ディープラーニングのためのラストバーンライブラリ
美容とファッションの専門家による、ディープラーニングを活用した最新のライブラリー

Rust Burnとは何ですか?
Rust Burnは、完全にRustプログラミング言語で書かれた新しい深層学習フレームワークです。既存のPyTorchやTensorFlowなどのフレームワークを使用する代わりに新しいフレームワークを作成する目的は、研究者、機械学習エンジニア、低レベルのソフトウェアエンジニアなど、さまざまなユーザーに適した多目的なフレームワークを構築することです。
- 「ジュリアプログラミング言語の探求:統合テスト」
- 『プロンプトブリーダーの内部:Google DeepMindの新しい自己改善プロンプト技術』
- Japanese AI規制- 仮定はありませんか?それとも何もしない?
Rust Burnの主な設計原則は、柔軟性、パフォーマンス、使いやすさです。
柔軟性は、最先端の研究アイデアを迅速に実装し実験を実行できる能力から生まれます。
パフォーマンスは、NVIDIA GPUのTensor Coresなどのハードウェア固有の機能を活用するなどの最適化によって実現されます。
使いやすさは、トレーニング、展開、およびモデルの本番実行のワークフローの簡素化から生まれます。
主な特徴:
- 柔軟で動的な計算グラフ
- スレッドセーフなデータ構造
- 開発プロセスを簡素化する直感的な抽象化
- トレーニングおよび推論中の高速パフォーマンス
- CPUおよびGPUのための複数のバックエンド実装のサポート
- トレーニング中のログ記録、メトリクス、チェックポイントの完全なサポート
- 小規模ながら活発な開発者コミュニティ
始めるには
Rustのインストール
Burnは、Rustプログラミング言語を基にした強力な深層学習フレームワークです。Rustの基本的な理解が必要ですが、一旦理解できれば、Burnが提供するすべての機能を活用することができます。
ガイドを使用してインストールします。また、WindowsとLinuxにRustをインストールするためのスクリーンショット付きのガイドもGeeksforGeeksで確認できます。
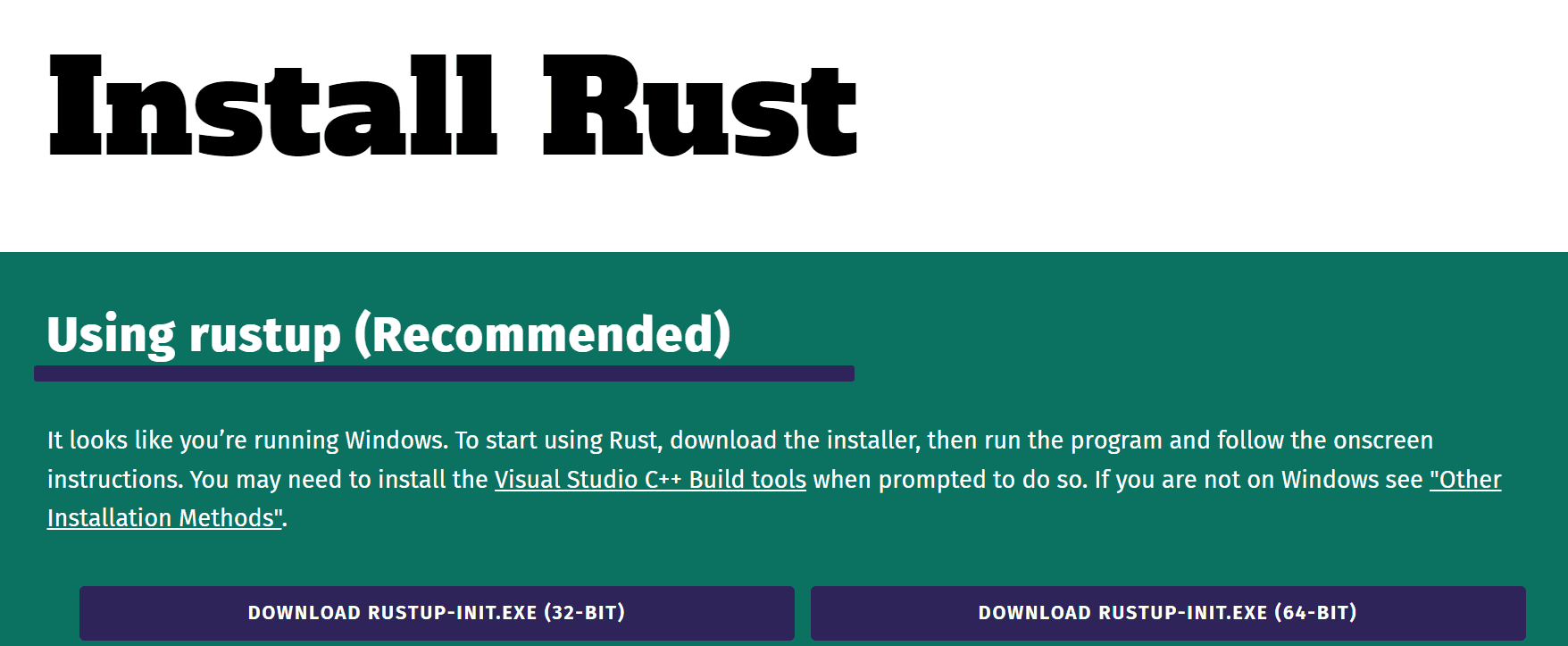
Burnのインストール
Rust Burnを使用するには、まずシステムにRustがインストールされている必要があります。Rustが正しくセットアップされている場合、Rustのパッケージマネージャであるcargoを使用して、新しいRustアプリケーションを作成できます。
現在のディレクトリで以下のコマンドを実行します:
cargo new new_burn_app
この新しいディレクトリに移動します:
cd new_burn_app
次に、Burnを依存関係に追加し、GPU操作を可能にするWGPUバックエンドの機能も追加します:
cargo add burn --features wgpu
最後に、プロジェクトをコンパイルしてBurnをインストールします:
cargo build
これにより、WGPUバックエンドとともにBurnフレームワークがインストールされます。WGPUを使用することで、Burnは低レベルのGPU操作を実行できます。
サンプルコード
要素ごとの加算
以下のコードを実行するには、src/main.rsを開き、内容を置き換える必要があります:
