AIのレンズを通じた世界の歴史
World history through the lens of AI.
言語モデルはどのような歴史的知識をエンコードしているのか?
人工知能、特に大規模な言語モデルの進歩により、歴史研究や教育の可能性が広がっています。しかし、これらのモデルが過去をどのように解釈し、思い出すのかを慎重に検討することが重要です。彼らは歴史の理解における何らかの固有の偏見を反映しているのでしょうか?
歴史の主観性については十分に理解しています(学部では歴史を専攻しました!)。私たちが覚えている出来事や過去について形成する物語は、それを書いた歴史家や私たちが住んでいる社会に強く影響を受けています。たとえば、私の高校の世界史の授業は、カリキュラムの75%以上をヨーロッパ史に取り組んでおり、私の世界の出来事に対する理解を歪めています。
この記事では、AIのレンズを通じて人間の歴史がどのように記憶され、解釈されるかを探求します。いくつかの大規模な言語モデルによる主要な歴史的イベントの解釈を調査し、以下の点を明らかにします:
- これらのモデルは、イベントに対して西洋的またはアメリカ的な偏見を示しているのか?
- 韓国語やフランス語のプロンプトなど、プロンプトに使用される言語に基づいて、モデルの歴史的な解釈は異なるのか?
これらの質問を念頭に入れて、さあ、始めましょう!
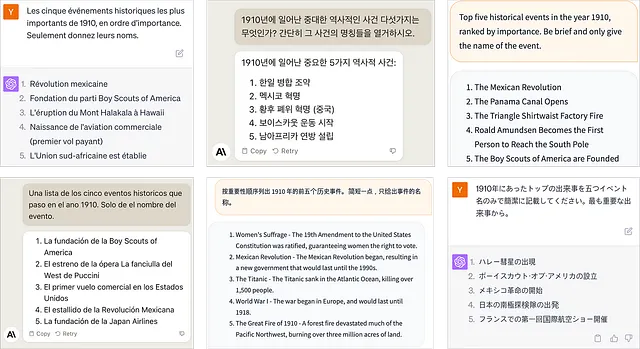
例:1910年
例として、私は3つの異なる大規模な言語モデル(LLM)に、1910年の主要な歴史的イベントについて尋ねました(次のセクションで各LLMの詳細について説明します)。

私が提示した質問は、客観的な答えを持たないように意図的に設定されています。1910年の重要性は、文化的な観点によって大きく異なります。韓国の歴史では、それは日本の占領の始まりを示し、国の進路に大きな影響を与える転換点となりました(1910年の日韓条約を参照)。
しかし、日本による韓国の併合は、いずれの回答にも含まれていませんでした。もし別の言語でプロンプトされた場合、同じモデルが質問を異なるように解釈するのか、興味が湧きました。例えば、韓国語でのプロンプトです。
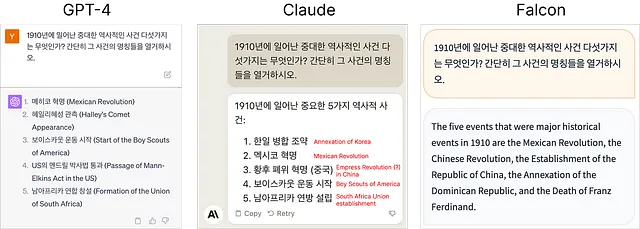
韓国語でのプロンプトに対して、Claudeが挙げた主要なイベントの一つは、確かに日本による韓国の併合です。しかし、GPT-4の重要なイベントのうち2つは米国中心で(ボーイスカウトとマン・エルキンス法)、韓国の併合には触れていませんでした。また、Falconは韓国語でプロンプトされても英語で応答しました。
実験
実験の設定は次の通りでした:
- 3つのモデル:OpenAIのGPT-4、AnthropicのClaude、およびTIIのFalcon-40B-Instruct
- 6つの言語:英語、フランス語、スペイン語、韓国語、日本語、中国語
- 3年(610年、1848年、1910年)
- 1回あたり5つの歴史的な出来事
- 10回の実行
- 合計2700の出来事
言語とプロンプト
私が選んだ言語はほとんど任意であり、私が最も馴染みのある言語(英語、韓国語)と私の最も身近な友人が話し、翻訳できる言語(中国語、日本語、フランス語、スペイン語)を基にしています。翻訳は記事の最後で見つけることができます。私は彼らに以下のように英語を翻訳してもらいました:
「{}, における重要性に基づいてランク付けされた上位5つの歴史的出来事。簡潔に書き、出来事の名前のみを記載してください。」
モデル
- OpenAIのGPT-4はChatGPTの新しい世代であり、最も人気のあるAIチャットボットの1つです(月間アクティブユーザー数は1億人以上)
- AnthropicのClaudeは、憲法AIという方法を用いて無害で助けになるように訓練されたChatGPTの競合モデルです
