「ゼロからヒーローへ:PyTorchで最初のMLモデルを作ろう」
Zero to Hero Creating the First ML Model with PyTorch

動機
PyTorchは、最も広く使用されているPythonベースのディープラーニングフレームワークです。すべての機械学習アーキテクチャとデータパイプラインに対して非常に強力なサポートを提供しています。この記事では、アルゴリズムを実装するためのフレームワークの基本をすべて説明します。
- 「Verbaに会ってください:自分自身のRAG検索増強生成パイプラインを構築し、LLMを内部ベースの出力に活用するためのオープンソースツール」
- 高性能意思決定のためのRLHF:戦略と最適化
- 「ResFieldsをご紹介します:長くて複雑な時間信号を効果的にモデリングするために、時空間ニューラルフィールドの制約を克服する革新的なAIアプローチ」
すべての機械学習の実装には4つの主要なステップがあります:
- データの処理
- モデルのアーキテクチャ
- トレーニングループ
- 評価
これらのステップをすべて実装しながら、PyTorchで自分自身のMNIST画像分類モデルを作成します。これにより、機械学習プロジェクトの一般的なフローに慣れることができます。
インポート
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# PyTorchによって提供されるMNISTデータセットを使用
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# 別のファイルで実装されたモデルをインポート
from model import Classifier
import matplotlib.pyplot as plt
torch.nnモジュールは、ニューラルネットワークのアーキテクチャをサポートし、Dense Layers、Convolutional Neural Networksなどの人気のあるレイヤーの組み込み実装を提供しています。
torch.optimは、確率的勾配降下法やAdamなどの最適化手法の実装を提供しています。
その他のユーティリティモジュールは、データの処理サポートや変換に使用できます。詳細については後で説明します。
ハイパーパラメータの宣言
各ハイパーパラメータについては、適切な箇所で詳しく説明します。ただし、変更や理解のためにファイルの先頭で宣言するのがベストプラクティスです。
INPUT_SIZE = 784 # 28x28の画像をフラット化
NUM_CLASSES = 10 # 0から9までの手書き数字
BATCH_SIZE = 128 # ミニバッチを使用してトレーニング
LEARNING_RATE = 0.01 # オプティマイザのステップ
NUM_EPOCHS = 5 # トレーニングの総エポック数
データの読み込みと変換
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
MNISTは、PyTorchのデフォルトで提供される人気のある画像分類データセットです。0から9までの10個の手書き数字のグレースケール画像で構成されています。各画像は28ピクセル×28ピクセルのサイズで、データセットには60000のトレーニング画像と10000のテスト画像が含まれています。
トレーニングデータセットとテストデータセットを別々にロードし、MNISTの初期化関数のtrain引数で示します。root引数はデータセットをダウンロードするディレクトリを宣言します。
ただし、追加のtransform引数も渡します。PyTorchでは、すべての入力と出力はTorch.Tensor形式である必要があります。これはnumpyのnumpy.ndarrayに相当します。このテンソル形式は、データ操作のための追加のサポートを提供します。ただし、ロードするMNISTデータはPIL.Image形式です。画像をPyTorch互換のテンソルに変換する必要があります。そのために、次の変換を行います:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
ToTensor()変換は画像をテンソル形式に変換します。次に、追加のLambda変換を渡します。Lambda関数を使用すると、カスタム変換を実装できます。ここでは、入力をフラット化する関数を宣言しています。画像のサイズは28×28ですが、フラット化して1次元の配列に変換します。これは、後でモデルを実装する際に重要になります。
Compose関数は、すべての変換を順次結合します。まず、データをテンソル形式に変換し、次に1次元の配列にフラット化します。
データをバッチに分割する
計算とトレーニングの目的のために、モデルに完全なデータセットを一度に渡すことはできません。データセットをモデルに順次フィードするために、データセットをミニバッチに分割する必要があります。これにより、トレーニングが高速化され、データセットにランダム性が追加され、安定したトレーニングが可能になります。
