_summary['R_Score'], color=colors)plt.xlabel('クラスタ')plt.ylabel('平均Recency')plt.title('各クラスタの平均Recency')plt.grid(True, linestyle='--', alpha=0.5)plt.legend(bars, cluster_summary.index, title='クラスタ')# 平均Frequencyをプロットplt.subplot(3, 1, 2)bars = plt.bar(cluster_summary.index, cluster_summary['F_Score'], color=colors)plt.xlabel('クラスタ')plt.ylabel('平均Frequency')plt.title('各クラスタの平均Frequency')plt.grid(True, linestyle='--', alpha=0.5)plt.legend(bars, cluster_summary.index, title='クラスタ')# 平均Monetaryをプロットplt.subplot(3, 1, 3)bars = plt.bar(cluster_summary.index, cluster_summary['M_Score'], color=colors)plt.xlabel('クラスタ')plt.ylabel('平均Monetary')plt.title('各クラスタの平均Monetary値')plt.grid(True, linestyle='--', alpha=0.5)plt.legend(bars, cluster_summary.index, title='クラスタ')plt.tight_layout()plt.show()
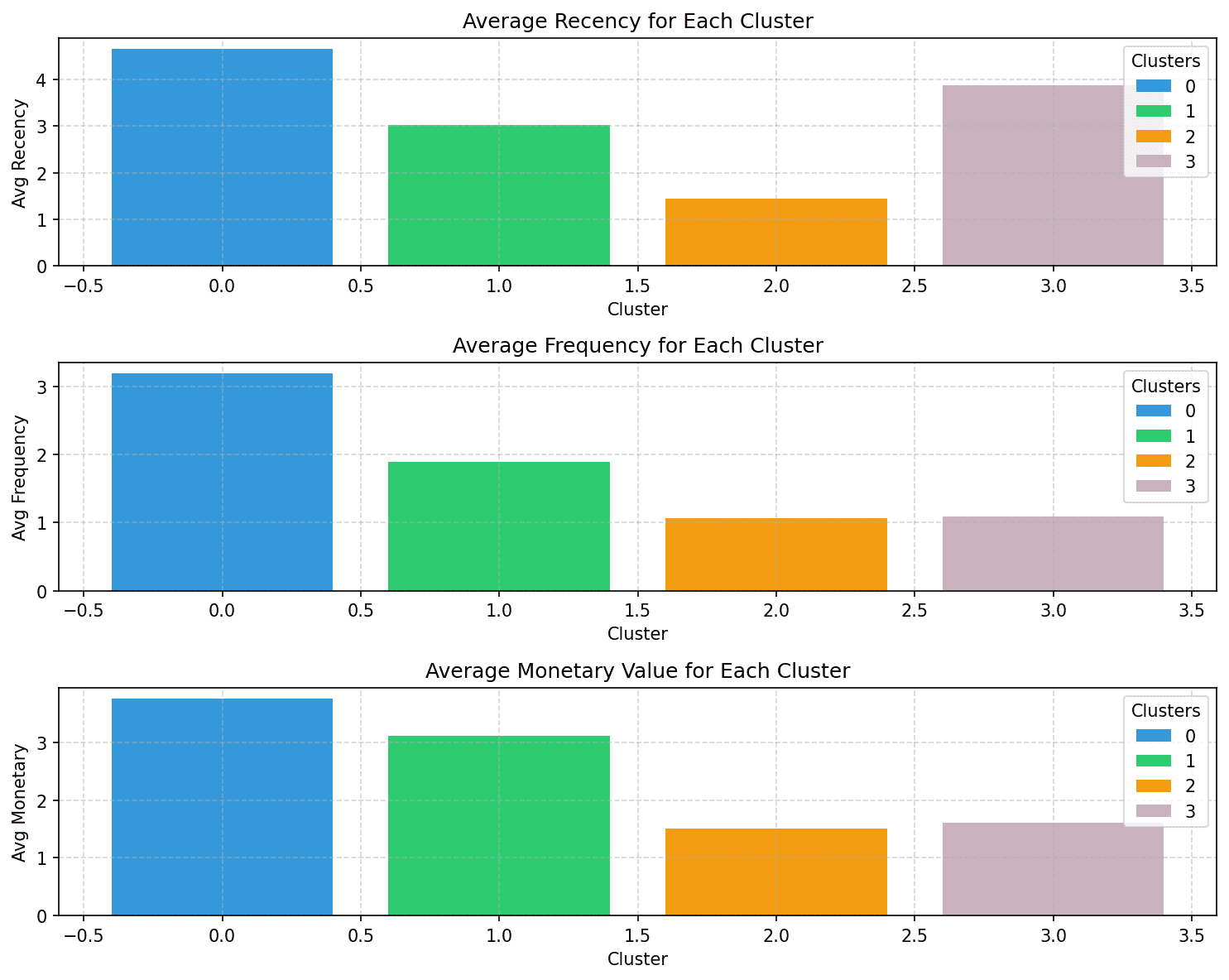
それぞれのセグメントのお客様は最新,頻度,金銭価値に基づいて特徴づけられることに注意してください:
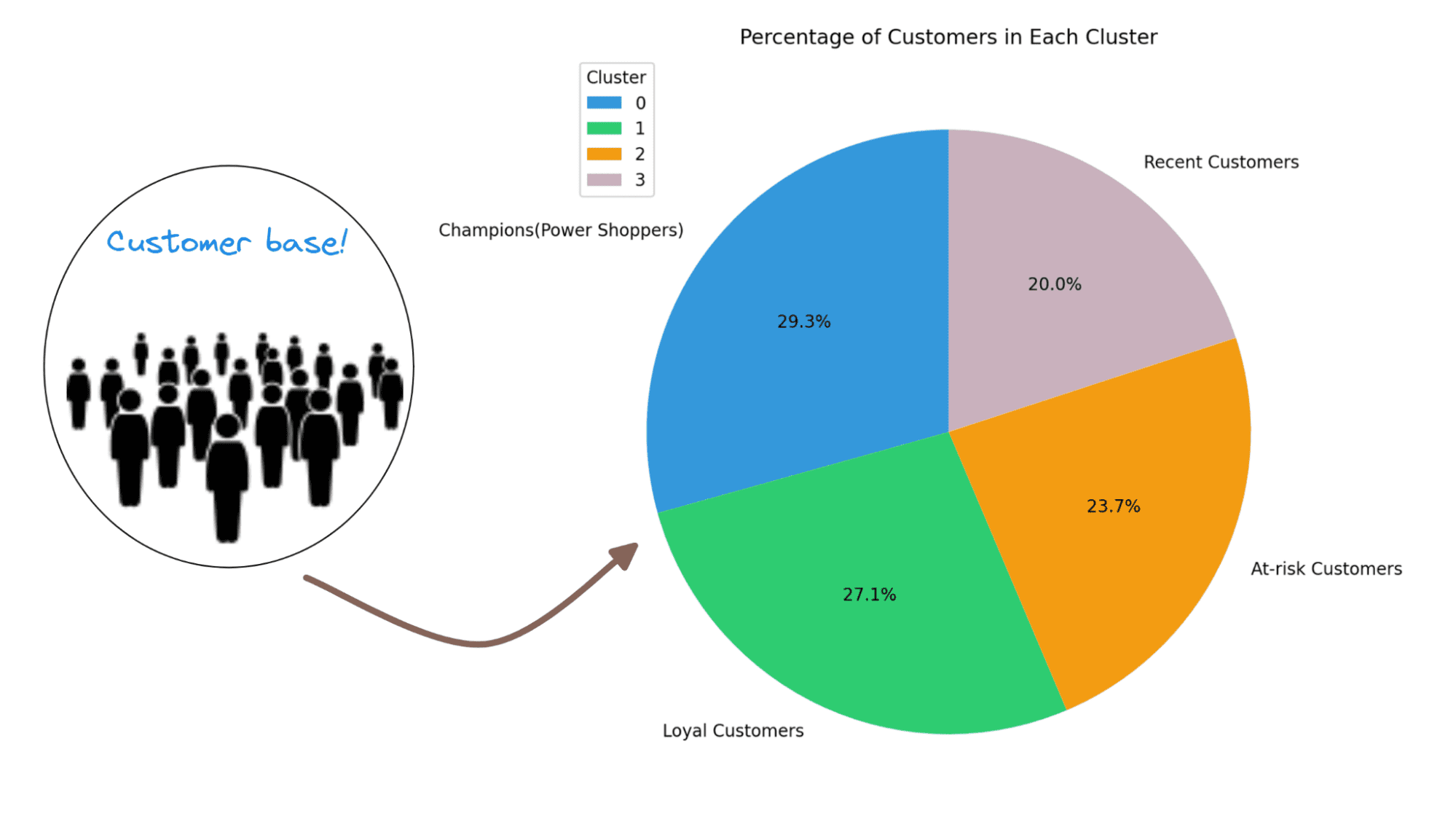
- クラスター0:この4つのクラスターの中で、このクラスターは最も最新、頻度、金銭価値が高いです。このクラスターのお客様を優勝者(またはパワーショッパー)と呼びましょう。
- クラスター1:このクラスターは、中程度の最新、頻度、金銭価値で特徴付けられます。これらのお客様はクラスター2と3よりもまだ多くのお金を使い、より頻繁に購入します。彼らを忠実なお客様と呼びましょう。
- クラスター2:このクラスターのお客様は少なくお金を使います。彼らは頻繁には買わず、最近も購入していません。これらは非アクティブまたはリスクのある顧客である可能性があります。
- クラスター3:このクラスターは最新が高く、頻度が比較的低く、金銭価値が中程度です。したがって、これらは最近のお客様であり、将来的に長期的なお客様になる可能性があります。
各セグメントのお客様に対してマーケティング努力を適応することで、顧客の関与と維持を向上させるためのいくつかの例:
