「ワイルドワイルドRAG…(パート1)」
Wild Wild RAG... (Part 1)
まず、最近注目を集めている用語であるRAGアプリケーションとは何かを理解することから始めましょう。
RAG(Retrieval-Augmented Generation)は、外部の知識源を組み込むことで言語モデルによる生成応答の品質を向上させるAIフレームワークです。これにより、言語モデルと現実世界の情報のギャップを埋め、より文脈に即した信頼性の高いテキスト生成が可能となります。以下の画像は、魅力的な例を提供しています。
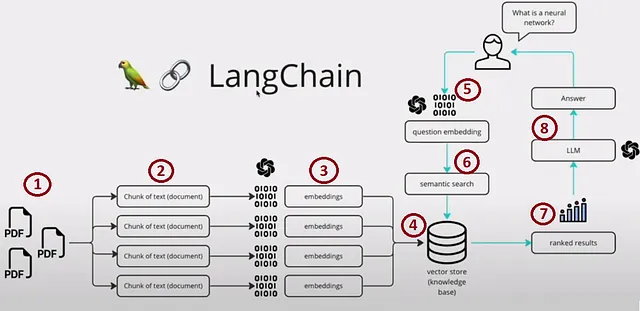
このプロセスは、次の4つの主要なセクションに分けることができます:
- ステップ1,2,3および4 – インデックス化
- ステップ5 – プロンプティング
- ステップ6と7 – 検索および取得
- ステップ8 – 生成
RAGアプリケーションのプロトタイプを作成するのは簡単ですが、広範な知識データベースを扱う際に高いパフォーマンス、耐久性、スケーラビリティを実現するために最適化することは、重要な課題です。
このブログでは、RAGアプリケーションを基本的な言語モデル(LLM)アプリケーションとは異なる特徴について掘り下げ、特にこの文脈での埋め込みとベクトルストアの選択の重要性に焦点を当てます。具体的には、インデックス化と検索および取得のセクションについてです。
さあ、始めましょう。

プロンプトとクエリに関連付けられる「文脈」を構築するために、まずセグメント化されたデータチャンクから埋め込みを生成する必要があります。これらの埋め込みはベクトルインデックスとして保存され、ユーザーのクエリに基づいて近似最近傍(ANN)検索を行う際の基盤となります。この概念は簡単に思えますが、このプロセスを本番環境に移行する際の複雑さは、探求する価値のある多くの課題を明らかにします。
ベクトルインデックスの作成、検索、および取得のコスト
さて、中心となる考慮事項の1つであるインデックスのコストについて詳しく説明しましょう。本番用のアプリケーションを構築する際には、無料のインメモリオプションに頼ることは適切ではありません。
内部の知識ベースを構成する35万ページまたは100万のPDFからの埋め込みの作成について、保守的な見積もりを行いましょう。平均3.5ページのPDFで構成されていると仮定します。単純化のために、各ページは画像を含まず、テキストのみで構成されているとします。したがって、各ページはおおよそ1000トークンに相当します。これを1,000トークンごとのチャンクに分割すると、35万のチャンクが得られ、それに対応する35万の埋め込みが得られます。
コストの計算には、このドメインでの2つの主要なオプションであるWeaviateとPineconeを考慮しましょう。以下の3つの主要なセクションにわたる月額の費用をシンプルに評価します:
- 一度限りの埋め込み変換コスト:35万の埋め込みを処理するためのおおよそのコストは、変換当たり0.0001ドルのレートで350ドルになります。
- Pinecone パフォーマンス最適化ベクトルデータベース(スタンダード):単一のレプリカの場合、このオプションのコストは約650ドルになります。これには、インデックス化と取得のコストが含まれます。重要なことは、要件が拡大するにつれてコストが線形にスケールするということです。Weviateという別の選択肢も、おそらく類似の価格体系を持っているでしょう。
- クエリ埋め込み変換のコスト:1,000人のユーザーが1日あたり平均25件のクエリを行い、各クエリとプロンプトが合計100トークンの場合、このセクションのコストは約10ドルになります。
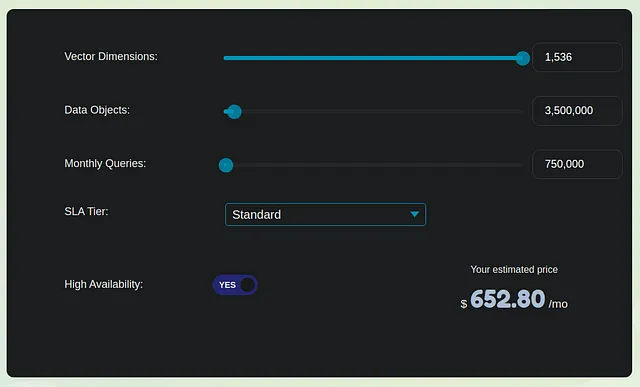
中程度でのインデックス作成にかかる月額費用は約1,000ドルです。ただし、この金額にはOpenAI LLM応答生成およびアプリケーションホスティングに関連する費用は含まれていません。これらの費用は前述の費用よりも約5から7倍以上になると推定されます。したがって、ベクトルストアの費用は全体の支出の約15から20%を占める重要な部分です。
コストを下げるためには、埋め込みモデルのホスティングを検討することもできます。これにより、埋め込みサイズを1536よりも小さくすることでベクトルストアの費用も削減できます。
ただし、ベクトルストアの料金は別途支払う必要があります。

類似検索メトリックやインデックスのような機能が一貫している場合、100以上のオプションからベクトルストアを選択する際に考慮すべき他の要素は何ですか?