PyTorchはデータをバッチ処理するための組み込みサポートを提供しています。torch.utilsモジュールのDataLoaderクラスは、torchデータセットモジュールを指定してデータのバッチを作成することができます。先ほどのように、すでにデータセットをロードしています。
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
データセットをdataloaderに渡し、バッチサイズのハイパーパラメータを初期化引数として渡します。これにより、イテラブルなデータローダーが作成され、単純なforループを使用して各バッチを簡単に反復処理することができます。
最初の画像はサイズが(784、)であり、1つの関連するラベルがありました。バッチ処理では、異なる画像とラベルがバッチに結合されます。たとえば、バッチサイズが64の場合、バッチ内の入力サイズは(64、784)になり、各バッチには64の関連するラベルがあります。
また、トレーニングバッチをシャッフルし、各エポックごとにバッチ内の画像を変更します。これにより、モデルパラメータの安定したトレーニングと収束が高速化されます。
分類モデルの定義
私たちは、3つの隠れ層からなるシンプルな実装を使用しています。これはシンプルですが、より複雑な実装における異なる層の組み合わせの一般的な理解を提供することができます。
上記のように、入力テンソルのサイズは(784、)であり、0から9までの10個の異なる出力クラスがあります。
** モデルの実装では、バッチの次元を無視できます。
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# 各Denseレイヤーと活性化関数を通して入力を順次渡す
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
まず、モデルはtorch.nn.Moduleクラスを継承する必要があります。これにより、ニューラルネットワークアーキテクチャの基本的な機能が提供されます。その後、__init__とforwardの2つのメソッドを実装する必要があります。
__init__メソッドでは、モデルが使用するすべてのレイヤーを宣言します。PyTorchが提供するLinear(またはDense)レイヤーを使用します。最初のレイヤーは入力を512つのニューロンにマッピングします。input_sizeをモデルのパラメータとして渡すことで、後で異なるサイズの入力に対しても使用できるようにします。2つ目のレイヤーは512つのニューロンを256つにマッピングします。3つ目の隠れ層は、前のレイヤーの256つのニューロンを128つにマッピングします。最後のレイヤーは最終的な出力サイズに減少します。出力サイズは、10個の異なる数字を予測するため、サイズ(10、)のテンソルになります。
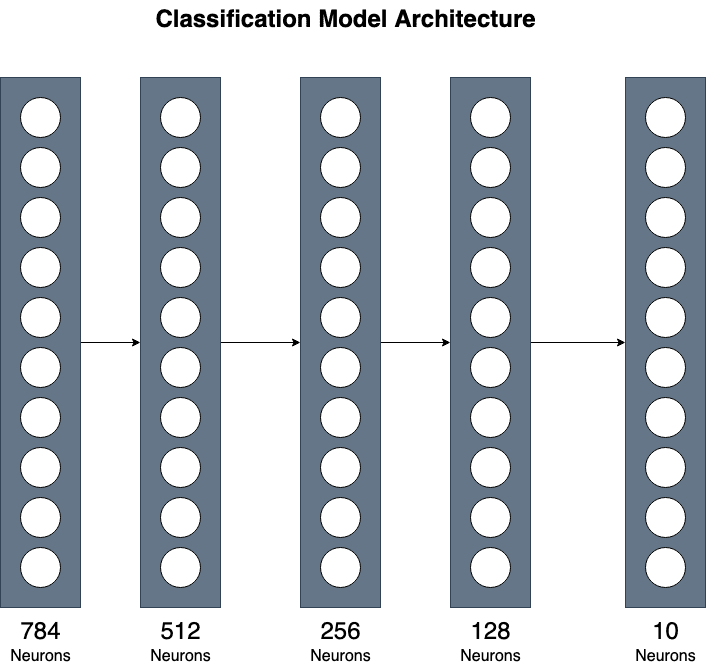
さらに、モデルに非線形性をもたらすReLU活性化レイヤーを初期化します。
forward関数は画像を受け取り、入力の処理のためのコードを提供します。宣言されたレイヤーを使用し、入力を各レイヤーを順次通過させ、中間のReLU活性化レイヤーを使用します。
メインのコードでは、データセットの入力サイズと出力サイズを指定してモデルを初期化することができます。
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
初期化された後、モデルデバイス(CUDA GPUまたはCPU)を変更します。ハイパーパラメータを初期化する際にデバイスをチェックしました。今は、テンソルとモデルのレイヤーのデバイスを手動で変更する必要があります。
トレーニングループ
まず、モデルのパラメータを最適化するために使用される損失関数とオプティマイザを宣言する必要があります。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
まず、モデルのパラメータを最適化するために使用される損失関数とオプティマイザを宣言する必要があります。
多クラス分類モデルに主に使用されるクロスエントロピー損失を使用します。これは、まず予測にソフトマックスを適用し、与えられたターゲットラベルと予測値を計算します。
アダムオプティマイザは、収束に向かって安定した勾配降下を可能にする最も使用されるオプティマイザ関数です。現在ではデフォルトのオプティマイザの選択肢であり、満足のいく結果を提供します。 最適化される重みを示す引数としてモデルのパラメータを渡します。
トレーニングループでは、理解を深めながらステップバイステップで構築し、欠落部分を埋めていきます。
まず、データセット全体を複数回(エポックと呼ばれる)反復し、各回でモデルを最適化する必要があります。ただし、データをバッチに分割しています。そのため、各エポックでは各バッチに対しても反復する必要があります。このためのコードは以下のようになります:
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
