はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
Yes, Transformers are effective for time series prediction (+Autoformer).
![]()
イントロダクション
数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。
まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。
さあ、始めましょう!
- Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
- 私たちの新しいコンテンツガイドラインとポリシーをお知らせします
- Hugging Face SpacesでLivebookノートブックをアプリとしてデプロイする
ベンチマーキング – Transformers vs. DLinear
最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。
上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。
次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。
要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。
Autoformer – 内部構造
Autoformerは、時系列を季節性とトレンドサイクルの要素に分解する従来の手法に基づいて構築されています。これは、Decomposition Layerを組み込むことでこれらの要素を正確に捉える能力を向上させます。さらに、Autoformerは、通常のセルフアテンションではなく、パフォーマンスを向上させるために周期ベースの依存性を利用する革新的な自己相関メカニズムを導入しています。
次のセクションでは、Autoformerの2つの主要な貢献であるDecomposition LayerとAttention(Autocorrelation)Mechanismについて詳しく説明します。また、これらのコンポーネントがAutoformerのアーキテクチャ内でどのように機能するかを示すコード例も提供します。
Decomposition Layer
Decompositionは、時系列解析で長い間人気のある手法ですが、Autoformer論文の導入まで、深層学習モデルに広く組み込まれていませんでした。このコンセプトの簡単な説明に続いて、PyTorchコードを使用してAutoformerでのアイデアの適用方法を示します。
時系列の分解
時系列解析では、分解は時系列をトレンドサイクル、季節変動、ランダムな変動の3つのシステム要素に分解する方法です。トレンド成分は時系列の長期的な方向を表し、時間の経過に伴って増加、減少、または安定することがあります。季節成分は、年次や四半期のような周期的なパターンを表します。最後に、ランダム(時には「不規則」とも呼ばれる)成分は、トレンドまたは季節成分によって説明できないデータのランダムなノイズを表します。
分解の主なタイプは加法分解と乗法分解であり、これらは優れたstatsmodelsライブラリで実装されています。これらの要素に時系列を分解することで、データの基になるパターンをよりよく理解し、モデル化することができます。
しかし、Transformerのアーキテクチャに分解を組み込む方法はどのようになるのでしょうか?Autoformerがそれを行う方法を見てみましょう。
Autoformerにおける分解
Autoformerは、モデルの内部操作として分解ブロックを組み込みます。上のAutoformerのアーキテクチャに示されているように、エンコーダとデコーダは分解ブロックを使用して系列からトレンドサイクル部分を集約し、季節的な部分を抽出します。内部分解の概念は、Autoformerの発表以来、その有用性が示されています。その後、FEDformer(Zhou、Tian、他、ICML 2022)やDLinear(Zeng、Ailing、他、AAAI 2023)など、他のいくつかの時系列の論文でも採用され、時系列モデリングにおけるその重要性が強調されています。
では、分解層を形式的に定義しましょう:
長さ L の入力系列 X ∈ R L × d \mathcal{X} \in \mathbb{R}^{L \times d} X ∈ R L × d に対して、分解層は X trend , X seasonal \mathcal{X}_\textrm{trend}, \mathcal{X}_\textrm{seasonal} X trend , X seasonal として定義されます:
X trend = AvgPool(Padding( X )) X seasonal = X − X trend \mathcal{X}_\textrm{trend} = \textrm{AvgPool(Padding(} \mathcal{X} \textrm{))} \\ \mathcal{X}_\textrm{seasonal} = \mathcal{X} – \mathcal{X}_\textrm{trend} X trend = AvgPool(Padding( X )) X seasonal = X − X trend
そして、PyTorchでの実装は次のようになります:
import torch
from torch import nn
class DecompositionLayer(nn.Module):
"""
時系列のトレンドと季節部分を返します。
"""
def __init__(self, kernel_size):
super().__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=1, padding=0) # 移動平均
def forward(self, x):
"""Input shape: Batch x Time x EMBED_DIM"""
