「機械学習におけるモデルの解釈性においてSHAP値の使用」
Using SHAP values for model interpretability in machine learning
機械学習の解釈性
機械学習の解釈性とは、機械学習モデルが予測を行う方法を説明し理解するための技術のことです。モデルが複雑になるにつれて、内部の論理を説明し、振る舞いを理解することがますます重要になります。
- 「AWSとAccelが「ML Elevate 2023」を立ち上げ、インドのAIスタートアップエコシステムを力強く支援」
- 「業界アプリケーションにおける大規模言語モデルを評価するための4つの重要な要素」
- 「7月24日から7月31日までの週間でのトップのコンピュータビジョン論文」
これは重要なことです。なぜなら、機械学習モデルは、医療、金融、刑事司法など、現実世界の結果をもたらす意思決定に使用されることが多いからです。解釈性がないと、機械学習モデルが良い意思決定を行っているのか、バイアスがあるのかを判断することが困難になります。
機械学習の解釈性には、さまざまな技術があります。一つの人気な手法は、特徴の重要度スコアを決定することで、モデルの予測に最も大きな影響を与える特徴を明らかにすることです。SKlearnモデルはデフォルトで特徴の重要度スコアを提供しますが、SHAP、Lime、Yellowbrickなどのツールを利用すると、機械学習の結果をより良く視覚化し理解することができます。
このチュートリアルでは、SHAP値とSHAP Pythonパッケージを使用して機械学習の結果を解釈する方法について説明します。
SHAP値とは何ですか?
SHAP値は、ゲーム理論のシャプリー値に基づいています。ゲーム理論では、シャプリー値は協力ゲームにおいて各プレイヤーが総支払額にどれだけ貢献したかを決定するのに役立ちます。
機械学習モデルでは、各特徴は「プレイヤー」と見なされます。特徴のシャプリー値は、特徴が全ての特徴の組み合わせにおいてどれだけ貢献するかの平均の大きさを表します。
具体的には、SHAP値は、特定の特徴が存在する場合と存在しない場合のモデルの予測を比較することで計算されます。これは、データセット内の各特徴と各サンプルに対して反復的に行われます。
