ゼロショット画像からテキスト生成 BLIP-2
'Zero-shot image-to-text generation BLIP-2'
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。
目次
- はじめに
- BLIP-2の内部構造は?
- Hugging Face TransformersでのBLIP-2の使用
- 画像キャプショニング
- プロンプト付き画像キャプショニング
- ビジュアルな質問応答
- チャットベースのプロンプト
- 結論
- 謝辞
はじめに
近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。
現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。
BLIP-2の内部構造は?
BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。
- Hugging FaceとAWSが協力し、AIをよりアクセスしやすくするためにパートナーシップを結成
- Swift 🧨ディフューザー – Mac用の高速安定拡散
- 複雑なテキスト分類のユースケースにおいて、Hugging Faceを活用する
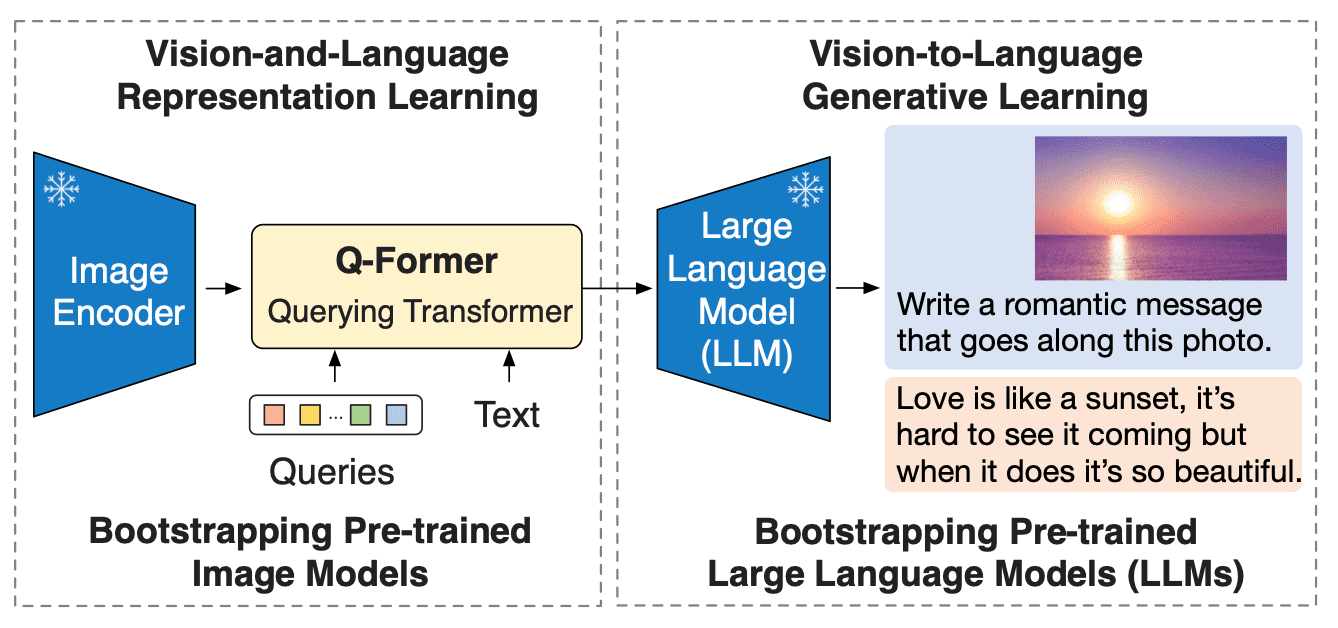
Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています:
- 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。
- テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。
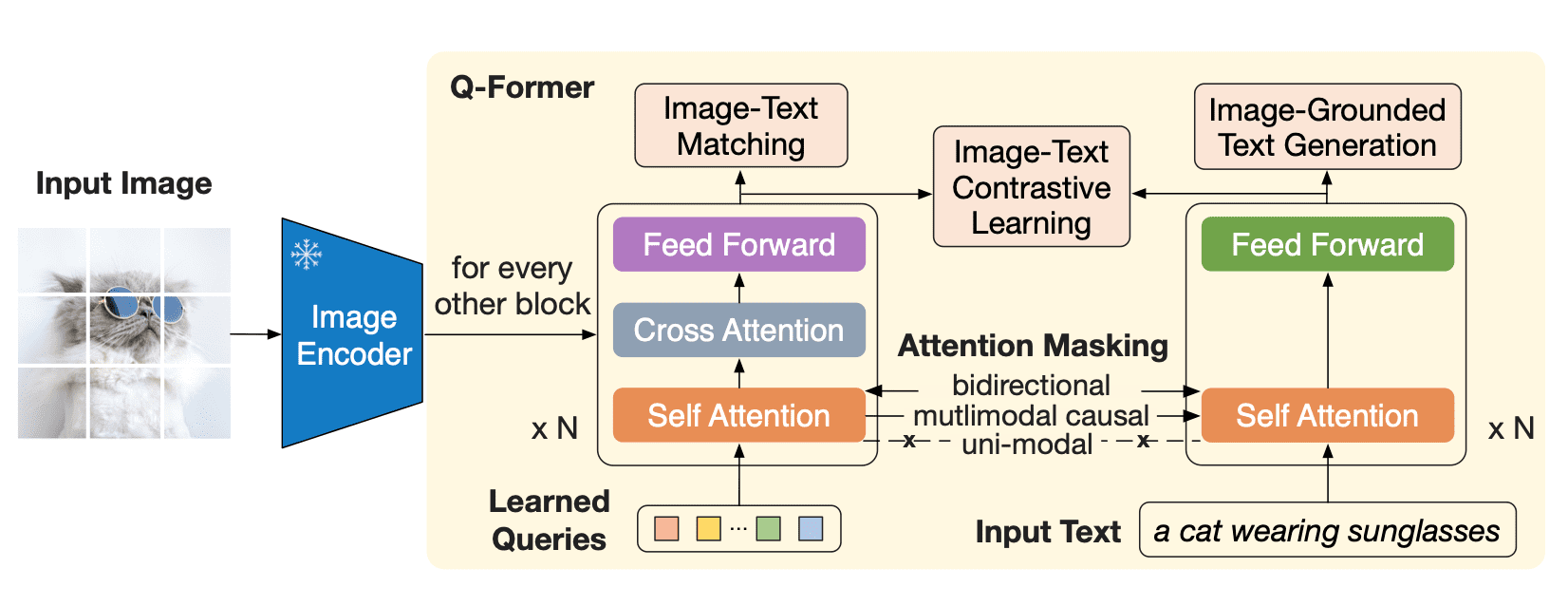
画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。
Q-Formerは2つの段階で事前学習されます。最初の段階では、画像エンコーダが凍結され、Q-Formerは3つの損失関数で訓練されます:
- 画像テキストの対比損失:各クエリ出力とテキスト出力のCLSトークンのペアごとの類似度が計算され、最も類似度の高いものが選択されます。クエリ埋め込みとテキストは互いを「見る」ことはありません。
- 画像に基づいたテキスト生成:クエリは互いを見ることができますが、テキストトークンには因果マスクがあり、すべてのクエリにアテンションを向けることができます。
- 画像テキストのマッチング損失:クエリとテキストは互いを見ることができ、テキストが画像に一致するかどうかを示すロジットを取得します。負の例を得るために、ハードネガティブマイニングが使用されます。
2番目の事前学習段階では、クエリ埋め込みにはテキストに関連する視覚情報が含まれており、情報のボトルネックを通過したため、これらの埋め込みはLLMへの入力として使用されます。この事前学習フェーズでは、因果LM損失を使用した画像に基づいたテキスト生成タスクが効果的に行われます。
ビジュアルエンコーダとして、BLIP-2はViTを使用しており、LLMについては、論文の著者はOPTとFlan T5モデルを使用しました。Hugging Face Hubでは、OPTとFlan T5の事前トレーニング済みのチェックポイントを見つけることができます。ただし、前述のように、導入された事前トレーニングアプローチでは、任意のビジュアルバックボーンと任意のLLMを組み合わせることができます。
