ビジョン-言語モデルへのダイブ
Vision-Language Model.
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。
2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。
このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。
目次
- はじめに
- 学習戦略
- コントラスティブラーニング
- PrefixLM
- クロスアテンションを用いたマルチモーダル融合
- MLM / ITM
- トレーニングなし
- データセット
- 🤗 Transformersでのビジョン言語モデルのサポート
- 研究の新たな展開
- 結論
はじめに
モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか?
これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。
たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。
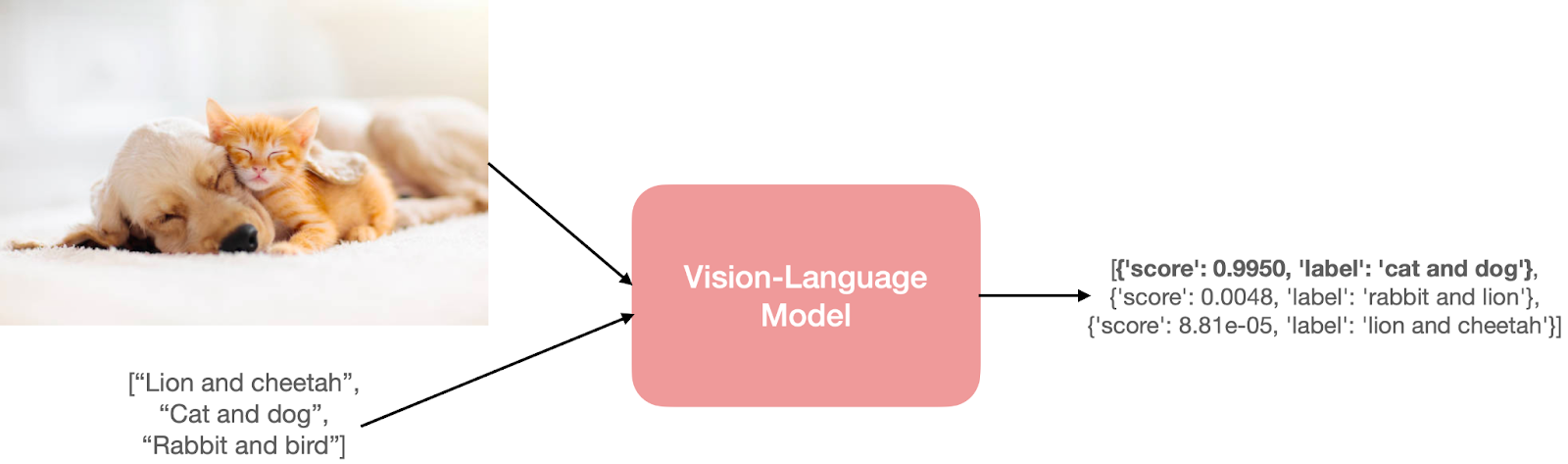 この猫と犬の画像はここから取得しました。
この猫と犬の画像はここから取得しました。
そういった予測をするためには、モデルは入力画像とテキストのプロンプトの両方を理解する必要があります。この理解を実現するために、モデルにはビジョンと言語のための別々または融合したエンコーダーが必要です。
しかし、これらの入力と出力はさまざまな形式で表現することができます。以下にいくつかの例を示します:
- 自然言語テキストからの画像検索。
- フレーズのグラウンディング、つまり、入力画像と自然言語フレーズからのオブジェクト検出(例:若い人がバットを振っています)。
- 視覚的な質問応答、つまり、入力画像と自然言語の質問からの回答の検索。
- 与えられた画像にキャプションを生成する。これは条件付きテキスト生成の形式を取ることもあります。自然言語のプロンプトと画像から始める場合などです。
- 画像とテキストのモダリティを含むソーシャルメディアコンテンツからのヘイトスピーチの検出。
学習戦略
ビジョン言語モデルは通常、画像エンコーダー、テキストエンコーダー、および両方のエンコーダーからの情報を結合するための戦略という3つの主要な要素で構成されています。これらの主要な要素は、損失関数がモデルのアーキテクチャと学習戦略の両方に基づいて設計されているため、密接に結びついています。ビジョン言語モデルの研究は新しい研究分野ではありませんが、これらのモデルの設計は年々大きく変わってきました。以前の研究では、手作業で作成された画像ディスクリプタや事前学習済みの単語ベクトル、または頻度ベースのTF-IDF特徴量を採用していましたが、最新の研究では、画像とテキストのエンコーダーにトランスフォーマーアーキテクチャを使用して画像とテキストの特徴を別々または共同で学習することが主流です。これらのモデルは、さまざまなダウンストリームタスクを可能にする戦略的な事前トレーニング目標で事前トレーニングされます。
このセクションでは、転移性能の観点から優れたパフォーマンスを発揮することが示されたビジョン言語モデルの典型的な事前トレーニング目標と戦略について説明します。また、これらの目標に固有の興味深い要素または事前トレーニングの一般的な構成要素についても触れます。
