「Würstchenの紹介:画像生成のための高速拡散」
Würstchen High-speed Diffusion for Image Generation

Würstchenとは何ですか?
Würstchenは、テキスト条件付きの成分が画像の高度に圧縮された擬似モデルです。なぜこれが重要なのでしょうか?データの圧縮により、トレーニングと推論の両方の計算コストを桁違いに削減することができます。1024×1024の画像でのトレーニングは、32×32の画像でのトレーニングよりも遥かに高価です。通常、他の研究では比較的小規模な圧縮(4倍から8倍の空間圧縮)を使用しますが、Würstchenはこれを極限まで高めました。新しいデザインにより、42倍の空間圧縮を実現しました!これは以前には見られなかったものです。なぜなら、一般的な手法では16倍の空間圧縮後に詳細な画像を忠実に再構築することができないからです。Würstchenは2段階の圧縮、ステージAとステージBを採用しています。ステージAはVQGANであり、ステージBはディフュージョンオートエンコーダーです(詳細は論文を参照)。ステージAとBはデコーダーと呼ばれ、圧縮された画像をピクセル空間に戻します。高度に圧縮された潜在空間で学習される第3のモデル、ステージCも存在します。このトレーニングでは、現在の最高性能モデルに比べてずっと少ない計算リソースが必要であり、より安価で高速な推論が可能です。ステージCを事前モデルと呼んでいます。

なぜ別のテキストから画像へのモデルが必要なのですか?
それは非常に高速かつ効率的です。Würstchenの最大の利点は、Stable Diffusion XLなどのモデルよりもはるかに高速に画像を生成でき、メモリの使用量も少ないことです!A100が手元にない私たち全員にとって、これは便利なツールです。以下は、異なるバッチサイズでのSDXLとの比較です:
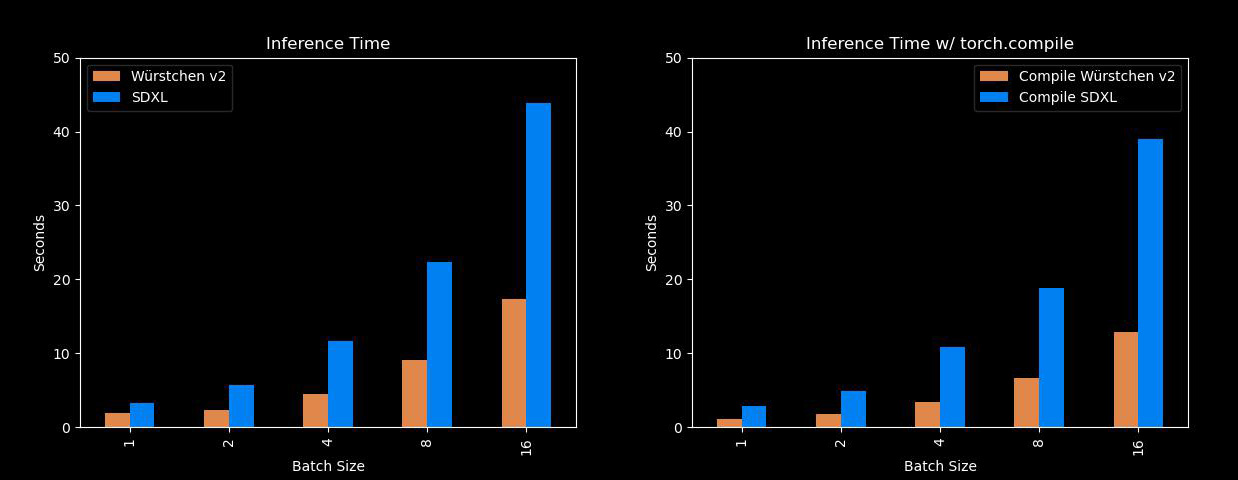
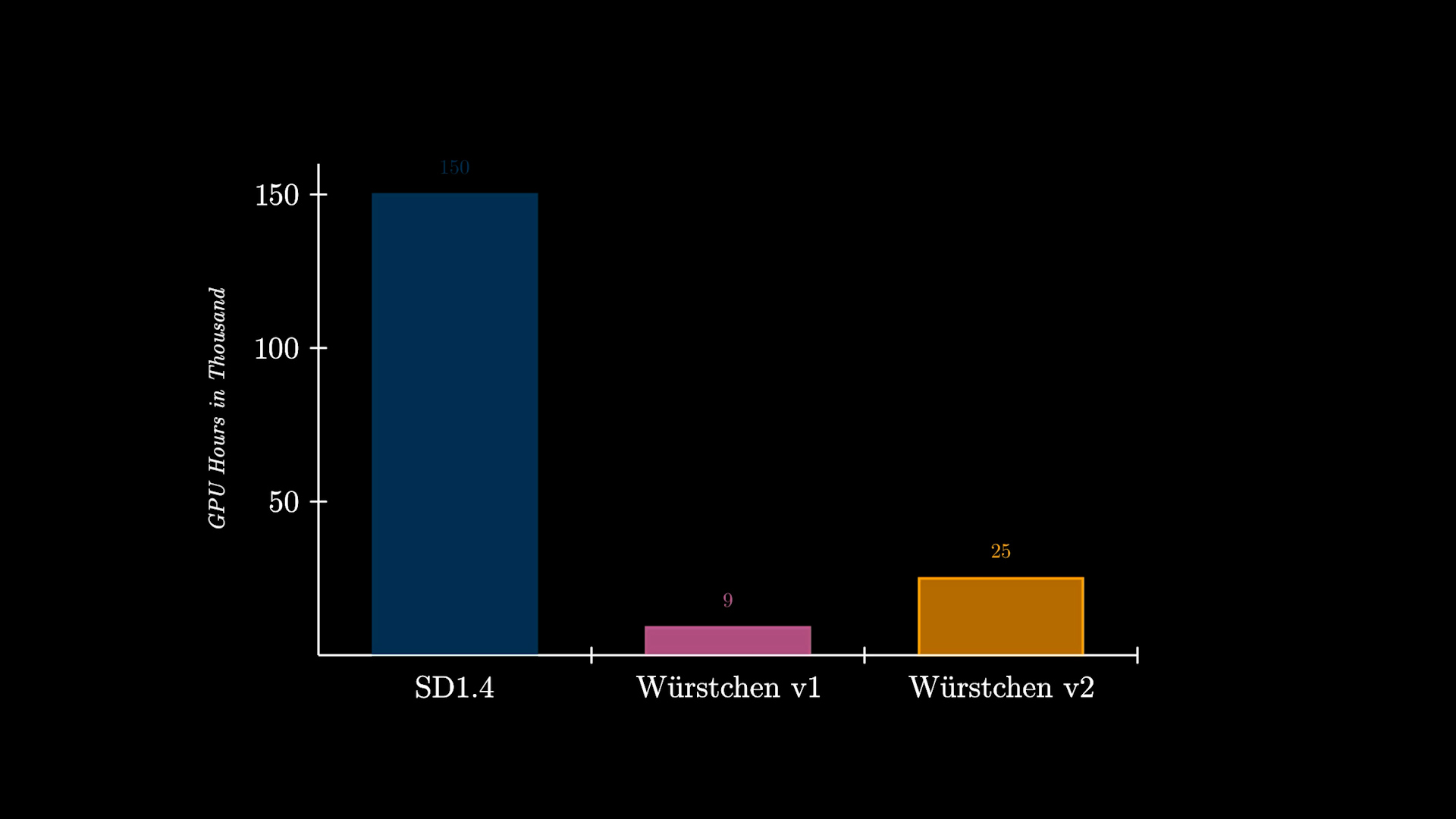
さらに、Würstchenの大幅な利点として、トレーニングコストの削減があります。512×512で動作するWürstchen v1は、わずか9,000時間のGPUでトレーニングされました。これを、Stable Diffusion 1.4に費やされた150,000時間のGPUと比較すると、コストが16倍も削減されていることがわかります。これにより、研究者が新しい実験を行う際にだけでなく、より多くの組織がこのようなモデルのトレーニングを行うことができるようになります。Würstchen v2は24,602時間のGPUを使用しました。解像度が1536まで上がっても、これはSD1.4の6倍安価です。SD1.4は512×512でのみトレーニングされました。
詳しい説明ビデオは次のリンクでご覧いただけます:
Würstchenの使用方法
こちらのデモを使用して試すこともできます:
または、モデルはDiffusersライブラリを介して利用可能なため、既に慣れているインターフェースを使用することができます。例えば、AutoPipelineを使用して推論を実行する方法は次のとおりです:
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Anthropomorphic cat dressed as a firefighter"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images
Würstchenはどの画像サイズで動作しますか?
