「ベクトルデータベースの力を活用する:個別の情報で言語モデルに影響を与える」
Utilizing the power of vector databases influencing language models with individual information.
ベクトルデータベースで言語モデルを強化しましょう!パーソナライズドなプロンプトを使用して、これらの強力なモデルの振る舞いを形成し、それに文脈を与えましょう。カスタマイズされた言語生成体験のためにパーソナル情報を統合しましょう。
この記事では、ベクトルデータベースと大規模な言語モデルという2つの新しいテクノロジーがどのように連携して働くかについて学びます。この組み合わせは現在、テクノロジー業界で大きな変革を引き起こしています。
これは通常、言語モデルが訓練されていない自分自身のドキュメントや企業の知識データベースを組み込むために使用されます。そのアイデアは、モデルの応答を生成する際にそのような情報が考慮されることを確保することです。言い換えれば、モデルに有用な情報へのアクセスを与え、その出力をより良く、より関連性があるものにすることです。
それが私たちが探求するユースケースです。以下では、以下の手順に従います:
- ChromaDBを使用してベクトルデータベースを作成します。
- データベースに情報を保存します。
- クエリを介して情報を取得します。
- この情報を使用して拡張プロンプトを生成します。
- Hugging Faceからモデルをロードします。
- プロンプトをモデルに渡します。
- モデルは提供された情報を考慮に入れて応答を提供します。
これらの手順に従うことで、ChromaDBを使用して言語モデルの意思決定プロセスにパーソナル情報を簡単に追加することができます。
この方法で、高度にカスタマイズされた文脈に即した応答を得ることができます。
それでは、各ステップについて詳しく見てみましょう!
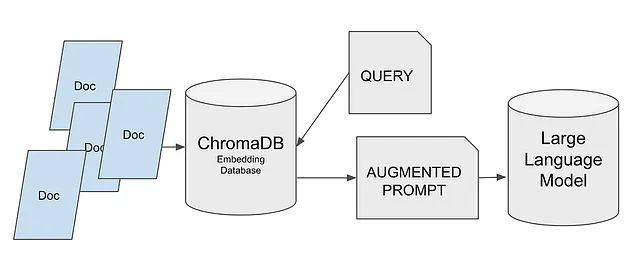
しかし、はじめる前に、ベクトルデータベースの動作原理について簡単に紹介しましょう。
ベクトルデータベースはどのように動作するのでしょうか
まず、これらのデータベースは、その名前が示すように、ベクトルを格納します。私たちは持っているテキストをこれらのツールで格納できる情報に変換する必要があります。言い換えれば、テキストをベクトルに変換する必要があります。
さまざまなアプローチがありますが、要約すると、すべてのアプローチは、単語、音節、またはフレーズのようなテキストのシーケンスをベクトルに変換します。
取得したベクトルは多次元ですし、自然に、1つのベクトルと別のベクトルの間の差を計算したり、特定のベクトルに近いベクトルを検索したりすることができます。
この情報を使用することで、一般的な動作原理を理解することができます。
- テキストをベクトルに変換して格納します。
- 検索するテキストをベクトルに変換して比較します。
- 最も近いベクトルを選択します。
- これらのベクトルをテキストに変換して返します。
テキスト検索については忘れましょう!すべてはベクトルの比較にかかっています。
おそらくすでに想像しているかもしれませんが、テキストをベクトルに変換するプロセスは、格納されたテキストと検索するテキストの両方に対して同じである必要があります。そうでなければ、比較は意味をなさなくなってしまいます。
ベクトルデータベースは、関連するニュースを検索するような私たちのようなケースだけでなく、任意のレコメンデーションシステムにおいてもますます重要性を増しています。
実際、ベクトルは本質的に数値表現であり、テキストから生じる必要はありません。映画をベクトルに変換し、メタデータと一緒に格納し、最も似ているものを検索することができます。ユーザーの視聴習慣に基づいて映画を推奨するためのパターンを特定することさえできます。ちょっと待って…Netflixもレコメンデーションシステムにそれらを使用しているのではないでしょうか?賭けましょうか?