以下では、事前トレーニング目標に関連する以下のテーマをカバーします:
- コントラスティブラーニング: 画像とテキストを対比的な方法で共通の特徴空間に整列させること
- PrefixLM: 画像を言語モデルの接頭辞として使用して画像とテキストの埋め込みを共同で学習すること
- クロスアテンションを用いたマルチモーダル融合: クロスアテンションメカニズムを使用してビジュアル情報を言語モデルのレイヤーに融合すること
- MLM / ITM: マスクされた言語モデリングと画像テキストマッチングの目的で、画像の一部をテキストと整列させること
- トレーニングなし: イテレーション最適化を介してスタンドアロンのビジョンモデルと言語モデルを使用すること
このセクションは網羅的なリストではなく、他の様々な手法やUnified-IOのようなハイブリッド戦略も存在することに注意してください。マルチモーダルモデルのより包括的なレビューについては、この研究を参照してください。
1) コントラスティブラーニング
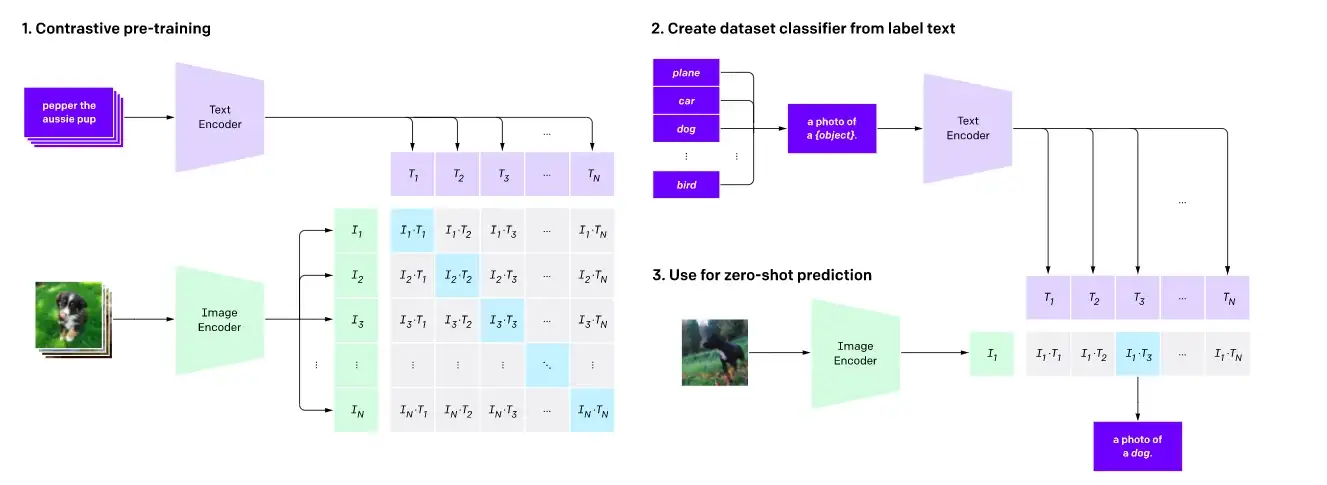 ここに示すように、コントラスティブプリトレーニングとゼロショット画像分類。
ここに示すように、コントラスティブプリトレーニングとゼロショット画像分類。
コントラスティブラーニングは、ビジョンモデルのプリトレーニング目的として一般的に使用されており、ビジョン言語モデルのプリトレーニング目的としても非常に効果的であることが証明されています。CLIP、CLOOB、ALIGN、DeCLIPなどの最近の研究では、大規模な{画像、キャプション}のペアからなるデータセットを使用して、テキストエンコーダと画像エンコーダをコントラスティブロスを用いて共同で学習し、ビジョンと言語のモダリティを結びつけています。コントラスティブラーニングは、入力画像とテキストを同じ特徴空間にマッピングすることを目指し、画像とテキストの埋め込み間の距離を、一致する場合には最小化し、一致しない場合には最大化するようにします。
CLIPでは、距離は単純にテキストと画像の埋め込み間のコサイン距離ですが、ALIGNやDeCLIPなどのモデルは、ノイズのあるデータセットを考慮した独自の距離メトリックを設計しています。
別の研究であるLiTでは、テキストエンコーダをCLIPのプリトレーニング目的でファインチューニングする簡単な方法を紹介していますが、画像エンコーダは固定されたままです。著者たちは、このアイデアを、テキストエンコーダによる画像エンコーダからの画像埋め込みのより良い読み取り方を教える方法として解釈しています。このアプローチは効果的であり、CLIPよりもサンプル効率が高いです。FLAVAなどの他の研究では、コントラスティブラーニングと他のプリトレーニング戦略の組み合わせを使用して、ビジョンと言語の埋め込みを整列させることを目指しています。
2) PrefixLM
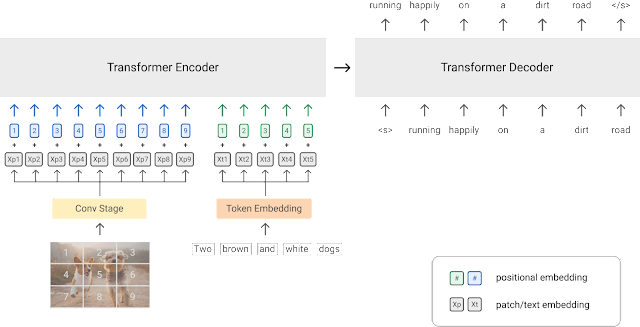 PrefixLMプリトレーニング戦略のダイアグラム(画像の出典)
PrefixLMプリトレーニング戦略のダイアグラム(画像の出典)
ビジョン言語モデルのトレーニングの別のアプローチは、PrefixLM目的を使用することです。SimVLMやVirTexなどのモデルは、このプリトレーニング目的を使用して統合されたマルチモーダルアーキテクチャを特徴としています。このアーキテクチャは、トランスフォーマーエンコーダとトランスフォーマーデコーダからなり、自己回帰言語モデルと同様のものです。