# 各バッチごとにモデルをトレーニングする
さて、単一の入力バッチを与えてモデルをトレーニングできます。バッチは画像とラベルで構成されます。まず、それぞれを分離する必要があります。モデルは予測を行うために入力として画像のみを必要とします。次に、予測と真のラベルを比較して、モデルの性能を推定します。
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
images, labels = batch # 入力とラベルを分離する
# テンソルのハードウェアデバイスをGPUまたはCPUに変換する
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# モデル.forward()関数を呼び出して予測を生成する
predictions = model(images)
予測をモデルに直接渡し、モデルのフォワード関数で処理されるようにします。予測が得られたら、モデルの重みを最適化できます。
最適化のコードは次のようになります:
# クロスエントロピー損失を計算する
loss = criterion(predictions, labels)
# 前のバッチの勾配値をクリアする
optimizer.zero_grad()
# 損失に基づいてバックプロップ勾配を計算する
loss.backward()
# モデルの重みを最適化する
optimizer.step()
上記のコードを使用することで、すべてのバックプロパゲーション勾配を計算し、Adamオプティマイザを使用してモデルの重みを最適化できます。上記のコードを組み合わせることで、モデルを収束に向かってトレーニングすることができます。
完全なトレーニングループは以下のようになります:
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # 入力とラベルを分離する
# テンソルのハードウェアデバイスをGPUまたはCPUに変換する
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# モデル.forward()関数を呼び出して予測を生成する
predictions = model(images)
# クロスエントロピー損失を計算する
loss = criterion(predictions, labels)
# 前のバッチの勾配値をクリアする
optimizer.zero_grad()
# 損失に基づいてバックプロップ勾配を計算する
loss.backward()
# モデルの重みを最適化する
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'エポック: {epoch + 1} / {NUM_EPOCHS}: 平均損失: {total_epoch_loss / steps}')
損失は徐々に減少し、0に近づきます。その後、最初に宣言したテストデータセットでモデルを評価することができます。
モデルの評価
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# 最も確率の高い予測ラベルを取得する
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nテスト正解率: {((correct_predictions / total_predictions) * 100):.2f}")
トレーニングループと同様に、テストデータセットの各バッチを評価するために反復処理を行います。入力に対して予測を生成します。ただし、評価では、最も高い確率を持つラベルのみが必要です。argmax関数は、予測配列内の最も高い値のインデックスを取得するためのこの機能を提供します。
正確性のスコアにおいては、予測されたラベルが真のターゲットラベルと一致するかどうかを比較することができます。それによって、正しく予測されたラベルの数を総予測ラベルで割った正確性を計算します。
結果
モデルを5エポックでトレーニングし、トレーニング前の10%の正確性に比べて96%以上のテスト正確性を達成しました。以下の画像は、5エポックのトレーニング後のモデルの予測を示しています。
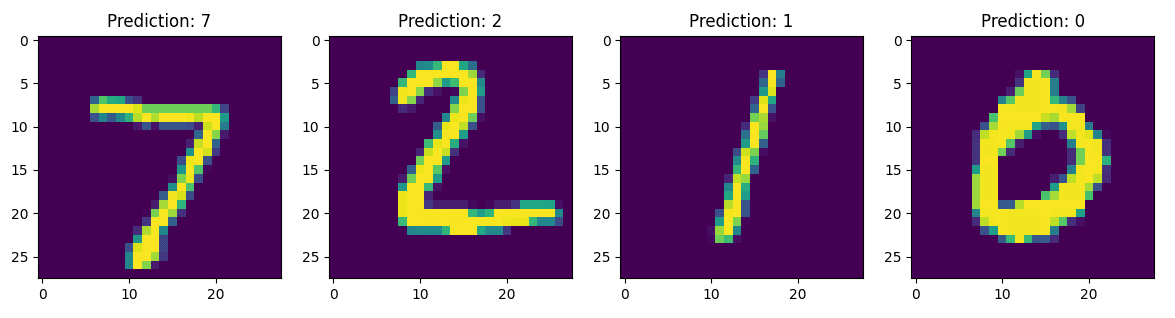
以上です。画像のピクセル値だけで手書きの数字を識別できるモデルをゼロから実装しました。
これはPyTorchの包括的なガイドではありませんが、機械学習プロジェクトの構造とデータフローについて一般的な理解を提供します。これは、深層学習の最先端のアーキテクチャを実装するための十分な知識です。
完全なコード
完全なコードは以下の通りです:
model.py:
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# 入力を各密結合層と活性化関数に順番に通す
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
main.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# PyTorchが提供するMNISTデータセットを使用