# 時系列の両端にパディングを追加
num_of_pads = (self.kernel_size - 1) // 2
front = x[:, 0:1, :].repeat(1, num_of_pads, 1)
end = x[:, -1:, :].repeat(1, num_of_pads, 1)
x_padded = torch.cat([front, x, end], dim=1)
# 系列のトレンドと季節部分を計算
x_trend = self.avg(x_padded.permute(0, 2, 1)).permute(0, 2, 1)
x_seasonal = x - x_trend
return x_seasonal, x_trendご覧のように、実装は非常にシンプルで、DLinearなどの他のモデルでも使用できます。次に、2番目の貢献である注意(自己相関)メカニズムを説明します。
注意(自己相関)メカニズム
分解層に加えて、Autoformerは自己相関を無理なく置き換える革新的な自己相関メカニズムを使用しています。通常の時系列Transformerでは、注意の重みは時間領域で計算され、要素ごとに集約されます。一方、上の図に示されているように、Autoformerでは周波数領域(高速フーリエ変換を使用)で計算し、時間遅延ごとに集約します。
次のセクションでは、これらのトピックを詳しく掘り下げ、コード例で説明します。
周波数領域の注意
理論的には、時差 τ \tau τ に対して、単一の離散変数 y y y の自己相関は、変数の現在の値 y t y_t y t とその過去の値 y t − τ y_{t-\tau} y t − τ の「関係」(ピアソン相関)を測定するために使用されます:
自己相関 ( τ ) = 相関 ( y t , y t − τ ) \textrm{自己相関}(\tau) = \textrm{相関}(y_t, y_{t-\tau}) 自己相関 ( τ ) = 相関 ( y t , y t − τ )
オートコリレーションを使用することで、Autoformerはクエリとキーから周波数ベースの依存関係を抽出します。これは、自己注意の中のQKT(QK^T)の代わりとして考えることができます。
実際には、クエリとキーのオートコリレーションは、FFTによって一度にすべての遅延で計算されます。これにより、オートコリレーションメカニズムはO(L log L)の時間計算量(ここでLは入力時間長です)を達成します。これは、InformerのProbSparse attentionと同様です。なお、FFTを使用してオートコリレーションを計算する理論は、このブログ記事の範囲外であるウィーナー・キンチンの定理に基づいています。
それでは、PyTorchのコードを見てみましょう:
import torch
def autocorrelation(query_states, key_states):
"""
`torch.fft`を使用して自己相関(Q,K)を計算します。
自己注意の中のQK^Tの代わりとして考えてください。
前提条件:状態は[バッチサイズ、時間長、埋め込み次元]の同じ形にリサイズされているものとします。
"""
query_states_fft = torch.fft.rfft(query_states, dim=1)
key_states_fft = torch.fft.rfft(key_states, dim=1)
attn_weights = query_states_fft * torch.conj(key_states_fft)
attn_weights = torch.fft.irfft(attn_weights, dim=1)
return attn_weights非常にシンプルです! 😎 ただし、これはautocorrelation(Q,K)の部分的な実装であり、完全な実装は🤗 Transformersで見つけることができます。
次に、attn_weightsを時間遅延によって値と結合する方法である「タイムディレイ集約」を見てみましょう。
タイムディレイ集約
オートコリレーション(attn_weightsとも呼ばれる)をRQ,Kとします。この場合、RQ,K(τ1)、RQ,K(τ2)、…、RQ,K(τk)をVとどのように結合するのでしょうか?通常の自己注意機構では、この結合はドット積によって行われます。しかし、Autoformerでは異なるアプローチを採用しています。まず、Vを時間遅延τ1、τ2、…τkに対して値を計算することで整列します(これはローリングとも呼ばれます)。次に、整列されたVとオートコリレーションの要素ごとの乗算を行います。提供された図では、左側にはVの時間遅延によるローリングが示され、右側にはオートコリレーションとの要素ごとの乗算が示されています。
次の方程式でまとめることができます:
τ1、τ2、…、τk = arg Top-k(RQ,K(τ))
R̂Q,K(τ1)、R̂Q,K(τ2)、…、R̂Q,K(τk) = Softmax(RQ,K(τ1)、RQ,K(τ2)、…、RQ,K(τk))
オートコリレーション-アテンション = ∑i=1k Roll(V, τi) ⋅ R̂Q,K(τi)
以上です!k k k は autocorrelation_factor というハイパーパラメータで制御されています(Informer の sampling_factor に似ています)。乗算前には softmax が自己相関に適用されます。
さて、最終的なコードを見てみましょう:
import torch
import math
def time_delay_aggregation(attn_weights, value_states, autocorrelation_factor=2):
"""
value_states.roll(delay) * top_k_autocorrelations(delay) として集約を計算します。
最終結果は自己相関アテンションの出力です。
attn_weights と value_states の形状は [batch_size, time_length, embedding_dim] を想定しています。
"""
bsz, num_heads, tgt_len, channel = ...
