「ChatGPTコードインタプリタを使用して、人道支援データの非構造化Excelテーブルを分析する」
Using the ChatGPT code interpreter to analyze unstructured Excel tables of humanitarian aid data.
コードインタプリターを使った初期の探索

要約
新しい実験的な機能「コードインタプリター」は、ChatGPTの使用の一部としてPythonコードの生成と実行をネイティブにサポートします。これにより、非技術的なユーザーが使用できる会話形式のインターフェースを提供し、データエンジニアリングや分析のタスクを行うための大いに可能性を示しています。この記事では、以前のブログ記事の非構造化のExcelテーブルにChatGPT(GPT-4)コードインタプリターをテストし、このテーブルをデータベースにロードできるより標準的な形式に自動的に変換できるかどうかを確認しています。限られたプロンプトの指示で、階層的な見出しの構造を識別できましたが、テーブルを正確に解析するコードを生成することはできませんでした。openpyxl Pythonライブラリを使用してExcelのマージセルに関する情報を抽出することを示唆するようにプロンプトを調整すると、一度にテーブルを解析することができました。しかし、まったく同じプロンプトでタスクを繰り返すと失敗しました。結果をより決定的にするための温度パラメータの制御がまだないため、Code Interpreterはこの特定のタスクに一貫して対応できるように見えません。しかし、まだ初期段階でベータ機能であり、大規模言語モデルを使用した自動データ処理のパターンはおそらく今後も続き、間違いなく改善されるでしょう。
今週、ChatGPTは、「コードインタプリター」と呼ばれる新機能をリリースしました。これにより、ChatGPTはPythonコードを生成し呼び出すことができるだけでなく、データ分析などのタスクを実行するためのデータファイルをアップロードすることも可能です。以前のブログ記事で調査したように、大規模言語モデルはデータエンジニアリングや分析のタスクを簡素化する可能性を持っています。LangChainプロジェクトには素晴らしいパターンがあり、この分野では既に多くの商業的な活動が行われているため、OpenAIがネイティブサポートを提供し始めることは興味深いです。
既にOpenAIのコードインタプリターについての記事が多数ありますが、私は以前に探索したいくつかの表形式のデータを使用してどれくらいうまく機能するかを試してみました。HDX(ヒューマニタリアンデータエクスチェンジ)で見つかるデータをHDXプラットフォームなどの自然言語インターフェースで提供できるようにすることは、技術的な知識のないユーザーがこのデータを探索し理解することを可能にし、人道的な災害イベントに対する予測と対応時間の短縮に影響を与えます。
Open AIのコードインタプリターへのアクセス方法
Code Interpreterは現在「アルファ」機能であり、早期のテストフェーズであり、標準のChatGPTの一部ではありません。アクセスするには、以下の手順が必要です:
- ChatGPT+の購読者であること(月額20ドル)
- https://chat.openai.com/ にアクセスする
- 左下の名前の隣にある「…」を選択し、「設定」を選択する
- 「ベータ機能」をクリックし、「コードインタプリター」を有効にする
- チャットウィンドウに戻り、GPT-3.5またはGPT-4のいずれかにカーソルを合わせ、「コードインタプリター」を選択する
最初はOpenAIのプラグインのウェイトリストに登録する必要がありましたが、まだそのような場合かどうかはわかりません。私はリストを介してアクセスを与えられた確認を受けていませんが、上記の手順で機能が表示されました。上記の手順が機能しない場合は、追加される必要があるかもしれません。
Excelファイルの非構造化テーブルの分析
以前のブログ記事で述べたように、Excelファイルのテーブルはマージセル、空行など、さまざまな形式で存在することがあり、自動処理を難しくすることがあります。この記事では、Humanitarian Data Exchange(HDX)で見つかるExcelテーブルの典型的な例を分析するために、GPT-4とCode Interpreterを使用してみることにしました…
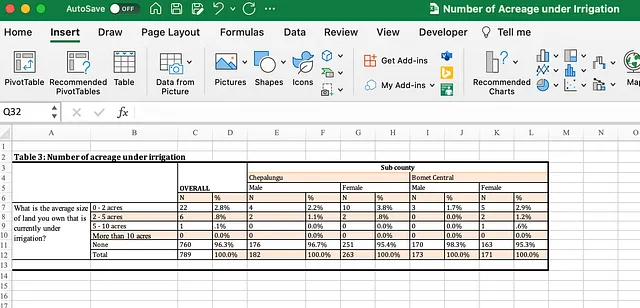
Code Interpreterはオープンデータセットにアクセスできますが、まだHDXは含まれておらず、インターネットにアクセスする能力もありません。これはすぐに変わると予想していますが、その間に、ファイルをダウンロードし、上記で説明したようにhttps://chat.openai.com/でセッションを開始し、チャットエントリボックスの「+」をクリックしてこのファイルをアップロードしました…