各予測に対して各特徴に重要度の値を割り当てることで、SHAP値はモデルの振る舞いの局所的かつ一貫した説明を提供します。これにより、特定の予測に最も影響を与える特徴がどれであるか(肯定的または否定的に)が明らかになります。これは、深層ニューラルネットワークなどの複雑な機械学習モデルの理由を理解するために貴重です。
SHAP値の始め方
このセクションでは、KaggleのMobile Price Classificationデータセットを使用して、マルチ分類モデルを構築し分析します。RAM、サイズなどの特徴に基づいて、モバイル電話の価格を分類します。目的変数は、0(低コスト)、1(VoAGIコスト)、2(高コスト)、3(非常に高コスト)の値を持ちます。
注意: コードのソースと出力はDeepnoteワークスペースで利用できます。
SHAPのインストール
システムに<code>shap</code>をインストールするのは非常に簡単です。<code>pip</code>または<code>conda</code>コマンドを使用します。
pip install shapまたは
conda install -c conda-forge shapデータの読み込み
データセットは、ラベルエンコーダーを使用してカテゴリを数値に変換したクリーンで整理されたものです。
import pandas as pd
mobile = pd.read_csv("train.csv")
mobile.head()
モデルのトレーニングと評価
その後、トレーニングセットを使用してランダムフォレスト分類器モデルをトレーニングし、テストセットでのパフォーマンスを評価します。正確度は87%で非常に良く、モデル全体としてバランスが取れています。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# モデルの適合
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
# 予測
y_pred = rf.predict(X_test)
# モデルの評価
print(classification_report(y_pred, y_test))
precision recall f1-score support