Hugging Face Transformersを使用したBLIP-2の利用方法
Hugging Face Transformersを使用すると、事前トレーニング済みのBLIP-2モデルを簡単にダウンロードして画像で実行することができます。このブログポストの例に従う場合は、高いRAMを持つGPU環境を使用してください。
まず、Transformersをインストールします。このモデルは最近Transformersに追加されたため、ソースからTransformersをインストールする必要があります:
pip install git+https://github.com/huggingface/transformers.git次に、入力画像が必要です。毎週、The New Yorkerは読者の間で漫画のキャプションコンテストを開催していますので、その中から一つの漫画を選んでBLIP-2をテストしてみましょう。
import requests
from PIL import Image
url = 'https://media.newyorker.com/cartoons/63dc6847be24a6a76d90eb99/master/w_1160,c_limit/230213_a26611_838.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
display(image.resize((596, 437)))
入力画像があります。これから、事前トレーニング済みのBLIP-2モデルと対応するプリプロセッサが必要です。Hugging Face Hubでは、すべての利用可能な事前トレーニング済みのチェックポイントのリストを見つけることができます。ここでは、2.7 billionパラメータを持つMeta AIによって事前トレーニングされたOPTモデルを活用したBLIP-2のチェックポイントをロードします。
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)BLIP-2はAuto API(AutoModelForXXXなど)を使用してモデルをロードすることができない珍しいケースですので、明示的にBlip2ForConditionalGenerationを使用する必要があります。ただし、AutoProcessorを使用して適切なプロセッサクラス(この場合はBlip2Processor)を取得することができます。
テキスト生成を高速化するためにGPUを使用しましょう:
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)画像キャプショニング
BLIP-2がNew Yorkerの漫画をゼロショットでキャプションできるか調べてみましょう。画像のキャプションを作成するために、モデルにテキストプロンプトを提供する必要はありません。入力画像のみを提供すれば、モデルはBOS(シーケンスの先頭)トークンからテキストを生成し、キャプションを作成します。
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"キャンプファイヤーの周りに座っている2匹の漫画のモンスター"これは、New Yorkerスタイルの漫画ではトレーニングされていないモデルにとって、驚くほど正確な説明です!
プロンプト付き画像キャプショニング
テキストプロンプトを提供することで、画像キャプショニングを拡張することができます。モデルは画像を与えられたテキストプロンプトに続けて生成を続けます。