これを詳しく見てみましょう。Prefix目的を持つ言語モデルは、入力テキストをプレフィックスとして次のトークンを予測します。例えば、シーケンス「A man is standing at the corner」を考えてみましょう。「A man is standing at the」をプレフィックスとして使用し、モデルを次のトークン「corner」またはプレフィックスの続きとしての別の適切なトークンの予測を目的としてトレーニングすることができます。
ビジョントランスフォーマ(ViT)は、同じプレフィックスの概念を画像にも適用し、各画像をいくつかのパッチに分割し、これらのパッチを順番にモデルに入力します。このアイデアを活用して、SimVLMは、エンコーダが連結された画像パッチシーケンスとプレフィックステキストシーケンスをプレフィックス入力として受け取り、デコーダがテキストシーケンスの続きを予測します。上記のダイアグラムは、このアイデアを示しています。SimVLMモデルは、最初に画像パッチがプレフィックスに存在しないテキストデータセットでプリトレーニングされ、その後、整列した画像テキストデータセットでプリトレーニングされます。これらのモデルは、画像に基づいたテキスト生成/キャプション付けやVQAタスクに使用されます。
ビジョン情報を言語モデル(LM)に統合して画像に誘導されたタスクに対応するモデルは、印象的な機能を示しています。ただし、PrefixLM戦略のみを使用するモデルは、主に画像キャプションやビジュアルクエスチョンアンサリングのダウンストリームタスク用に設計されているため、応用範囲に制限がある場合があります。例えば、集団の写真が与えられた場合、その写真の説明を書くために画像にクエリを行うことができます(例:「建物の前で一緒に立っている人々のグループが微笑んでいます」)またはビジュアルリーズニングを必要とする質問でクエリを行うこともできます。「赤いTシャツを着ている人は何人いますか?」。一方、マルチモーダル表現を学習するかハイブリッドアプローチを採用するモデルは、オブジェクト検出や画像セグメンテーションなどのさまざまな他のダウンストリームタスクに適応することができます。
凍結されたPrefixLM
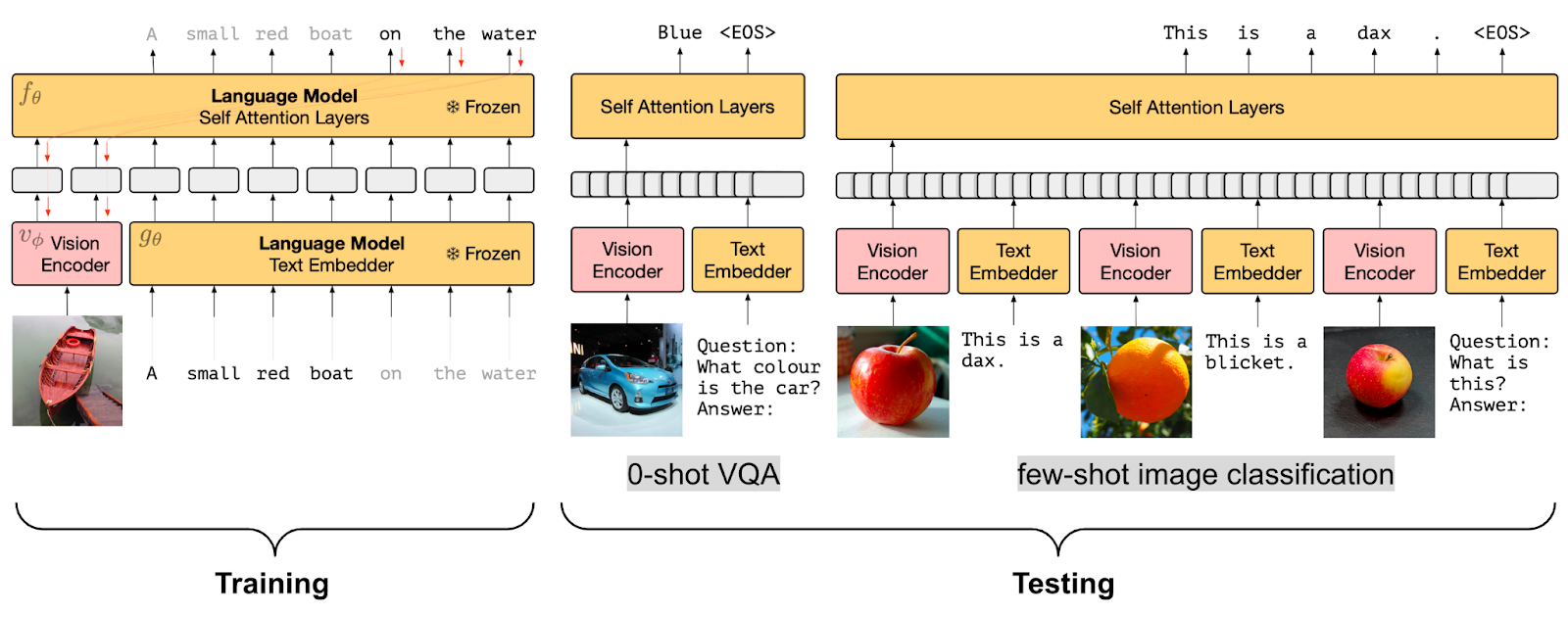 凍結されたPrefixLMプリトレーニング戦略(画像の出典)
凍結されたPrefixLMプリトレーニング戦略(画像の出典)
言語モデル(LM)との整列した画像埋め込みを学習することができるビジョン言語モデルの別のプリトレーニング目的です。
モデルの例として、FrozenとClipCapはこのFrozen PrefixLMの事前学習目的を使用しています。トレーニング中には画像エンコーダのパラメータのみを更新し、トレーニング済みの凍結された言語モデルの前置きとして使用できる画像埋め込みを生成します。これは上記で説明したPrefixLMの目的と同様です。FrozenとClipCapの両方は、画像の埋め込みと前置きテキストを与えた場合に、キャプション内の次のトークンを生成することを目的として、画像とテキスト(キャプション)のデータセットでトレーニングされます。