レイテンシ、スケール、およびリコールのバランス
スケールとコストの観点から、ベクトルストアにはクライアントサーバーアーキテクチャを考慮しましょう。データのボリューム、プライバシー、お金などの要素に基づいて、クラウド上またはオンプレミスでホスティングすることができます。
ベクトルストアには、インデックスのレイテンシと検索のレイテンシの2つの重要なタイプの遅延があります。多くのユースケースでは、検索のレイテンシがインデックスのレイテンシよりも優先されます。これは、インデックス操作は通常断続的または一度のタスクであるのに対し、ユーザークエリと類似したチャンクの検索はより頻繁に発生し、ユーザーインターフェースを通じてリアルタイムかつスケールで行われることが多いためです。一方、リコールは、すべてのクエリに対して見つかった真の最近傍点の割合を平均化したものです。このドメインのほとんどのベンダーは、キーワードとベクトルの検索技術をさまざまな方法で組み合わせたハイブリッドベクトル検索手法を採用しています。特に、異なるデータベースベンダーは、リコールまたはレイテンシの最適化において異なる選択と妥協を行っています。
以下は、コサインメトリックの標準データセットに対するリコールとクエリ数/秒のベンチマークを確認しましょう:
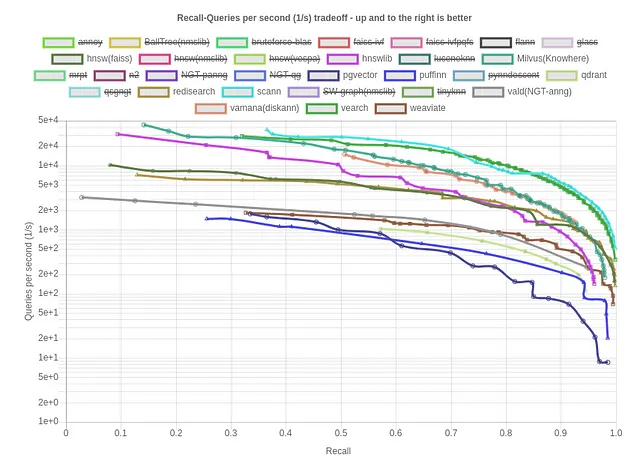
Scann、Vamana(DiskANN)、およびHNSWがインデックス作成のための最適なオプションとして浮上しています。次に、同じ指標に対するリコールとインデックスサイズ(kB)/クエリ数/秒を確認しましょう。これは、ベクトルデータベースの効率性とリソース消費を評価するための貴重な指標です。値が小さいほどメモリ効率が高く、ベクトルデータベースのパフォーマンスとスケーラビリティが最適化されます。

この文脈で、Qdrant、Weviate、およびRedisearchがメモリ効率の良い最適なオプションとして浮上しています。
ただし、各データベースで使用されているベクトルインデックスについては、以下の画像を参照してください。

多くのデータベースベンダーが、グラフベースのHNSWの独自の実装を開発することを選択していることが明らかです。これらのカスタム実装では、HNSWとプロダクト量子化(PQ)を組み合わせるなど、メモリ消費を減らすための最適化が行われることがよくあります。ただし、数少ないベンダーがDiskANNを採用しており、これはHNSWと同等のパフォーマンスを提供しながら、純粋にディスク上に格納されたメモリよりも大きいサイズのインデックスにスケーリングするというユニークな利点を提供しています。
私たちの評価では、ベンダーが提供するベンチマークに依存せず、評価プロセスに偏りを生じさせないようにしています。
柔軟性と継続的な学習の不足
将来のシナリオでは、Large Language Model(LLM)や埋め込みモデルをファインチューニングを通じて更新したり、アップグレードされたモデルに登録したり、埋め込み次元を拡張したり、データの変更に対応したりする必要がある場合、再インデックスと関連するコストは悪夢と言っても過言ではありません。このような硬直性は、システムの進化の機敏さとコスト効率を大幅に妨げる可能性があります。
これらの課題に加えて、ベクトル検索と検索プロセスに固有の複雑さについて探ってみましょう。
インデックスエラーハンドリングと次元の呪い
テキストクエリが関連するコンテキストを取得せず、関連のない情報や意味のない情報を提供する状況に遭遇した場合、この失敗の根本原因は一般的に次の3つの要因のいずれかに帰せられます:
a) 関連するテキストの不足:いくつかの場合、関連するテキストチャンクがデータベース内に存在しない場合があります。この結果は、クエリがデータセットの内容と関連性がないことを示唆しているため、受け入れられるものです。
b) 埋め込みの品質の低さ:別の原因として、埋め込み自体の品質が低い可能性があります。このような場合、埋め込みはコサイン類似度を使用して2つの関連テキストを効果的に一致させることができません。
c) 埋め込みの分布:または、埋め込み自体は品質が良いかもしれませんが、これらの埋め込みがインデックス内でどのように分布しているかによって、ANNアルゴリズムが正しい埋め込みを取得するのに苦労する場合があります。
一般的にクエリのデータセットへの関連性のなさを理由(a)として無視することは受け入れられますが、理由(b)と(c)の区別は、複雑で時間のかかるデバッグプロセスとなる可能性があります。この動作は、多数の高次元ベクトルを扱うANNアルゴリズムの場合に特に顕著になります。これは一般的に「次元の呪い」と呼ばれる現象です。
ベクトル検索と検索方法の再評価
ベクトル検索エコシステムの主要な目標が、クエリに応じて「関連するテキスト」を取得することであるならば、なぜ2つの別々のプロセスを維持するのでしょうか?代わりに、質問テキストが提示されると、直接「最も関連する」テキストを提供する統合された学習システムを構築することはできないでしょうか?
全エコシステムの基本的な仮定は、ベクトル埋め込み間の類似性尺度に依存して関連するテキストを取得するということです。しかし、このアプローチには可能性のある優れた代替手段が存在することを認識することが重要です。Large Language Models(LLMs)は類似性検索に特化したものではなく、他の検索方法がより効果的な結果をもたらす可能性があります。
出典:Twitter
ディープラーニングの革命は貴重な教訓をもたらしました:埋め込みと近似最近傍(ANN)操作が互いに非依存である切断されたプロセスよりも、共同で最適化された検索システムの方が優れたパフォーマンスを発揮する傾向があります。最適化された検索システムでは、埋め込みプロセスとANNコンポーネントが密接に関連し、互いの複雑さを認識しているため、より一貫性があり効率的な情報検索が行われます。これは、情報検索とコンテキストマッチングのシステムを設計する際に、包括的かつ統合的なアプローチの重要性を強調しています。
結論
Production-Ready Retrieval-Augmented Generation(RAG)アプリケーションとベクトル検索の領域では、言語モデルと現実世界の知識を結びつける課題と機会を見つけました。インデックス作成のコストを考慮したり、レイテンシ、スケール、リコールの微妙なバランスを取ったりすることから、これらのシステムを本番向けに最適化するには綿密な計画が必要です。モデルの柔軟性の欠如は、変化に対して適応性の重要性を示しています。ベクトル検索と検索を本番環境向けに再評価する際に、統合された共同最適化システムが有望であることがわかります。この常に進化する風景において、テキスト生成と情報検索の境界を再定義するよりコンテキストに敏感なAIシステムの創造が目前に迫っています。
旅は続きます…
お読みいただきありがとうございました。LinkedInでご連絡ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
