「あなたのデータは(ついに)クラウドにありますそして、オンプレミスでの行動をやめてください」
Your data is now in the cloud, so please stop actions on-premises.
モダンなデータスタックは、単に大規模なスケールでなく、異なる方法で作業を行うことを可能にします。それを活用しましょう。

あなたがほとんどのキャリアでハンマーと釘で家を建ててきたと想像してください。そして私がネイルガンをあなたに与えました。しかし、それを木に押し当ててトリガーを引くのではなく、横にしてハンマーのようにネイルを打つようにしました。
おそらくそれは高価で効果的ではないと思うでしょうし、現場の検査官はそれを安全上の危険と見なすでしょう。
それは、モダンなツールを使っているが、古い考え方やプロセスを持っているからです。そして、このたとえは、オンプレミスからモダンなデータスタックに移行した後、一部のデータチームがどのように運営しているかを完全に表現しているわけではありませんが、近いものです。
チームはすぐに、ハイパーエラスティックなコンピュートとストレージサービスが、以前に聞いたことのないボリュームと速度でさまざまなデータタイプを処理できることを理解しますが、クラウドのワークフローへの影響を常に理解しているわけではありません。
- 「ChatGPTのコードインタプリタをデータサイエンスに活用する5つの方法」
- プロンプトエンジニアリング:検索強化生成(RAG)
- Google AIのAdaTapeは、Transformerベースのアーキテクチャを持つ新しいAIアプローチです
したがって、最近移行したデータチームにとって、もっと良いたとえは、私があなたに1,000のネイルガンを与え、それらをすべて横にして同時に1,000本のネイルを打つのを見ているようなものかもしれません。
とにかく、重要なことは、モダンなデータスタックが単にデータをより大きく、より速く保存および処理するだけでなく、新しい目標を達成し、異なるタイプの価値を抽出するためにデータを基本的に異なる方法で処理できるようにするということです。
これは、スケールとスピードの増加による部分もありますが、より豊かなメタデータとエコシステム全体でのシームレスな統合の結果でもあります。
この記事では、クラウド上でデータチームが行動を変えるより一般的な方法のうち、3つを紹介します。また、変えるべきであるが変えていない方法についても5つ紹介します。さあ、深く掘り下げましょう。
クラウドで変わったデータチームの3つの方法
データチームがモダンなデータスタックに移行する理由はいくつかあります(CFOが予算を解放したこと以上の理由です)。これらのユースケースは、データチームがクラウドに入った後、最初で最も簡単な行動の変化です。それらは次のとおりです:
ETLからELTへの移行による洞察までの時間の短縮
オンプレミスのデータベースには何でもロードすることはできません。特に週末にクエリが返る前に。その結果、これらのデータチームは、データを選択し、Pythonでパイプラインを介して最終状態に変換する方法を慎重に考える必要があります。
それは、データの消費者ごとに特定の料理を注文することと同じであり、クルーズ船に乗ったことがある人なら誰でもわかるように、組織全体にわたるデータへの飽くなき需要を満たすためには、ビュッフェが最適です。
これは、AutoTrader UKのテクニカルリードであるEdward Kent氏の場合でした。彼は昨年、データの信頼性とセルフサービス分析への需要について私のチームと話しました。
「私たちは、AutoTraderとその顧客がデータに基づいた意思決定を行い、データへのアクセスを民主化するためのセルフサーブプラットフォームを提供したいと考えています…私たちは信頼されたオンプレミスシステムをクラウドに移行しているため、古いシステムのユーザーは、過去に使用していた古いシステムと同じくらい信頼性のある新しいクラウドベースのテクノロジーを信頼する必要があります」と彼は言いました。