MAPLやFlamingoなどのモデルでは、事前学習されたビジョンエンコーダと言語モデルの両方を凍結したままにしています。Flamingoは、事前学習済みの凍結されたビジョンモデルの上にPerceiver Resamplerモジュールを追加し、既存の事前学習および凍結されたLMレイヤーの間に新しいクロスアテンションレイヤーを挿入して、LMを視覚データに基づいて条件付けることで、幅広いオープンエンドのビジョンと言語のタスクにおいてfew-shot学習の最新の成果を達成します。
Frozen PrefixLMの事前学習目的の便利な利点は、限られた対応付け済みの画像テキストデータでのトレーニングを可能にし、対応するマルチモーダルデータセットが利用できないドメインに特に有用です。
3) クロスアテンションを用いたマルチモーダル融合
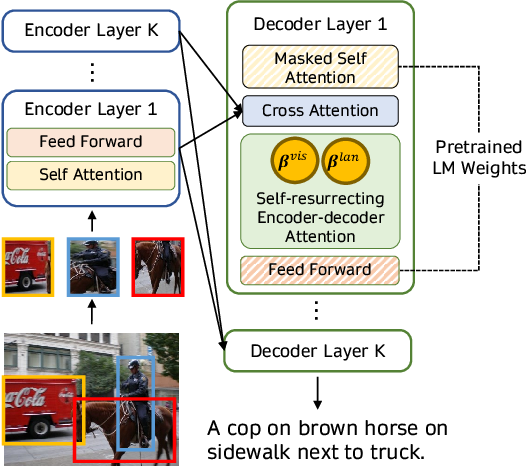 このようなクロスアテンション機構を用いて視覚情報を融合する(画像の出典)
このようなクロスアテンション機構を用いて視覚情報を融合する(画像の出典)
マルチモーダルタスクにおいて事前学習された言語モデルを活用する別のアプローチは、画像を言語モデルのデコーダのレイヤーに直接クロスアテンション機構を使用して融合することです。VisualGPT、VC-GPT、Flamingoなどのモデルは、この事前学習戦略を使用し、画像キャプションやビジュアルクエスチョンアンサリングのタスクでトレーニングされます。このようなモデルの主な目標は、テキスト生成能力と視覚情報を効率的にバランスさせることであり、大規模なマルチモーダルデータセットが存在しない場合に非常に重要です。
VisualGPTなどのモデルは、視覚エンコーダを使用して画像を埋め込み、そのビジュアル埋め込みを事前学習された言語デコーダのクロスアテンションレイヤーにフィードして、妥当なキャプションを生成します。より最近の研究であるFIBERは、ビジョンと言語のバックボーンの両方にゲーティングメカニズムを持つクロスアテンションレイヤーを挿入し、より効率的なマルチモーダル融合を実現し、画像テキストの検索やオープンボキャブラリーオブジェクト検出など、さまざまな他のダウンストリームタスクを可能にします。
4) マスク付き言語モデリング / 画像-テキストマッチング
ビジョン言語モデルのもう1つの系統は、マスク付き言語モデリング(MLM)と画像-テキストマッチング(ITM)の目的を組み合わせて、画像の特定の部分をテキストと整合させ、ビジュアルクエスチョンアンサリング、ビジュアル常識推論、テキストベースの画像検索、テキストガイドのオブジェクト検出など、さまざまなダウンストリームタスクを可能にします。このような事前学習セットアップに従うモデルには、VisualBERT、FLAVA、ViLBERT、LXMERT、BridgeTowerなどがあります。
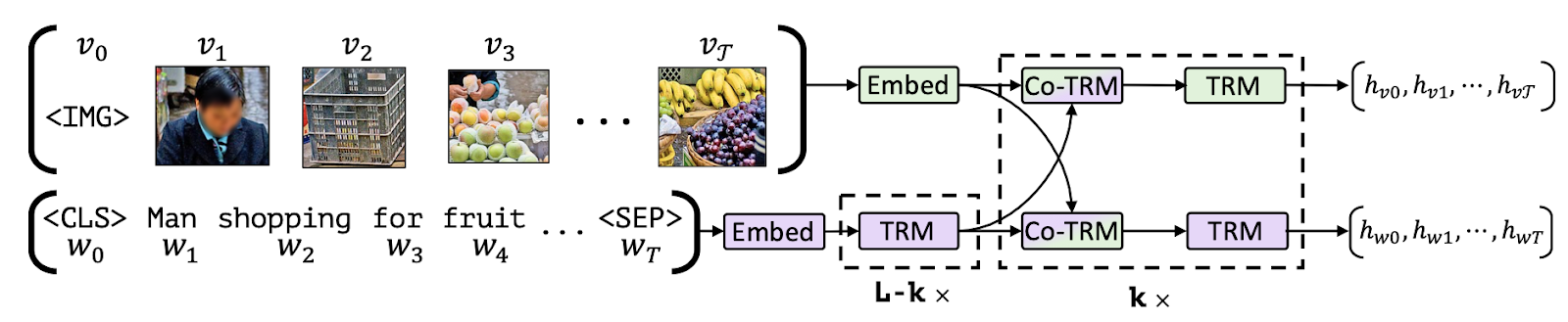 画像の一部をテキストと整合させる(画像の出典)
画像の一部をテキストと整合させる(画像の出典)
MLMとITMの目標が何を意味するかを分解してみましょう。部分的にマスクされたキャプションが与えられた場合、MLMの目的は対応する画像に基づいてマスクされた単語を予測することです。MLMの目的には、バウンディングボックスで豊富に注釈が付けられたマルチモーダルデータセットを使用するか、入力テキストの一部のためのオブジェクト検出モデルを使用してオブジェクト領域の提案を生成する必要があります。