0 0.95 0.91 0.93 141
1 0.83 0.81 0.82 153
2 0.80 0.85 0.83 158
3 0.93 0.93 0.93 148
accuracy 0.87 600
macro avg 0.88 0.87 0.88 600
weighted avg 0.87 0.87 0.87 600
SHAP値の計算
この部分では、SHAPツリーエクスプレイナーを作成し、それを使用してテストセットのSHAP値を計算します。
import shap
shap.initjs()
# SHAP値の計算
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X_test)
サマリープロット
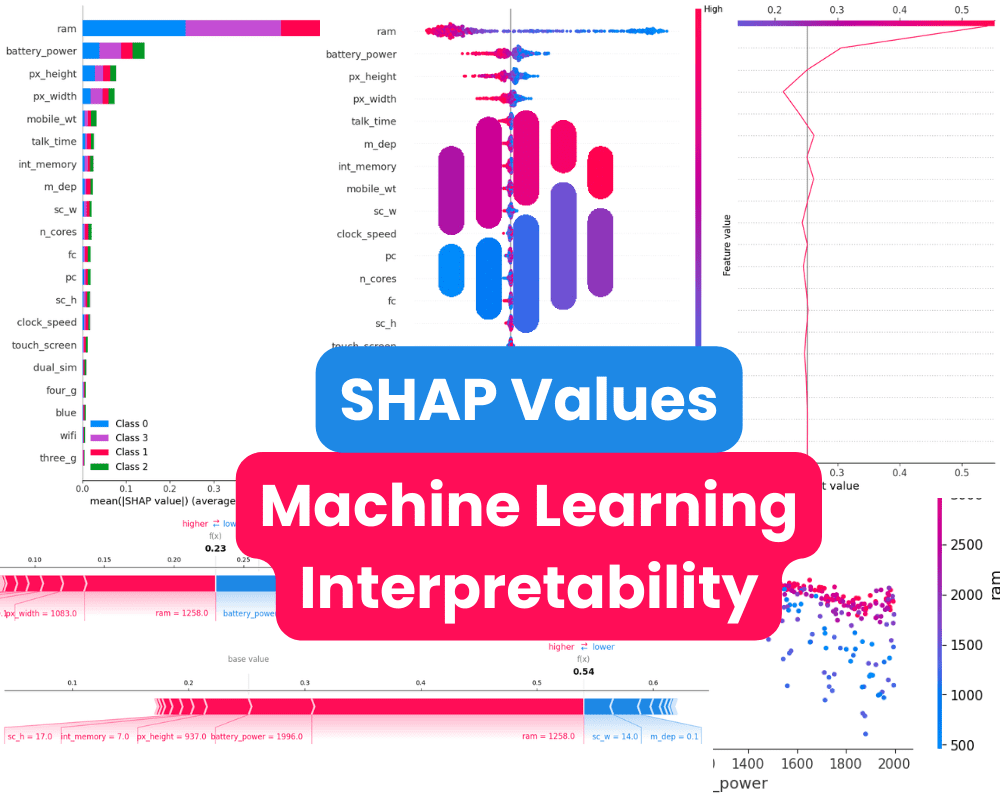
サマリープロットは、モデルの各特徴の特徴重要度をグラフィカルに表示するものです。モデルが予測を行う方法や最も重要な特徴を特定するための有用なツールです。
この場合、価格帯を決定するのに「ram」、「battery_power」、および電話のサイズが重要な役割を果たしていることが示されています。
# 特徴の影響をまとめる
shap.summary_plot(shap_values, X_test)
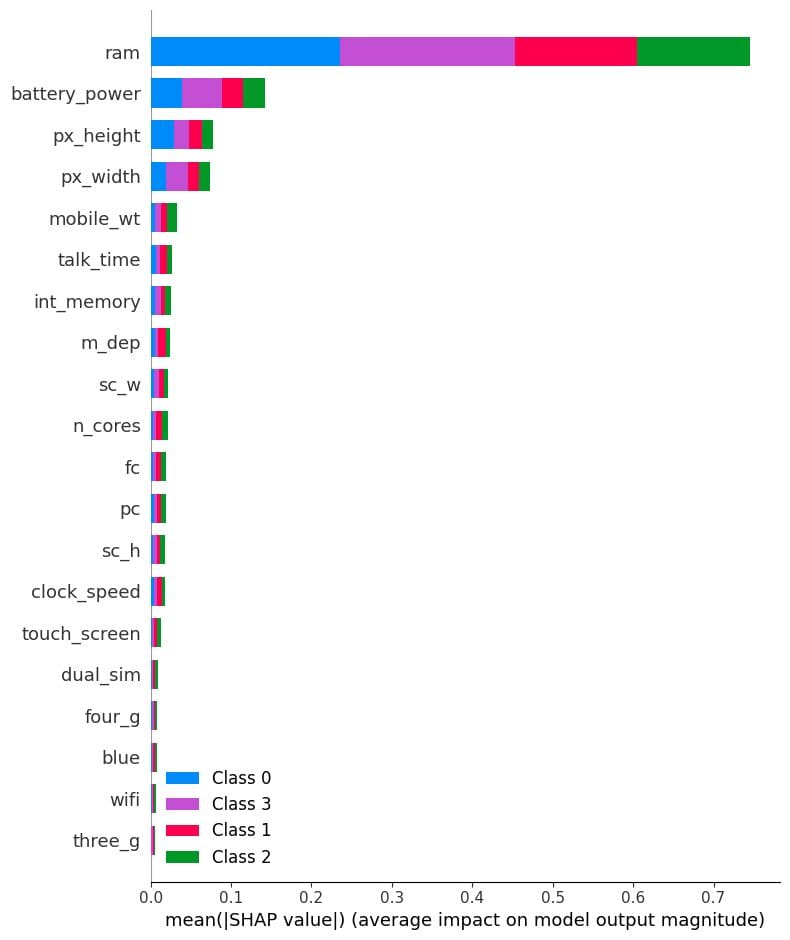
次に、「0」クラスの特徴重要度を視覚化します。予測するためにram、バッテリー、および電話のサイズがネガティブな影響を与えることが明確にわかります。
shap.summary_plot(shap_values[0], X_test) 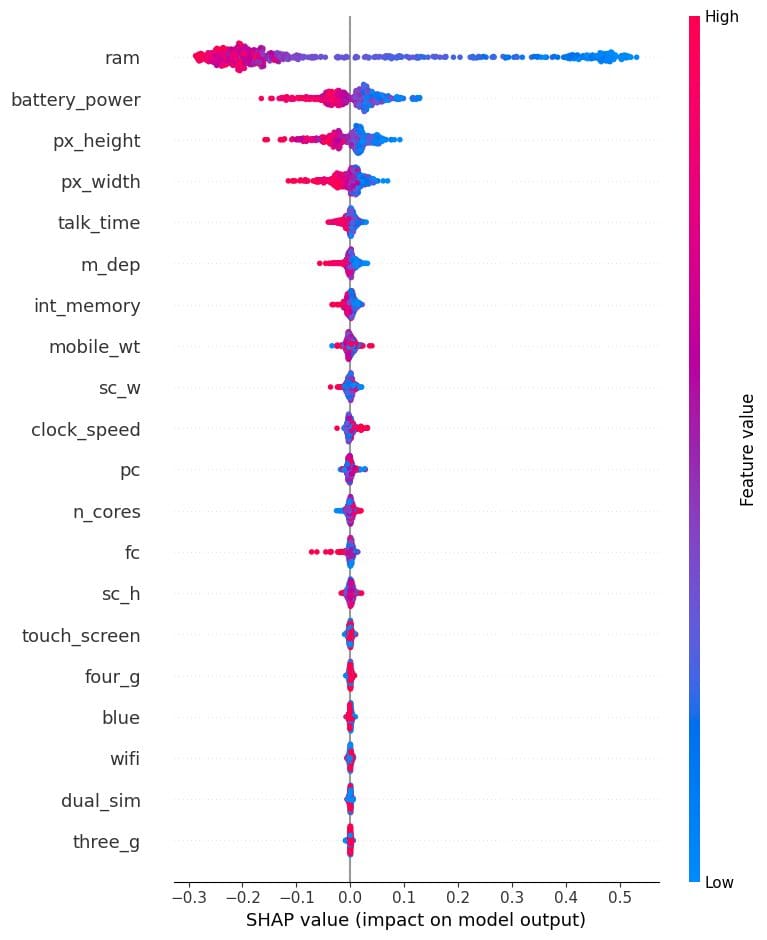
依存プロット
依存プロットは、特定の特徴がモデルの予測にどのように影響するかを表示する散布図の一種です。この例では、「battery_power」が特徴です。
プロットのx軸には「battery_power」の値が表示され、y軸にはshap値が表示されます。バッテリー電力が1200を超えると、下位のモバイル電話モデルの分類に否定的な影響を与え始めます。