データチームがモダンなデータスタックに移行すると、Fivetranのような自動化されたインジェスチョンツールや、dbtやSparkのような変換ツールを喜んで採用し、より洗練されたデータキュレーション戦略と共に分析のセルフサービスを採用します。分析のセルフサービスは、データモデリングを誰が担当すべきかが常に明確ではないですが、全体としては分析(およびその他の)ユースケースに対処するより効率的な方法です。
運用上の意思決定のためのリアルタイムデータ
現代のデータスタックでは、データは十分な速さで移動するため、それを日次のメトリックパルスチェックのために予約する必要はありません。データチームはDelta liveテーブル、Snowpark、Kafka、Kinesis、マイクロバッチングなどを活用することができます。
リアルタイムデータを使用するケースを持つチームはすでにその存在を認識していることが多いです。これらは通常、運用サポートを必要とする物流業務のある企業や、製品に統合された強力なレポーティングを持つテクノロジー企業です(ただし、後者の多くはクラウドで生まれたものです)。
もちろん、まだ課題も存在します。これには、並行して実行されるアーキテクチャ(分析バッチとリアルタイムストリーム)や、ほとんどの人が望む程度の品質管理レベルに到達しようとすることが含まれることもあります。しかし、ほとんどのデータリーダーは、リアルタイムの運用上の意思決定をより直接的にサポートできるという価値をすぐに理解します。
生成型AIと機械学習
データチームはGenAIの波に非常に敏感であり、多くの業界ウォッチャーはこの新興技術がインフラの近代化と活用の大きな波を引き起こしていると考えています。
ただし、ChatGPTが最初のエッセイを生成する前から、機械学習の応用はメディア、電子商取引、広告などのデータ集中型産業で、徐々に先端技術から標準的なベストプラクティスへ移行してきました。
今日では、多くのデータチームはスケーラブルなストレージとコンピューティングが利用可能になった瞬間から、これらのユースケースをすぐに検討し始めます(ただし、より良い基盤の構築が必要な場合もあります)。
最近クラウドに移行し、これらのユースケースがビジネスをどのようにサポートできるかをまだ尋ねていない場合は、カレンダーに予定を入れてください。今週中に。または今日中に。後で感謝されることでしょう。
データチームがまだオンプレミスのように振る舞う5つの方法
それでは、かつてオンプレミスで動作していたデータチームが利用しきれていない可能性のある機会のいくつかを見てみましょう。
補足情報:私の前の比喩は少しユーモラスでしたが、まだオンプレミスで動作しているチームや以下のプロセスを使用してクラウドで動作しているチームをからかっているわけではありません。変化は難しいものです。特に、常にバックログと増加する需要に直面している場合はさらに困難です。
データテスト
オンプレミスで動作しているデータチームは、中央のクエリログや現代のテーブル形式からの豊富なメタデータやスケールの利点を持っていないため、機械学習に基づいた異常検出(つまりデータの可視化)を簡単に実行することはできません。
その代わりに、彼らはドメインチームと協力してデータ品質の要件を理解し、それらをSQLルールまたはデータテストに変換します。たとえば、customer_idはNULLにならないはずであり、currency_conversionには負の値があってはなりません。このプロセスを加速し管理するためのオンプレミスベースのツールがあります。
これらのデータチームがクラウドに移行すると、データ品質を異なる方法でアプローチするのではなく、クラウドスケールでデータテストを実行することが最初の考えになります。彼らが知っている方法です。
私は、数百のパイプライン全体でデータ品質を監視するために、データエンジニアリングチームが何千ものDAGを介して数百万のタスクを実行しているというホラーストーリーのような事例を目にしたことがあります。おっと!
