より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
Xeon上で効率的なAI体験、Q8-Chat
大規模言語モデル(LLM)は、機械学習の世界を席巻しています。Transformerアーキテクチャのおかげで、LLMはテキスト、画像、ビデオ、オーディオなどの大量の非構造化データから学習する驚異的な能力を持っています。テキスト分類のような抽出型のタスクや、テキスト要約、テキストから画像生成などの生成型のタスクでも非常に優れたパフォーマンスを発揮します。
その名前からもわかるように、LLMは一般的に100億パラメータを超える大規模なモデルです。BLOOMモデルのように1000億パラメータ以上のものもあります。LLMは、検索や対話型アプリケーションなどの低遅延のユースケースで十分に高速な予測を行うために、高性能なGPUに典型的に見られる大量の計算能力を必要とします。残念ながら、多くの組織にとっては関連するコストが高く、最先端のLLMをアプリケーションに使用することが困難になります。
この記事では、Intel CPU上で効率的に実行するために、LLMのサイズと推論レイテンシを減らす最適化技術について説明します。
量子化の基礎
通常、LLMは16ビットの浮動小数点パラメータ(FP16/BF16)でトレーニングされます。したがって、単一の重みまたはアクティベーション値の値を保存するためには2バイトのメモリが必要です。さらに、浮動小数点の演算は整数の演算よりも複雑で遅く、追加の計算能力が必要です。
- 大規模なネアデデュープリケーション:BigCodeの背後に
- Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
- 🐶セーフテンソルは、本当に安全であり、デフォルトの選択肢として採用されました
量子化は、モデルパラメータが取ることができるユニークな値の範囲を縮小することで、両方の問題を解決するモデルの圧縮技術です。たとえば、モデルを8ビット整数(INT8)のような低精度に量子化して、モデルを縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。
要するに、量子化はモデルパラメータをより小さな値範囲に再スケーリングします。成功すると、モデルのサイズが少なくとも2倍に縮小され、モデルの精度には影響しません。
量子化は、通常、トレーニング中に適用することができます。これを量子化対応トレーニング(QAT)と呼びますが、一般的に最良の結果が得られます。既存のモデルを量子化する場合は、非常に少ない計算能力を必要とする高速なテクニックであるポストトレーニング量子化(PTQ)を適用することもできます。
さまざまな量子化ツールが利用可能です。たとえば、PyTorchには量子化の組み込みサポートがあります。また、QATおよびPTQのための開発者向けのAPIを備えたHugging Face Optimum Intelライブラリを使用することもできます。
LLMの量子化