time_length = value_states.size(1)
autocorrelations = attn_weights.view(bsz, num_heads, tgt_len, channel)
# 上位 k 個の自己相関遅延を見つける
top_k = int(autocorrelation_factor * math.log(time_length))
autocorrelations_mean = torch.mean(autocorrelations, dim=(1, -1)) # bsz x tgt_len
top_k_autocorrelations, top_k_delays = torch.topk(autocorrelations_mean, top_k, dim=1)
# チャネル次元に softmax を適用する
top_k_autocorrelations = torch.softmax(top_k_autocorrelations, dim=-1) # bsz x top_k
# 集約を計算する: value_states.roll(delay) * top_k_autocorrelations(delay)
delays_agg = torch.zeros_like(value_states).float() # bsz x time_length x channel
for i in range(top_k):
value_states_roll_delay = value_states.roll(shifts=-int(top_k_delays[i]), dims=1)
top_k_at_delay = top_k_autocorrelations[:, i]
# 集約
top_k_resized = top_k_at_delay.view(-1, 1, 1).repeat(num_heads, tgt_len, channel)
delays_agg += value_states_roll_delay * top_k_resized
attn_output = delays_agg.contiguous()
return attn_output<pやりました!Autoformer モデルは現在 🤗 Transformers ライブラリで利用可能で、AutoformerModel と呼ばれています。
このモデルの戦略は、単変量 Transformer モデルのパフォーマンスを DLinear モデルと比較することで示すことです。DLinear モデルは本質的に単変量であり、次に示すように同じデータでトレーニングされた2つの多変量 Transformer モデルの結果も提示します。
DLinear – 内部動作
DLinear は概念的には非常にシンプルです。Autoformer の DecompositionLayer を使用した完全に接続された層です。入力の時系列データを残差(季節性)とトレンドの部分に分解するために DecompositionLayer を使用します。順方向パスでは、それぞれの部分は独自の線形層を通過し、シグナルを適切な prediction_length サイズの出力に射影します。最終的な出力は、ポイント予測モデルの2つの対応する出力の合計です:
def forward(self, context):
seasonal, trend = self.decomposition(context)
seasonal_output = self.linear_seasonal(seasonal)
trend_output = self.linear_trend(trend)
return seasonal_output + trend_output<p確率的な設定では、linear_seasonal と linear_trend のレイヤーを介してコンテキスト長の配列を prediction_length * hidden 次元に射影することができます。生成された出力は加算され、(prediction_length, hidden) の形に再形成されます。最後に、確率的なヘッドはサイズ hidden の潜在表現をいくつかの分布のパラメータにマッピングします。
<pベンチマークでは、GluonTS からの DLinear の実装を使用しています。
例:トラフィックデータセット
ライブラリ内の Transformer ベースのモデルのパフォーマンスを実証するため、862 の時系列データを持つ traffic データセットでベンチマークを行います。各個別の時系列データに対して共有モデルをトレーニングします(つまり、単変量設定)。各時系列データはセンサーの占有値を表し、範囲は [0, 1] です。以下のハイパーパラメータをすべてのモデルで固定します:
# Traffic prediction_length is 24. Reference:
# https://github.com/awslabs/gluonts/blob/6605ab1278b6bf92d5e47343efcf0d22bc50b2ec/src/gluonts/dataset/repository/_lstnet.py#L105
prediction_length = 24
context_length = prediction_length*2
batch_size = 128