ITMの目的では、画像とキャプションのペアが与えられた場合、キャプションが画像と一致するかどうかを予測するタスクです。ネガティブサンプルは通常、データセット自体からランダムにサンプリングされます。MLMとITMの目的は、マルチモーダルモデルの事前学習中によく組み合わせられます。例えば、VisualBERTは、BERTのようなアーキテクチャを提案し、事前学習されたオブジェクト検出モデルであるFaster-RCNNを使用してオブジェクトを検出します。このモデルは、セルフアテンションを使用して入力テキストの要素と関連する入力画像の領域を暗黙的に整列させるために、MLMとITMの目標の組み合わせを使用します。
別の研究であるFLAVAは、画像エンコーダ、テキストエンコーダ、およびマルチモーダルエンコーダから構成され、画像とテキストの表現を融合し整列させ、マルチモーダル推論を行います。これらはすべてトランスフォーマーに基づいています。FLAVAは、MLM、ITM、マスク付き画像モデリング(MIM)、および対照的な学習など、さまざまな事前学習目的を使用しています。
5) トレーニングなし
最後に、さまざまな最適化戦略は、事前学習済みの画像およびテキストモデルを使用するか、追加のトレーニングなしで事前学習されたマルチモーダルモデルを新しいダウンストリームタスクに適応させることを目指しています。
例えば、MaGiCは、事前学習済みの自己回帰言語モデルを用いて、入力画像に対するキャプションを生成するための反復的な最適化を提案しています。これを行うために、MaGiCは生成されたトークンと入力画像のCLIP埋め込みを使用してCLIPベースの「Magicスコア」を計算します。
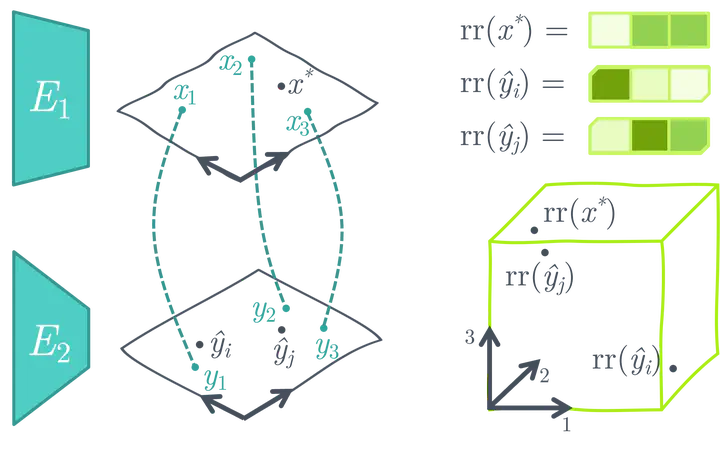 プレトレーニング済みの凍結されたユニモーダルの画像とテキストエンコーダを使用して類似性検索空間を作成する(画像のソース)
プレトレーニング済みの凍結されたユニモーダルの画像とテキストエンコーダを使用して類似性検索空間を作成する(画像のソース)
ASIFは、追加のトレーニングなしで比較的小さいマルチモーダルデータセットを使用して、事前トレーニングされたユニモーダルの画像モデルとテキストモデルをマルチモーダルモデルに変換する簡単な方法を提案しています。ASIFの背後にある主要な直感は、類似した画像のキャプションも互いに類似しているということです。したがって、マルチモーダルのグラウンドトゥルースの小さなデータセットを使用して相対的な表現空間を作成することで、類似性に基づく検索を行うことができます。
データセット
ビジョン言語モデルは、通常、事前トレーニングの目的に基づいて構造が異なる大規模な画像とテキストのデータセットでトレーニングされます。事前トレーニングが完了した後、タスク固有のデータセットを使用してさまざまな下流タスクでさらに微調整されます。このセクションでは、ビジョン言語モデルのトレーニングと評価に使用されるいくつかの人気のある事前トレーニングおよび下流のデータセットについて概説します。
事前トレーニングデータセット
ビジョン言語モデルは、一般に、マッチング画像/ビデオとテキストのペアの形式でウェブから収集された大規模なマルチモーダルデータセットで事前トレーニングされます。これらのデータセットのテキストデータには、人間によって生成されたキャプション、自動生成されたキャプション、画像のメタデータ、または単純なオブジェクトのラベルが含まれることがあります。このような大規模なデータセットの例には、PMDとLAION-5Bがあります。PMDデータセットは、Flickr30K、COCO、Conceptual Captionsなどの複数の小規模データセットを組み合わせたものです。COCO検出および画像キャプション(> 330K画像)データセットには、各画像が含むオブジェクトのテキストラベルと自然な文の説明がペアになっています。Conceptual Captions(> 3.3M画像)およびFlickr30K(> 31K画像)データセットは、画像のキャプション(画像を説明する自由形式の文)と共にウェブからスクレイピングされます。
