ディフューザーの新着情報は何ですか?🎨
What is the latest information on diffusers? 🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。
- 画像から画像へのパイプライン
- テキストの逆転
- インペインティング
- より小さなGPUに最適化
- Mac上で実行
- ONNXエクスポーター
- 新しいドキュメント
- コミュニティ
- SD潜在空間での動画生成
- モデルの説明可能性
- 日本語のStable Diffusion
- 高品質なファインチューニングモデル
- Stable Diffusionによるクロスアテンション制御
- 再利用可能なシード
画像から画像へのパイプライン
最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます!
公式のColabノートブックに基づいたコードを見てみましょう。
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# 初期画像をダウンロード
# ...
init_image = preprocess(init_img)
prompt = "アートステーションで注目されているファンタジーの風景"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]コードに時間がない場合は心配しないでください。直接試すことができるSpaceデモも作成しました。
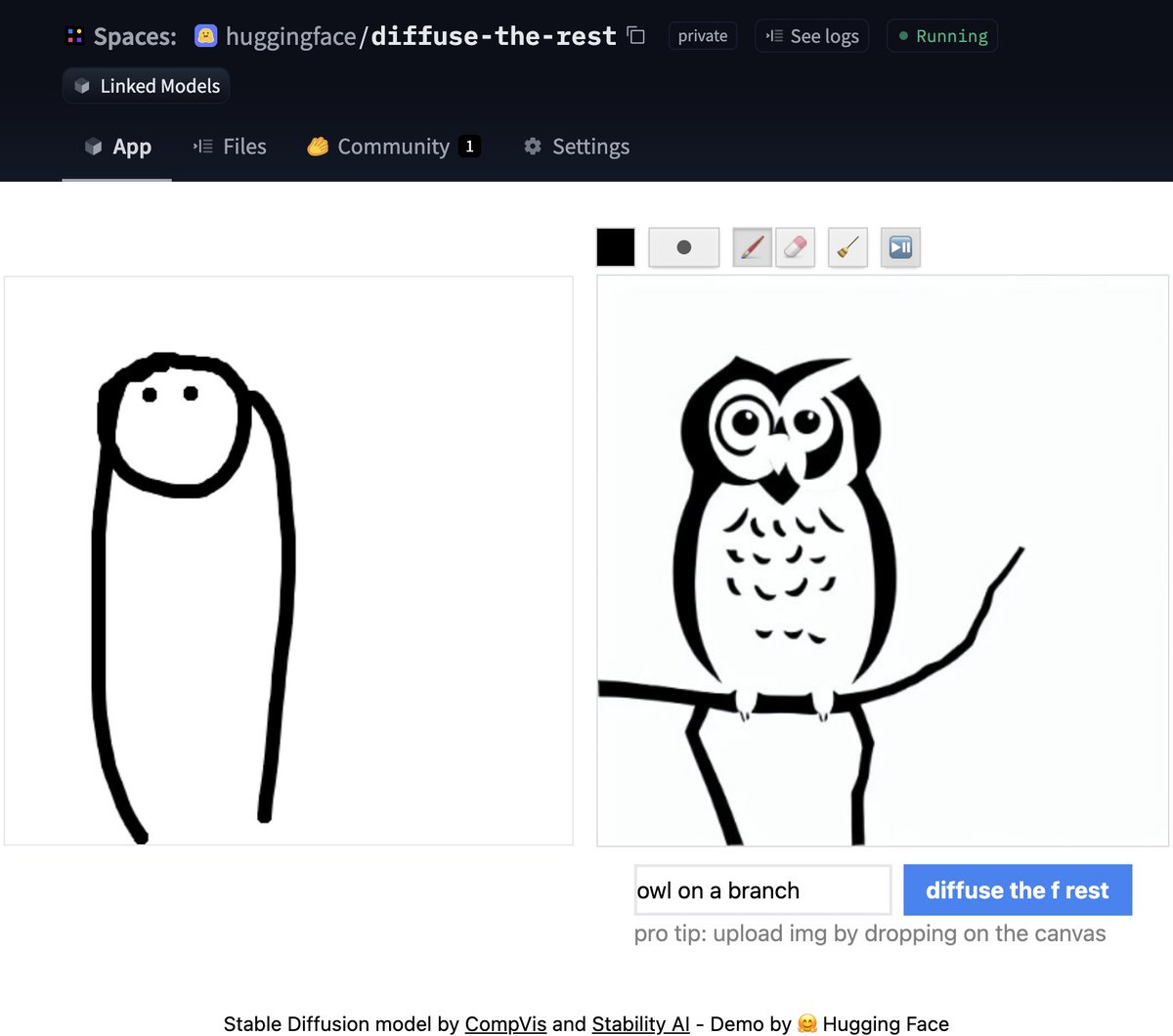
テキストの逆転
テキストの逆転を使用すると、たった3〜5のサンプルで自分自身の画像に対してStable Diffusionモデルをパーソナライズできます。このツールを使用すると、ある概念に基づいてモデルをトレーニングし、その概念をコミュニティ全体と共有することができます!