50万のデータテストを実行するとどうなるか、教えましょう。たとえ大多数が合格したとしても、まだ数万のテストが失敗します。そして、明日も同じように失敗します。なぜなら、原因究明を迅速に進めたり、トリアージを開始したりするための文脈がないからです。
チームに警告の疲労を引き起こし、まだ必要なカバレッジレベルに到達していないことを考えると、困難です。さらに、広範なデータテストは時間とコストがかかります。
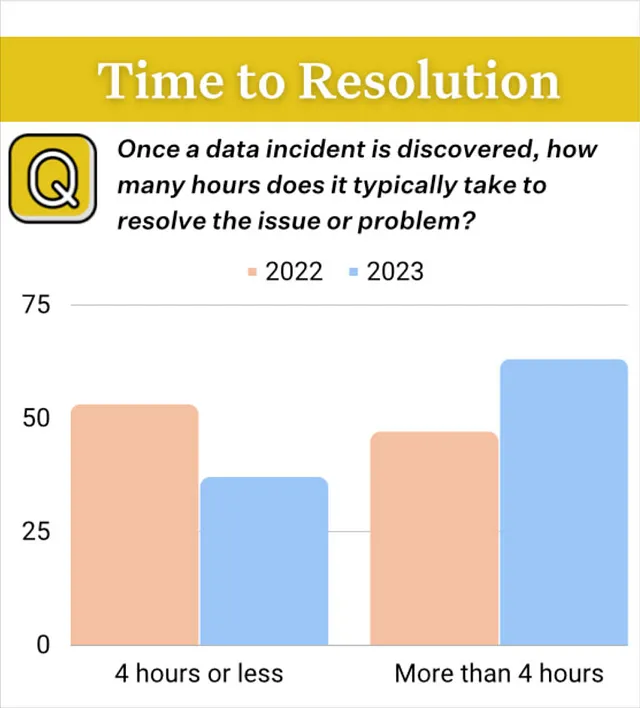
代わりに、データチームは、潜在的な問題を検出し、トリアージし、RCAを支援できる技術を活用するべきです。データテスト(またはカスタムモニター)は、最も使用されるテーブル内の最も重要な値に対してのみ最も明確なしきい値に予約するべきです。
データラインナップのためのデータモデリング
中央のデータモデルをサポートする多くの正当な理由がありますし、素晴らしいチャッド・サンダーソンの投稿ですべてを読んだことでしょう。
しかし、クラウド上のデータチームでは、データの系譜を維持し理解するために、かなりの時間とリソースを投資してデータモデルを維持していることがあります。オンプレミスの場合、それが最善の方法です。長いSQLコードを読んだり、フラッシュカードと糸でいっぱいのコルクボードを作ったりすることが好きでない限り、あなたのパートナーはあなたが大丈夫かどうか尋ねることでしょう。

(「いや、リオール!大丈夫じゃないよ、このWHERE句がこのJOINに含まれる列をどう変えるのか理解しようとしているんだよ!」)
データカタログ、データ観察プラットフォーム、データリポジトリなど、モダンなデータスタック内の複数のツールは、メタデータを利用して自動的なデータの系譜を作成することができます。それは単なる好みの問題です。
顧客セグメンテーション
従来の世界では、顧客のビューは平面的であり、本当は360度のグローバルなビューであるべきです。
この制約された顧客ビューは、事前モデル化されたデータ(ETL)、実験の制約、オンプレミスのデータベースでより洗練されたクエリ(ユニークカウント、異なる値)を大きなデータセット上で計算するために必要な時間の長さの結果です。
残念なことに、データチームはクラウドに移行した後も、その制約が取り除かれた後に顧客レンズから目を覚まさないことがあります。これにはいくつかの理由があることがよくありますが、最も大きな原因は、従来のデータのサイロです。
マーケティングチームが運営する顧客データプラットフォームはまだ生きています。そのチームは、ワウスやレイクハウスに保存されている他のドメインのデータから見込み客や顧客のビューを豊かにすることができますが、キャンペーン管理の数年間にわたる習慣と所有感は破るのが難しいです。
そのため、最高の見込み顧客の基づいてターゲティングする代わりに、リードあたりのコストやクリックあたりのコストを目指すことになります。これは、データチームが組織に直接かつ非常に目に見える方法で価値を提供する機会を逃すことになります。
外部データのエクスポートと共有
データのコピーとエクスポートは最悪です。時間がかかり、コストがかかり、バージョン管理の問題を引き起こし、アクセス制御をほとんど不可能にします。
典型的なパートナーにデータを高速にエクスポートするために、モダンなデータスタックを活用する代わりに、クラウド上のより多くのデータチームはゼロコピーのデータ共有を活用すべきです。クラウドファイルの許可設定を管理するのと同様に、ゼロコピーのデータ共有は、ホスト環境からデータを移動することなくデータにアクセスすることができます。
SnowflakeとDatabricksの両社は、過去2年間にわたり、データ共有技術を発表し、重要な特徴として取り上げています。もっと多くのデータチームがこれを活用する必要があります。
コストとパフォーマンスの最適化