Flickr30Kなどの人間によって生成されたキャプションのみで構成される画像テキストデータセットは、ユーザーが画像のために記述的または反射的なキャプションを書くことはまれであるため、ノイズが含まれる傾向があります。この問題を克服するために、LAION-5Bデータセットなどのデータセットでは、CLIPや他の事前トレーニング済みのマルチモーダルモデルを使用してノイズのあるデータをフィルタリングし、高品質なマルチモーダルデータセットを作成しています。さらに、ALIGNなどのいくつかのビジョン言語モデルでは、さらなる前処理手法を提案し、独自の高品質なデータセットを作成しています。LSVTDやWebVidなどの他のビジョン言語データセットは、ビデオとテキストのモダリティで構成されていますが、規模は小さいです。
下流のデータセット
事前トレーニングされたビジョン言語モデルは、一般に、ビジュアルクエスチョンアンサリング、テキストガイドされたオブジェクト検出、テキストガイドされた画像補完、マルチモーダル分類などのさまざまな下流タスクでトレーニングされます。
ビジュアルクエスチョンアンサリングの下流タスクで微調整されたモデル(例:ViLT、GLIP)は、VQA(ビジュアルクエスチョンアンサリング)、VQA v2、NLVR2、OKVQA、TextVQA、TextCaps、VizWizなどのデータセットを最も一般的に使用します。これらのデータセットには通常、画像と複数のオープンエンドの質問と回答がペアになっています。さらに、VizWizやTextCapsなどのデータセットは、画像セグメンテーションやオブジェクトの位置特定などの下流タスクにも使用することができます。その他の興味深いマルチモーダル下流データセットには、マルチモーダル分類用のHateful Memes、ビジュアルエンテールメント予測用のSNLI-VE、およびビジョン言語的な合成的推論用のWinogroundがあります。
ビジョン言語モデルは、テキストまたは画像の分類などのさまざまな古典的なNLPおよびコンピュータビジョンタスクに使用され、通常、そのような下流タスクにはユニモーダルデータセット(SST2、ImageNet-1kなど)が使用されます。さらに、COCOやConceptual Captionsなどのデータセットは、モデルの事前トレーニングおよびキャプション生成の下流タスクの両方で一般的に使用されます。
🤗 Transformersでのビジョン言語モデルのサポート
Hugging Face Transformersを使用すると、さまざまな事前トレーニング済みのビジョン言語モデルを簡単にダウンロード、実行、および微調整したり、事前トレーニングされたビジョンモデルと言語モデルを組み合わせて独自のレシピを作成したりすることができます。🤗 Transformersでサポートされている一部のビジョン言語モデルは次のとおりです:
- CLIP
- FLAVA
- GIT
- BridgeTower
- GroupViT
- BLIP
- OWL-ViT