num_batches_per_epoch = 100
epochs = 50
scaling = "std"トラフィック予測の長さは24です。参考:
https://github.com/awslabs/gluonts/blob/6605ab1278b6bf92d5e47343efcf0d22bc50b2ec/src/gluonts/dataset/repository/_lstnet.py#L105
prediction_length = 24
context_length = prediction_length*2
batch_size = 128
num_batches_per_epoch = 100
epochs = 50
scaling = “std”
トランスフォーマーモデルはすべて比較的小さいです:
encoder_layers=2
decoder_layers=2
d_model=16Autoformerを使用してモデルをトレーニングする方法を示す代わりに、この前の2つのブログ記事(TimeSeriesTransformerとInformer)で使われていたモデルを新しいAutoformerモデルに置き換えて、trafficデータセットでトレーニングすることができます。同じことを繰り返さないように、モデルは既にトレーニングされ、HuggingFace Hubにプッシュされています。評価にはそれらのモデルを使用します。
データセットの読み込み
まず必要なライブラリをインストールしましょう:
!pip install -q transformers datasets evaluate accelerate "gluonts[torch]" ujson tqdmLai et al. (2017)によって使用されたtrafficデータセットは、サンフランシスコの交通データを含んでいます。2015年から2016年までのサンフランシスコベイエリアの高速道路の1時間ごとの道路占有率を示す862の時系列データが含まれています。
from gluonts.dataset.repository.datasets import get_dataset
dataset = get_dataset("traffic")
freq = dataset.metadata.freq
prediction_length = dataset.metadata.prediction_lengthデータセット内の時系列を可視化し、トレイン/テストの分割をプロットしましょう:
import matplotlib.pyplot as plt
train_example = next(iter(dataset.train))
test_example = next(iter(dataset.test))
num_of_samples = 4*prediction_length
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
test_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()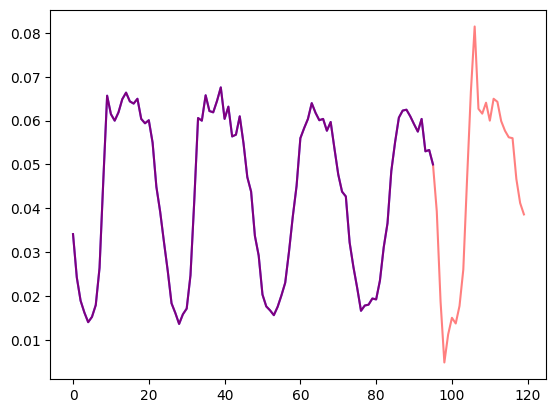
トレイン/テストの分割を定義しましょう:
train_dataset = dataset.train
test_dataset = dataset.test変換の定義
次に、データの変換を定義します。特に、時系列特徴の作成のための変換を定義します(データセットに基づくものまたは共通のもの)。
GluonTSのChainを使用して(画像のtorchvision.transforms.Composeに似ている)、複数の変換を1つのパイプラインに組み合わせることができます。
以下の変換にはコメントが付いており、それぞれの役割を説明しています。大まかに言えば、データセットの各時系列を反復処理し、フィールドや特徴の追加/削除を行います:
from transformers import PretrainedConfig
from gluonts.time_feature import time_features_from_frequency_str
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# 削除するフィールドのリストを作成する
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# ステップ1: 指定されていない場合は静的/動的フィールドを削除する
[RemoveFields(field_names=remove_field_names)]
# ステップ2: データをNumPyに変換する(必要な場合はしなくても良い)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# 多変量の場合は追加の次元が必要です:
expected_ndim=1 if config.input_size == 1 else 2,
),
# ステップ3: NaNを0で埋めてターゲットにマスクを返す
# 観測値に対してはtrue、NaNに対してはfalse
# デコーダーはこのマスクを使用します(観測されていない値には損失が発生しません)
# xxxForPredictionモデルの内部のloss_weightsを参照してください
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# ステップ4: データセットの周波数に基づいて時間特徴を追加する
