「機械学習を使ったイタリアンファンタジーフットボールで勝利した方法」
Winning method in Italian fantasy football using machine learning.
AIの力でFantacalcioの謎を解く
私は機械工学の知識を持つエンジニアであり、プログラミングとコンピュータ科学に興味を持っています。数年前から、私は機械学習と人工知能の世界に魅了されました。これらの技術は、さまざまなエンジニアリング分野での可能性を認識し、機械学習の学習を始めました。しかし、理論的な知識を獲得しても、実際にそれを応用して実践する方法が見つからないという問題に直面しました。既製のデータセットは利用可能でしたが、データの収集と処理の完全な体験を提供してくれませんでした。そこで、私はある考えに至りました:なぜ機械学習を使ってファンタジーフットボールで勝つのを手助けしないのだろう?
Fantacalcioの紹介

Fantacalcioはイタリアのサッカーファンの間で非常に人気のあるゲームです。参加者はグループを組み、シーズンを通じてイタリアのトップリーグであるセリエAの選手の成績に基づいて競い合います。シーズン開始前には、参加者は20人以上の選手からなるロースターをドラフトするためのオークションを行います。セリエAの試合ごとに、選手はパフォーマンスに応じて得点を受け取ります。ゴールやアシストには追加のボーナスがあります。これらの獲得ポイントとボーナスによって、参加者のスコアが決まります。ゲームの重要な要素の1つは、週ごとに選手のラインナップを選び、定期的に出場させる選手やベンチに置く選手についての決定をすることです。
私の研究の目的
私の機械学習アルゴリズムの主な目的は、セリエAの選手のチームの試合に基づいて得点とファンタビュート(得点とボーナスの合計)を予測することです。サッカーは不確実なゲームです。選手が得点するかどうかを保証することは不可能です。しかし、特定の選手は他の選手よりも得点する可能性が高く、そのパフォーマンスは対戦相手のチームによって変動することがあります。私の目標は、セリエAの試合ごとに、どの選手がより強いパフォーマンスを発揮する可能性が高いかを客観的に判断する方法を見つけることでした。
免責事項:このようなセクションは、Fantacalcioの実例を提供し、説明されている概念を示すために記事で使用されます。ゲームやセリエAの選手に詳しくない場合は、これらのセクションをスキップしてください。
データの収集と処理
Fantacalcioから得点のアーカイブをダウンロードした後、次のステップは、機械学習アルゴリズムのトレーニングに使用する包括的な特徴セットを収集することでした。このデータセットを構築するために、私はfbref.comを非常に有用なリソースと見なしました。このサイトは、セリエAの選手やチームの統計情報をスクレイピングするための便利な手段を提供していました。FBRefでは、予想されるゴール数、タックル数、パス数、平均的なチャンス作成数など、さまざまな指標を含む、詳細に編纂された統計データが豊富に提供されていました。FBRefで利用可能な詳細なデータのおかげで、機械学習アルゴリズムのトレーニングに堅牢な特徴セットを組み立てるプロセスが大幅に容易になりました。


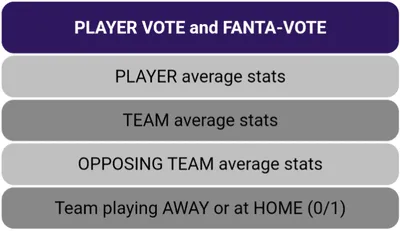
私が取ったアプローチは、各プレーヤーの50以上の特徴を含むデータセットを構築することでした。このデータセットは、プレーヤーの処理された平均統計を統合し、彼らのチームの統計と試合日に対戦相手の統計を結合したものです。データセットの各行のターゲット出力は、プレーヤーの投票とファンタビューです。データセットを構築するために、私はセリエAの過去3シーズンを考慮しました。
シーズン中のプレーヤーの信頼性の低い統計に対処するために、私は3つの戦略を使用しました:
- 前シーズンの統計との重み付き平均。
- 信頼性のある過去のデータがない場合、プレーヤーの統計は同じ役割を持つ平均プレーヤーの統計と平均化されました。
- 予め定義されたリストを使用して、プレーヤーの統計を同じ役割を持つ以前のプレーヤーの統計と一部平均化しました。
