ベクトルデータベースとは何か、そしてなぜLLMsにとって重要なのか?
What is a vector database and why is it important for LLMs?

Twitter、LinkedIn、またはニュースフィードをスキャンしていると、chatbots、LLMs、およびGPTに関する情報が表示されます。新しいLLMsが毎週リリースされるため、多くの人々がLLMsについて話しています。
現在、AI革命の真っ只中にいるため、多くの新しいアプリケーションがベクトル埋め込みに依存していることを理解することが重要です。そこで、ベクトルデータベースについて詳しく学び、なぜLLMsにとって重要なのかを説明します。
ベクトルデータベースとは何ですか?
まず、ベクトル埋め込みを定義しましょう。ベクトル埋め込みは、AIシステムがデータをより良く理解し、長期的な記憶を保つのに役立つ意味情報を持つデータ表現の一種です。学ぼうとしている新しいことには、トピックを理解し、それを覚えることが重要な要素です。
- GPUを活用した特徴量エンジニアリングにおいてRAPIDS cuDFを使用する
- JPLは、マルウェア研究を支援するためのPDFアーカイブを作成しました
- データ解析の刷新:OpenAI、LangChain、LlamaIndexで簡単に抽出
埋め込みは、LLMsなどのAIモデルによって生成されます。これらのモデルには多数の特徴が含まれているため、その表現を管理することは困難です。埋め込みは、データの異なる次元を表し、AIモデルが異なる関係、パターン、隠れた構造を理解できるようにします。
従来のスカラーベースのデータベースを使用してベクトル埋め込みを行うことは課題であり、データのスケールや複雑さに対応することができません。ベクトル埋め込みに伴うすべての複雑さを考えると、専門化されたデータベースが必要であることが想像できます。そこで、ベクトルデータベースが登場します。
ベクトルデータベースは、ベクトル埋め込みのユニークな構造に最適化されたストレージおよびクエリ機能を提供します。これらのデータベースは、値を比較し、お互いの類似性を見つけることによって、簡単な検索、高いパフォーマンス、スケーラビリティ、およびデータの取得を提供します。
素晴らしいと思いませんか?ベクトル埋め込みの複雑な構造に対処するための解決策があります。はい、しかし、ベクトルデータベースを実装することは非常に困難です。
ベクトルデータベースは、開発だけでなく、管理することができる能力を持ったテックジャイアントによってしか使用されていませんでした。ベクトルデータベースは高価であるため、適切にキャリブレーションされて高いパフォーマンスを提供することが重要です。
ベクトルデータベースはどのように機能しますか?
ベクトル埋め込みとデータベースについて少し知ったところで、その仕組みについて説明しましょう。
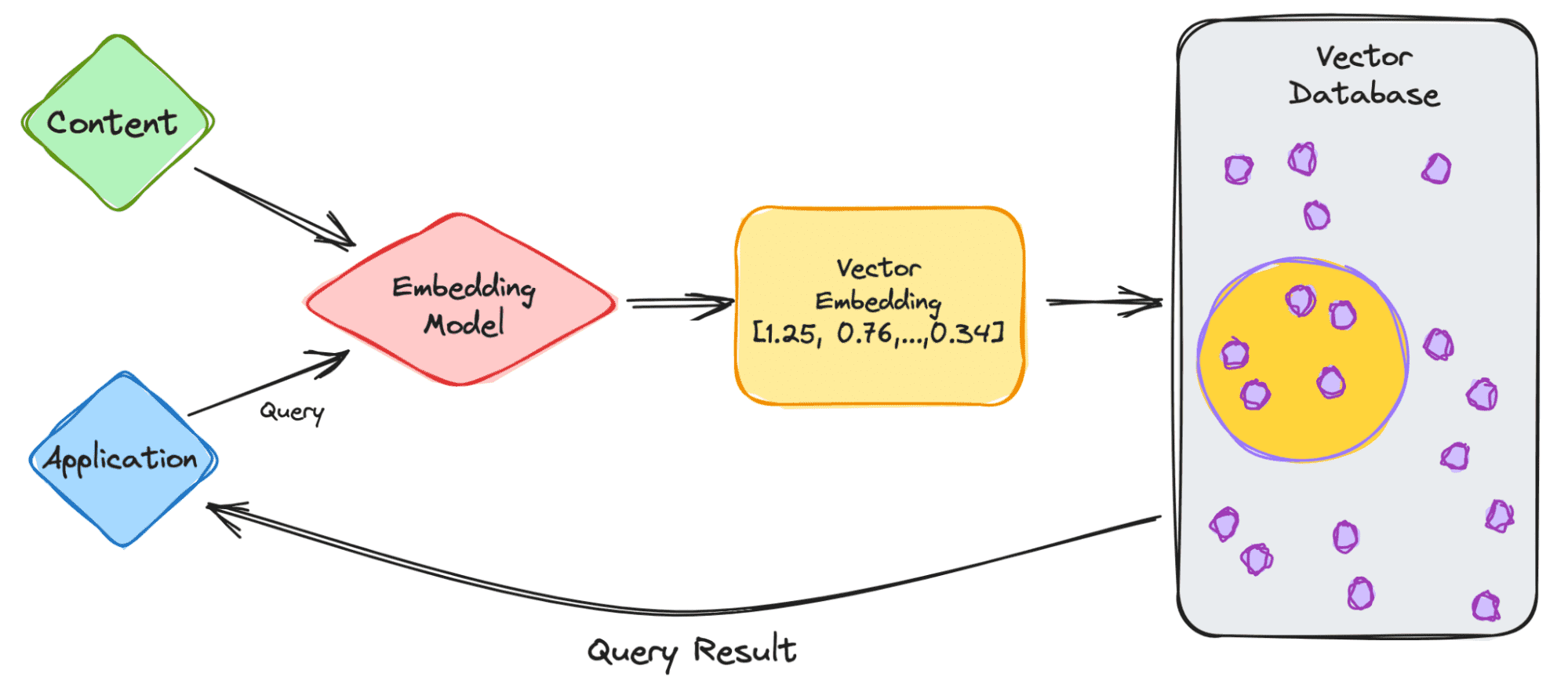
まず、ChatGPTなどのLLMを扱う簡単な例から始めましょう。モデルには多数のコンテンツがあり、ChatGPTアプリケーションを提供しています。
では、手順を見ていきましょう。
- ユーザーとして、アプリケーションにクエリを入力します。
- クエリは、インデックス化したいコンテンツに基づいてベクトル埋め込みを作成する埋め込みモデルに挿入されます。
