「V-Net、イメージセグメンテーションにおけるU-Netの兄貴」
V-Net, U-Net's big brother in image segmentation.
V-Netへようこそ!3D画像のセグメンテーションにおけるU-Netのいとこです。それを中から外まで熟知することになります!
ディープラーニングアーキテクチャの世界へのエキサイティングな旅へようこそ!おそらく、画像セグメンテーションの風変わりな方法であるU-Netには既に慣れているかもしれません。U-Netはコンピュータビジョンにおいて大きな影響を与え、画像セグメンテーションの風景を大幅に変えることになりました。
今日は、U-Netの兄弟であるV-Netにスポットライトを当てましょう。
研究者のFausto Milletari、Nassir Navab、Seyed-Ahmad Ahmadiによって発表された論文「VNet: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation」は、3D画像解析のための画期的な手法を紹介しています。
この記事では、この画期的な論文について詳しく解説し、その独自の貢献とアーキテクチャの進歩に光を当てます。経験豊富なデータサイエンティスト、新興のAI愛好家、最新のテクノロジートレンドに興味を持つ人々にとって、何かしらの価値があるはずです!
- データ駆動型のディスパッチ
- 「Salesforce Data Cloudを使用して、Amazon SageMakerで独自のAIを持ち込む」
- 「Amazon SageMakerとSalesforce Data Cloudの統合を使用して、SalesforceアプリをAI/MLで強化しましょう」
U-Netについての簡単なリマインダー
V-Netの核心に入る前に、そのアーキテクチャのインスピレーションであるU-Netを少し紹介しましょう。初めてU-Netに触れる方でも大丈夫です。U-Netのアーキテクチャについての簡単でわかりやすいチュートリアルを用意しました。たった5分で概念を理解することができます!
以下はU-Netの概要です:
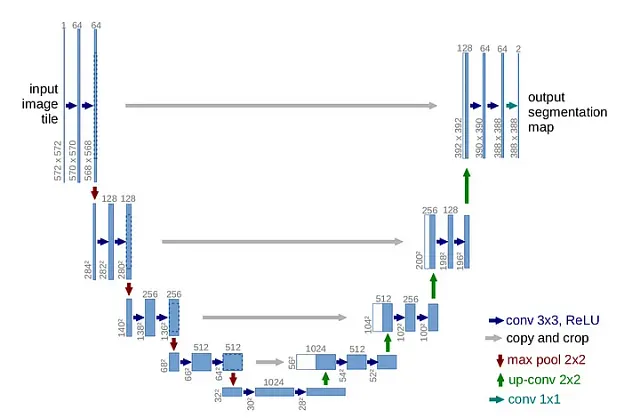
U-Netは、その対称的な構造で有名であり、「U」の形をしています。このアーキテクチャは2つの異なるパスウェイで構成されています:
- Contracting Pathway(左):ここでは、イメージの解像度を徐々に減少させながら、フィルタの数を増やしていきます。
- Expanding Pathway(右):このパスウェイは、Contracting Pathwayのミラーイメージとして機能します。解像度を徐々に増加させながら、フィルタの数を減少させ、元のイメージサイズと一致させます。
