「GPU インスタンスに裏打ちされた SageMaker マルチモデルエンドポイントを利用して、数百の NLP モデルをホストします」
Using SageMaker multi-model endpoints backed by GPU instances to host hundreds of NLP models.
Amazon SageMakerとTriton Inference Serverの統合
過去には、SageMaker Multi-Model Endpoints(MME)を使用して、複数のモデルを単一のエンドポイントにホストするコスト効率の高いオプションを探求しました。小さなモデルをCPUベースのインスタンスでホストすることは可能ですが、これらのモデルが大きく、より複雑な場合にはGPUコンピューティングが必要になることもあります。
MMEをバックエンドとするGPUベースのインスタンスは、この記事で紹介するSageMaker Inferenceの特定の機能であり、単一のエンドポイントに数百のNLPモデルを効率的にホストする方法を示します。なお、この記事の執筆時点では、SageMakerのMME GPUは以下の単一のGPUベースのインスタンスファミリーをサポートしています:p2、p3、g4dn、およびg5。
MME GPUは現在、以下の2つのモデルサービングスタックによっても駆動しています:
- Nvidia Triton Inference Server
- TorchServe
この記事では、PyTorchバックエンドを使用したTriton Inference Serverを利用して、GPUインスタンス上でBERTベースのモデルをホストします。Tritonについて初めての方は、こちらの初心者向け記事を参照することをおすすめします。
- 「ABBYYインテリジェントオートメーションレポートによると、AIの予算は80%以上増加していることが明らかになりました」
- 「AI for All 新しい民主化された知能の時代を航海する」
- 「AlphaFold 2の2億モデルによって明らかにされたタンパク質の宇宙を詳細に分析する2つの新論文」
注意:この記事は、SageMaker Deploymentおよびリアルタイム推論の中級者レベルの理解を前提としています。Deployment/Inferenceについてより詳しく理解するためには、この記事を参照してください。また、Multi-Model Endpointsについても概説しますが、さらに理解するためにはこのドキュメントを参照してください。
免責事項:私はAWSの機械学習アーキテクトであり、ここに述べる意見は私自身のものです。
MMEとは?ソリューションの概要
なぜMulti-Model Endpointsを使用し、いつ使用するのでしょうか?MMEはコストと管理の効率的なホスティングオプションです。従来のSageMakerエンドポイントのセットアップは以下のようになります:
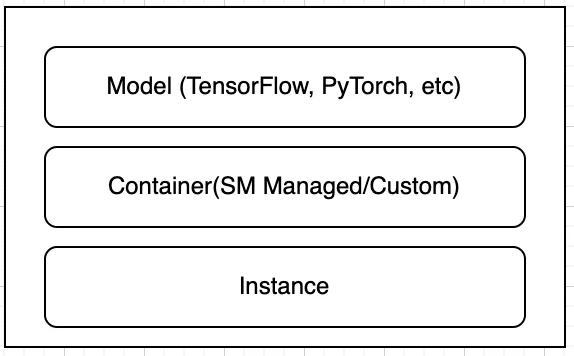
数百、さらには数千のモデルがある場合、それぞれのエンドポイントを管理することが難しくなり、多くの料金が発生します…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






