Weaviate入門:ベクトルデータベースを使った検索の初心者ガイド
Weaviate入門:初心者ガイド
PythonとOpenAI、Weaviateを使用してセマンティック検索、質問応答、ジェネレーティブ検索にベクトルデータベースを使用する方法

この記事にたどり着いたということは、大規模な言語モデル(LLM)を使用してアプリを構築し、ベクトルデータベースという用語に出会った可能性があると思います。
LLMを使用したアプリのツールの世界は急速に成長しており、LangChainやLlamaIndexなどのツールが人気を集めています。
最近の記事では、LangChainの使い方について説明しましたが、今回はWeaviateを使ってLLMのツールの世界をさらに探求してみたいと思います。
Weaviateとは何ですか?
Weaviateはオープンソースのベクトルデータベースです。データオブジェクトとベクトル埋め込みを保存し、類似度に基づいてクエリを行うことができます。
GitHub – weaviate/weaviate: Weaviateはオブジェクトとベクトルの両方を保存するオープンソースのベクトルデータベースです…
Weaviateはオブジェクトとベクトルの両方を保存し、ベクトル検索を組み合わせることができるオープンソースのベクトルデータベースです…
github.com
ベクトルデータベースは、LLMのメディアの注目が高まって以来、注目を集めています。LLMの文脈でのベクトルデータベースの最も人気のある使用例は、「LLMに長期記憶を提供することです。
ベクトルデータベースの概念についての復習が必要な場合は、以前の記事を参照してください。
3つの難易度レベルでベクトルデータベースを説明する
初心者からエキスパートまで:異なるバックグラウンドでのベクトルデータベースの解説
towardsdatascience.com
このチュートリアルでは、データセットの埋め込みを使用してWeaviateベクトルデータベースを準備する方法について説明します。その後、次の3つの異なる方法で情報を取得する方法を説明します。
- ベクトル検索
- 質問応答
- ジェネレーティブ検索
前提条件
このチュートリアルを進めるためには、次のものが必要です。
- Python 3の環境
- OpenAI APIキー(または代わりに、Hugging Face、Cohere、またはPaLMのAPIキー)
APIキーに関する注意事項:このチュートリアルでは、テキストから埋め込みを生成するための推論サービス(この場合、OpenAI)を使用します。使用する推論サービスに応じて、予期しないコストを回避するために、プロバイダの価格ページを確認してください。例えば、使用されるAdaモデル(バージョン2)の場合、執筆時点で1,000トークンあたり0.0001ドルかかり、このチュートリアルの推論コストは1セント未満でした。
セットアップ
Weaviateは、Docker、Kubernetes、またはEmbedded Weaviateを使用して独自のインスタンスで実行するか、Weaviate Cloud Services(WCS)を使用して管理されたサービスとして実行することができます。このチュートリアルでは、推奨される最も簡単な方法であるWCSを使用してWeaviateインスタンスを実行します。
Weaviate Cloud Services(WCS)を使用してクラスタを作成する方法
サービスを使用するためには、まずWCSに登録する必要があります。
登録が完了したら、「クラスタの作成」ボタンをクリックして新しいWeaviateクラスタを作成できます。

このチュートリアルでは、無料トライアルプランを使用します。このプランでは、14日間のサンドボックスが提供されます(支払い情報の追加は必要ありません)。代わりに、トライアル期間が終了するとサンドボックスは自動的に無効になりますが、いつでも新しい無料トライアルサンドボックスを作成することができます。
「無料サンドボックス」タブの下で、以下の設定を行ってください:
- クラスター名を入力してください
- 認証を有効にします(「YES」に設定)
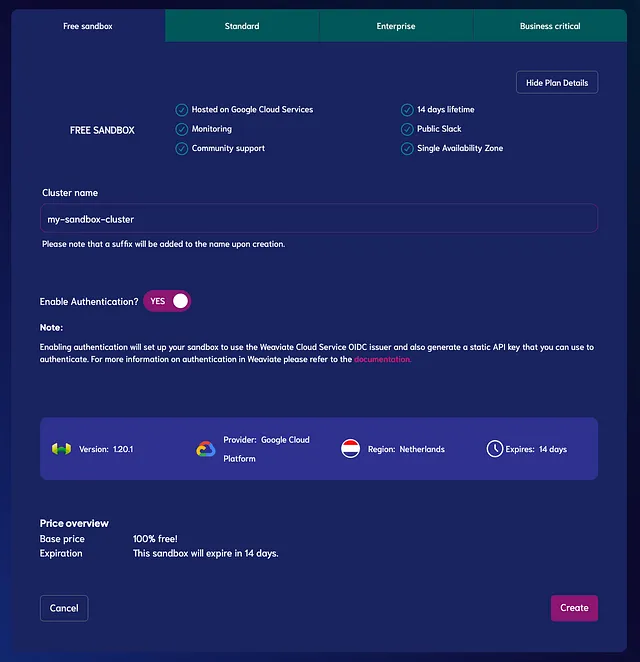
最後に、「作成」をクリックしてサンドボックスインスタンスを作成します。
PythonでWeaviateをインストールする方法
最後に、pipを使用してPython環境にweaviate-clientを追加してください。
$ pip install weaviate-clientそして、ライブラリをインポートします:
import weaviateクライアントを介してWeaviateクラスターにアクセスする方法
次のステップでは、クラスターにアクセスするために次の2つの情報が必要です:
- クラスターのURL
- Weaviate APIキー(「Enabled — Authentication」の下にあります)

これで、以下のようにWeaviateクライアントをインスタンス化してWeaviateクラスターにアクセスできます。
auth_config = weaviate.AuthApiKey(api_key="YOUR-WEAVIATE-API-KEY") # WeaviateインスタンスのAPIキーに置き換えてください# クライアントをインスタンス化するclient = weaviate.Client( url="https://<your-sandbox-name>.weaviate.network", # WeaviateクラスターのURLに置き換えてください auth_client_secret=auth_config, additional_headers={ "X-OpenAI-Api-Key": "YOUR-OPENAI-API-KEY", # OpenAIキーに置き換えてください })上記のように、埋め込みモデルにアクセスするためにadditional_headersの下にOpenAIのAPIキーを使用しています。OpenAI以外のプロバイダーを使用している場合は、適用されるキーパラメータを以下のいずれかに変更してください:X-Cohere-Api-Key、X-HuggingFace-Api-Key、またはX-Palm-Api-Key。
