時系列予測のためのXGBoostの活用
XGBoost for Time Series Prediction
XGBoost(eXtreme Gradient Boosting)は、勾配ブースティング木を実装したオープンソースのアルゴリズムで、パフォーマンスと速度の向上のための追加の改善を行っています。正確な予測を迅速に行う能力があるため、このモデルはKaggleのコンペティションなど、多くの競技会でよく使用されるモデルです。
XGBoostの一般的な応用例は、詐欺検出などの分類予測や、住宅価格予測などの回帰予測です。ただし、XGBoostアルゴリズムを時系列データの予測に拡張することも可能です。どのように動作するのでしょうか?さらに探ってみましょう。
時系列予測
- Together AIがLlama-2-7B-32K-Instructを発表:拡張コンテキスト言語処理の大きな進歩
- 言語モデルの未来:ユーザーエクスペリエンスの向上のためにマルチモダリティを取り入れる
- 「AIの革命:WatsonXの力を明らかにする」
データサイエンスと機械学習における予測は、時間の経過に伴って収集された過去のデータに基づいて将来の数値を予測するための技術です。データの収集間隔は一定または不定期である場合があります。
一般的な機械学習のトレーニングデータでは、各観測値は他の観測値とは独立していますが、時系列予測のためのデータは連続した順序であり、各データポイントに関連している必要があります。たとえば、時系列データには月次株価、週次天気、日次売上などが含まれます。
ここでは、Kaggleからの例としてDaily Climateデータセットを見てみましょう。
import pandas as pd
train = pd.read_csv('DailyDelhiClimateTrain.csv')
test = pd.read_csv('DailyDelhiClimateTest.csv')
train.head()
上記のデータフレームを見ると、すべての特徴量が日次で記録されていることがわかります。日付の列はデータが観測された日付を示し、各観測値は関連しています。
時系列予測では、トレンドや季節性、その他のパターンをデータから取り込んで予測を作成することが一般的です。パターンを確認するための簡単な方法は、可視化することです。たとえば、例のデータセットから平均気温データを可視化します。
train["date"] = pd.to_datetime(train["date"])
test["date"] = pd.to_datetime(test["date"])
train = train.set_index("date")
test = test.set_index("date")
train["meantemp"].plot(style="k", figsize=(10, 5), label="train")
test["meantemp"].plot(style="b", figsize=(10, 5), label="test")
plt.title("Mean Temperature Dehli Data")
plt.legend()
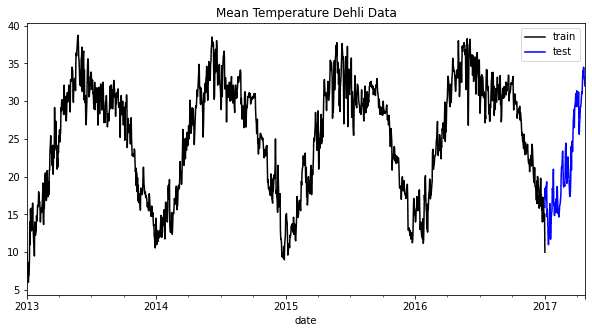
上記のグラフから、各年には共通の季節性パターンがあることが見て取れます。この情報を取り入れることで、データの動作を理解し、予測モデルに合うモデルを選択することができます。
一般的な予測モデルには、ARIMA、Vector AutoRegression、Exponential Smoothing、Prophetなどがあります。ただし、XGBoostも予測に利用することができます。
XGBoostによる予測
XGBoostを使用して予測する準備をする前に、まずパッケージをインストールする必要があります。
pip install xgboost
インストールが完了したら、モデルトレーニングのためのデータを準備します。XGBoost予測では、数値のみを含む単一または複数の特徴量に基づいて回帰モデルを実装するため、データトレーニングも数値である必要があります。また、XGBoostモデル内で時間の経過を取り込むために、時系列データを複数の数値特徴量に変換します。
まず、日付から数値特徴量を作成する関数を作成します。
def create_time_feature(df):
df['dayofmonth'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['weekofyear'] = df['date'].dt.weekofyear
return df
次に、この関数をトレーニングデータとテストデータに適用します。
train = create_time_feature(train)
test = create_time_feature(test)
train.head()
必要な情報はすべて利用可能です。次に、予測したい内容を定義します。この例では、平均気温を予測し、上記のデータに基づいてトレーニングデータを作成します。
