Visual BERTのマスタリー | 最初のエンカウンターのパワーを解き放て
Visual BERT マスタリー | 最初のエンカウンターのパワー解放
イントロダクション
Googleは、BERTが検索の歴史でも最も大きな進歩の一つであり、より正確に人々が求めている情報を理解するのに役立つと述べています。Visual BERTのマスタリーは特別です。なぜなら、それは文の中の単語を前後の単語を見ることで理解することができるからです。これにより、文の意味をより良く理解することができます。まるで、すべての単語を考慮して文を理解するようなものです。

BERTは、コンピュータがさまざまな状況でテキストの意味を理解するのに役立ちます。例えば、テキストの分類、メッセージの感情の理解、認識された質問への回答、物や人の名前の理解などに役立ちます。Google検索でBERTを使用することにより、言語モデルがどれだけ進化し、コンピュータとのやり取りをより自然で助けになるものにしてくれるかがわかります。
学習目標
- BERTの略称(Bidirectional Encoder Representations from Transformers)を理解する。
- BERTが大量のテキストデータでトレーニングされる方法を知る。
- 事前トレーニングの概念と、それがBERTの言語理解の発展にどのように役立つかを理解する。
- BERTが文の左右の文脈の両方を考慮することを認識する。
- BERTを検索エンジンで使用してユーザーのクエリをより良く理解する。
- BERTのトレーニングに使用されるマスクされた言語モデルと次の文予測タスクを探求する。
この記事は、Data Science Blogathonの一環として公開されました。
BERTとは何ですか?
BERTはBidirectional Encoder Representations from Transformersの略です。これは、コンピュータが人間の言語を理解し処理するのを助ける特別なコンピュータモデルです。それは私たちのようなテキストを読み、理解することができる知的なツールです。
BERTの特別な点は、単語の意味を前後の単語を見ることで理解することができるということです。すべての単語を考慮して文の意味を理解するのと同じです。

BERTは、本や記事、ウェブサイトからのテキストを使用してトレーニングされます。これにより、単語間のパターンや関連性を学ぶことができます。したがって、BERTに文を与えると、トレーニングに基づいて各単語の意味と文脈を把握することができます。
BERTのこの強力な言語理解能力は、さまざまな方法で活用されます。また、テキストの分類、メッセージの感情や感情の理解、質問への回答などのタスクにも役立ちます。
SST2データセット
データセットリンク: https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2
この記事では、上記のデータセットを使用します。このデータセットには、映画のレビューから抽出された文が含まれています。値1は肯定的なラベルを表し、値0は否定的なラベルを表します。

このデータセット上でモデルをトレーニングすることで、ラベル付きデータから学んだパターンに基づいて、モデルに新しい文を肯定的または否定的に分類させることができます。
モデル:文の感情分類
私たちは、文を肯定的または否定的に分類する感情分析モデルを作成することを目指しています。
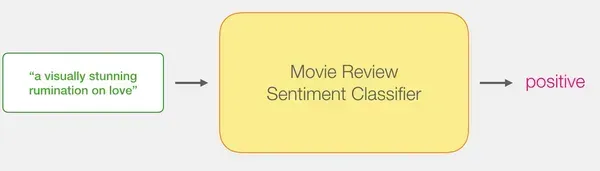

DistilBERTの文処理能力とロジスティック回帰の分類能力を組み合わせることで、効率的かつ正確な感情分析モデルを構築することができます。

DistilBERTで文埋め込みを生成する:事前トレーニングされたDistilBERTモデルを使用して、2,000の文のための文埋め込みを生成します。

これらの文章の埋め込みは、文章の意味と文脈に関する重要な情報を捉えます。
トレーニング/テストの分割を実行します:データセットをトレーニングセットとテストセットに分割します。

トレーニングセットを使用してロジスティック回帰モデルをトレーニングし、テストセットは評価に使用します。
ロジスティック回帰モデルのトレーニング:scikit-learnを使用してトレーニングセットを利用してロジスティック回帰モデルをトレーニングします。

ロジスティック回帰モデルは、文の埋め込みに基づいて文を肯定的または否定的に分類することを学習します。
この計画に従うことで、DistilBERTのパワーを活用して情報を提供する文の埋め込みを生成し、その後、ロジスティック回帰モデルをトレーニングして感情分類を行うことができます。評価ステップにより、新しい文の感情を予測するモデルのパフォーマンスを評価することができます。
単一の予測の計算方法
トレーニングされたモデルが例文「愛についての視覚的に見事な思索」を使用して予測を計算する方法について説明します。
トークン化:フレーズ内の各単語は、トークンとして知られるより小さい構成要素に分割されます。トークナイザは、特定のトークン(「CLS」の開始、「SEP」の終了など)も挿入します。

