Learn more about Search Results GeeksforGeeks

- You may be interested
- デジタルアートの革新:ソウル国立大学の...
- ChatGPTの大きなサプライズ:OpenAIがAIマ...
- 「MicrosoftとKPMGが20億ドルのAIパートナ...
- Amazon SageMaker Data WranglerのSnowfla...
- AWSを使用したジェネレーティブAIを使用し...
- FitBot — フィットネスチャットボットエー...
- 新しいAI研究が、転移学習のためのマルチ...
- 「Pythonのグローバル変数は本当にグロー...
- テキストブック品質の合成データを使用し...
- 意味レイヤーの力:データエンジニアのガイド
- ChatGPTが1歳になりました:バイラルなモ...
- このAI研究は、DISC-MedLLMという包括的な...
- 「OpenAIがDall E-3を発売!次世代AIイメ...
- 大規模言語モデルの挙動を監視する7つの方法
- モビリティが活気づけられる:EVの発表増...

「サポートベクターマシン(SVM)とは何ですか?」
サポートベクターマシン(SVM)は、機械学習の分野で利用される教師あり学習アルゴリズムです。主に分類や回帰などのタスクを実行するために使用されます。このアルゴリズムは、メールがスパムかどうかの判断、手書き文字の認識、写真での顔の検出など、さまざまなタスクを処理できます。データ内の多くの情報や複雑な関係に対応できる非常に適応性のあるアルゴリズムです。 SVMの主な役割は、特徴に基づいて異なるグループの間を最適な線(または面)で分離することです。データが紙の上の点のようなもので、それらを完全に異なるクラスに分けるための単一の直線を引くことができると想像してください。これは、データが完全に線形に分離可能である必要があります。 SVMの種類 線形サポートベクターマシン データが直線を使用して簡単に2つのグループに分割できる場合、線形SVMが最適です。データが紙の上の点のようなもので、1本の直線を引いてそれらをきれいに2つの異なるクラスに分離できる状態であることを想像してください。 非線形サポートベクターマシン データが直線を使用して2つの別々のグループに分類できない場合、非線形SVMを使用します。ここでは、データは線形に分離できません。このような場合には、非線形SVMが救世主となります。データが複雑なパターンに従わずにしばしば乱雑な現実世界では、非線形SVMのカーネルトリックが使用されます。 どのように動作するのか? 床に散らばった2つのグループ、例えば緑と青の点があると想像してください。SVMの役割は、これらの点をそれぞれのグループに分けるための最適な線(または3次元の世界では面)を見つけ出すことです。 今、点を分けるための多くの線があるかもしれませんね?しかし、SVMは特別な線を探します。すなわち、線と最も近い緑の点から線までの距離と線と最も近い青の点から線までの距離が最大となる線です。この距離を「マージン」と呼び、SVMはできるだけ大きくすることを目指します。 この線を定義するのに重要な役割を果たす最も近い点を「サポートベクター」と呼びます。SVMは、2つのグループの間のスペースを最大化する最良の線を描くためにこれに焦点を当てます。 しかし、もし点がきれいに直線で分離されていない場合はどうでしょうか?もし点があちこちに散らばっている場合はどうでしょうか?そんなときに、SVMは問題を高次元空間に持ち上げるために「カーネルトリック」と呼ばれるものを使用することができます。これにより、より複雑な分割曲線や曲面を引くことが可能になります。 用途とアプリケーション 1. スパムメールフィルタリング: スパムと普通のメールが混在するメールボックスがあると想像してください。SVMを使用して、スパムと通常のメールを区別するスマートフィルターを作成できます。使用される単語などのメールの様々な特徴を見て、スパムと非スパムを区別する境界線を描き、メールボックスをきれいに保ちます。 2. 手書き文字認識: コンピュータが異なる人々の手書き文字を認識することを希望する場合、SVMが役立ちます。手書き文字の形や大きさなどの特徴を分析することで、SVMは一人の人の手書き文字を別の人のものと分離する線や曲線を描くことができます。これは郵便サービスでの数字認識などのアプリケーションに役立ちます。 3. 医療診断: 医学の世界では、SVMは疾患の診断に役立ちます。ある特定の状態の患者とその他の一般の患者についてのデータがあるとします。SVMは様々な健康指標を分析し、健康な患者と状態を持つ患者を区別する境界線を作成します。これにより、医師がより正確な診断を行うのに役立ちます。 4. 画像分類:…