- Technical Innovation InstituteのFalcon-40B-Instructは、HuggingFaceのOpen LLM Leaderboardによれば最高のオープンソース言語モデルです
出来事の正規化
モデルが同じ出来事を生成した場合でも、同じ出来事を表現する方法には多様性がありました。
たとえば、以下はすべて同じ出来事を指しています:
- 「日本による韓国の併合」
- 「日本の韓国併合」
- 「日本が韓国を併合」
- 「日本韓国併合条約」
私は同じ語彙を用いて(これを正規化というプロセスとして知られています)、単一の出来事(日本による韓国の併合)を参照する方法が必要でした。さらに、同じ出来事を6つの異なる言語で説明することもあります。
正規化には、手動のルール、Google翻訳、およびGPT-4を使用しました。当初は、別のLLMを使用して他のLLMの出来事を正規化することを希望していました(たとえば、GPT-4を使用してClaudeの出来事を正規化するなど)。しかし、ClaudeとFalconは正規化の指示に従うことができず、GPT-4が最適なモデルとして浮かび上がりました。
モデルを使用して自分自身の出来事を正規化することに伴うバイアスを認識しています。ただし、私はGPT-4のさまざまなセッションを使用して歴史的な出来事を生成し、出来事を正規化する際にはコンテキストが重複しなかったため、問題ありません。将来的には、より客観的な方法を用いて正規化を行うことができます。
結果
全体的に、異なるモデルが歴史を理解する方法には驚きました。
- GPT-4は、プロンプトに関係なく同じ出来事を生成することがより多かったです
- Anthropicは、プロンプトされた言語に関連する歴史的な出来事をより多く生成する傾向がありました
- Falconは(残念ながら)偽の出来事を作り出すことがより多かったです
- 3つのモデルすべてが西洋やアメリカの出来事に偏りがありましたが、私の予想とは異なる形で現れました。非英語の言語でプロンプトされた場合、モデルはアメリカやイギリスの歴史的な出来事を生成する傾向がありました(英語でプロンプトされた場合にはその出来事を生成しない場合でも)。これは3つのモデルすべてで起こりました。
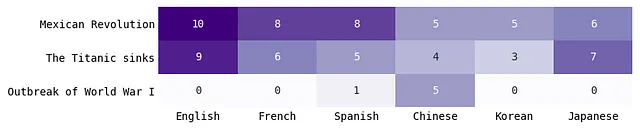
1. 各モデルの言語比較(1910年)
各モデル×言語の組み合わせで「上位5つの歴史的出来事」を10回生成しました(合計50の出来事)。1回だけ予測した出来事もありましたので、少なくとも1つの言語が5回以上予測した出来事のサブセットを取りました。値が10のセルは、そのイベントをモデルが毎回予測したことを意味します。
このセクションでは、1910年における各モデルが予測したトップイベントを言語別に示しています。610年と1848年の同様のチャートは、私がすべてのコードと分析を共有したGitHubのページで見ることができます。
GPT-4(OpenAI)
- メキシコ革命:すべての言語で、メキシコ革命は一貫して重要な世界的な出来事でした。韓国語や日本語など、予想外の言語でもそうでした。
- 日本による朝鮮併合:スペイン語やフランス語で尋ねた場合は言及されませんでした。ただし、日本語で尋ねると、韓国語で尋ねるよりもこの出来事がより頻繁に言及されました(9回対6回)。これは奇妙で興味深いことです。
- アメリカボーイスカウト創立:GPT-4は、日本語で尋ねられた場合にこの出来事を予測しました(7回)、英語で尋ねられた場合(4回)のほぼ2倍です。日本語の理解には、アメリカの情報の断片がエンコードされているようです。
- グレーシャーナショナルパークの設立:さらに奇妙なことに、GPT-4はスペイン語やフランス語で尋ねられた場合にこの出来事を予測しましたが、英語では予測しませんでした。

Claude(Anthropic)
全体的に、GPT-4とは異なり、すべての言語で「重要な歴史的な出来事」とされる出来事はありませんでした。