prompt = "これは漫画です。"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"キャンプファイヤーの周りに座っている2匹のモンスター"
prompt = "彼らは楽しそうに見える"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"楽しい時間を過ごしている"ビジュアル質問応答
ビジュアル質問応答では、プロンプトは特定の形式に従う必要があります。「Question: {} Answer:」
prompt = "Question: 恐竜は何を持っていますか? Answer:"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
"トーチ"チャットベースのプロンプティング
最後に、生成された応答を会話に連結することで、ChatGPTのようなインターフェースを作成することができます。テキスト(例:「恐竜は何を持っていますか?」)でモデルにプロンプトを与えると、モデルはそれに対する回答を生成します(「トーチ」)。これを会話に連結することで、コンテキストを構築していきます。ただし、コンテキストがBLIP-2(OPTおよびT5が使用する言語モデル)のコンテキスト長である512トークンを超えないように注意してください。
context = [
("恐竜は何を持っていますか?", "トーチ"),
("それらはどこにいますか?", "森の中です。")
]
question = "何のためですか?"
template = "Question: {} Answer: {}."
prompt = " ".join([template.format(context[i][0], context[i][1]) for i in range(len(context))]) + " Question: " + question + " Answer:"
print(prompt)
Question: 恐竜は何を持っていますか? Answer: トーチ. Question: それらはどこにいますか? Answer: 森の中です.. Question: 何のためですか? Answer:
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
火をつけるためです。結論
BLIP-2は、画像とテキストのプロンプトを使用した複数の画像からテキストへのタスクに使用できるゼロショットのビジュアル言語モデルです。これは、例が少ない場合に特に効果的で効率的なアプローチです。
このモデルは、事前学習モデルの間にトランスフォーマーを追加することで、ビジョンと自然言語のモダリティのギャップを埋めるものです。新しい事前学習パラダイムにより、このモデルは個々のモダリティの進化に追いつくことができます。
さまざまなビジョン言語タスクのBLIP-2モデルをファインチューニングする方法を学びたい場合は、SalesforceのLAVISライブラリをチェックして、モデルトレーニングの包括的なサポートを利用してください。
BLIP-2のデモを試すには、Hugging Face Spacesのデモをご覧ください。
謝辞
BLIP-2の開発に取り組んだSalesforce Researchチーム、BLIP-2を🤗 Transformersに追加したNiels Rogge、およびこのブログ記事のレビューを行ったOmar Sansevieroに多くの感謝を申し上げます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