関係データベースとその応用についての深い探求
今日では、さまざまな頻繁に関連のないカテゴリに膨大な量のデータを記憶する必要性が、高い効率のデータベースの重要な意義を強調しています。データベースは、迅速なアクセス、操作、分析を可能にするために、注意深く整理、構造化、保存されたデータのコレクションです。データベースは、データウェアハウジングやオンライントランザクション処理など、さまざまなタスクに役立ち、在庫記録、顧客情報、財務記録などのデータの種類をサポートしています。 リレーショナルデータベースとは何ですか? リレーショナルデータベースは、基本的にはテーブル形式で行と列にデータが整然と構造化されたセットです。このパラダイムでは、テーブルを使用してデータを記述し、各行が特定のレコードを示し、各列が特定のプロパティまたはフィールドを定義します。 基本的には、予め定義された関係を持つデータオブジェクトのセットがリレーショナルデータベースを構成します。テーブルの列は、各々が特定のタイプのデータを含み、フィールドは属性の実際の値を含んでいます。テーブルの行は、単一のアイテムやエンティティの関連する値のグループを表します。テーブル内の各行を識別するために一意の識別子である主キーが使用されます。外部キーは、異なるテーブルの行の関係を確立するために使用されます。 リレーショナルデータベースの例 子供の夏キャンプのデータでは、テーブル内の各行が個別のキャンパーを表し、彼らの名前、年齢、参加しているアクティビティ、および一意のID番号などの情報が含まれています。 ID Name Age Activity 1 John 11 Pottery 2 Courtney 16 Photography 3 Matt 14 Cooking 4 Jasmine…
「時系列分析による回帰モデルの堅牢性向上—Part 2」
第1部では、SARIMA(季節性自己回帰和分移動平均)を使用して、タイムシリーズモデルを成功裏に構築することに成功しましたさらに、構築したモデルを評価しました

ディープラーニングのためのラストバーンライブラリ
「研究者、MLエンジニア、開発者向けに柔軟性、パフォーマンス、使いやすさをバランスさせることを目指した、完全にRustで構築された新しいディープラーニングフレームワーク」

データストレージの最適化:SQLにおけるデータ型と正規化の探索
SQLにおけるデータ型と正規化の技術について学び、データストレージの最適化に非常に役立ちます

「教師あり学習の理論と概要の理解」
この記事は、人気のある教師あり学習アルゴリズムの高レベルな概要をカバーし、初心者向けに特別に作成されています
「生データから洗練されたデータへ:データの前処理の旅 — パート3:重複データ」
データ内の重複した値の存在は、多くのプログラマーによってしばしば無視されますしかし、データ内の重複したレコードに対処することは非常に重要です例えば、置き換えるとどうなるかなど、重複したレコードの扱いは重要です
マルチアームバンディットを用いた動的価格設定:実践による学習
意思決定の問題の広大な世界において、一つのジレンマが特に強化学習の戦略によって所有されています:探索と活用スロットマシンが並ぶカジノに入っていると想像してください...
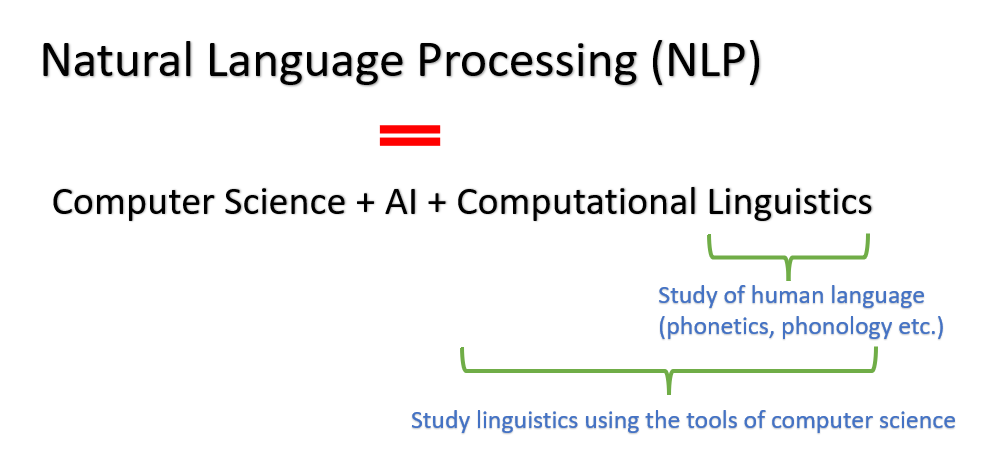
NLPの探索 – NLPのキックスタート(ステップ#1)
今学期、私はカリキュラムの一部としてNLPを受講していますやったー!さて、この科目の今後の評価の一環として、与えられた教材を復習し、いくつかのノートを作成しましたそれが私がすることです...

予測の作成:Pythonにおける線形回帰の初心者ガイド
最も人気のある機械学習アルゴリズムである線形回帰について、その数学的直感とPythonによる実装をすべて学びましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.