「知識グラフの力を利用する:構造化データでLLMを豊かにする」
Utilizing the power of knowledge graphs Enriching LLM with structured data.
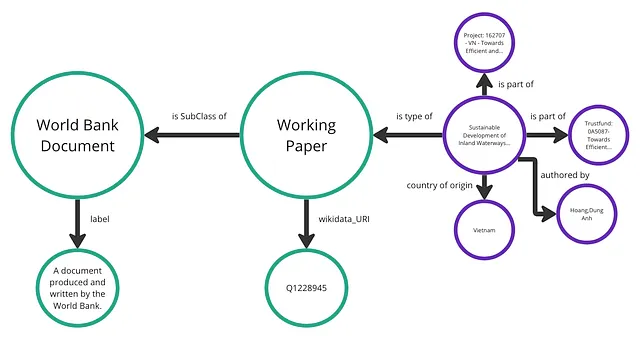
知識グラフを作成し、LLMを向上させるためのステップバイステップガイド
関連するコードについては、こちらのノートブックをご覧ください。
近年、大規模な言語モデル(LLM)は普及してきました。おそらく最も有名なLLMは、OpenAIが2022年11月にリリースしたChatGPTです。ChatGPTは、アイデアを生成したり、個別の推奨事項を提供したり、複雑なトピックを理解したり、執筆アシスタントとして機能したり、アカデミー賞の予測モデルを構築するのに役立つことができます。Metaは独自のLLMであるLLaMAを発表し、GoogleはLaMDAを持っており、オープンソースの代替案であるBLOOMも存在しています。
LLMは、上記にリストされたような自然言語処理(NLP)のタスクで優れた成績を収めてきました。これは、LLMが従来から非構造化データに焦点を当ててきたためです。非構造化データは、事前に定義された構造を持たず、通常はテキストが多いデータのことを指します。私はChatGPTに尋ねました、「なぜLLMは従来から非構造化データに焦点を当ててきたのですか?」その回答は次の通りでした:
- 「Pythonデータ構造について知っておくべき3つの重要な概念」
- 「Jaro-Winklerアルゴリズムを使用して小規模言語モデル(SLM)を構築し、スペルエラーを改善・強化する」
- データベースの最適化:SQLにおけるインデックスの探索
「LLMは、その豊富さ、利用可能性、およびそれに伴う課題のために、従来から非構造化データに焦点を当ててきました。非構造化データは、言語モデルのトレーニングにおいて広範な情報源を提供し、パターン、文脈、および意味を学習することを可能にします。LLMは非構造化データの複雑さや微妙なニュアンスを処理するのに優れており、豊かな文脈、意見、および創造的な表現を活用して言語の微妙なニュアンスを捉えることができます。LLMと構造化データのギャップを埋める取り組みが進められていますが、非構造化データへの歴史的な重点は、その独特の特性と提供する貴重な情報に起因しており、LLMがより人間らしい応答を提供できるようにしています。」
一方、構造化データは通常数量的でよく整理されており、通常は行と列に整理されています。また、ChatGPTが指摘するように、LLMと構造化データの間にはまだギャップが存在しています。
一方、知識グラフ(KG)は、構造化データのクエリに優れています。知識グラフは次のように定義されます:
「ノードとエッジにドメイン固有の意味が関連付けられた有向ラベル付きグラフです。ノードは、人、会社、コンピュータなど、任意の現実世界のエンティティを表すことができます。エッジラベルは関係を捉えます…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