トークンからIDへの変換:トークナイザは、埋め込みテーブルから各トークンを対応するIDで置き換えます。埋め込みテーブルは、トレーニングされたモデルに付属するコンポーネントであり、トークンを数値表現にマッピングします。
入力の形状:トークン化と変換の後、DistilBERTは処理のために入力文を適切な形状に変換します。ユニークなトークンを追加して、文をトークンIDのシーケンスとして表現します。

トークナイザライブラリが提供するトークン化およびID変換を含むこれらの手順を、1行のコードで実行できることに注意してください。

これらの前処理の手順に従うことで、入力文はDistilBERTモデルによるさらなる処理と予測に供するための形式で準備されます。
DistilBERTを通過する
実際には、入力ベクトルをDistilBERTを通過させるプロセスはBERTと似たようなプロセスです。出力は各入力トークンに対して1つのベクトルが含まれ、各ベクトルは768個の数値(浮動小数点数)を含みます。

文の分類の場合、私たちは最初のベクトルに焦点を当てます。このベクトルは[CLS]トークンに対応します。[CLS]トークンは、シーケンス全体の全体的な文脈を捉えるために設計されています。そのため、BERTなどのモデルでは、文の分類には最初のベクトル([CLS]トークン)のみを使用します。このトークンの位置、事前トレーニングでの役割、プーリング技術は、分類タスクにおいて重要な情報をエンコードする能力に貢献します。さらに、[CLS]トークンのみを使用することで、計算の複雑さとメモリ要件を削減し、モデルが様々な分類タスクに対して正確な予測を行うことができます。このベクトルは、ロジスティック回帰モデルへの入力として渡されます。
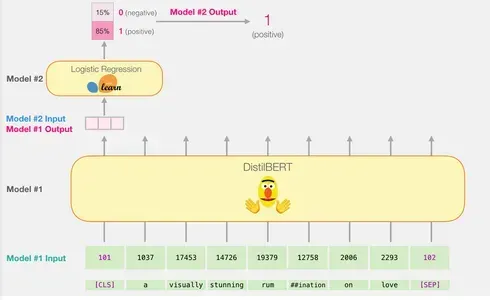
ロジスティック回帰モデルの役割は、トレーニングフェーズ中に学習した内容に基づいてこのベクトルを分類することです。予測の計算は次のように考えることができます:
- ロジスティック回帰モデルは、入力ベクトル([CLS]トークンに関連付けられたもの)を入力として受け取ります。
- モデルは、ベクトル内の768個の数値それぞれに学習した重みを適用します。
- 重み付けされた数値は合計され、追加のバイアス項が加えられます。
最終的に、合計値はシグモイド関数を通過して予測スコアを生成します。

ロジスティック回帰モデルのトレーニングフェーズと全体のプロセスの完全なコードについては、次のセクションで説明します。
スクラッチからの実装
このセクションでは、この文章分類モデルのトレーニングコードを強調表示します。
ライブラリの読み込み
まず、必要なツールをインポートして始めましょう。データの外観を確認するためにdf.head()を使用して、データフレームの最初の5行を表示できます。

事前学習済みのDistilBERTモデルとトークナイザーのインポート
データセットをトークン化しますが、前の例とは少し異なります。1つの文を一度にトークン化して処理する代わりに、バッチとしてすべての文を一緒に処理します。
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer,
'distilbert-base-uncased')
## distilBERTの代わりにBERTを使用したい場合は?
##以下の行のコメントを解除してください:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer,
'bert-base-uncased')
# 事前学習済みモデル/トークナイザーを読み込む
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)たとえば、映画のレビューのデータセットがあり、2,000のレビューを同時にトークン化して処理したいとします。DistilBERTモデルを使用してテキストをトークン化するために特に設計されたトークナイザーであるDistilBertTokenizerを使用します。
トークナイザーは、バッチ全体の文を受け取り、トークン化を実行します。これには、文をトークンと呼ばれるより小さな単位に分割することが含まれます。また、各文の先頭に[CLS]、末尾に[SEP]などの特殊トークンも追加されます。
トークン化
その結果、各文はIDのリストになります。データセットはリストのリスト(またはpandasのSeries/DataFrame)で構成されています。より短いフレーズは、すべてのベクトルを同じ長さにするためにトークンID 0でパディングする必要があります。これで、パディング後にBERTに提供できる行列/テンソルができました:
tokenized = df[0].apply((lambda x: tokenizer.
encode(x, add_special_tokens=True)))