X_train = train.drop('meantemp', axis =1)
y_train = train['meantemp']
X_test = test.drop('meantemp', axis =1)
y_test = test['meantemp']
湿度などの他の情報も使用して、XGBoostが多変量のアプローチを使用して値を予測することも示します。ただし、実際には、予測を試みる際に存在するとわかっているデータのみを組み込みます。
モデルにデータを適合させることで、トレーニングプロセスを開始しましょう。現在の例では、木の数以外のハイパーパラメータの最適化は行いません。
import xgboost as xgb
reg = xgb.XGBRegressor(n_estimators=1000)
reg.fit(X_train, y_train, verbose = False)
トレーニングプロセスの後、モデルの特徴の重要性を見てみましょう。
xgb.plot_importance(reg)
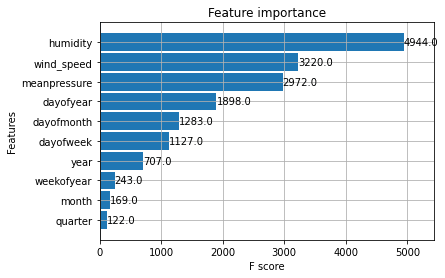
最初の3つの特徴量は予測に役立つことが予想されますが、時間の特徴量も予測に貢献しています。テストデータでの予測を試して、それらを視覚化してみましょう。
test['meantemp_Prediction'] = reg.predict(X_test)
train['meantemp'].plot(style='k', figsize=(10,5), label = 'train')
test['meantemp'].plot(style='b', figsize=(10,5), label = 'test')
test['meantemp_Prediction'].plot(style='r', figsize=(10,5), label = 'prediction')
plt.title('Mean Temperature Dehli Data')
plt.legend()
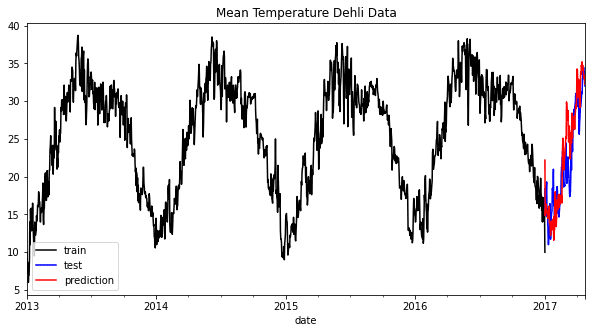
上記のグラフからわかるように、予測はわずかにずれているかもしれませんが、全体的な傾向に従っています。エラーメトリックに基づいてモデルを評価してみましょう。
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
print('RMSE: ', round(mean_squared_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAE: ', round(mean_absolute_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAPE: ', round(mean_absolute_percentage_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
RMSE: 11.514
MAE: 2.655
MAPE: 0.133
結果から、予測には約13%の誤差がある可能性があり、RMSEも予測にわずかな誤差があることが示されています。ハイパーパラメータの最適化を行うことでモデルを改善することができますが、XGBoostを使用して予測する方法を学びました。
結論
XGBoostはオープンソースのアルゴリズムであり、多くのデータサイエンスのケースやKaggleの競技でよく使用されます。よくある使用例は、詐欺検知のような一般的な分類ケースや、家の価格予測のような回帰ケースですが、XGBoostは時系列予測にも拡張することができます。XGBoostリグレッサーを使用することで、将来の数値を予測するモデルを作成することができます。Cornellius Yudha Wijayaは、データサイエンスのアシスタントマネージャー兼データライターです。Allianz Indonesiaでフルタイムで働きながら、Pythonとデータのヒントをソーシャルメディアや執筆メディアで共有することが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Pantsを使用してMachine LearningのMonorepoを整理する」
- 「AVIS内部:Googleの新しい視覚情報検索LLM」
- 「言語の壁を乗り越える:アフリカの言語のためのAIツールの推進」
- 「機械学習 vs AI vs ディープラーニング vs ニューラルネットワーク:違いは何ですか?」
- Google AIは、スケールで事前に訓練されたニューラルネットワークを剪定するための最適化ベースのアプローチ、CHITAを紹介します
- 大規模な言語モデルを使用した自律型の視覚情報検索
- 「Lineが『japanese-large-lm』をオープンソース化:36億パラメータを持つ日本語言語モデル」