オンプレミスのシステム内では、データベース管理者が全体のパフォーマンスに影響を与える可能性のあるすべての変数を監視し、必要に応じて規制する役割があります。
一方、モダンなデータスタックでは、次の2つの極端なケースがよく見られます。
いくつかの場合では、DBAの役割が残っているか、中央のデータプラットフォームチームに委託されていますが、適切に管理されないとボトルネックを引き起こすことがあります。しかし、より一般的なのは、コストやパフォーマンスの最適化がワイルドウエスト化し、特に目を見開いてしまうような請求書がCFOの机に届くまで放置されることです。
これは、データチームが適切なコストモニタを持っていない場合や、特に激しい外れ値イベント(たとえば、悪いコードや爆発するJOIN)が発生した場合によく起こります。
さらに、一部のデータチームは「使用量に応じて支払う」というモデルを十分に活用せず、あらかじめ決められたクレジット額(通常は割引価格)にコミットすることを選択します…そしてそれを超えます。クレジットコミット契約には何も問題はありませんが、その余地があると悪い習慣が生まれ、注意を払わない限り時間の経過とともに蓄積される可能性があります。
クラウドはDevOps/DataOpsにおいてより連続的で協力的かつ統合的なアプローチを促進し、FinOpsにおいても同様です。モダンなデータスタック内でコストの最適化に最も成功しているチームは、それを日常のワークフローの一部とし、コストに最も近い人々にインセンティブを与えるチームです。
「消費ベースの価格設定の台頭により、新しい機能のリリースはコストを指数関数的に増加させる可能性があります」とTenableのTom Milner氏は述べています。「私のチームのマネージャーとして、私はSnowflakeのコストを毎日チェックし、スパイクをバックログの優先事項にします。」
これにより、フィードバックループ、共有の学び、そして数千もの小さな、素早い修正が生まれ、大きな結果を生み出します。
「私たちは、$1以上の費用がかかるクエリを誰かが行った場合にアラートを設定しています。これは非常に低いしきい値ですが、それ以上の費用がかかる必要はないことがわかっています。これは良いフィードバックループだとわかりました。[このアラートが発生するとき]、パーティション化された列やクラスタ化された列にフィルタを忘れていることがよくあり、彼らはすぐに学ぶことができます」とAivenのStijn Zanders氏は述べています。
最後に、クラウドの前には考えられなかったチーム間でのチャージバックモデルの展開は、複雑ながらも最終的には価値のある取り組みであり、私はもっと多くのデータチームが評価することを望んでいます。
学ぶことを大切にする
MicrosoftのCEOであるSatya Nadella氏は、企業の組織文化を意図的に「知っている人々」から「学んでいる人々」に変えたことについて話しています。これは、データリーダーにとって最良のアドバイスであり、移行したばかりであれ、データの現代化の最先端にいる場合であれ、同じです。
私は、どれだけ圧倒されるかを理解しています。新しいテクノロジーが次々に登場し、それを売り込むベンダーからの呼びかけも激しくなっています。最終的には、業界で「最もモダンな」データスタックを持つことではなく、現代のツール、トップの才能、そしてベストプラクティスの間に調和を生み出すことが重要になります。
そのためには、同じような課題に取り組んでいる仲間がどのように取り組んでいるかを常に学ぶ準備をしておく必要があります。ソーシャルメディアで関わり、VoAGIを読み、アナリストをフォローし、カンファレンスに参加してください。そこで会いましょう!
クラウド上ではもはや意味のない他のオンプレミスのデータエンジニアリング活動については、コメントや質問はLinkedInのBarrさんにお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