最近の研究[1][2]によると、現在の量子化技術はLLMとはうまく機能しません。特に、LLMはすべてのレイヤーとトークンで特定のアクティベーションチャネルに大きな値の外れ値を示します。以下はOPT-13Bモデルの例です。すべてのトークンで、アクティベーションの1つのチャネルが他のすべてのチャネルよりもはるかに大きな値を持っていることがわかります。この現象はモデルのすべてのTransformerレイヤーで見られます。
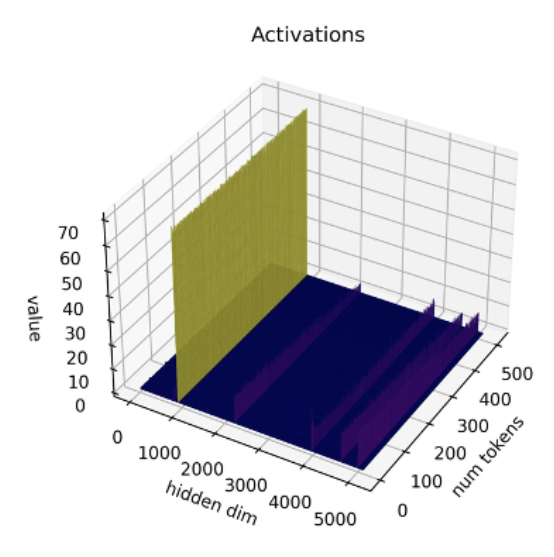 *出典: SmoothQuant*
*出典: SmoothQuant*
現在の最良の量子化技術は、トークン単位でアクティベーションを量子化し、切り捨てられた外れ値または低いマグニチュードのアクティベーションを引き起こします。いずれの解決策もモデルの品質に大きな影響を与えます。さらに、量子化対応トレーニングには追加のモデルトレーニングが必要であり、計算リソースとデータの不足のため、ほとんどの場合には実用的ではありません。
SmoothQuant[3][4]は、この問題を解決する新しい量子化技術です。それは重みとアクティベーションに共同の数学的変換を適用し、アクティベーションの外れ値と非外れ値の比率を減らすことで、Transformerのレイヤーを「量子化に適した」状態にします。これにより、モデルの品質に影響を与えずに8ビットの量子化が可能となります。その結果、SmoothQuantはIntel CPUプラットフォーム上で優れたパフォーマンスを発揮する、より小さく、高速なモデルを生成します。
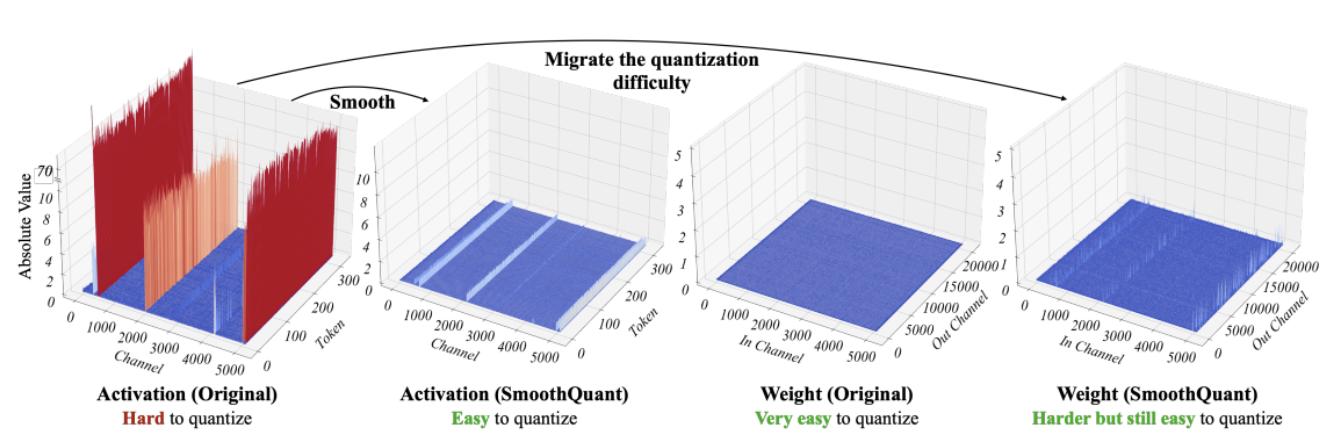 *出典: SmoothQuant*
*出典: SmoothQuant*
それでは、SmoothQuantを人気のあるLLMに適用した場合の動作を見てみましょう。
SmoothQuantを使用したLLMの量子化
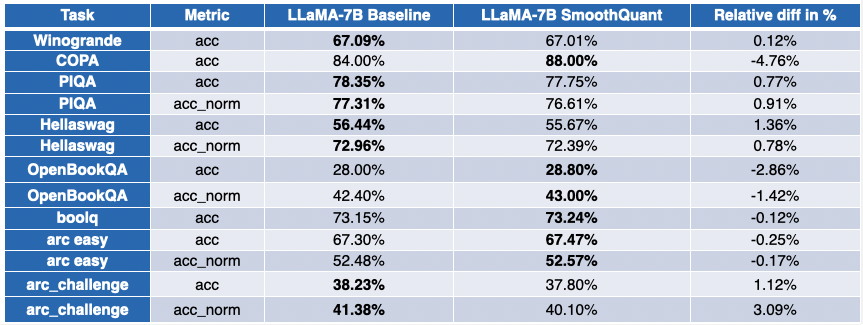
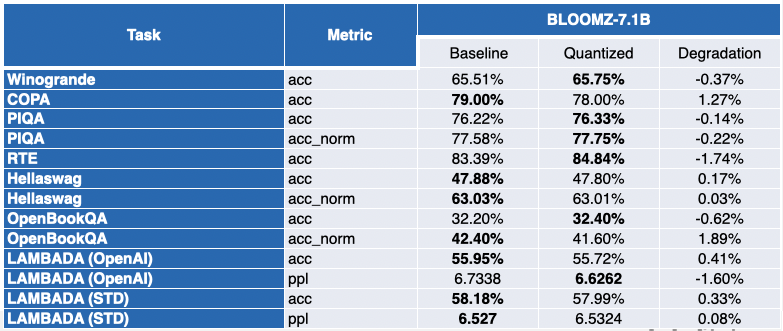
Intelのパートナーである私たちの友人は、SmoothQuant-O3を使用していくつかのLLMを量子化しました。OPT 2.7Bと6.7B [5]、LLaMA 7B [6]、Alpaca 7B [7]、Vicuna 7B [8]、BloomZ 7.1B [9]、MPT-7B-chat [10]です。また、Language Model Evaluation Harnessを使用して、量子化されたモデルの精度も評価しました。
以下の表は、彼らの調査結果の要約を示しています。2番目の列には、量子化後に改善されたベンチマークの割合が表示されます。3番目の列には、平均平均劣化が含まれています(*負の値はベンチマークが改善されたことを示します)。詳細な結果は、この投稿の最後で見つけることができます。
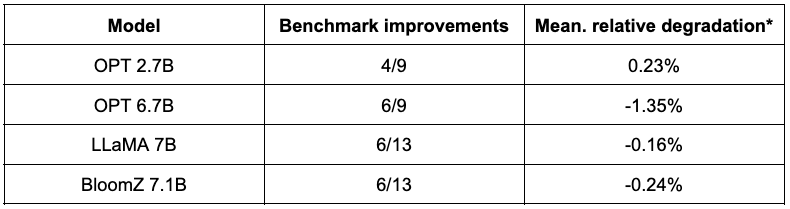
ご覧のように、OPTモデルはSmoothQuant量子化の優れた候補です。事前学習済み16ビットモデルと比較して、モデルは約2倍小さくなります。多くのメトリックが改善され、改善されなかったものもわずかにペナルティが課されています。