use burn::tensor::Tensor;use burn::backend::WgpuBackend;// 使用するバックエンドの型エイリアス.type Backend = WgpuBackend;fn main() { // 明示的な値を持つ最初のテンソルと、同じ形状を持つすべての要素が1である2番目のテンソルの作成 let tensor_1 = Tensor::::from_data([[2., 3.], [4., 5.]]); let tensor_2 = Tensor::::ones_like(&tensor_1); // 2つのテンソルの要素ごとの加算(WGPUバックエンドで実行)を表示 println!("{}", tensor_1 + tensor_2);}
メインの関数では、WGPUバックエンドを使用して2つのテンソルを作成し、加算を実行しました。
コードを実行するには、ターミナルでcargo runを実行する必要があります。
出力:
加算の結果を表示できるはずです。
Tensor { data: [[3.0、4.0]、[5.0、6.0]]、形状: [2、2]、デバイス: BestAvailable、バックエンド: "wgpu"、種類: "Float"、dtype: "f32"}
注意:次のコードはBurn Bookの例です:はじめに。
位置別のフィードフォワードモジュール
ここでは、フレームワークの使用がどれだけ簡単かの例を示します。このコードスニペットを使用して、位置別のフィードフォワードモジュールとそのフォワードパスを宣言します。
use burn::nn;use burn::module::Module;use burn::tensor::backend::Backend;#[derive(Module, Debug)]pub struct PositionWiseFeedForward<B: Backend> { linear_inner: Linear<B>, linear_outer: Linear<B>, dropout: Dropout, gelu: GELU,}impl PositionWiseFeedForward<B> { pub fn forward(&self, input: Tensor<B, D>) -> Tensor<B, D> { let x = self.linear_inner.forward(input); let x = self.gelu.forward(x); let x = self.dropout.forward(x); self.linear_outer.forward(x) }}
上記のコードはGitHubのリポジトリから取得されています。
サンプルプロジェクト
より多くの例について学び、実行するには、https://github.com/burn-rs/burnリポジトリをクローンし、次のプロジェクトを実行してください:
- MNIST:さまざまなバックエンドを使用してCPUまたはGPUでモデルをトレーニングします。
- MNIST推論Web:ブラウザでのモデル推論。
- テキスト分類:GPU上でゼロからトランスフォーマーエンコーダーをトレーニングします。
- テキスト生成:GPU上でゼロからオートリグレッシブトランスフォーマーを構築してトレーニングします。
事前トレーニングモデル
AIアプリケーションを構築するために、以下の事前トレーニングモデルを使用し、データセットでファインチューニングできます。
- SqueezeNet:squeezenet-burn