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# 別のファイルで実装されたモデルをインポート
from model import Classifier
import matplotlib.pyplot as plt
if __name__ == "__main__":
INPUT_SIZE = 784 # 平坦化された28x28の画像
NUM_CLASSES = 10 # 0から9までの手書きの数字
BATCH_SIZE = 128 # トレーニングにはミニバッチを使用
LEARNING_RATE = 0.01 # 最適化ステップ
NUM_EPOCHS = 5 # トレーニングの総エポック数
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# 画像をPyTorchのテンソルに変換するために使用されます
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # 入力とラベルを分離
# テンソルをGPUまたはCPUに変換
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# モデル.forward()関数を呼び出して予測を生成
predictions = model(images)
# クロスエントロピー損失を計算
loss = criterion(predictions, labels)
# 前のバッチの勾配値をクリア
optimizer.zero_grad()
# 損失に基づいてバックプロパゲーションの勾配を計算
loss.backward()
# モデルの重みを最適化
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'エポック:{epoch + 1} / {NUM_EPOCHS}:平均損失:{total_epoch_loss / steps}')
# トレーニング済みモデルを保存
torch.save(model.state_dict(), 'trained_model.pth')
model.eval()
correct_predictions = 0
total_predictions = 0
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# 最も確率の高い予測されたラベルを取得
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nテスト正確性:{((correct_predictions / total_predictions) * 100):.2f}")
# -- 結果のプロットのためのコード -- #
batch = next(iter(test_dataloader))
images, labels = batch
fig, ax = plt.subplots(nrows=1, ncols=4, figsize=(16,8))
for i in range(4):
image = images[i]
prediction = torch.softmax(model(image), dim=0)
prediction = torch.argmax(prediction, dim=0)
# print(type(prediction), type(prediction.item()))
ax[i].imshow(image.view(28,28))
ax[i].set_title(f'予測:{prediction.item()}')
plt.show()ムハンマド・アルハムは、コンピュータビジョンと自然言語処理の分野で活動するディープラーニングエンジニアです。彼はVyro.AIでグローバルトップチャートにランクインしたいくつかの生成型AIアプリケーションのデプロイと最適化に取り組んできました。彼は知的システムのための機械学習モデルの構築と最適化に興味を持ち、絶えず改善を信じています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ディープラーニングによる触媒性能の秘密の解明:異種触媒の高精度スクリーニングのための「グローバル+ローカル」畳み込みニューラルネットワークのディープダイブ
- 「時を歩く:SceNeRFlowは時間的一貫性を持つNeRFを生成するAIメソッドです」
- 強化学習 価値反復の簡単な入門
- Fast.AIディープラーニングコースからの7つの教訓
- Google AIは、TPUを使用して流体の流れを計算するための新しいTensorFlowシミュレーションフレームワークを導入しました
- アデプトAIラボは、Persimmon-8Bという強力なフルパーミッシブライセンスの言語モデルをオープンソース化しました
- 「Falcon 180Bをご紹介します:1800億のパラメータを持つ、公開されている最大の言語モデル」