shap.dependence_plot("battery_power", shap_values[0], X_test,interaction_index="ram") 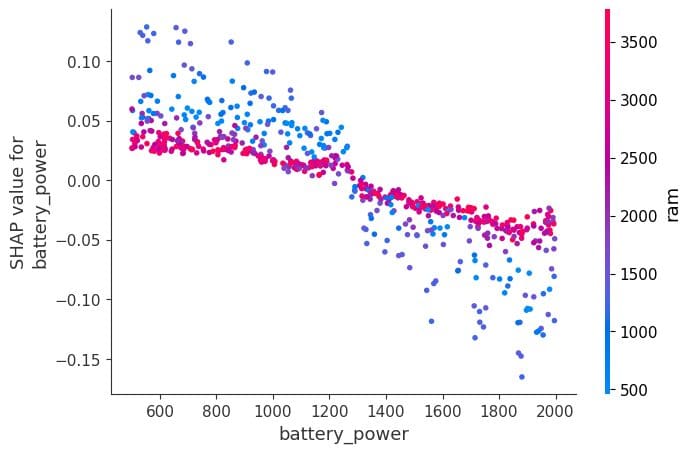
フォースプロット
特定のサンプルに焦点を当てます。具体的には、12番目のサンプルを詳しく調べて、どの特徴が「0」の結果に貢献したかを見てみましょう。そのために、フォースプロットを使用し、期待値、SHAP値、およびテストサンプルを入力します。
結果として、ram、電話のサイズ、およびクロック速度がモデルにより高い影響を与えることがわかります。また、f(x)が低いため、モデルは「0」クラスを予測しないことも観察されました。
shap.plots.force(explainer.expected_value[0], shap_values[0][12,:], X_test.iloc[12, :], matplotlib = True)
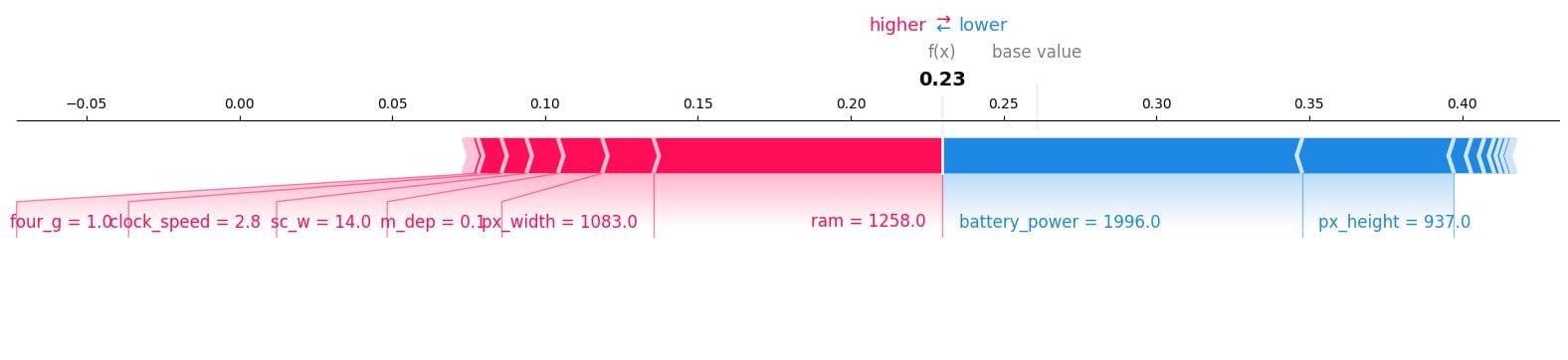
これからクラス「1」のフォースプロットを可視化します。右のクラスであることがわかります。
shap.plots.force(explainer.expected_value[1], shap_values[1][12, :], X_test.iloc[12, :], matplotlib = True)
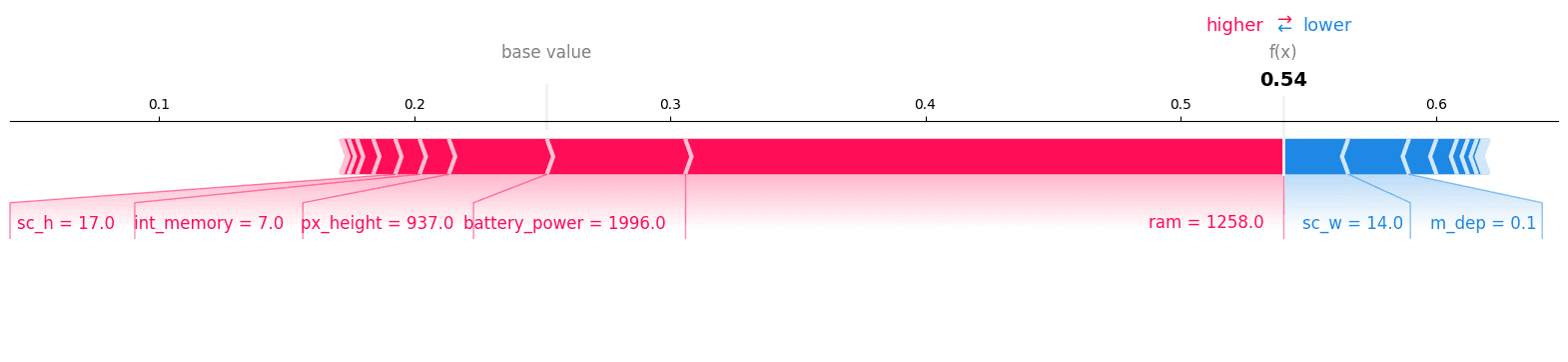
テストセットの12番目のレコードを確認することで、予測を確認できます。
y_test.iloc[12]
>>> 1
決定プロット
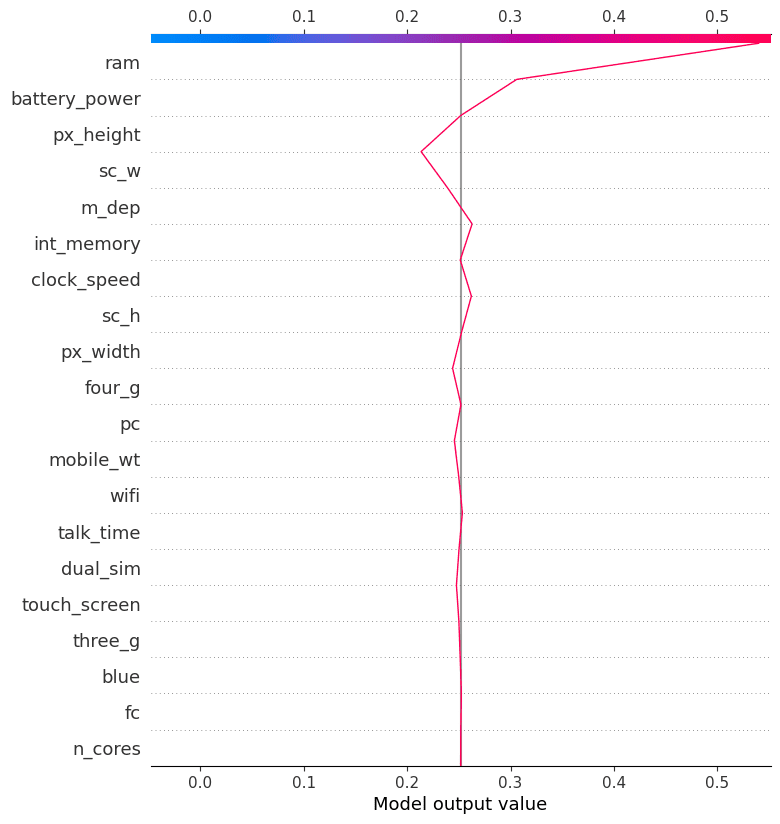
決定プロットは、機械学習モデルの意思決定プロセスを理解するための有用なツールです。これにより、モデルの予測に最も重要な特徴量や潜在的なバイアスを特定することができます。
クラス「1」の予測に影響を与えた要因をより良く理解するために、決定プロットを調べます。このプロットに基づくと、電話の高さはモデルに対して負の影響を与え、RAMは正の影響を与えたようです。
shap.decision_plot(explainer.expected_value[1], shap_values[1][12,:], X_test.columns)