U-Netの美しさは、「残差接続」または「スキップ接続」という革新的な使用方法にあります。これらは、Contracting PathwayとExpanding Pathwayの対応する層を接続し、通常Contractingプロセスで失われる高解像度の詳細を保持することができます。
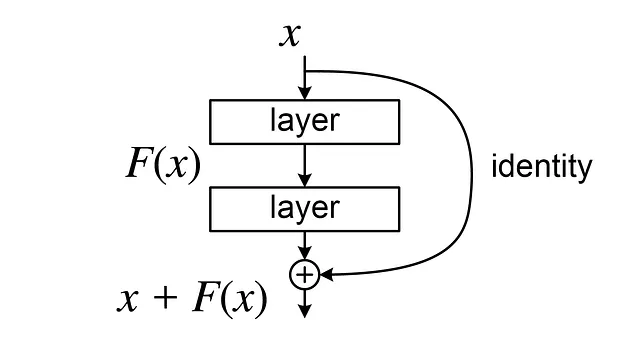
なぜこれが重要なのでしょうか?それは、特に初期の層でバックプロパゲーション中の勾配フローを容易にするからです。要するに、勾配がゼロに近づく「消失勾配」という一般的な問題を回避することができます:
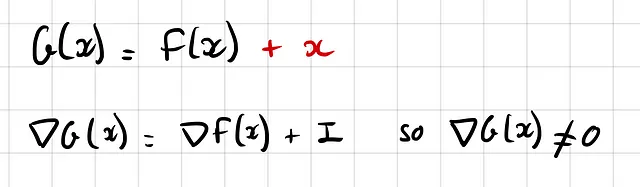
さて、このU-Netの理解を念頭に置いたまま、V-Netの世界に移行しましょう。V-Netは本質的には同様のエンコーダーデコーダーの哲学を共有しています。しかし、すぐに発見するでしょうが、U-Netとは異なる独自の特徴を持っています。
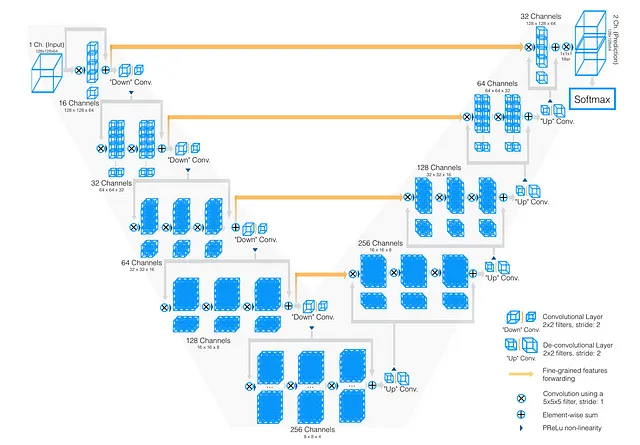
V-NetをU-Netから異なるものにする要素とは何でしょうか?
さあ、ダイブしましょう!
違い1:2次元畳み込みではなく3次元畳み込み
最初の違いは明らかです。U-Netは2次元画像セグメンテーションに特化されていましたが、医療画像では3次元の視点が必要です(体積的な脳スキャン、CTスキャンなどを考えてください)。
それがV-Netの出番です。V-Netの「V」は「ボリューメトリック」を意味し、この次元のシフトにより、2次元畳み込みを3次元畳み込みに置き換える必要があります。
違い2:活性化関数、ReLUの代わりにPreLU
深層学習の領域では、シンプルさと計算効率性からReLU関数が非常に愛されています。シグモイドやtanhなどの他の関数と比較して、ReLUは「飽和しない」という特徴があり、勾配消失の問題を軽減します。
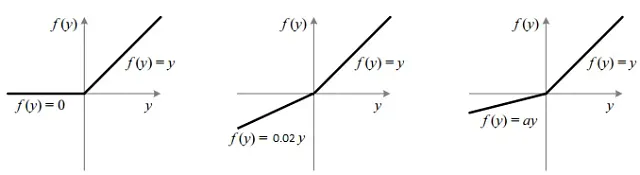
しかし、ReLUは完璧ではありません。多くのニューロンが常にゼロを出力し、”dead neurons”となる「Dying ReLUの問題」として知られています。これに対抗するために、左側のゼロに小さなが非ゼロの傾きを持つLeakyReLUが導入されました。
さらに論理を推し進めると、V-NetはParametric ReLU(PReLU)を活用しています。LeakyReLUの傾きをハードコーディングする代わりに、ネットワークに学習させるのはいかがでしょうか?