- 優勝者/パワーショッパーのために:個別の割引、早期アクセス、その他の特典を提供して、彼らが価値を感じ、感謝されていることを示します。
- 忠実なお客様のために:感謝キャンペーン、紹介ボーナス、忠誠度に対する報酬。
- リスクのある顧客のために:購買を促進するために割引やプロモーションを実行する再関与の取り組み。
- 最近のお客様のために:ブランドについて教育するターゲットキャンペーンや次回の購入への割引。
また、異なるセグメントのお客様の割合も理解することは役に立ちます。これにより、マーケティング努力を効率化し、ビジネスを成長させることができます。
パイチャートを使用して、異なるクラスターの分布を視覚化しましょう:
cluster_counts = rfm['Cluster'].value_counts()colors = ['#3498db', '#2ecc71', '#f39c12','#C9B1BD']
# 顧客の総数を計算
total_customers = cluster_counts.sum()
# 各クラスターの顧客の割合を計算
percentage_customers = (cluster_counts / total_customers) * 100labels = ['優勝者(パワーショッパー)','忠実なお客様','リスクのある顧客','最近のお客様']
# パイチャートを作成
plt.figure(figsize=(8, 8),dpi=200)plt.pie(percentage_customers, labels=labels, autopct='%1.1f%%', startangle=90, colors=colors)plt.title('各クラスターの顧客の割合')plt.legend(cluster_summary['Cluster'], title='Cluster', loc='upper left')plt.show()そして、完成です!この例では、顧客がセグメント間にかなり均等に分布しています。したがって、既存の顧客を維持し、リスクのある顧客と最近の顧客との関係を再活性化し、教育するために時間と労力を投資することができます。
まとめ
以上です!154,000以上の顧客レコードを7つの簡単なステップで4つのクラスターに分類しました。顧客セグメンテーションがビジネスの成長と顧客満足度に影響を与えるデータに基づく意思決定を行うことがどのように可能になるかを理解していただければ幸いです。
- パーソナライズ:セグメンテーションにより、企業は各顧客グループの特定のニーズと興味に合わせてマーケティングメッセージ、商品の推奨、プロモーションを調整することができます。
- ターゲット向上:高価値顧客やリスクのある顧客を特定することで、企業は効果的にリソースを割り当て、効果をもたらす最も可能性の高い場所に重点を置くことができます。
- 顧客維持:セグメンテーションにより、企業は顧客の関与と満足度を維持するための戦略を作成することができます。