どのようなテクノロジーを使用しますか
データベースに関しては、ChromaDBを選びました。これは最新のデータベースの一つであり、急速に人気を集めています。その使用方法は非常に簡単です!私たちはほとんど心配する必要がありません、なぜならChromaDBが私たちのためにほとんどの作業を処理してくれるからです。これはオープンソースのソリューションであり、重要な点として、将来の記事ではLangChainを使用してますます複雑なソリューションを構築する予定です。
私たちはHugging Faceからモデルを取得します。具体的には、dolly-v2-3bを使用しました。これはDollyモデルファミリーの最小バージョンです。可能な限り小さいモデルの使用をお勧めします。
個人的には、機会があるときにはいつでも異なるモデルで実験することを楽しんでおり、Hugging Faceでは多種多様なモデルを選ぶことができます。
異なるモデルを試してみたい場合は、Hugging Faceで検索し、テキスト生成のためにトレーニングされていることを確認してください。

プロジェクトを始めましょう!
Kaggleのノートブックでコードを見つけることができます。ノートブックをフォークして実行、実験することができます。また、対応する記事と共に、すべてのノートブックを保存しているGitHubのリポジトリでも利用できます。
ベクトルデータベースを使用してLLMsのプロンプトを最適化する
複数のデータソースからのデータを使用してKaggleノートブックで機械学習コードを探索および実行する
www.kaggle.com
GitHub – peremartra/Large-Language-Model-Notebooks-Course
GitHubでアカウントを作成してperemartra/Large-Language-Model-Notebooks-Courseの開発に貢献しましょう。
github.com
コース全体をフォローする興味がある場合は、GitHubリポジトリに登録するのが最適です。 これにより、新しいレッスンや既存のレッスンの変更に関する通知を受け取ることができます。
必要なライブラリをインポートしましょう。
始めるには、いくつかのPythonパッケージをインストールする必要があります:
- sentence-transformers:文を固定長のベクトルに変換するために必要なライブラリです。
- transformers:このパッケージは、トランスフォーマーモデルでの作業を容易にするさまざまなライブラリとユーティリティを提供します。直接使用しないかもしれませんが、インストールしないとモデルの作業時にエラーメッセージが表示されます。
- chromadb:ベクトルデータベースです。使いやすく、オープンソースで高速です。埋め込みを格納するための最も広く使用されているベクトルデータベースです。
次のコマンドを使用してこれらのパッケージをインストールできます:
!pip install sentence-transformers!pip install xformers!pip install chromadb次の2つのライブラリはおそらくお馴染みです:NumpyとPandas。これらはデータサイエンスで最も広く使用されているPythonライブラリの2つです。
Numpyは数値計算のためのライブラリで、簡単に数学計算を行うことができます。
Pandasはデータの操作と分析におけるデファクトスタンダードのライブラリです。
import numpy as np import pandas as pdデータセットをロードする。
私はKaggleで利用可能な3つの異なるデータセットで作業するためにノートブックを準備しました。すべてのデータセットにはニュース記事が含まれていますが、異なる形式で提供されています。2つのデータセットには記事の要約のみが含まれており、3番目のデータセットには記事の全文が含まれています。
トピックラベル付きニュースデータセット
8つのトピック(バランス)にラベル付けされた108774のニュース記事
www.kaggle.com
BBCニュース
自己更新データセット – BBCニュースRSSフィード
www.kaggle.com
MIT AIニュース2023年までの公開
MITのウェブサイトで公開されたすべてのAI関連ニュース。
www.kaggle.com
ノートブックを3つの異なるデータセットで動作させる唯一の理由は、異なる入力に対するソリューションの反応を実験して確認するためです。好きなだけデータセットを試すことができます。ソリューションの振る舞いやパフォーマンスを異なるデータソースで観察し理解することが目的です。
KaggleやColabなどのリソースが限られているプラットフォームで作業しているため、読み込むニュース記事の数に制限を設けました。この制限は変数MAX_NEWSで定義されています。
ニュース記事を含むフィールド名は変数DOCUMENTに、メタデータやカテゴリと考えられる情報は変数TOPICに格納されています。これにより、ノートブックの他の部分を特定のデータセットから分離することができます。
使用するデータセットに対してコメントマーカーを削除するだけで使用できます。