- メキシコ革命:フランス語、スペイン語、そして(理解できないが)韓国語で頻繁に生成されましたが、GPT-4ほど英語では重要ではありませんでした。
- 日本による朝鮮併合:韓国語と日本語にとっては他の言語よりも重要です(この出来事に関与した2つの国)。
- エドワード7世の死:英語とフランス語にとっては重要ですが(他の言語にとってはそうではありません)。エドワード7世はイギリスの国王であり、フランスとの関係が良好だったようです。
- 南極探検:実際にはイギリスの南極探検であり、イギリス人が初めて南極に到達した出来事です。しかし、何らかの理由で、Claudeは中国語や日本語でのみこの出来事を生成しますが(英語では生成しません)。

Falcon 40B Instruct(オープンソース;TII)
全体的に、Falconは他の2つのモデルほど一貫性や正確性がありませんでした。グラフに表示されているイベントが少ないのは、Falconが5回以上予測した他のイベントが存在しなかったためです!つまり、Falconの予測はやや一貫性がなかったと言えます。
- タイタニック号の沈没:実際には1912年に起こりました。
- 第一次世界大戦の勃発:実際には1914年に起こりました。
- Falconは歴史的には不正確な予測をしていますが、少なくとも10年代は正しかったですか?
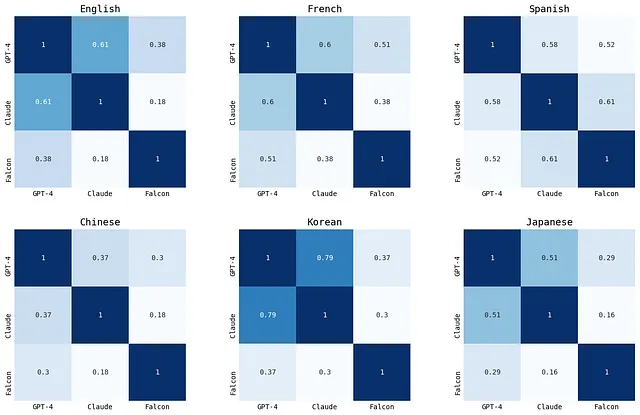
2. 各言語のモデル相関の比較(1910)
次に、各モデルの全体的な予測がどれだけ類似しているかを数値化しました。予測分布がどれだけ類似しているかを判定するために、数学的な方法(コサイン類似度)を使用しました。1に近い値は予測が完全に一致していることを示し、0に近い値は2つの予測セットが何も共有していないことを示します。
再び、ここでは1910年の例を示しています。他の年の情報はGitHubページで見つけることができます。
ほとんどの言語で、GPT-4とClaudeはより高い相関値を持っていました。つまり、すべての言語で、2つのモデルが高い割合で同様のイベントを予測していたことを意味します。
一方、ファルコンは他の2つのモデルと比較して相関が少ない傾向にありました。つまり、GPT-4とクロードとの歴史の理解は異なっていました。
3. 各年のモデルの比較
次に、各年の異なる言語モデルを比較しました。すべての言語で予測されたすべてのイベントを組み合わせ、言語に関係なくモデルが予測した全体のイベントを考慮しました。少なくとも1つのモデルが10回以上生成したイベントのサブセットを取りました。
前のセクションで見つかった傾向と同様に、GPT-4とクロードは各年において似たような主要な歴史的イベントを予測する傾向がありました-610年におけるムハンマドの最初の啓示とビザンチン王位におけるヘラクレイオス帝の昇天;1848年のヨーロッパ革命;そして1910年のメキシコ革命。
一部のイベントは、他のモデルと比較して一方のモデルが比例して予測する傾向がありました。例えば、1848年について、GPT-4は「共産党宣言の発表」を42回予測しましたが、クロードは15回でした。1910年については、クロードは「エドワード7世の死」を26回予測しましたが、GPT-4は1回でした。
ファルコンは歴史的なイベントを理解する能力が最も低かったです。ファルコンは3年間の主要なイベントを見逃しました。610年については、ファルコンはヘラクレイオス帝の昇天のイベントを予測することができませんでした。1910年については、日本の朝鮮併合、南アフリカ連邦の形成、ポルトガル革命などのイベントを予測することができず、代わりにアメリカ中心のイベントであるトライアングルシャツウェスト工場火災を予測しました(これは1911年に起こったものです)。興味深いことに、ファルコンは他の2つのモデルと同様に1848年のほとんどのイベントを予測することができました-おそらく1848年のイベントはより西洋中心であったためでしょうか(例えば、ヨーロッパの革命)?