すべてが正しく設定されているかどうかを確認するには、次のコードを実行してください:
client.is_ready()返される値がTrueであれば、次のステップに進む準備が整っています。
Weaviateベクトルデータベースの作成とデータの追加方法
ここで、Weaviateでベクトルデータベースを作成し、いくつかのデータを追加する準備ができました。
このチュートリアルでは、KaggleのJeopardy Questionsデータセット[1]の最初の100行を使用します。
import pandas as pddf = pd.read_csv("your_file_path.csv", nrows = 100)![KaggleのJeopardy Questionsデータセット[1]の最初のいくつかの行](https://miro.medium.com/v2/resize:fit:640/format:webp/1*PFx77R8i42o_1Zs3PC_HiQ.png)
トークンの数と関連するコストについての注意事項:次の例では、「category」と「question」、「answer」の列を最初の100行に埋め込みます。 tiktokenライブラリを使用した計算に基づくと、埋め込むために約3,000トークンが必要であり、2023年7月現在、OpenAIのAdaモデル(バージョン2)を使用した場合の推論コストは約$0.0003です。
ステップ1:スキーマを作成する
まず、基礎となるデータ構造といくつかの設定を定義する必要があります:
class:このベクトル空間内のオブジェクトのコレクションは何と呼ばれますか?properties:オブジェクトのプロパティ名とデータ型を含むプロパティ。Pandasのデータフレームのアナロジーでは、これらはデータフレームの列になります。vectorizer:埋め込みを生成するモデルです。テキストオブジェクトの場合、使用するのは通常、text2vecモジュール(text2vec-cohere、text2vec-huggingface、text2vec-openai、またはtext2vec-palm)のいずれかです。プロバイダに応じて選択します。moduleConfig:ここでは、使用されるモジュールの詳細を定義できます。例えば、ベクトル化器はモデルとバージョンを定義できるモジュールです。
class_obj = { # クラス定義 "class": "JeopardyQuestion", # プロパティ定義 "properties": [ { "name": "category", "dataType": ["text"], }, { "name": "question", "dataType": ["text"], }, { "name": "answer", "dataType": ["text"], }, ], # ベクトル化器を指定 "vectorizer": "text2vec-openai", # モジュールの設定 "moduleConfig": { "text2vec-openai": { "vectorizeClassName": False, "model": "ada", "modelVersion": "002", "type": "text" }, },}上記のスキーマでは、"JeopardyQuestion"というクラスを作成し、"category"、"question"、"answer"の3つのテキストプロパティを持つことがわかります。使用しているベクトル化器はOpenAIのAdaモデル(バージョン2)です。すべてのプロパティはベクトル化されますが、クラス名はベクトル化されません("vectorizeClassName" : False)。埋め込みたくないプロパティがある場合は、これを指定できます(ドキュメントを参照してください)。
スキーマを定義したら、create_class()メソッドでクラスを作成できます。
client.schema.create_class(class_obj)クラスが正常に作成されたかどうかを確認するには、次のようにスキーマを確認できます:
client.schema.get("JeopardyQuestion")作成されたスキーマは以下のようになります:
{ "class": "JeopardyQuestion", "invertedIndexConfig": { "bm25": { "b": 0.75, "k1": 1.2 }, "cleanupIntervalSeconds": 60, "stopwords": { "additions": null, "preset": "en", "removals": null } }, "moduleConfig": { "text2vec-openai": { "model": "ada", "modelVersion": "002", "type": "text", "vectorizeClassName": false } }, "properties": [ { "dataType": [ "text" ], "indexFilterable": true, "indexSearchable": true, "moduleConfig": { "text2vec-openai": { "skip": false, "vectorizePropertyName": false } }, "name": "category", "tokenization": "word" }, { "dataType": [ "text" ], "indexFilterable": true, "indexSearchable": true, "moduleConfig": { "text2vec-openai": { "skip": false, "vectorizePropertyName": false } }, "name": "question", "tokenization": "word" }, { "dataType": [ "text" ], "indexFilterable": true, "indexSearchable": true, "moduleConfig": { "text2vec-openai": { "skip": false, "vectorizePropertyName": false } }, "name": "answer", "tokenization": "word" } ], "replicationConfig": { "factor": 1 }, "shardingConfig": { "virtualPerPhysical": 128, "desiredCount": 1, "actualCount": 1, "desiredVirtualCount": 128, "actualVirtualCount": 128, "key": "_id", "strategy": "hash", "function": "murmur3" }, "vectorIndexConfig": { "skip": false, "cleanupIntervalSeconds": 300, "maxConnections": 64, "efConstruction": 128, "ef": -1, "dynamicEfMin": 100, "dynamicEfMax": 500, "dynamicEfFactor": 8, "vectorCacheMaxObjects": 1000000000000, "flatSearchCutoff": 40000, "distance": "cosine", "pq": { "enabled": false, "bitCompression": false, "segments": 0, "centroids": 256, "encoder": { "type": "kmeans", "distribution": "log-normal" } } }, "vectorIndexType": "hnsw", "vectorizer": "text2vec-openai"}ステップ2:Weaviateへのデータのインポート
この段階では、ベクトルデータベースにはスキーマがありますが、まだ空です。したがって、データセットでそれを埋めましょう。このプロセスは「upserting」とも呼ばれます。
データを200件ずつバッチ処理でupsertします。もし注意していればわかるように、ここでは100行のデータしかありませんので、これは必要ありません。しかし、より多量のデータをupsertする準備ができたら、バッチ処理で行うことが望ましいでしょう。そのため、以下にバッチ処理のコードを残しておきます:
from weaviate.util import generate_uuid5
with client.batch(
batch_size=200, # バッチサイズを指定
num_workers=2 # プロセスの並列化
) as batch:
for _, row in df.iterrows():
question_object = {
"category": row.category,
"question": row.question,
"answer": row.answer,
}
batch.add_data_object(
question_object,
class_name="JeopardyQuestion",
uuid=generate_uuid5(question_object)
)ただし、Weaviateはユニークな識別子(uuid)を自動生成しますが、重複したアイテムをインポートしないために、question_objectからuuidを手動で生成するためにgenerate_uuid5()関数を使用します。
確認のために、以下のコードスニペットでインポートされたオブジェクトの数を確認できます:
client.query.aggregate("JeopardyQuestion").with_meta_count().do()
{'data': {'Aggregate': {'JeopardyQuestion': [{'meta': {'count': 100}}]}}}Weaviateベクトルデータベースのクエリ方法
ベクトルデータベースで最も一般的な操作は、オブジェクトの取得です。オブジェクトを取得するには、get()関数を使用してWeaviateベクトルデータベースにクエリを行います:
client.query.get(
<クラス>,
[<プロパティ>]