結論
このブログ投稿では、機械学習モデルの出力を説明するためのSHAP値という手法を紹介しました。SHAP値を使用して個別の予測とモデルの全体的なパフォーマンスを説明する方法を示しました。また、SHAP値を実践的に使用する例も提供しました。
機械学習が医療、金融、自動運転などの敏感な領域に拡大するにつれて、解釈性と説明可能性はますます重要になります。SHAP値は、予測とモデルの振る舞いを説明する柔軟かつ一貫したアプローチを提供します。予測がどのように行われるか、潜在的なバイアスを特定し、モデルのパフォーマンスを向上させるための洞察を得るために使用できます。Abid Ali Awan(@1abidaliawan)は、機械学習モデルの構築が大好きな認定データサイエンティストです。現在、コンテンツ作成と機械学習およびデータサイエンス技術に関する技術ブログの執筆に注力しています。Abidはテクノロジーマネジメントの修士号と通信工学の学士号を取得しています。彼のビジョンは、メンタルヘルスの問題を抱える学生向けにグラフニューラルネットワークを使用したAI製品を開発することです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 2023年に知っておくべきトップ13の自然言語処理プロジェクト
- このAIニュースレターは、あなたが必要なもの全てです#58
- 「UniDetectorであなたが望むものを検出しましょう」
- 「QLORAとは:効率的なファインチューニング手法で、メモリ使用量を削減し、単一の48GB GPUで65Bパラメーターモデルをファインチューニングできるだけでなく、完全な16ビットのファインチューニングタスクのパフォーマンスも保持します」
- 「LLMは強化学習を上回る- SPRINGと出会う LLM向けの革新的なプロンプティングフレームワークで、コンテキスト内での思考計画と推論を可能にするために設計されました」
- 「DeepMind AIが数百万の動画のために自動生成された説明を作成することで、YouTube Shortsの露出を大幅に向上させる」
- 「効果的なマーケティング戦略開発のための機械学習の活用」