DistilBERTでの処理
パディングされたトークン行列は、入力テンソルに変換され、DistilBERTに提出されます。
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)このステップを完了すると、DistilBERTの出力はlast_hidden_statesに格納されます。この場合、私たちは2000のインスタンスのみを考慮したため、last_hidden_statesは2000(2000の例から最長のシーケンスのトークン数)と768(DistilBERTモデルの隠れユニットの数)です。
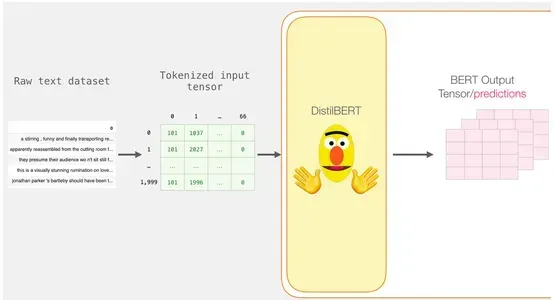
BERT出力テンソルの展開
3Dの出力テンソルの次元を検査し、それを抽出しましょう。DistilBERTの出力テンソルを含むlast_hidden_states変数があると仮定します。
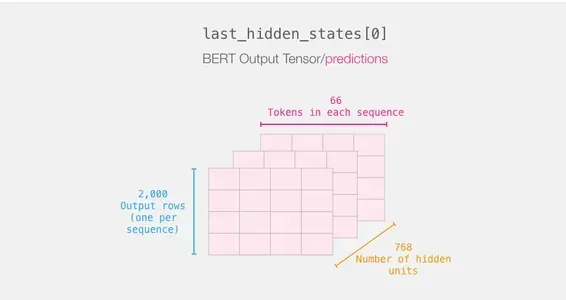
文の旅のおさらい
各行にはデータセットからのテキストが添付されています。最初の文の処理フローを確認するために、次のようにイメージしてください:

重要な部分をスライスする
[CLS]トークンのBERTの結果に興味があるため、文のカテゴリ分類にはそのキューブのスライスのみを選択します。

その3Dテンソルから興味がある2Dテンソルを取得するために、次のようにスライスします:
# すべてのシーケンスの最初の位置の出力をスライスし、すべての隠れユニットの出力を取得します
features = last_hidden_states[0][:,0,:].numpy()最終的に、featuresはデータセットのすべての文の文の埋め込みを含む2Dのnumpy配列です。

ロジスティック回帰の適用
BERTの出力を持っているので、ロジスティック回帰モデルをトレーニングするために必要なデータセットがあります。最初のデータセットの768列は特徴とラベルを含んでいます。

機械学習の従来のトレーニング/テスト分割を行った後、データセットに基づいてロジスティック回帰モデルを定義してトレーニングすることができます。
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)これにより、データセットがトレーニングセットとテストセットに分割されます:

その後、ロジスティック回帰モデルをトレーニングセットを使用してトレーニングします。
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)モデルがトレーニングされた後、その結果をテストセットと比較することができます:
lr_clf.score(test_features, test_labels)これにより、モデルの正確性が約81%であることがわかります。
結論
BERTは、コンピュータが人間の言語をより良く理解するのに役立つ強力な言語モデルです。単語の文脈を考慮し、大量のテキストデータでトレーニングすることで、BERTは意味を捉えて言語理解を向上させることができます。
主なポイント
- BERTは、コンピュータが人間の言語をより良く理解するのに役立つ言語モデルです。
- 文の中の単語の文脈を考慮することで、意味を理解する上でより賢くなります。
- BERTは、言語パターンを学習するために大量のテキストデータでトレーニングされます。
- テキスト分類や質問応答などの特定のタスクに適応することができます。
- BERTは、アプリケーションにおける検索結果や言語理解の向上に貢献します。
- 未知の単語は、より小さな部分に分割することで処理されます。
- BERTは、TensorFlowとPyTorchと共に使用されます。
BERTによって、検索エンジンやテキスト分類などのアプリケーションが改善され、より賢く役立つものとなりました。全体として、BERTはコンピュータが人間の言語をより効果的に理解するための重要な進歩です。
よくある質問
この記事に表示されているメディアはAnalytics Vidhyaの所有ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