).<引数>.do()クラス:取得するオブジェクトのクラス名を指定します。ここでは"JeopardyQuestion"です。プロパティ:取得するオブジェクトのプロパティを指定します。ここでは"category"、"question"、"answer"のいずれか、または複数を指定します。引数:オブジェクトを取得するための検索条件を指定します。制限や集計など、いくつかの例を以下で説明します。
get()関数を使用して、JeopardyQuestionクラスからいくつかのエントリを取得して、どのようなものかを確認しましょう。Pandasの類推では、以下のコードをdf.head(2)に思い浮かべることができます。なお、get()関数の戻り値はJSON形式ですので、結果を視覚的に表示するために関連するライブラリをインポートします。
import json
res = client.query.get("JeopardyQuestion",
["question", "answer", "category"])
.with_additional(["id", "vector"])
.with_limit(2)
.do()
print(json.dumps(res, indent=4))
{ "data": { "Get": { "JeopardyQuestion": [ { "_additional": { "id": "064fee53-f8fd-4513-9294-432170cc9f77", "vector": [ -0.02465364, ...] # ベクトルは可読性のために省略されています }, "answer": "(Lou) Gehrig", "category": "ESPN's TOP 10 ALL-TIME ATHLETES", "question": "No. 10: FB/LB for Columbia U. in the 1920s; MVP for the Yankees in '27 & '36; \"Gibraltar in Cleats\"" }, { "_additional": { "id": "1041117a-34af-40a4-ad05-3dae840ad6b9", "vector": [ -0.031970825, ...] # ベクトルは可読性のために省略されています }, "answer": "Jim Thorpe", "category": "ESPN's TOP 10 ALL-TIME ATHLETES", "question": "No. 2: 1912 Olympian; football star at Carlisle Indian School; 6 MLB seasons with the Reds, Giants & Braves" }, ] } }}上記のコードスニペットでは、"JeopardyQuestion"クラスからオブジェクトを取得していることがわかります。オブジェクトのプロパティとして"category"、"question"、および"answer"を取得するように指定しました。
さらに、2つの追加のargumentsを指定しました。最初に、.with_additional()引数を使用して、オブジェクトのIDとベクトル埋め込みに関する追加情報を取得するように指定しました。そして、.with_limit(2)引数を使用して、2つのオブジェクトのみを取得するように指定しました。この制限は重要であり、後の例でも再度見ることになります。これは、ベクトルデータベースからオブジェクトを取得すると、正確な一致ではなく類似性に基づいてオブジェクトが返されるため、閾値で制限する必要があるためです。
ベクトル検索
さあ、いくつかのベクトル検索を行いましょう!ベクトルデータベースから情報を取得することのクールな点は、例えば、動物に関連する"concepts"に関連するJeopardyの質問を取得するように指示できることです。
これには、以下に示すように.with_near_text()引数を使用し、興味がある"concepts"を渡すことができます:
res = client.query.get( "JeopardyQuestion", ["question", "answer", "category"])\ .with_near_text({"concepts": "animals"})\ .with_limit(2)\ .do()指定したvectorizerは、入力テキスト("animals")をベクトル埋め込みに変換し、2つの最も近い結果を取得します:
{ "data": { "Get": { "JeopardyQuestion": [ { "answer": "an octopus", "category": "SEE & SAY", "question": "Say the name of <a href=\"http://www.j-archive.com/media/2010-07-06_DJ_26.jpg\" target=\"_blank\">this</a> type of mollusk you see" }, { "answer": "the ant", "category": "3-LETTER WORDS", "question": "In the title of an Aesop fable, this insect shared billing with a grasshopper" } ] } }}すでにこれがどれだけクールなのかがわかります。ベクトル検索は、2つの異なるカテゴリからの動物の回答を持つ2つの質問が返されたことがわかります。従来のキーワード検索では、まず動物のリストを定義し、そのリストに含まれる動物の質問をすべて取得する必要がありました。
質問応答
質問応答は、LLMsとベクトルデータベースを組み合わせた際の最も人気のある例の一つです。