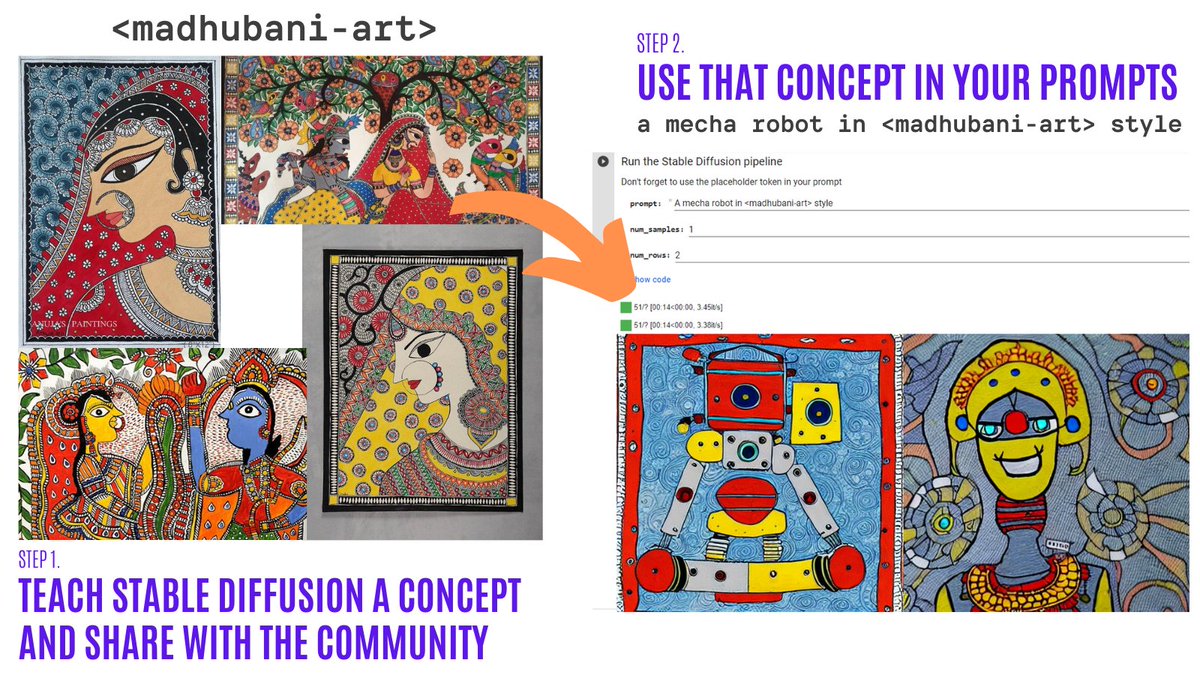
わずか数日で、コミュニティは200を超える概念を共有しました!ぜひチェックしてみてください!
- 概念ごとの組織化
- ナビゲーターColab:コミュニティが作成した150以上の概念を視覚的に閲覧して使用できます。
- トレーニングColab:Stable Diffusionに新しい概念を教えて、コミュニティ全体と共有します。
- インフェレンスColab:学習済みの概念を使用してStable Diffusionを実行します。
実験的なインペインティングパイプライン
インペインティングでは、画像を提供し、画像内の領域を選択(またはマスクを提供)し、Stable Diffusionを使用してマスクを置き換えることができます。以下に例を示します。

最小限のColabノートブックを試したり、以下のコードをチェックしたりすることができます。デモも近日中に公開されます!
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["ベンチに座る猫"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).imagesこれは実験的な機能であるため、改善の余地がありますのでご了承ください。
小さなGPU向けの最適化
いくつかの改善を行った結果、拡散モデルはより少ないVRAMを使用することができます。🔥 例えば、Stable Diffusionはわずか3.2GBしか使用しません!これにより、スピードの10%の犠牲でまったく同じ結果が得られます。以下はこれらの最適化を使用する方法です。
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()これは非常に興奮することです。これにより、これらのモデルを使用する障壁がさらに低くなります!