- CLIPSeg
- X-CLIP
- VisualBERT
- ViLT
- Lit(
VisionTextDualEncoderのインスタンス) - TrOCR(
VisionEncoderDecoderModelのインスタンス) VisionTextDualEncoderVisionEncoderDecoderModel
CLIP、FLAVA、BridgeTower、BLIP、LiT、VisionEncoderDecoderモデルなどは、イメージとテキストの埋め込みを提供し、ゼロショットイメージ分類などのダウンストリームタスクに使用できます。他のモデルは興味深いダウンストリームタスクで訓練されます。さらに、FLAVAはユニモーダルおよびマルチモーダルな事前トレーニング目標で訓練され、ユニモーダルビジョンまたは言語タスクおよびマルチモーダルタスクの両方に使用できます。
例えば、OWL-ViTはゼロショット/テキストガイドおよびワンショット/イメージガイドの物体検出を可能にし、CLIPSegとGroupViTはテキストおよびイメージガイドのイメージセグメンテーションを可能にし、VisualBERT、GIT、ViLTは視覚的な質問応答およびその他のさまざまなタスクを可能にします。X-CLIPはビデオとテキストのモダリティで訓練されたマルチモーダルモデルであり、CLIPのゼロショットイメージ分類能力に類似したゼロショットビデオ分類を可能にします。
他のモデルとは異なり、VisionEncoderDecoderModelは、エンコーダとして事前トレーニングされたTransformerベースのビジョンモデル(例:ViT、BEiT、DeiT、Swin)とデコーダとして事前トレーニングされた言語モデル(例:RoBERTa、GPT2、BERT、DistilBERT)を使用してイメージからテキストモデルを初期化するために使用できる汎用モデルです。実際、TrOCRはこの汎用クラスのインスタンスです。
これらのモデルのいくつかで実験してみましょう。視覚的な質問応答にはViLTを、ゼロショットイメージセグメンテーションにはCLIPSegを使用します。まず、🤗Transformersをインストールしましょう:pip install transformers。
VQAのためのViLT
ViLTから始めて、VQAデータセットで事前トレーニングされたモデルをダウンロードしましょう。対応するモデルクラスを初期化し、from_pretrained()メソッドを呼び出して所望のチェックポイントをダウンロードします。
from transformers import ViltProcessor, ViltForQuestionAnswering
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")次に、2匹の猫のランダムな画像をダウンロードし、画像とクエリの質問の両方を前処理してモデルが期待する入力形式に変換します。これには、対応する前処理クラス(ViltProcessor)を使用して、対応するチェックポイントの前処理設定で初期化します。
import requests
from PIL import Image
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# 入力画像をダウンロードします
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "猫は何匹いますか?"