なぜなら、これはディープラーニングの基本的な哲学です。なるべく帰納バイアスを入れずに、モデルがすべてを自己学習することを望んでいるからです。十分なデータがあると仮定します。
違い3:Diceスコアに基づく異なる損失関数
さて、おそらくV-Netの最も影響力のある貢献に到着しました。V-NetはU-Netのクロスエントロピー損失関数とは異なり、Dice損失関数を使用しています。

ただし、この関数の主な問題は、クラスのバランスが悪い場合に適切に処理できないことです。これは医療画像では非常に頻繁に発生する問題であり、背景が関心領域よりもはるかに存在することがほとんどです。
例えば、この画像を考えてみてください:
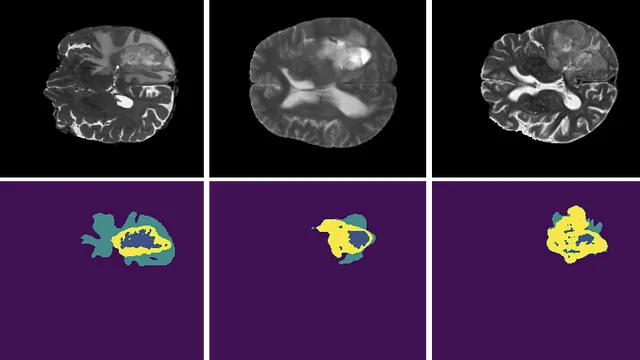
その結果、一部のモデルは背景を予測し続け、小さな損失を得ることができるため、「怠惰」になる可能性があります。
したがって、V-Netではこの問題に対してはるかに効果的な損失関数を使用しています:Dice係数。
それがより良い理由は、予測された領域と正解の領域の重なりを「比率」として測定するため、クラスのサイズが考慮されることです。
背景がほぼどこにでも存在するとしても、Diceスコアは予測と正解の重なりを測定するため、クラスが優勢であるにも関わらず0から1の数値が得られます。
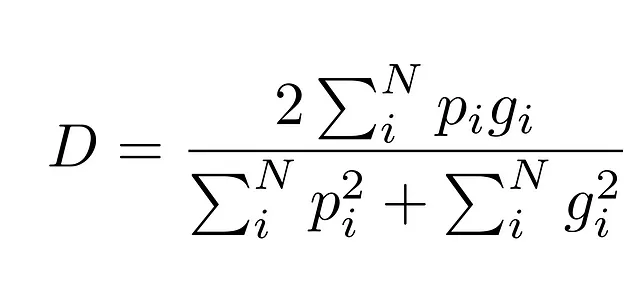
2Dから3D畳み込みへの移行は、3D画像を扱うための非常に自然なアイデアであるため、この記事の主要な貢献であると言っています。ただし、この損失関数は画像セグメンテーションのタスクで非常に広く採用されています。
実際のところ、ハイブリッドアプローチは、クロスエントロピーロスとダイスロスを組み合わせることで、両方の強みを活用することがよく効果的です。
V-Netのパフォーマンス
それでは、V-Netのユニークな側面を旅してきましたが、おそらく「このすべての理論は素晴らしいですが、V-Netは実際に実用的な成果をもたらすのでしょうか?」と思っているかもしれません。さて、V-Netをテストしてみましょう!
著者たちは、PROMISE12データセット上でV-Netのパフォーマンスを評価しました。
PROMISE12データセットは、MICCAI 2012プロステイトセグメンテーションチャレンジのために提供されました。
V-Netは50の磁気共鳴(MR)画像で訓練されました。これはそれほど多くありません!