アップロード後、ChatGPTはPython Pandasにデータを読み込み、初期の分析を行います…

すぐに、シートのテーブルがやや不規則であることに気づき、すぐにこれに対処しようとします…

それは実際には的確です。実際、次のように尋ねます…

私は次のように答えました…

また、各応答の「Show Work」ドロップダウンを選択すると、生成されたPythonコードと結果を表示することで、どのようにこの結論に至ったのかを詳細に確認することもできます…

そのアプローチは合理的ですが、ネイティブなExcelのマージセル情報を使用せずに、直接Pandasにロードしていることに注意する価値があります。
ChatGPTは作業に取り掛かり、自動的にデータの処理を開始します…

しかし、これはすぐに失敗します。「Show Work」を選択すると、表のパースのためのいくつかのPythonが生成されていることがわかります…
# Drop the rows that are not neededdata = data.drop([0, 1])# Reset the indexdata = data.reset_index(drop=True)# Define the land size categoriesland_sizes = data.iloc[:, 1].values# Initialize empty lists to hold the tidy datasub_counties = []genders = []land_sizes_tidy = []numbers = []percentages = []# Iterate over the sub-counties and gendersfor i in range(4, data.shape[1], 2): sub_county = data.columns[i].split(' ')[0] gender = data.columns[i].split(' ')[1] # Iterate over the land size categories for j in range(len(land_sizes)): land_size = land_sizes[j] number = data.iloc[j, i] percentage = data.iloc[j, i + 1] # Append the values to the lists sub_counties.append(sub_county) genders.append(gender) land_sizes_tidy.append(land_size) numbers.append(number) percentages.append(percentage)# Create a tidy dataframetidy_data = pd.DataFrame({ 'Sub County': sub_counties, 'Gender': genders, 'Land Size': land_sizes_tidy, 'Number': numbers, 'Percentage': percentages})tidy_dataしかし、これにより境界エラーが発生します…

ChatGPTは諦めず、自動的にデバッグを開始します…

これはかなり印象的です。問題を正しく特定できたようです。ただし、会話の最初に正確な列階層を特定していたにもかかわらず、この情報を ‘失った’ようです。
再び、それは進んで自動的に進行します…

これによって次のような見出しのあるテーブルが得られます…

ここでは、列の終わりとデータの開始位置を特定していないことを示す列見出しにデータが含まれていることがわかります。実際、それはこれを見つけて勇敢に続行します…
この時点で、それは少し混乱した状態に陥り、ここに表示されていないサイクルで多くの試みを行います。
最終的に、トークンの制限が超過され、生成が停止し、次のようなテーブルが表示されます…

上記の ‘作業の表示’ 出力と元のテーブルを比較してこれらの値をスポットチェックすると、最後の ‘Total’ 行の値は正しいようですが、 ‘Bomet Central Femail N Bomet’ の列見出しが2つあります。それはこれを見つけます…

それがとても近かったので、ChatGPTに続行するように頼みました…

しばらく待ってから再開するように頼んだ結果、コード環境のジョブが終了したようです。それは再開することを喜んでいるようですが、いくつかの変数が失われてしまいました…

指示に従ってファイルを再アップロードし、それから再開しました。最終的に、これが生成されたテーブルです…
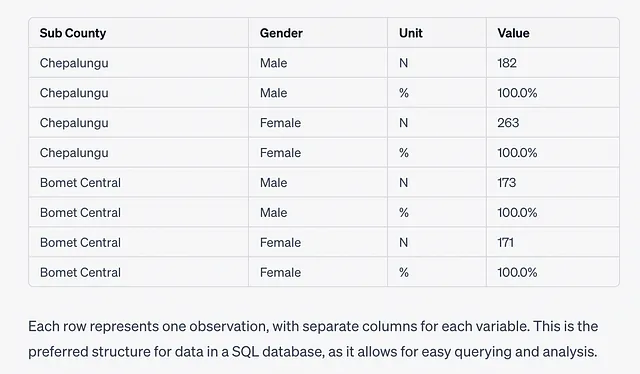
これは素晴らしいです…。元のテーブルの合計行だけですが。ChatGPTは、エーカーごとに分割された他の行すべてを失ってしまったため、解析に失敗しています。
実際、最初のアップロード直後に土地サイズに関連する列が欠けていることを指摘しました…

この時点で、ChatGPTは別の試みを始め、シートの解析を複数回繰り返しましたが、結局成功しませんでした。チャットの完全なリンクはこちらです。
新しいチャットセッションを開始して再試行しましたが、結果は異なりました。これはこの手法の再現性に影響を与えます。しかし、どれだけ試しても、結果は正しくありませんでした。
ChatGPTにいくつかのコーディングの提案をする
以前のブログ投稿では、Excelから抽出した情報を使用して、セルがマージされていることを示し、テーブル見出しの階層と私たち人間がExcelテーブルを見る際に使用するキーを理解することで、提供された例のようなテーブルの解析で最も成功を収めることができました。Pandas Excel解析のみを使用する場合(私たちのテストでChatGPTが行った方法)、セルごとにExcel構造を問い合わせるのではなく、この情報は失われるため、マージされた見出しセルを持つテーブルの解析ははるかに困難になります。
それでは、ChatGPTに直接「openpyxl」を使用し、マージされたセルを考慮するようにヒントを与えてみましょう。