- Llama 2:Gadersd/llama2-burn
- Whisper:Gadersd/whisper-burn
- Stable Diffusion v1.4:Gadersd/stable-diffusion-burn
結論
Rust Burnは、深層学習フレームワークのランドスケープにおける興味深い新しい選択肢です。既にRust開発者である場合、Rustのスピード、安全性、並行性を活用して、深層学習の研究と製品開発の可能性を広げることができます。 Burnは、柔軟性、パフォーマンス、使いやすさの適切な妥協点を見つけ、さまざまなユースケースに適したユニークなフレームワークを作成することを目指しています。
まだ初期段階ではありますが、Burnは既存のフレームワークの課題に取り組み、さまざまな実務家のニーズを満たすという可能性を秘めています。フレームワークが成熟し、そのコミュニティが成長するにつれて、確立されたオプションと同じくらいの実用的なフレームワークになる可能性を秘めています。その新しいデザインと言語の選択肢は、深層学習コミュニティに新たな可能性を提供しています。
リソース
- ドキュメンテーション: https://burn-rs.github.io/book/overview.html
- ウェブサイト: https://burn-rs.github.io/
- GitHub: https://github.com/burn-rs/burn
- デモ: https://burn-rs.github.io/demo
****[Abid Ali Awan](https://www.polywork.com/kingabzpro)**** (@1abidaliawan)は、機械学習モデルの構築が大好きな認定データサイエンティストです。現在はコンテンツ作成および機械学習およびデータサイエンスの技術に関する技術ブログの執筆に焦点を当てています。Abidはテクノロジーマネジメントの修士号とテレコミュニケーションエンジニアリングの学士号を取得しています。彼のビジョンは、メンタルヘルスの問題を抱える学生向けに、グラフニューラルネットワークを使用したAI製品の構築です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ひとつのAIモデルで全てのオーディオタスクをこなせるのか?UniAudioに出会ってください:新しいユニバーサルオーディオ生成システム」
- In Japanese 「GTE-tinyに会いましょう:ダウンストリームタスクのためのパワフルなテキスト埋め込み人工知能モデル」(GTE-tiny ni aimashou Daunsutori-mu tasuku no tame no pawafuru na tekisuto umekomi jōchū nō moeru) Note Please keep in mind that this translation is accurate, but it may be adjusted to fit
- ハスデックスとステーブルディフュージョン:2つのAI画像生成モデルを比較
- オンラインで機械学習を学ぶ方法
- 「イギリスのテックフェスティバルが、クリエイティブ産業でAIを活用するスタートアップ企業を紹介する」
- 「ソーシャルメディアと機械学習を使用して明らかになる、公園の質の格差」
- チャットアプリのLLMを比較する:LLaMA v2チャット対Vicuna