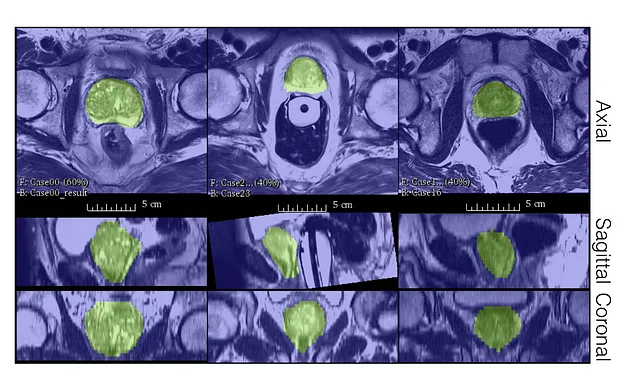
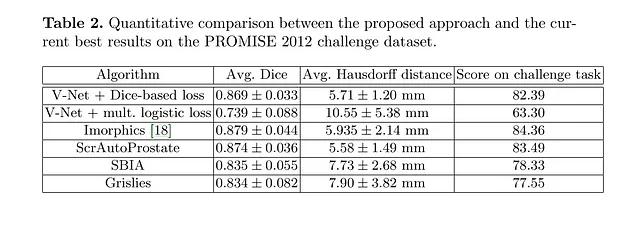
見てわかるように、ラベルが少なくてもV-Netは良い質のセグメンテーションを生成し、非常に良いダイススコアを獲得することができます。
V-Netの主な制限事項
確かに、V-Netは画像セグメンテーションの領域で新たな基準を設定しましたが、すべてのイノベーションには成長の余地があります。ここでは、V-Netが改善できるいくつかの主要な領域について説明します。
制限1:モデルのサイズ
2Dから3Dへの移行には、メモリ消費量の大幅な増加が伴います。この増加の波及効果は多岐にわたります:
- モデルは大量のメモリスペースを要求します。
- 複数の3DテンソルをGPUメモリに読み込むことが難しくなるため、バッチサイズが制限されます。
- 医療画像データは疎であり、ラベル付けするのが困難なため、そんなに多くのパラメータを持つモデルを適合させるのが難しくなります。
制限2:教師なし学習や自己教師あり学習を使用しない
- V-Netは純粋に教師あり学習の文脈で動作し、教師なし学習の可能性を無視しています。ラベルのないスキャンは注釈付きのものよりもはるかに多いため、教師なし学習を取り入れることはゲームチェンジャーになる可能性があります。
制限3:不確実性の推定がない
- V-Netは不確実性を推定せず、自身の予測の信頼性を評価することができません。これはベイズ深層学習の得意とする領域です(ベイズ深層学習の初心者向けのガイドは、この記事を参照してください)。
制限4:頑健性の欠如
- 畳み込みニューラルネットワーク(CNN)は一般化に苦労することが伝統的にあります。対比変化、多峰分布、異なる解像度などの変動に対して頑健ではありません。これもV-Netが改善できる領域です。
結論
U-Netのパワフルな対照的な存在であるV-Netは、特に医療画像において、コンピュータビジョンを革新しました。2Dから3D画像への移行とダイス係数の導入は、現在では普遍的なツールとなり、新たな基準を設定しました。
制限事項があるにもかかわらず、V-Netは3D画像セグメンテーションの課題に取り組む際のモデルの選択肢となるべきです。さらなる改善のために、教師なし学習の探求やアテンションメカニズムの統合など、有望なアプローチを探索してみることが重要です。
フィードバックや共有のアイデア、一緒に働きたい、または単にこんにちはと言いたい場合は、以下のフォームに記入して、会話を始めましょう。
こんにちは 🌿
拍手を残したり、もっとフォローしてもらえるとうれしいです!
参考文献
- 画像セグメンテーションのための最初のU-Netの作り方
- ベイジアンディープラーニングの優しい入門
- Milletari, F., Navab, N., & Ahmadi, S. A. (2016). V-Net: 体積医療画像セグメンテーションのための完全畳み込みニューラルネットワーク. In 3D Vision (3DV), 2016 Fourth International Conference on (pp. 565–571). IEEE.
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: バイオメディカル画像セグメンテーションのための畳み込みネットワーク. In International Conference on Medical image computing and computer-assisted intervention (pp. 234–241). Springer, Cham.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