Würstchenは1024×1024から1536×1536の解像度の画像でトレーニングされました。1024×2048などの解像度でも良い出力が得られることもあります。ぜひお試しください。また、Prior(ステージC)は新しい解像度に非常に速く適応することも観察されています。したがって、2048×2048での微調整は計算コストが非常に低いはずです。 
ハブ上のモデル
すべてのチェックポイントは、Huggingface Hub上でも確認することができます。複数のチェックポイントや将来のデモ、モデルの重みもそこで見つけることができます。現在、Priorには3つのチェックポイントがあり、Decoderには1つのチェックポイントがあります。チェックポイントの説明や異なるPriorモデルの使用方法については、ドキュメントをご覧ください。
Diffusersの統合
Würstchenはdiffusersに完全に統合されているため、さまざまな便利な機能や最適化が付属しています。これには以下が含まれます:
- PyTorch 2の
SDPAによる自動化された高速化されたアテンションの使用(以下で説明)。 - PyTorch 1.xではなく2を使用する必要がある場合に、xFormersフラッシュアテンション実装をサポート。
- 使用されていないコンポーネントをCPUに移動するモデルのオフロード。これにより、パフォーマンスへの影響はほとんどありませんが、メモリを節約できます。
- メモリが本当に重要な状況のためのシーケンシャルCPUオフロード。メモリ使用量は最小限に抑えられますが、推論速度は遅くなります。
- Compelライブラリによるプロンプトの重み付け。
- Apple Silicon Mac上の
mpsデバイスのサポート。 - 再現性のためのジェネレータの使用。
- ほとんどの状況で高品質な結果を生成するための推論のための合理的なデフォルト値。もちろん、すべてのパラメータを自由に調整できます!
最適化テクニック1:フラッシュアテンション
バージョン2.0以降、PyTorchには高度に最適化されたリソースフレンドリーなアテンションメカニズムであるtorch.nn.functional.scaled_dot_product_attentionまたはSDPAが統合されています。入力の性質に応じて、この関数は複数の最適化手法を活用します。そのパフォーマンスとメモリ効率は従来のアテンションモデルを凌駕しています。注目すべきは、SDPA関数がDaoとチームによって執筆されたFast and Memory-Efficient Exact Attention with IO-Awarenessという研究論文で強調されているように、フラッシュアテンションの特性を反映していることです。
DiffusersをPyTorch 2.0またはそれ以降のバージョンで使用しており、SDPA関数にアクセスできる場合、これらの改善が自動的に適用されます。公式ガイドラインに従ってtorch 2.0または新しいバージョンをセットアップして始めましょう!
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesdiffusersがどのようにSDPAを活用しているかの詳細については、ドキュメントをご覧ください。
PyTorch 2.0より前のバージョンを使用している場合でも、xFormersライブラリを使用してメモリ効率の良いアテンションを実現できます:
pipeline.enable_xformers_memory_efficient_attention()最適化テクニック2:Torch Compile
さらなるパフォーマンス向上を求めている場合、torch.compileを使用することができます。パフォーマンスの最大の向上を実現するために、priorとdecoderのメインモデルの両方に適用することが最適です。
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)ただし、初期の推論ステップではモデルのコンパイルが行われるため、長い時間(最大2分)がかかります。その後は通常通り推論を実行することができます:
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesそして、このコンパイルは一度だけの実行です。その後、同じ画像解像度に対して一貫して高速な推論を体験することができます。コンパイルにかかる初期の時間投資は、後続の高速化の恩恵によってすぐに相殺されます。詳細なtorch.compileとそのニュアンスについては、公式ドキュメントをご覧ください。
リソース
- このモデルに関する詳細情報は、公式のdiffusersドキュメントで見つけることができます。
- すべてのチェックポイントはハブ上で見つけることができます
- こちらでデモを試すことができます。
- 将来のプロジェクトについて議論したり、自分のアイデアを貢献したりするには、Discordに参加してください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