前回と同様に、最初から正しい結果が得られます…

そして、解析を続行します…

ただし、今回は技術に関するガイダンスが提供されたため、上記の単一のプロンプトだけでほぼ完璧にテーブルをフラット化し、さらなる介入なしで処理しました。

唯一の問題は最後の行ですが、さらなるプロンプトを与えることで簡単に除去できます。完全なやり取りとこの結果の生成されたコードを見るには、こちらをご覧ください。
私はChatGPTに完全なコードを生成するように依頼し、最終的に何が出てくるか確認しました…

from openpyxl import load_workbook
import pandas as pd
# ワークブックをロード
wb = load_workbook(filename='/mnt/data/Number of Acreage under Irrigation.xlsx')
ws = wb.active
data = ws.values
data = list(data)
# タプルをリストに変換
data = [list(row) for row in data]
# 最初の2つの列のNone値を処理する関数
def handle_none(data):
last_valid = [None, None]
for row in data:
for i in range(2):
if row[i] is not None:
last_valid[i] = row[i]
else:
row[i] = last_valid[i]
return data
data_filled = handle_none(data)
# ヘッダーを構築
headers = [None] * len(data_filled[0])
for row in data_filled[2:6]:
for i, value in enumerate(row):
if value is not None:
if headers[i] is None:
headers[i] = value
else:
headers[i] += '_' + value
# 最初の2つのヘッダーを調整
headers[0] = 'Question'
headers[1] = 'Category'
# '%'ヘッダーを調整
for i in range(len(headers)):
if headers[i] == '%':
headers[i] = headers[i-1].rsplit('_', 1)[0] + '_%'
# 'Female_N'および'Female_%'ヘッダーを調整
headers[6] = 'Sub county_Chepalungu_Female_N'
headers[7] = 'Sub county_Chepalungu_Female_%'
headers[10] = 'Bomet Central_Female_N'
headers[11] = 'Bomet Central_Female_%'
# DataFrameを作成
df = pd.DataFrame(data_filled[6:], columns=headers)
# DataFrameをCSVファイルとして保存
df.to_csv('/mnt/data/Number_of_Acreage_under_Irrigation_SQL.csv', index=False)これは合理的なように思われます。一般的ではなく、処理されるファイルに特化した行があります。おそらく、ChaGPTが一般的なコードを生成するためにはさらなるプロンプトが必要なのかもしれませんが、この研究のタスクでは非構造化のテーブルをうまく解析できました。
素晴らしい結果です!
最初のテストでChatGPTが同じプロンプトで異なる結果を示したことを考慮して、成功したテストでまったく同じ成功したプロンプトを繰り返して実行して、事柄がどのように動作するかを見ることにしました。残念ながら、まったく異なる結果が得られ、同じプロンプトを使用しても正しくありませんでした。
素晴らしい結果ではありません!
APIでは、モデルをより決定論的にし、再現可能な結果を得るために温度パラメータを減らすことができますが、Code InterpreterはまだAPIで利用できないため、これについて実験することはできませんでした。
結論
最初は失敗しましたが、私たちはChatGPTに対してPythonでこれをどのように行うかについてのいくつかのコーディングのヒントを提供することで、非構造化のテーブルを正しく解析するように促すことができました。これは実際には非常に驚くべき結果です。ただし、同じプロンプトでの再現性のある結果は得られませんでした。これは、このベータ機能ではまだモデルの温度パラメータを制御できないためです。
もう1つの興味深い制限事項は、トークン制限を超えて補完が停止し、タスクが完了する前に別のプロンプトが必要になることです。また、ChatGPTが異なるコードのチャンクを試行するため、プロセスはかなり遅くなります。迅速な応答が必要なタスクにはまだ適用できる技術ではありません。
基本的に、Code Interpreterは非常に印象的で将来性がありますが、上記のタスクにはまだ完全に準備ができていないようです。
したがって、今のところ、非常に短い時間ではありますが、私はChatGPTに勝っています。 😊
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データサイエンスの役割に関するGoogleのトップ50のインタビュー質問」
- 「Spotifyのデータサイエンティストによるインサイトを効果的なアクションに変えるためのガイド」
- 「Adam Ross Nelsonによるデータサイエンティストになる方法からの9つの重要なポイント」
- 「データサイエンス、STEM、ビジネス、および営業のプロフェッショナルが仕事を見つける場所」
- AIはデータ専門家の役割にどのような影響を与えるのか?
- Streamlitを使用して、Hugging Face Spacesにモデルとデータセットをホスティングする
- データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