質問応答を有効にするには、モジュール設定の下にベクトル化器(すでに持っているはず)と質問応答モジュールを指定する必要があります。次の例に示すように:
# モジュール設定 "moduleConfig": { "text2vec-openai": { ... }, "qna-openai": { "model": "text-davinci-002" } },質問応答には、with_ask()引数を追加し、_additionalプロパティも取得する必要があります。
ask = { "question": "Which animal was mentioned in the title of the Aesop fable?", "properties": ["answer"]}res = ( client.query .get("JeopardyQuestion", [ "question", "_additional {answer {hasAnswer property result} }" ]) .with_ask(ask) .with_limit(1) .do())上記のコードは、質問"Which animal was mentioned in the title of the Aesop fable?"の答えが含まれる可能性のあるすべての質問を調べ、答え"The ant"を返します。
{ "JeopardyQuestion": [ { "_additional": { "answer": { "hasAnswer": true, "property": "", "result": " The ant" } }, "question": "In the title of an Aesop fable, this insect shared billing with a grasshopper" } ]}生成検索
LLMを組み込むことで、検索結果を返す前にデータを変換することもできます。この概念は生成型検索と呼ばれます。
生成型検索を有効にするには、以下の例に示すようにモジュール構成の下に生成モジュールを指定する必要があります:
# モジュール設定 "moduleConfig": { "text2vec-openai": { ... }, "generative-openai": { "model": "gpt-3.5-turbo" } },生成型検索では、前回のベクトル検索コードにwith_generate()引数を追加するだけで十分です。以下に示すように:
res = client.query.get( "JeopardyQuestion", ["question", "answer"])\ .with_near_text({"concepts": ["animals"]})\ .with_limit(1)\ .with_generate(single_prompt= "Generate a question to which the answer is {answer}")\ .do()上記のコードは以下のことを行います:
- 「動物」という概念に最も近い質問を検索する
- 質問「「あなたが見たこの種の軟体動物の名前を言ってください」という質問」を回答「タコ」とともに返す
- プロンプト「「タコ」という答えに対する質問を生成してください」の完全な結果であるプロンプトの生成を行う:
{ "generate": { "error": null, "singleResult": "八本の腕を持ち、知能と擬態能力で知られる海の生物は何ですか?」 }}サマリー
LLMの人気は、LangChainやLLaMaIndexなどの興味深い新しい開発者ツールを生み出すだけでなく、ベクトルデータベースなどの既存のツールを使用して、LLMパワードのアプリケーションの潜在能力を向上させる方法も示しています。
この記事では、ベクトルデータベースをベクトル検索だけでなく、質問応答や生成型検索と組み合わせて使用するためにWeaviateで試行錯誤を始めました。
より詳細なウォークスルーに興味がある場合は、ベクトルデータベースとWeaviateに関する包括的な4部講座をチェックすることをお勧めします:
1. Zero to MVP | Weaviate — ベクトルデータベース
コース概要
weaviate.io
免責事項:この執筆時点では、私はWeaviateのデベロッパーアドボケートです。
このストーリーを楽しんだ?
無料で購読して、新しいストーリーが公開されたときに通知を受け取りましょう。
月に3つ以上の無料ストーリーを読みたいですか? — 5ドル/月でVoAGIメンバーになりましょう。登録時に私の紹介リンクを使用することで、私には追加費用はかかりません。
私の紹介リンクでVoAGIに参加する – Leonie Monigatti
VoAGIメンバーとして、会費の一部はあなたが読む作家に支払われ、すべてのストーリーに完全アクセスできます…
VoAGI.com
LinkedIn、Twitter、Kaggleで私に会ってください!
参考文献
データセット
[1] Ulrik Thyge Pedersen (2023). 200,000以上のJeopardyの質問がKaggleのデータセットにあります。
ライセンス:Attribution 4.0 International (CC BY 4.0)
画像の参照
特に明記されていない場合、すべての画像は著者によって作成されたものです。
ウェブ&文献
[2] Weaviate (2023). Weaviateドキュメント(2023年7月14日アクセス)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