Mac OSでのDiffusers
🍎 そうです!さらに要望の多かった機能がリリースされました!公式ドキュメントで完全な手順(パフォーマンス比較、仕様なども含む)を読むことができます。
PyTorch mpsデバイスを使用することで、M1/M2ハードウェアを持つ人々はStable Diffusionで推論を実行することができます。🤯 ユーザーには最小限のセットアップが必要です。ぜひ試してみてください!
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "火星で馬に乗る宇宙飛行士の写真"
image = pipe(prompt).images[0]実験的なONNXエクスポーターおよびパイプライン
新しい実験的なパイプラインを使用すると、ONNXをサポートするすべてのハードウェアでStable Diffusionを実行することができます。以下はその使用例です(onnxリビジョンが使用されていることに注意してください)
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "火星で馬に乗る宇宙飛行士の写真"
image = pipe(prompt).images[0]また、SDのチェックポイントを直接ONNXに変換することもできます。
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"新しいドキュメント
これまでの機能はすべて非常にクールです。オープンソースライブラリのメンテナとして、ライブラリを試すためにできるだけ簡単にするために高品質のドキュメントの重要性を知っています。
💅 そのために、私たちはドキュメントのスプリントを行い、ドキュメントの最初のリリースが非常に楽しみです。これは最初のバージョンですので、追加する予定のものがたくさんあります(コントリビューションは常に歓迎です!)。
ドキュメントのハイライトのいくつか:
- 最適化のためのテクニック
- トレーニングの概要
- コントリビュートガイド
- スケジューラの詳細なAPIドキュメント
- パイプラインの詳細なAPIドキュメント
コミュニティ