news = pd.read_csv('/kaggle/input/topic-labeled-news-dataset/labelled_newscatcher_dataset.csv', sep=';')MAX_NEWS = 1000DOCUMENT="title"TOPIC="topic"#news = pd.read_csv('/kaggle/input/bbc-news/bbc_news.csv')#MAX_NEWS = 1000#DOCUMENT="description"#TOPIC="title"#news = pd.read_csv('/kaggle/input/mit-ai-news-published-till-2023/articles.csv')#MAX_NEWS = 100#DOCUMENT="Article Body"#TOPIC="Article Header"#コースの一環としてNewsの一部を選択するために、ニュースの一部を選択します。subset_news = news.head(MAX_NEWS)ベクトルデータベースのインポートと設定
まず、ChromaDBをインポートします。次に、configモジュールからそのSettingsクラスをインポートします。このクラスを使用すると、ChromaDBシステムの設定を変更し、動作をカスタマイズすることができます。
import chromadbfrom chromadb.config import Settingsライブラリをインポートしたので、インポートしたSettingsクラスを呼び出して設定オブジェクトを作成しましょう。
設定オブジェクトは2つのパラメータで作成されます。
- chroma_db_impl: データベースの実装とデータの保存形式を指定します。すべての選択肢の詳細については説明しませんが、選んだものの背後にある理由を説明します: — 実装には「duckdb」を選択しました。これはほとんどメモリ上で動作するため、優れたパフォーマンスを提供します。また、SQLと完全に互換性があります。 — データ形式として「parquet」を使用します。これは表形式のデータに最適な選択肢です。Parquetは良い圧縮率を提供し、データのクエリと処理に高いパフォーマンスを発揮します。
- persist_directory: このパラメータには情報を保存するパスが含まれます。指定しない場合、データベースはインメモリであり永続的ではありません。ただし、純粋にインメモリで作業することは、Kaggleのようなクラウドや共同作業環境で問題を引き起こす可能性があります。
settings_chroma = Settings(chroma_db_impl="duckdb+parquet", persist_directory='./input')chroma_client = chromadb.Client(settings_chroma)ChromaDBでデータを操作する
ChromaDBのデータはコレクションに組織化されています。各コレクションは一意の名前を持たなければならないため、既存の名前を使用してコレクションを作成しようとするとエラーが発生します。
これを実現するために、ChromaDBのコレクションリストにコレクションが存在するかどうかを確認します。存在する場合は、再作成する前に削除します。重要な点として、このアプローチはこのノートブックのテストと実験に適しています。本番環境では異なる戦略を実装する必要があります。
代わりに、3つの別々のコレクションを作成することもできます。各データセットに1つずつコレクションを作成する方法もあります。ノートブックを変更して自分の好みに合わせて適応させる場合のアイデアとして残します。
collection_name = "news_collection"if len(chroma_client.list_collections()) > 0 and collection_name in [chroma_client.list_collections()[0].name]: chroma_client.delete_collection(name=collection_name)collection = chroma_client.create_collection(name=collection_name)コレクションを作成した後、ChromaDBデータベースにデータを追加する準備が整いました。これは、`add`関数を呼び出し、各レコードにドキュメント、メタデータ、および一意の識別子を提供することで行うことができます。
ドキュメントは任意の長さであり、ドキュメントの全内容が含まれます。格納するドキュメントの長さに応じて、ページや章などのより小さな部分に分割することも考えられます。データベースから返される情報は、プロンプトの文脈を作成するために使用され、これらのプロンプトには長さの制限があることに注意する必要があります。したがって、システムを設計する際には、ドキュメントの長さとプロンプトの長さ制限のトレードオフを考慮することが重要です。
この例では、プロンプトを作成するためにドキュメントの全情報を使用します。ただし、より高度なプロジェクトでは、返された情報の要約を生成する別のモデルを使用することができます。これにより、より少ないコンテンツでより関連性の高いプロンプトを作成することができます。LangChainの動作方法について詳しく説明する際に、このアプローチをさらに探求します。
メタデータはベクトル検索自体では使用されません。メタデータは、結果を絞り込むためのポストフィルタリングで使用されるカテゴリや追加情報を格納するために使用されます。
一意の識別子については、Pythonを使用して簡単に生成することができます。0からMAX_RANGEまでの数字を生成するだけで十分です。
collection.add( documents=subset_news[DOCUMENT].tolist(), metadatas=[{TOPIC: topic} for topic in subset_news[TOPIC].tolist()], ids=[f"id{x}" for x in range(MAX_NEWS)],)ChromaDBに格納された情報がある場合、クエリを実行し、目的のトピックや検索クエリに一致するドキュメントを取得することができます。