# これらは位置符号化として機能します
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# ステップ5: 別の時間特徴を追加する(単一の数値のみ)
# 時系列の値がライフのどこにあるかをモデルに伝えます
# 種類の実行カウンターのようなものです
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# ステップ6: すべての時間特徴をキーFEAT_TIMEに垂直にスタックする
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# ステップ7: HuggingFaceの名前と一致するようにフィールドの名前を変更する
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)インスタンス分割器(InstanceSplitter)の定義
次に、トレーニング/検証/テストのためにデータセットからウィンドウをサンプリングするために、InstanceSplitterを作成します(時間とメモリの制約により、全ての値の履歴をモデルに渡すことはできません)。
インスタンス分割器は、データからランダムにcontext_lengthのサイズと続くprediction_lengthのサイズのウィンドウをサンプリングし、対応するウィンドウの一時キーにpast_またはfuture_のキーを追加します。これにより、valuesはpast_valuesと続くfuture_valuesのキーに分割され、それぞれがエンコーダーとデコーダーの入力として機能します。同様のことがtime_series_fields引数のキーに対しても行われます:
from gluonts.transform import InstanceSplitter
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)PyTorchのDataLoaderの作成
次に、(入力、出力)のペアであるバッチ( past_values , future_values )を持つことができるPyTorchのDataLoaderを作成します。
from typing import Iterable
import torch
from gluonts.itertools import Cyclic, Cached
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# トレーニングインスタンスを初期化します
instance_splitter = create_instance_splitter(config, "train")
# インスタンス分割器は、ターゲットの時系列から
# コンテキスト長 + ラグ + 予測長(366個の変換可能な時系列から)の
# ウィンドウをランダムにサンプリングし、イテレータを返します。
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream, is_train=True)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# テストインスタンス分割器を作成し、エンコーダーのみで
# トレーニング中に最後に見たコンテキストウィンドウをサンプリングします。
instance_sampler = create_instance_splitter(config, "test")
# テストモードで変換を適用します
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)Autoformerでの評価
すでにこのデータセットでAutoformerモデルの事前学習を行っているため、モデルを取得してテストセットで評価することができます:
from transformers import AutoformerConfig, AutoformerForPrediction
config = AutoformerConfig.from_pretrained("kashif/autoformer-traffic-hourly")
model = AutoformerForPrediction.from_pretrained("kashif/autoformer-traffic-hourly")
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)推論時には、モデルのgenerate()メソッドを使用して、トレーニングセットの各時系列の最後のコンテキストウィンドウからprediction_lengthステップ先を予測します。
from accelerate import Accelerator
accelerator = Accelerator()
device = accelerator.device
model.to(device)