LLaMA 7BとBloomZ 7.1Bについては、状況はやや対照的です。モデルは約2倍圧縮され、タスクの半分がメトリックの改善を見ています。また、もう半分はわずかに影響を受け、1つのタスクは3%以上の相対的な劣化を示しています。
より小さなモデルで作業する明白な利点は、推論レイテンシの大幅な削減です。以下のビデオは、MPT-7B-chatモデルを使用してシングルソケットIntel Sapphire Rapids CPU(32コア)でバッチサイズ1でリアルタイムのテキスト生成を実演しています。
この例では、モデルに「*Hugging FaceのNLPの民主化の役割は何ですか?*」と尋ねます。これにより、以下のプロンプトがモデルに送信されます。「知識欲旺盛なユーザーと人工知能アシスタントのチャット。アシスタントはユーザーの質問に対して役立つ、詳細で丁寧な回答を提供します。ユーザー:Hugging FaceのNLPの民主化の役割は何ですか?アシスタント:」
この例は、8ビット量子化と第4世代Xeonの組み合わせによる追加の利点を示しており、各トークンの生成時間が非常に低いです。このパフォーマンスレベルは、CPUプラットフォームでLLMを実行することが確実に可能になり、お客様に従来よりも柔軟なITとコストパフォーマンスを提供します。
Xeon上でのチャット体験
HuggingFaceのCEOであるClementは最近「*より多くの企業は、トレーニングと実行コストが安いより小さな特定のモデルに焦点を当てる方が良い結果を得られるだろう*」と述べました。Alpaca、BloomZ、Vicunaなどの比較的小さいモデルの出現により、企業はファインチューニングと本番推論のコストを削減する新たな機会を得ることができます。上記のように、高品質の量子化は、Intel CPUプラットフォームで高品質のチャット体験を提供します。巨大なLLMや複雑なAIアクセラレータを必要としません。
Intelと共同で、私たちはSpacesでQ8-Chat(「キュートチャット」と発音)という新しいエキサイティングなデモを開催しています。Q8-Chatは、ChatGPTに似たチャット体験を提供しますが、シングルソケットIntel Sapphire Rapids CPU(32コア)でバッチサイズ1でのみ実行されます。
次のステップ
現在、これらの新しい量子化技術をHugging Face Optimum IntelライブラリにIntel Neural Compressorを介して統合する作業を行っています。完了したら、わずか数行のコードでこれらのデモを複製できるようになります。
お楽しみに。未来は8ビットです!
この投稿は、ChatGPTフリーを保証しています。
謝辞
このブログは、Intel LabsのOfir Zafrir、Igor Margulis、Guy Boudoukh、Moshe Wasserblatと共同で作成されました。彼らの素晴らしいコメントと協力に感謝します。
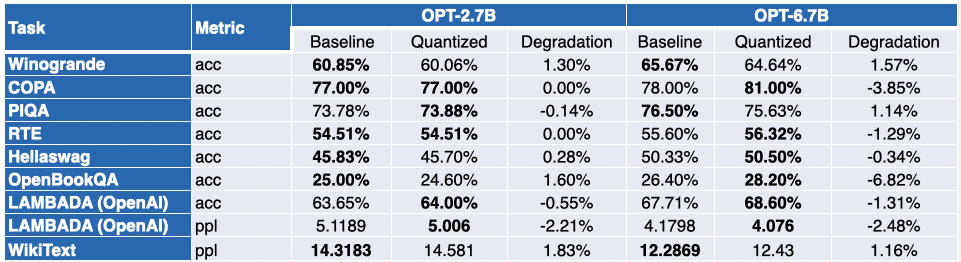
付録:詳細な結果
負の値はベンチマークが改善されたことを示しています。

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