先ほど説明したように、結果は検索用語とドキュメントの内容との類似性に基づいて返されます。
重要な点として、メタデータは検索プロセスでは使用されません。比較は、ドキュメントの内容だけに基づいて行われます。
results = collection.query(query_texts=["laptop"], n_results=10 )print(results)`n_results`パラメータでは、返されるドキュメントの最大数を指定します。
レスポンスを見てみましょう:
{‘ids’: [[‘id173’, ‘id829’, ‘id117’, ‘id535’, ‘id141’, ‘id218’, ‘id390’, ‘id273’, ‘id56’, ‘id900’]], ‘embeddings’: None, ‘documents’: [[‘The Legendary Toshiba is Officially Done With Making Laptops’, ‘3 gaming laptop deals you can’t afford to miss today’, ‘Lenovo and HP control half of the global laptop market’, ‘Asus ROG Zephyrus G14 gaming laptop announced in India’, ‘Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)’, “Apple’s Next MacBook Could Be the Cheapest in Company’s History”, “Features of Huawei’s Desktop Computer Revealed”, ‘Redmi to launch its first gaming laptop on August 14: Here are all the details’, ‘Toshiba shuts the lid on laptops after 35 years’, ‘This is the cheapest Windows PC by a mile and it even has a spare SSD slot’]], ‘metadatas’: [[{‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}]], ‘distances’: [[0.8593593835830688, 1.02944016456604, 1.0793330669403076, 1.093000888824463, 1.1329681873321533, 1.2130440473556519, 1.2143317461013794, 1.216413974761963, 1.2220635414123535, 1.2754170894622803]]}
見るように、10のニュース記事が返されました。それらはすべて非常に短いですが、ノートパソコンに関連しています。興味深いことに、すべての記事には「laptop」という単語が含まれているわけではありません。これはどのように可能なのでしょうか?
ベクトルは、各ベクトルがその空間内のポイントを表す多次元空間で表されると想像してください。ベクトル間の類似性は、これらのポイント間の距離を測定することによって決定されます。二次元空間を想像し、返されたフレーズの1つを例として、その空間内の単語を表すとします。
「Acer Swift 3は、第10世代のIntel Ice Lake CPU、2Kスクリーンなどを搭載したノートパソコンが、インドでINR 64999(米ドル865)で発売されました。」
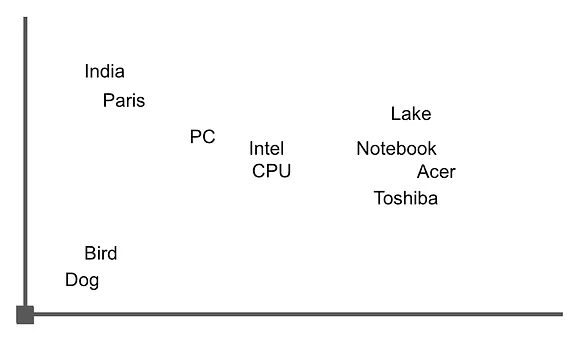
この画像に似たグラフを見ることができます。ここでは、「ノートパソコン」に関連する単語が密集してクラスタ化されていることがわかります。ベクトルの演算を使用してそれらの単語の間の距離を計算することで、これらの単語を含む文やドキュメントを取得することができます。
データが揃い、検索の動作について基本的な理解ができたので、モデルで作業を開始できます。
Hugging Faceからモデルをロードしてプロンプトを作成しましょう。
さあ、Transformers universeのライブラリで作業を始める時です。Hugging Faceがメンテナンスしている非常に人気のあるライブラリでは、信じられないほど多くのモデルにアクセスできます。
以下のユーティリティをインポートしましょう:
- AutoTokenizer:このツールはテキストをトークン化するために使用され、Hugging Faceのライブラリで利用可能な多くの事前学習済みモデルと互換性があります。
- AutoModelForCasualLM:GPTをベースとしたテキスト生成タスクに特化したモデルを使用するためのインターフェースを提供します。このミニプロジェクトでは、モデルdatabricks/dolly-v2-3bを使用しています。
- Pipeline:異なるタスクを組み合わせるパイプラインを作成することができます。
私が選んだモデルはdolly-v2-3bです。これはDollyファミリーの中で最も小さいモデルですが、3つの十億のパラメータを持っています。このモデルは私たちの小さな実験に十分すぎるほどであり、私が行ったテストに基づくと、GPT-2と比較してこのケースではより良いパフォーマンスを発揮するようです。
ただし、異なるモデルで実験することをお勧めします。ただし、選択したファミリーで最も小さいモデルから始めることをお勧めします。