上記のすべてを行っている間、コミュニティは何もしませんでした!以下はそのハイライトです(網羅的ではありませんが)
Stable Diffusion Videos
Stable Diffusionを使用して、潜在空間を探索し、テキストプロンプト間を変形させることで🔥ビデオを作成できます。以下のことができます:
- 同じプロンプトの異なるバージョンを夢見る
- 異なるプロンプト間を変形させる
Stable Diffusion Videosツールはpipでインストール可能であり、ColabノートブックとGradioノートブックが付属しており、非常に簡単に使用できます!
以下は例です
from stable_diffusion_videos import walk
video_path = walk(['猫', '犬'], [42, 1337], num_steps=3, make_video=True)Diffusers Interpret
Diffusers Interpretは、diffusersの上に構築された説明可能性ツールです。以下のようなクールな機能があります:
- 拡散プロセス中のすべての画像を表示する
- プロンプトの各トークンが生成にどのように影響を与えるかを分析する
- 画像の一部を理解するために特定のバウンディングボックス内を分析する
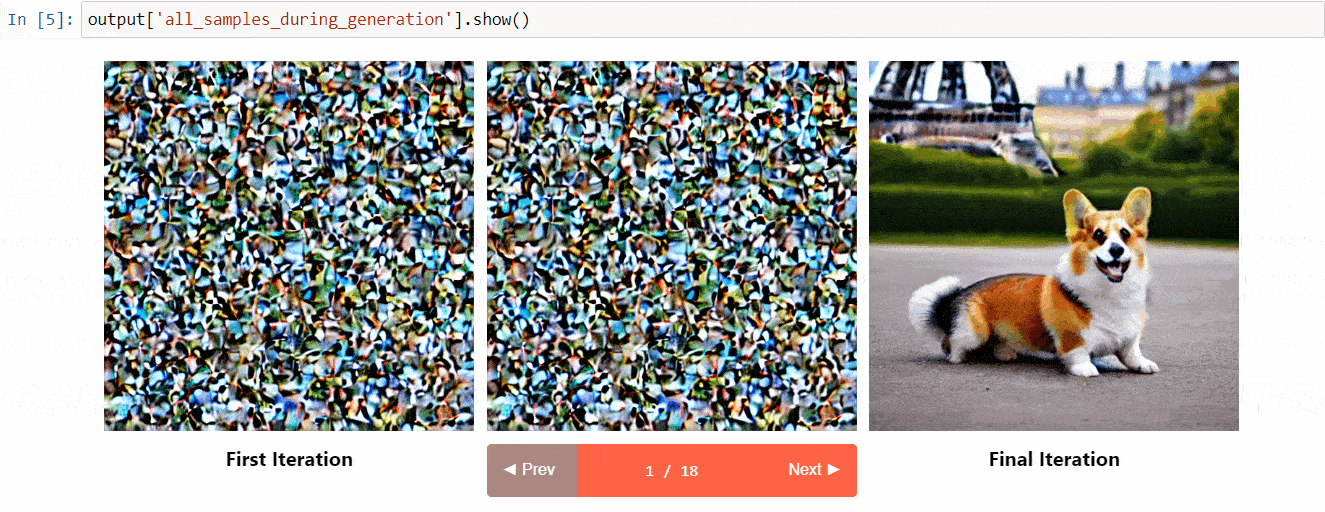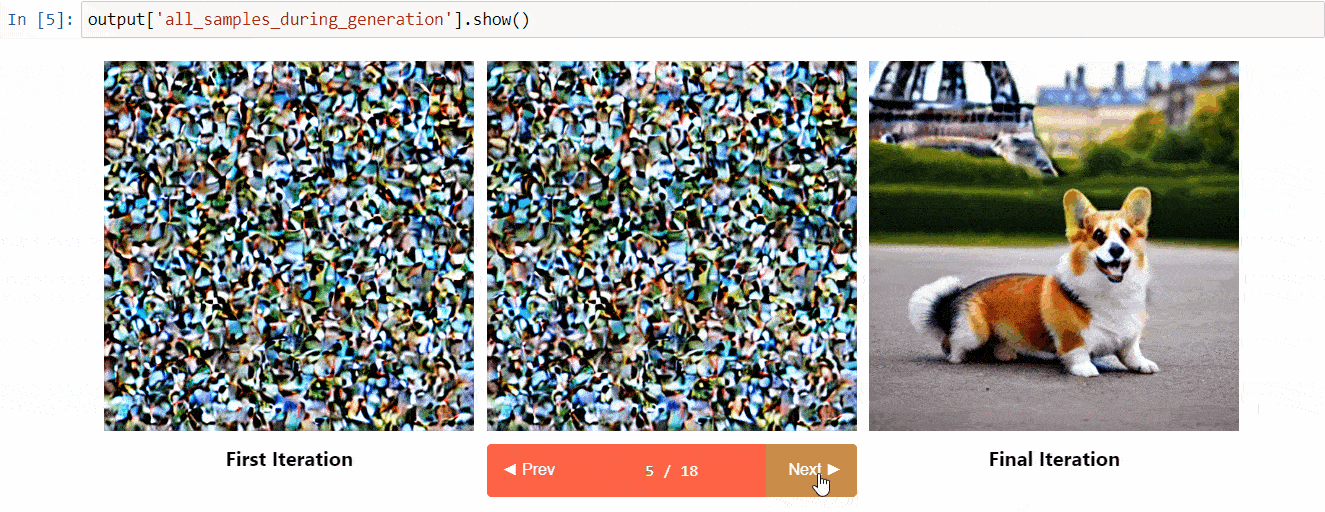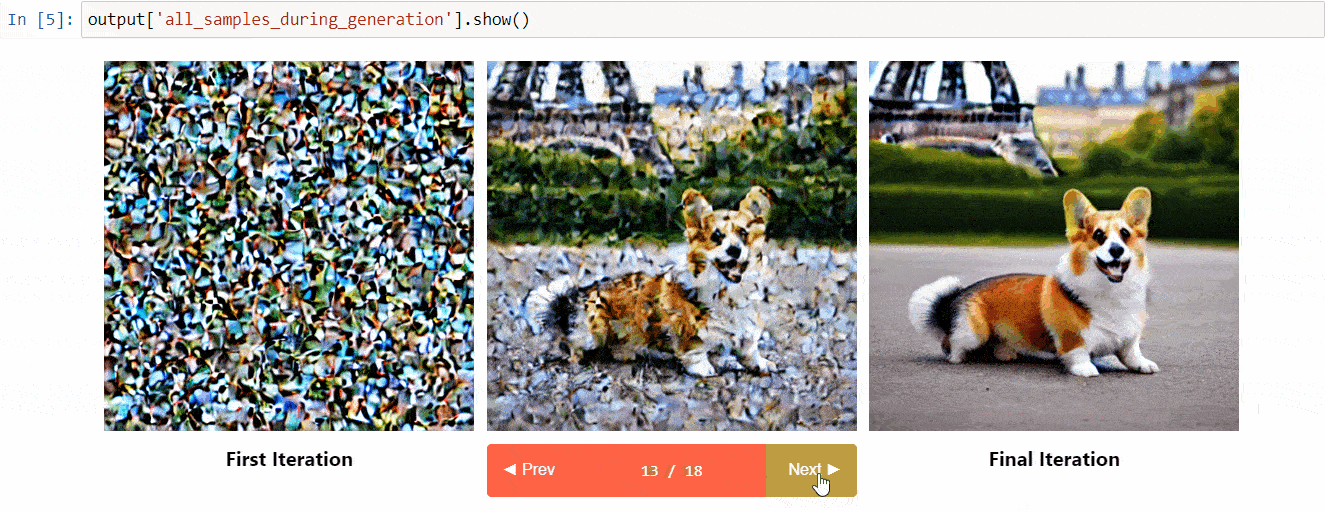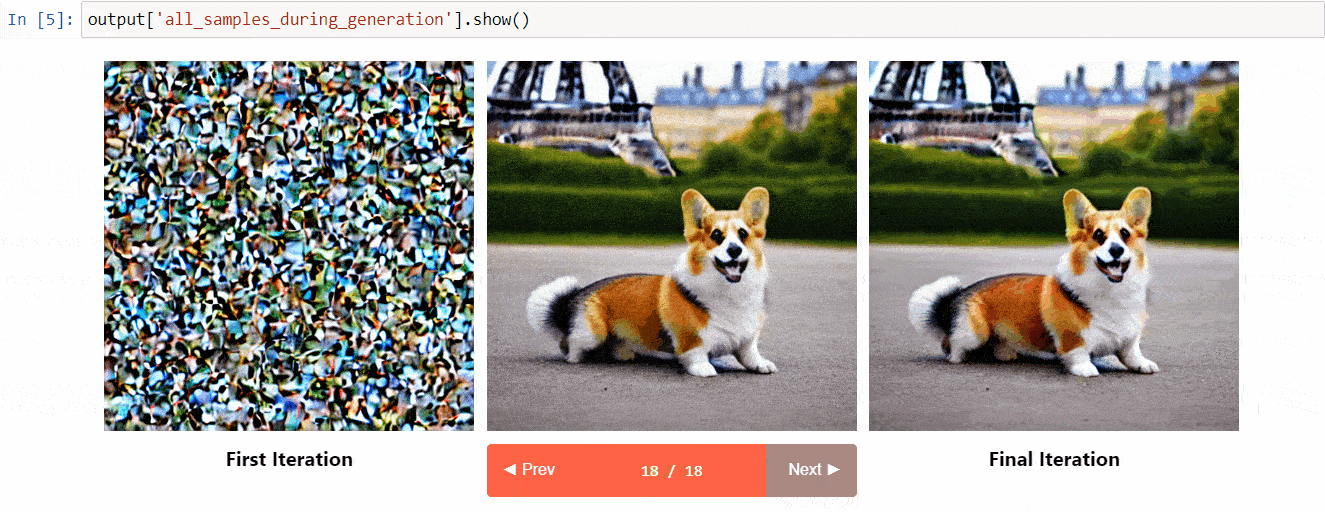 (ツールリポジトリからの画像)
(ツールリポジトリからの画像)
# パイプラインをエクスプレイナークラスに渡す
explainer = StableDiffusionPipelineExplainer(pipe)
# `explainer`で画像を生成する
prompt = "エッフェル塔とコーギー"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions #(トークン、割り当てパーセンテージ)