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())モデルはテンソルを出力し、その形状は(batch_size、サンプル数、予測長、入力サイズ)です。
この場合、テストデータローダーバッチの各時系列に対して、次の24時間に対して100個の可能な値が得られます(上記の記述からおぼえていると思いますが、バッチのサイズは64です):
forecasts_[0].shape
>>> (64, 100, 24)これらを垂直に積み上げて、テストデータセットのすべての時系列に対する予測を取得します。テストセットには7つのローリングウィンドウがあるため、合計で7 * 862 = 6034個の予測が得られます:
import numpy as np
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (6034, 100, 24)テストセットのグラウンドトゥルースのアウトオブサンプル値に対して、予測結果を評価することができます。そのために、🤗 Evaluateライブラリを使用し、MASEメトリクスを含んでいます。
データセットの各時系列に対してメトリクスを計算し、平均値を返します:
from tqdm.autonotebook import tqdm
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
for item_id, ts in enumerate(tqdm(test_dataset)):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])したがって、Autoformerモデルの結果は次のとおりです:
print(f"Autoformer単変量MASE:{np.mean(mase_metrics):.3f}")
>>> Autoformer単変量MASE:0.910グラウンドトゥルーステストデータに対して、任意の時系列の予測をプロットするために、次のヘルパーを定義します:
import matplotlib.dates as mdates
import pandas as pd
test_ds = list(test_dataset)
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_ds[ts_index][FieldName.START],
periods=len(test_ds[ts_index][FieldName.TARGET]),
freq=test_ds[ts_index][FieldName.START].freq,
).to_timestamp()
ax.plot(
index[-5*prediction_length:],
test_ds[ts_index]["target"][-5*prediction_length:],
label="実際",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="中央値",
)
plt.gcf().autofmt_xdate()
plt.legend(loc="best")
plt.show()たとえば、テストセットのインデックス4の時間系列データに対して、次のようにプロットします:
plot(4)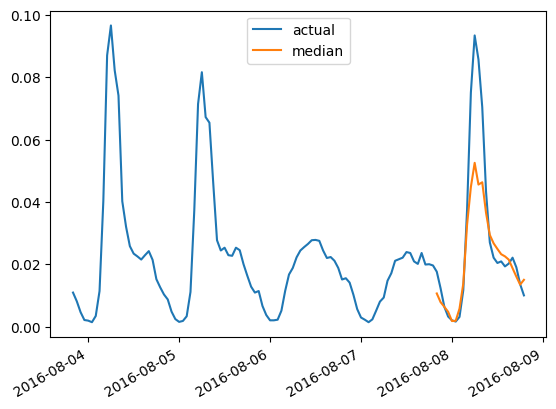
DLinearで評価する
確率的なDLinearはgluontsで実装されているため、ここでは比較的迅速にトレーニングと評価ができます:
from gluonts.torch.model.d_linear.estimator import DLinearEstimator
# Autoformerモデルと同じパラメータでDLinearモデルを定義する
estimator = DLinearEstimator(
prediction_length=dataset.metadata.prediction_length,
context_length=dataset.metadata.prediction_length*2,
scaling=scaling,
hidden_dimension=2,
batch_size=batch_size,
num_batches_per_epoch=num_batches_per_epoch,
trainer_kwargs=dict(max_epochs=epochs)
)モデルをトレーニングする:
predictor = estimator.train(
training_data=train_dataset,
cache_data=True,
shuffle_buffer_length=1024
)
>>> INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
---------------------------------------
0 | model | DLinearModel | 4.7 K
---------------------------------------
4.7 K Trainable params
0 Non-trainable params
4.7 K Total params
0.019 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]
...