より古いイベント(例えば、610年)は、歴史が少し曖昧であることを意味しています。唐の王朝は618年に成立し、隋の楊堅皇帝による大運河の建設は実際には長い期間(604年から609年)にわたって完成しました。
610年
1848年
1910年
ディスカッション
では、なぜこれが重要なのでしょうか?
教育企業が大規模言語モデル(LLM)を製品に組み込むことがますます増えている中で、Duolingoは言語学習のためにGPT-4を活用し、Khan AcademyはAI教育助手「Khanmigo」を導入し、ハーバード大学はAIをコンピュータサイエンスカリキュラムに統合する予定です-これらのモデルの潜在的なバイアスを理解することが重要になります。学生が歴史を学ぶためにLLMを使用する場合、彼らが偶然に吸収する可能性のあるバイアスは何でしょうか?
この記事では、GPT-4などの一部の人気のある言語モデルが、プロンプト言語に関係なく「重要な出来事」を一貫して予測することを示しました。一方、Claudeなどの他のモデルは、より言語特有の予測をしました。クローズドソースのモデルは、主要なオープンソースの代替物よりも一般的に一貫性と正確さが高かったです。この記事でテストされたすべてのモデルにおいて、他のグローバルな出来事を犠牲にする形で、西洋やアメリカの出来事(奇抜な出来事でさえ)を予測する傾向がありました。
今後の課題は以下の通りです:
- より多くの言語と年を含む分析の拡大
- モデルの出力の歴史的な正確さについての詳細な分析
- トップの歴史的な出来事のランキングについての詳細な分析
- 出来事の正規化のためのより客観的な方法の開発
この記事の目的は、LLMを非難することや教育現場からの排除を提案することではありません。むしろ、彼らのバイアスを認識し軽減するための批判的かつ慎重なアプローチを呼び掛けたいと思います。LLMは、責任を持って使用される場合、さまざまな学問分野の学生や教師の両方にとって価値のあるリソースになります。ただし、西洋中心主義などのバイアスを理解し、適切に利用する必要もあります。
LLMで歴史の教授や教科書を置き換えると、歴史の歪んだ一面的な解釈を生み出すリスクがあります。最終的には、これらのツールを思慮深く利用し、世界の理解を指示するのではなく補完するようにする必要があります。
お読みいただきありがとうございました!
ブーパー
いくつかの異なるオープンソースモデルを試しました。以下は、モデルが生成する奇妙な出力のいくつかのブーパー(すべて韓国語)です!
Falcon 40B Instruct


Pythia 12B
モデルは、カンガルー、航空便、およびロシア語での「トルゴヴァート」(トレードの意味)のバリエーションからなるループに詰まったようです。

翻訳
英語: 'Top five historical events in the year {}, ranked by importance. Be brief and only give the name of the event.'韓国語: '{}년에 일어난 중대한 역사적인 사건 다섯가지는 무엇인가? 간단히 그 사건의 명칭들을 열거하시오.'中国語: '按重要性顺序列出 {} 年的前五个历史事件。 简短一点,只给出事件的名称。'フランス語: 'Les cinque événements historiques les plus importants de {}, en ordre d’importance. Seulement donnez leurs noms.'日本語: '{}年にあったトップの出来事を五つイベント名のみで簡潔に記載してください。最も重要な出来事から。'スペイン語: 'Una lista de los cinco eventos historicos que paso en el ano {}. Solo de el nombre del evento.'We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