次のステップとして、このアプローチを別のデータセットに適用し、あなたの旅を文書化してコミュニティと共有してみてください!ただし、効果的な顧客セグメンテーションとターゲットキャンペーンを実行するには、顧客ベースと顧客ベースの変化についての理解が必要です。そのため、時間の経過に伴い戦略を洗練させるための定期的な分析が必要です。
データセットのクレジット
オンライン小売りデータセットはCreative Commons Attribution 4.0 International(CC BY 4.0)ライセンスで提供されています:
オンライン小売り。 (2015)。 UCI Machine Learning Repository。 https://doi.org/10.24432/C5BW33. Bala Priya Cはインドの開発者兼技術ライターです。 彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。 彼女の関心と専門分野はDevOps、データサイエンス、自然言語処理です。 彼女は読書、書き物、コーディング、コーヒーを楽しんでいます! 現在、彼女はチュートリアル、ハウツーガイド、意見記事などの執筆を通じて開発者コミュニティとの知識の共有に取り組んでいます。
[Bala Priya C](https://twitter.com/balawc27)はインドの開発者兼技術ライターです。 彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。 彼女の関心と専門分野はDevOps、データサイエンス、自然言語処理です。 彼女は読書、書き物、コーディング、コーヒーを楽しんでいます! 現在、彼女はチュートリアル、ハウツーガイド、意見記事などの執筆を通じて開発者コミュニティとの知識の共有に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- このNVIDIAのAI論文は、検索補完と長い文脈の力を探求しています:どちらが優れているのか、そしてそれらは共存できるのか?
- ミストラルAIのミストラル7Bファンデーションモデルは、Amazon SageMaker JumpStartで利用可能です
- 私たちはどのように大規模な言語モデルをストリーミングアプリケーションで効率的に展開できるのでしょうか?このAI論文では、無限のシーケンス長のためのStreamingLLMフレームワークを紹介しています
- ウェイモのMotionLMを紹介します:最新型のマルチエージェントモーション予測アプローチで、大規模言語モデル(LLM)が自動車の運転をサポートできるようにする可能性のあるものです
- CPR-CoachによるCPRトレーニングの革命:エラー認識と評価に人工知能を活用
- Amazon SageMakerのCanvas sentiment analysisとtext analysisモデルを使用して製品レビューから洞察を抽出するために、ノーコードの機械学習を使用してください
- 「Java での AI:Spring Boot と LangChain を使用して ChatGPT のクローンを構築する」