from transformers import AutoTokenizer, AutoModelForCausalLM, pipelinemodel_id = "databricks/dolly-v2-3b"tokenizer = AutoTokenizer.from_pretrained(model_id)lm_model = AutoModelForCausalLM.from_pretrained(model_id)これらの行の後、変数tokenizerにトークナイザーが、lm_modelにモデルが格納されています。これらの変数を使用してパイプラインを作成します。
パイプラインの呼び出しでは、応答サイズを256トークンに制限する必要があります。
device_mapフィールドには値「auto」を指定します。これにより、モデル自体がテキスト生成にCPUまたはGPUを使用するかを決定します。
pipe = pipeline( "text-generation", model=lm_model, tokenizer=tokenizer, max_new_tokens=256, device_map="auto",)プロンプトの作成。
プロンプトを作成するために、前に実行したデータベースのクエリの結果を使用します。この場合、キーワード「ノートパソコン」に関連する10の記事が返されました。
プロンプトは次の2つの部分で構成されます:
1. コンテキスト:モデルが既に知っている情報に加えて考慮する必要がある情報を提供します。この場合、データベースへのクエリから得られた結果です。
2. ユーザーの質問:ユーザーが特定の質問やクエリを入力できる部分です。
プロンプトの構築は、望むテキストをつなげて望むプロンプトを終了させるだけです。
question = "東芝のノートパソコンを買うことはできますか?"context = " ".join([f"#{str(i)}" for i in results["documents"][0]])#context = context[0:5120]prompt_template = f"関連するコンテキスト:{context}\n\n ユーザーの質問:{question}"prompt_templateプロンプトの見た目を見てみましょう:
「関連するコンテキスト:#The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple’s Next MacBook Could Be the Cheapest in Company’s History #Features of Huawei’s Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot\n\n ユーザーの質問:東芝のノートパソコンを買うことはできますか?」
ご覧の通り、すべては非常に簡単です!何の秘密もありません。モデルには単に「私が提供しているこの文脈と改行に続くユーザーの質問はこれです」と伝えるだけです。
ここから先は、モデルが引数を解釈し、正しい応答を生成するためにすべての作業を行います。
応答を取得しましょう。前に作成したパイプラインを呼び出し、最近作成したプロンプトを渡すだけです。
lm_response = pipe(prompt_template)print(lm_response[0]["generated_text"])モデルからの応答を見てみましょう:
関連する文脈:#The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple’s Next MacBook Could Be the Cheapest in Company’s History #Features of Huawei’s Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot
ユーザーの質問:東芝のノートパソコンを購入できますか?答え:いいえ、東芝はノートパソコンの製造をやめることにしました。
完璧です!モデルは私たちが提供した文脈を考慮し、プロンプトで渡した情報だけでなく、事前学習の知識をも活用してユーザーの応答を正しく構築しました。
結論、次のステップ。
おそらく最初に見えたよりもすべてが簡単だと気づいたことでしょう。
私たちは自分たちの情報を保存するためにベクトルデータベースを使用し、大規模言語モデルのためのプロンプトを構築するためにそれを使用しました。
モデルは私たちが提供した文脈を考慮して正しい応答を返しました。このような作業方法は、大規模言語モデルの微調整を完璧に補完する可能性を開くことができると想像できます。
ノートブックで遊んでみたい場合は、KaggleとGitHubで利用可能ですので、お気軽にご利用ください。
以下にいくつかのアイデアを示します:
1. ノートブックで準備されているすべてのデータセットを使用し、可能であれば新しいデータセットを組み込んでみてください。
2. Hugging Faceで異なるモデルを探索し、結果を比較してみてください。
3. プロンプトの作成プロセスを変更してみてください。
実験して、反復し、さまざまな可能性を探索してみてください。これにより、ベクトルデータベース、大規模言語モデル、および自然言語処理タスクへの応用についてより深い理解を得るのに役立ちます。
私は定期的にディープラーニングと機械学習について書いています。VoAGIで私をフォローして、新しい記事についての更新情報を入手してください。もちろん、LinkedInで私とつながることも歓迎します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