# 入力を準備します
inputs = processor(image, text, return_tensors="pt")最後に、前処理済みの画像と質問を入力として使用して推論を行い、予測された回答を表示できます。ただし、重要なポイントは、テキスト入力がトレーニングセットで使用される質問テンプレートに似ていることを確認することです。質問の形成方法については、論文とデータセットを参照してください。
import torch
# 順方向のパス
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("予測された回答:", model.config.id2label[idx])簡単ですね?次に、CLIPSegを使用してゼロショットイメージセグメンテーションを行うデモンストレーションを行いましょう。
ゼロショットイメージセグメンテーションのためのCLIPSeg
CLIPSegForImageSegmentationとそれに対応する前処理クラスを初期化し、事前トレーニングされたモデルをロードします。
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")次に、同じ入力画像を使用し、セグメント化したいすべてのオブジェクトのテキスト説明でモデルにクエリを行います。他の前処理器と同様に、CLIPSegProcessorは、モデルが期待する形式に入力を変換します。複数のオブジェクトをセグメント化したいので、各テキスト説明ごとに同じ画像を入力します。
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["猫", "リモコン", "ブランケット"]
inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")ViLTと同様に、モデルの推論中に最高のパフォーマンスを得るために、モデルをトレーニングするために使用されるテキストプロンプトの種類を確認するために元の作品を参照することが重要です。CLIPSegは、シンプルなオブジェクトの説明(例:「車」)でトレーニングされていますが、そのCLIPバックボーンはエンジニアリングされたテキストテンプレート(例:「車の画像」、「車の写真」)で事前にトレーニングされ、トレーニング中に固定されています。入力が前処理されると、各テキストクエリに対して形状(高さ、幅)の2値セグメンテーションマップを取得するために推論を実行できます。
import torch
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
print(logits.shape)
>>> torch.Size([3, 352, 352])CLIPSegのパフォーマンスを確認するために結果を可視化しましょう(コードはこの投稿から適応されたものです)。
import matplotlib.pyplot as plt
logits = logits.unsqueeze(1)
_, ax = plt.subplots(1, len(texts) + 1, figsize=(3*(len(texts) + 1), 12))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(logits[i][0])) for i in range(len(texts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(texts)]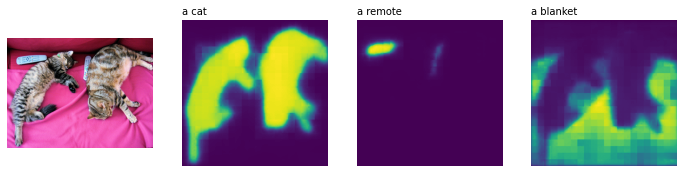
素晴らしいですね。
ビジョン言語モデルは、VQAやゼロショットセグメンテーションにとどまらない、さまざまな有用な興味深いユースケースを可能にします。このセクションで紹介されたモデルがサポートするさまざまなユースケースを試してみることをお勧めします。サンプルコードについては、各モデルの詳細なドキュメントを参照してください。
新興研究分野
ビジョン言語モデルの大幅な進展に伴い、医学やロボット工学など、新しいダウンストリームタスクやアプリケーション領域が登場しています。例えば、ビジョン言語モデルは、医療の用途にますます採用されており、放射線写真の医学的診断と報告生成のためのClinical-BERTや、医療領域でのビジュアル質問応答のためのMedFuseNetなどの研究が行われています。
また、スタイルCLIP、スタイルMC、DiffusionCLIPなどの作品では、ビジョン言語表現を活用した画像操作、X-CLIPなどのテキストベースのビデオ検索、Text2Liveなどの操作、AvatarCLIP、CLIP-NeRF、Latent3D、CLIPFace、Text2Meshなどの3D形状とテクスチャの操作が行われています。同様の作品の中で、MVTは3Dシーンテキスト表現モデルを提案し、3Dシーン完成などのさまざまなダウンストリームタスクに使用できます。
ロボティクス研究はまだ広範な範囲でビジョン言語モデルを利用していませんが、CLIPortなどの作品では、ビジョン言語表現を活用してエンドツーエンドの模倣学習を行い、従来のSOTAと比較して大幅な改善を実現しています。また、大規模な言語モデルは、共通のセンスの推論、ナビゲーション、タスク計画などのロボティクスタスクでも使用されるようになっています。たとえば、ProgPromptは大規模な言語モデル(LLM)を使用して配置されたロボットタスクプランを生成するためのフレームワークを提案しています。同様に、SayCanは環境と利用可能なオブジェクトのビジュアル説明を考慮に入れて、最も妥当なアクションを選択するためにLLMを使用します。これらの進展は印象的ですが、ロボティクス研究はオブジェクト検出データセットの制約により、限られた環境とオブジェクトのセットに制約されています。OWL-ViTやGLIPなどのオープンボキャブラリオブジェクト検出モデルの登場により、マルチモーダルモデルとロボットナビゲーション、推論、操作、タスク計画フレームワークのより密な統合が期待されます。
結論
近年、マルチモーダルモデルは非常に進化しており、ビジョン言語モデルはパフォーマンスとユースケースの多様性の面で最も大きな飛躍を遂げています。このブログでは、ビジョン言語モデルの最新の進展、利用可能なマルチモーダルデータセット、これらのモデルをトレーニングして微調整するために使用できる事前トレーニング戦略について話しました。また、これらのモデルが🤗 Transformersに統合されている方法と、数行のコードでさまざまなタスクを実行する方法を示しました。
私たちは、最も影響力のあるコンピュータビジョンとマルチモーダルモデルを統合し続けており、皆様からのご意見をお待ちしています。マルチモーダル研究の最新ニュースを知るには、Twitterで私たちをフォローしてください:@adirik、@NielsRogge、@apsdehal、@a_e_roberts、@RisingSayak、および@huggingface。
謝辞:Amanpreet SinghさんとAmy Robertsさんには、厳密なレビューをしていただきました。また、Hugging FaceのNiels Roggeさん、Younes Belkadaさん、Suraj Patilさんをはじめ、多くの方々がマルチモーダルモデルの利用拡大の基盤を築いてくださったことに感謝申し上げます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