- ベクトル埋め込みは、埋め込みが作成されたコンテンツに関するベクターデータベースに移動します。
- ベクトルデータベースは、出力を生成し、それをクエリの結果としてユーザーに送信します。
ユーザーがクエリを続けると、同じ埋め込みモデルを経由して、同様のベクトル埋め込みをクエリするためにデータベースをクエリします。ベクトル埋め込み間の類似性は、埋め込みが作成された元のコンテンツに基づいています。
ベクトルデータベースでの仕組みについてもっと知りたいですか?もっと学びましょう。
従来のデータベースは、文字列、数値などを行と列に格納して動作します。従来のデータベースからクエリを実行する場合、クエリに一致する行をクエリに対して検索します。しかし、ベクトルデータベースでは、文字列などではなくベクトルを使用し、クエリに最も類似するベクトルを見つけるのに役立つ類似度メトリックを適用します。
ベクトルデータベースは、近似最近傍(ANN)検索を支援するさまざまなアルゴリズムから構成されています。これは、クエリされたベクトルの近傍を取得するために、ハッシング、グラフベースの検索、または量子化を使用して行われます。
結果は、クエリにどの程度近いかまたは近似しているかに基づいています。したがって、考慮される主要な要素は、精度と速度です。クエリ出力が遅い場合、結果はより正確になります。
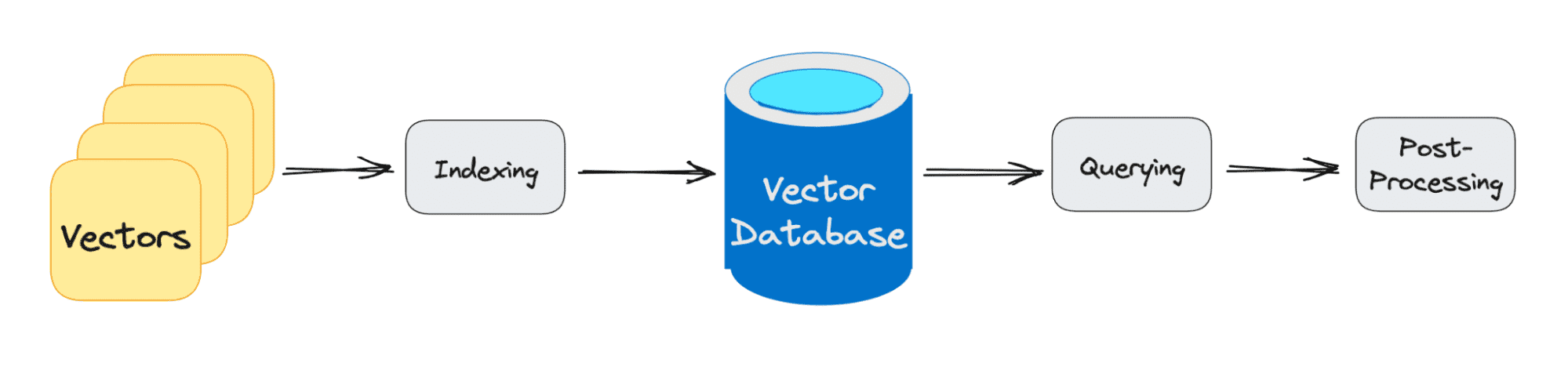
ベクトルデータベースクエリが通過する3つの主要なステージは次のとおりです。
1.インデックス化
先述の例で説明したように、ベクトル埋め込みがベクトルデータベースに移動すると、様々なアルゴリズムを使用してベクトル埋め込みをデータ構造にマップし、より高速な検索を行います。
2. クエリ
検索が完了すると、ベクトルデータベースはクエリされたベクトルとインデックスされたベクトルを比較し、類似性尺度を適用して最も近い隣接点を見つけます。
3. ポストプロセッシング
使用するベクトルデータベースによって異なりますが、ベクトルデータベースは最終的な最近傍点をポストプロセスしてクエリに対する最終出力を生成します。また、将来の参照のために最近傍点を再度ランク付けすることもあります。
まとめ
AIが成長し、毎週新しいシステムがリリースされる中で、ベクトルデータベースの成長が大きな役割を果たしています。ベクトルデータベースにより、正確な類似性検索をより効果的に行い、ユーザーにより良い・より速い出力を提供することができるようになりました。
次回ChatGPTやGoogle Bardでクエリを入力する際に、クエリに対する出力を生成するために行われるプロセスについて考えてみてください。
Nisha Aryaは、VoAGIのデータサイエンティスト、フリーランスの技術ライター、コミュニティマネージャーです。彼女は、データサイエンスのキャリアアドバイスやチュートリアル、理論的なデータサイエンスの知識を提供することに特に興味を持っています。また、人間の寿命を延ばすために人工知能がどのように役立つかを探求したいと考えています。彼女は、自分自身のテクノロジー知識とライティングスキルを広げながら、他の人々を指導することを助けることを目的としています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