たとえば、ナポリの新人キムのパフォーマンスは、以前のクリステンセンのパフォーマンスと比較されるかもしれません。また、トーヴァンのパフォーマンスは、彼の前任者であるデウロフェウとの関係で評価されるかもしれません(ただし、これは間違っていることが判明しました)。
アルゴリズムの定義とトレーニング
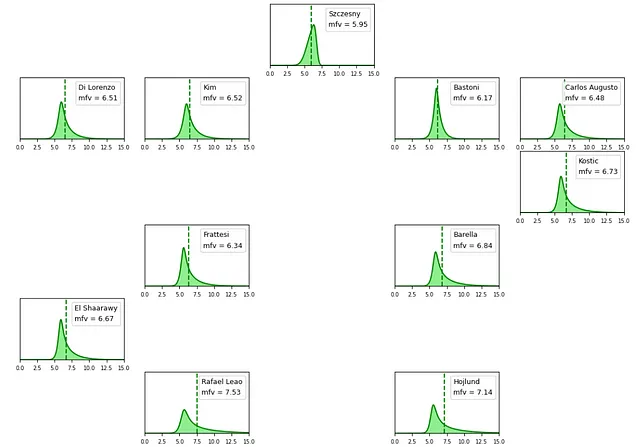
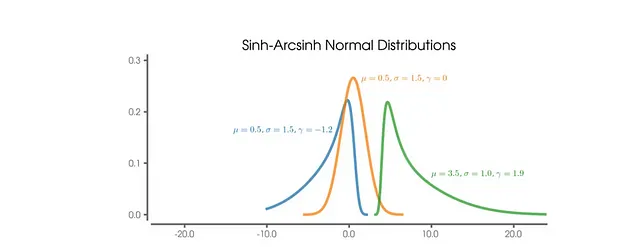
興味深く、結果の可視化をより良くするために、機械学習アルゴリズムは単純な投票とファンタビューの予測を超えるように設計されました。代わりに、確率的なアプローチが採用され、TensorFlowとTensorFlow Probabilityを活用して確率分布を生成するニューラルネットワークが構築されました。具体的には、ネットワークはsin-arcsinh確率分布のパラメータを予測しました。この選択は、プレーヤーのパフォーマンス投票の分布の固有の偏りを考慮するために行われました。たとえば、攻撃的なプレーヤーの場合、平均的なファンタビューは約6.5であるかもしれませんが、アルゴリズムは、ゴールを含む特別なパフォーマンスを示す10の投票が、稀な低パフォーマンスを示す4の投票よりもはるかにより頻繁に発生する可能性があることを認識しました。
このタスクに使用されたディープニューラルネットワークアーキテクチャは、シグモイド活性化関数を使用した複数の密な層で構成されています。過学習を防ぎ、汎化を高めるために、DropoutやEarly Stoppingなどの正則化技術が使用されました。Dropoutはトレーニング中にニューラルネットワークの一部のユニットをランダムに無効にし、Early Stoppingは検証損失が改善しなくなった場合にトレーニングプロセスを停止します。モデルのトレーニングには、予測された確率分布と実際の結果の不一致を測定するNegative Log Likelihoodが選択されました。
ニューラルネットワークの構築に使用されたコードの一部を以下に示します:
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience = 10)neg_log_likelihood = lambda x, rv_x: -rv_x.log_prob(x)inputs = tfk.layers.Input(shape=(X_len,), name="input")x = tfk.layers.Dropout(0.2)(inputs)x = tfk.layers.Dense(16, activation="relu") (x)x = tfk.layers.Dropout(0.2)(x)x = tfk.layers.Dense(16, activation="relu") (x)prob_dist_params = 4def prob_dist(t): return tfp.distributions.SinhArcsinh(loc=t[..., 0], scale=1e-3 + tf.math.softplus(t[..., 1]), skewness = t[..., 2], tailweight = tailweight_min + tailweight_range * tf.math.sigmoid(t[..., 3]), allow_nan_stats = False)x1 = tfk.layers.Dense(8, activation="sigmoid")(x)x1 = tfk.layers.Dense(prob_dist_params, activation="linear")(x1)out_1 = tfp.layers.DistributionLambda(prob_dist)(x1)x2 = tfk.layers.Dense(8, activation="sigmoid")(x)x2 = tfk.layers.Dense(prob_dist_params, activation="linear")(x2)out_2 = tfp.layers.DistributionLambda(prob_dist)(x2)modelb = tf.keras.Model(inputs, [out_1, out_2])modelb.compile(optimizer=tf.keras.optimizers.Nadam(learning_rate = 0.001), loss=neg_log_likelihood)modelb.fit(X_train.astype('float32'), [y_train[:, 0].astype('float32'), y_train[:, 1].astype('float32')], validation_data = (X_test.astype('float32'), [y_test[:, 0].astype('float32'), y_test[:, 1].astype('予測にニューラルネットワークを使用する
訓練されたアルゴリズムは、選手の投票とファンタ投票の確率分布予測を提供しました。選手の平均スタッツ、チーム情報、相手データ、ホーム/アウェイ要素を考慮することで、将来のセリエAの試合での選手のパフォーマンスを予測することができました。確率分布の事後処理により、予想される数値の投票予測と最大の潜在的な投票が導かれ、ファンタカルチョのラインアップ選択の意思決定が簡素化されました。
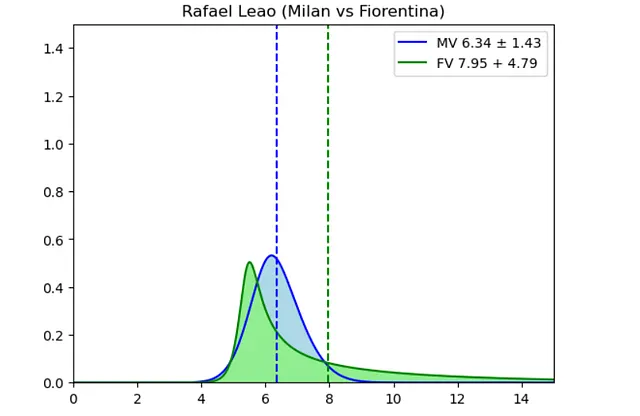
モンテカルロ法を使用して、各選手の確率分布を使用してラインアップの予想される総投票数を予測しました。モンテカルロ法は、複数のランダムシミュレーションを実行して潜在的な結果を推定する方法です。それだけです!セリエAの各試合日に、ファンタカルチョのロースターから最適なラインアップを選ぶために必要なすべてのツールを持っていました。

アルゴリズムが成功した点
追加の指標として、予想される投票数を個人的な予想と比較し、結果が満足であることを確認しました。アルゴリズムは、中央バックやサイドバックからウィンガーやストライカーまで、実際のサッカーと同様に複数の役割を担う選手が関与するマントラファンタカルチョバリアントで特に効果的でした。利用可能なモジュールから最適なラインアップを選ぶことは複雑な課題であり、攻撃的な選手が必ずしも守備的な選手を上回るわけではありませんでした。
さらに、アルゴリズムを使用して統計的に平均的なセリエAチームを対戦相手として選ぶことで、1月の市場オークションの準備に役立ちました。一般的な意見によって過小評価されている可能性のある過小評価された選手を特定することができました。
エル・シャーラウィやオルソリーニのような選手は、セリエAシーズン後半で非常に良いパフォーマンスを発揮した注目すべき例です。アルゴリズムは、彼らの予想されるパフォーマンスが1月末までに既に他のトップミッドフィールダーと同等のレベルであると予測しました。
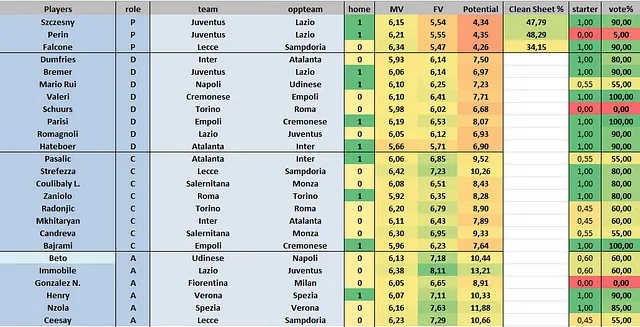
アルゴリズムが失敗した点または改善の余地がある点
アルゴリズムの弱点は、ゴールキーパーのパフォーマンスを予測することです。別個のニューラルネットワークを開発し、異なる特徴を利用し、クリーンシートの確率を出力として追加しました。しかし、結果は満足のいくものではありませんでした。おそらく、アウトフィールドプレーヤーに比べてゴールキーパーの数が限られているため、データセットが多様性に欠け、過学習のリスクが高まったためです。
さらに、アルゴリズムはシーズン全体での各選手の平均的なスタッツのみを考慮しました。このアプローチは十分でしたが、与えられた試合日の前の2つまたは3つの試合からのデータを組み込むことで、アルゴリズムが選手の現在のフォームを考慮する能力を向上させることができます。これにより、選手の最近のパフォーマンスのより包括的な評価が提供されます。
すべての作業は公開されています
このプロジェクトのコードと、いくつかのセリエAの試合日に生成された結果は、Githubで入手できます。時間が許す限り、次のシーズンのためにさらなる改善を行う予定です。質問や明確化が必要な場合は、お気軽にご連絡ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