INFO:pytorch_lightning.utilities.rank_zero:Epoch 49, global step 5000: 'train_loss' was not in top 1
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=50` reached.そして、テストセットで評価します:
from gluonts.evaluation import make_evaluation_predictions, Evaluator
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset.test,
predictor=predictor,
)
d_linear_forecasts = list(forecast_it)
d_linear_tss = list(ts_it)
evaluator = Evaluator()
agg_metrics, _ = evaluator(iter(d_linear_tss), iter(d_linear_forecasts))DLinearモデルの結果は次のようになります:
dlinear_mase = agg_metrics["MASE"]
print(f"DLinear MASE: {dlinear_mase:.3f}")
>>> DLinear MASE: 0.965前述のように、トレーニング済みのDLinearモデルの予測をプロットするために、次のヘルパー関数を使用します:
def plot_gluonts(index):
plt.plot(d_linear_tss[index][-4 * dataset.metadata.prediction_length:].to_timestamp(), label="target")
d_linear_forecasts[index].plot(show_label=True, color='g')
plt.legend()
plt.gcf().autofmt_xdate()
plt.show()
plot_gluonts(4)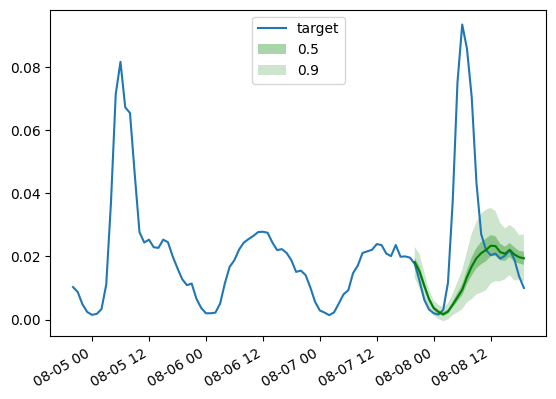
trafficデータセットは、平日と週末のセンサーパターンの分布シフトがあります。では、ここでは何が起こっているのでしょうか? DLinearモデルは共変量を組み込む能力を持っていないため、特に日付・時刻の特徴量を持たない場合、与えられたコンテキストウィンドウには週末か平日かを判断するための十分な情報がありません。したがって、モデルはより一般的なパターンである平日を予測し、週末の予測性能が低下します。もちろん、より大きなコンテキストウィンドウを与えることにより、線形モデルは週間のパターンを把握することができますが、おそらくデータには月次や四半期のパターンがあり、ますます大きなコンテキストが必要になるかもしれません。
結論
Transformerベースのモデルは、上記の線形ベースラインと比較してどのようになるのでしょうか? 以下に、さまざまなモデルのテストセットのMASEメトリクスが示されています:
観察すると、昨年紹介したバニラのTransformerモデルがここで最良の結果を出しています。第二に、多変量モデルは通常、単変量モデルよりも悪い結果となります。その理由は、クロスシリーズの相関/関係を推定する難しさです。推定値によって追加される追加の分散は、予測結果に悪影響を及ぼすか、モデルが見かけの相関を学習する可能性があります。CrossFormer(ICLR 23)やCARDなどの最近の論文は、この問題をTransformerモデルで解決しようとしています。多変量モデルは通常、大量のデータでトレーニングされた場合に良いパフォーマンスを発揮します。ただし、小規模なオープンデータセットなどの単変量モデルと比較すると、単変量モデルの方が通常はより良いメトリクスを提供します。
まとめると、タイムシリーズ予測においては、トランスフォーマーは決して時代遅れではありません!ただし、大規模なデータセットの利用可能性が彼らの潜在能力を最大限に引き出すためには重要です。CVやNLPとは異なり、タイムシリーズの分野には公開された大規模なデータセットが不足しています。現在のタイムシリーズ用の事前学習モデルのほとんどは、UCRやUEAなどのアーカイブからの小規模なサンプルサイズで訓練されており、数千個または数百個のサンプルしか含まれていません。これらのベンチマークデータセットは、タイムシリーズコミュニティの進歩において重要な役割を果たしてきましたが、限られたサンプルサイズと汎用性の欠如は、深層学習モデルの事前学習において課題を提起しています。
そのため、大規模かつ汎用的なタイムシリーズデータセット(CVのImageNetのようなもの)の開発が最も重要となります。このようなデータセットの作成により、タイムシリーズ解析に特化した事前学習モデルのさらなる研究が大幅に促進され、事前学習モデルのタイムシリーズ予測への適用性が向上します。
謝辞
このプロジェクト中に、Lysandre DebutさんとPedro Cuencaさんによる洞察に富んだコメントと助けに感謝の意を表します ❤️。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




