「情報検索と組み合わせたLLMの活用:シンプルなデモ」
Utilizing LLM with Information Retrieval Simple Demo
質問応答LLMと検索コンポーネントの統合デモ

大規模言語モデル(LLM)は膨大な事実データを保存することができますが、その能力はパラメータの数に制限されています。さらに、LLMを頻繁に更新することは高額であり、古いトレーニングデータがLLMに時代遅れの応答を生成する可能性があります。
上記の問題に対処するために、外部ツールでLLMを補完することができます。本記事では、LLMを検索コンポーネントと統合してパフォーマンスを向上させる方法について共有します。
検索補完(RA)
検索コンポーネントは、LLMに最新かつ正確な知識を提供することができます。入力xが与えられた場合、出力p(y|x)を予測したいとします。外部データソースRから、入力xに関連するコンテキストのリストz=(z_1, z_2,..,z_n)を取得します。そして、xとzを結合し、zの豊富な情報を活用してp(y|x,z)を予測します。さらに、Rを最新の状態に保つことも費用がはるかに安くなります。
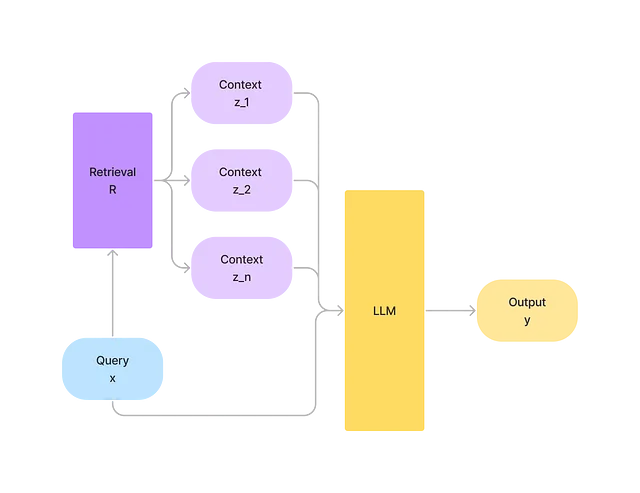
Wikipediaデータ+ChatGPTを使用したQAデモ
このデモでは、与えられた質問に対して次の手順を行います:
- 他人のPythonコードを簡単に理解する方法は?
- PyTorchを使用してx86 CPU上で推論速度を最大9倍高速化する方法
- アントロピックは、SKテレコムから1億ドルの資金を受けて、電気通信業界専用のAIの進展を推進します
- 質問に関連するWikipediaのドキュメントを取得します。
- 質問とWikipediaの両方をChatGPTに提供します。
追加のコンテキストがChatGPTの応答にどのように影響するかを比較して確認したいです。
データセット
Wikipediaのデータセットはこちらから抽出することができます。私は「20220301.simple」というサブセットを使用しており、200,000以上のドキュメントが含まれています。コンテキストの長さ制限のため、タイトルと概要の部分のみを使用しています。各ドキュメントには、後で検索の目的でドキュメントIDも追加しています。データの例は次のようになります。
{"title": "April", "doc": "April is the fourth month of the year in the Julian and Gregorian calendars, and comes between March and May. It is one of four months to have 30 days.", "id": 0}{"title": "August", "doc": "August (Aug.) is the eighth month of the year in the Gregorian calendar, coming between July and…We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