#[('コーギー', 40),
# ('と', 5),
# ('エッフェル', 5),
# ('塔', 25),
# ('', 25)]日本語ステーブルディフュージョン
その名前はすべてを物語っています! JSDの目標は、文化、アイデンティティ、ユニークな表現に関する情報もキャプチャするモデルを訓練することでした。 このモデルは、日本語のキャプションを持つ1億枚の画像で訓練されました。 モデルのトレーニングについての詳細はモデルカードで読むことができます
Waifu Diffusion
Waifu Diffusionは、高品質なアニメ画像生成のためのファインチューンされたSDモデルです。

(ツールリポジトリからの画像)
クロスアテンションコントロール
クロスアテンションコントロールは、ディフュージョンモデルの注意マップを変更することで、プロンプトを細かく制御することができます。 できることのいくつかは次のとおりです:
- プロンプト内のターゲットを置換する(例:「猫」を「犬」に置換する)
- プロンプト内の単語の重要性を減らしたり増やしたりする(例:「岩」にあまり注意を払わないようにする)
- 簡単にスタイルを注入する
などなど! リポジトリをチェックしてください。
再利用可能なシード
ステーブルディフュージョンの最も印象的な初期デモの1つは、シードの再利用を使用して画像を調整することです。 興味深い結果が得られます! Colabをチェックしてください
読んでいただきありがとうございます!
お楽しみいただければ幸いです! GitHubリポジトリでスターを付けて、Hugging Face Discordサーバーに参加してください。ディフュージョンモデルに関するカテゴリのチャンネルがあります。そこでは、ライブラリの最新ニュースが共有されます!
機能リクエストやバグレポートについては、遠慮なく問題を開いてください! このような素晴らしいコミュニティなしでは、達成されたすべてができませんでした。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






