「Retrieval Augmented GenerationとLangChain Agentsを使用して、内部情報へのアクセスを簡素化する」
Using Retrieval Augmented Generation and LangChain Agents to simplify access to internal information.
この記事では、顧客が内部文書を検索する際に直面する最も一般的な課題について説明し、AWSサービスを使用して内部情報をより有用にするための生成型AI会話ボットを作成するための具体的なガイダンスを提供します。
非構造化データは、組織内で見つかるすべてのデータの80%を占めており、マニュアル、PDF、FAQ、メールなどのリポジトリで構成されており、毎日増えています。現在のビジネスは、絶えず成長し続ける内部情報のリポジトリに依存しており、非構造データの量が手に負えなくなると問題が発生します。ユーザーは必要な回答を見つけるために、多くの異なる内部ソースを読んだり確認したりすることがよくあります。
内部の質問と回答のフォーラムは、ユーザーが非常に具体的な回答を得るのに役立ちますが、より長い待ち時間が必要です。企業固有の内部FAQの場合、長い待ち時間は従業員の生産性を低下させます。質問と回答のフォーラムは、手動で回答を書く必要があるため、スケーリングが困難です。生成型AIを使用することで、ユーザーが情報を検索して見つける方法には現在パラダイムシフトが起こっています。次の論理的なステップは、生成型AIを使用して大量のドキュメントをより小さな情報に要約し、ユーザーがより簡単に消費できるようにすることです。長いテキストを読んだり回答を待ったりする代わりに、ユーザーは内部情報の複数の既存リポジトリに基づいてリアルタイムで要約を生成することができます。
ソリューションの概要
このソリューションでは、トランスフォーマーモデルを使用して内部ドキュメントに関する質問に対する選りすぐりの回答を取得することができます。このモデルは、訓練されていないデータに対しても回答を生成するゼロショットプロンプティングという技術を使用しています。このソリューションを採用することで、以下の利点が得られます。
- 「Amazon Comprehendのカスタム分類を使用して分類パイプラインを構築する(パートI)」
- AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
- 「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
- 既存の内部ドキュメントを基にした正確な回答を見つけることができます
- 最新の情報を持つドキュメントを使用して、複雑なクエリに対して即座に回答を提供するために、大規模言語モデル(LLM)を使用して回答を見つけるための検索時間を短縮することができます
- 集中したダッシュボードを通じて以前に回答された質問を検索することができます
- 回答を探すために情報を手動で読む時間によって引き起こされるストレスを軽減することができます
リトリーバル増強生成(RAG)
リトリーバル増強生成(RAG)は、LLMベースのクエリのいくつかの欠点を軽減するために、知識ベースから回答を見つけ、LLMを使用してドキュメントを簡潔な回答に要約します。Amazon Kendraを使用したRAGアプローチの実装方法については、この記事をお読みください。LLMベースのクエリに関連する以下のリスクと制限があり、Amazon Kendraを使用したRAGアプローチで対処されます。
- 幻覚とトレーサビリティー – LLMSは大規模なデータセットで訓練され、確率で回答を生成します。これにより、幻覚として知られる不正確な回答が生じることがあります。
- 複数のデータシロ – 応答内で複数のソースのデータを参照するためには、データを集約するためのコネクタエコシステムを設定する必要があります。複数のリポジトリへのアクセスは手動であり、時間がかかります。
- セキュリティー – RAGとLLMによってパワードされた会話型ボットを展開する際には、セキュリティーとプライバシーが重要な考慮事項です。ユーザーのクエリを通じて提供される個人データをフィルタリングするためにAmazon Comprehendを使用していても、誤って個人情報や機密情報を公開する可能性があります。したがって、チャットボットへのアクセスを制御して機密情報への意図しないアクセスを防止することが重要です。
- データの関連性 – LLMSは特定の日付までのデータで訓練されているため、情報は常に最新ではありません。最新のデータでモデルをトレーニングするためのコストは高いです。正確で最新の回答を確保するために、組織はインデックスされたドキュメントのコンテンツを定期的に更新して充実させる責任があります。
- コスト – このソリューションを展開する際のコストは、ビジネスにとって考慮すべき要素です。ビジネスは、このソリューションを実装する際に予算とパフォーマンスの要件を慎重に評価する必要があります。LLMsの実行には大量の計算リソースが必要になる場合があり、これは運用コストを増加させる可能性があります。これらのコストは、大規模で動作する必要があるアプリケーションにとって制約になることがあります。ただし、AWSクラウドの利点の1つは、使用したリソースのみを請求する柔軟性があることです。AWSはシンプルで一貫した従量制の価格モデルを提供しており、使用したリソースのみが請求されます。
Amazon SageMaker JumpStartの利用
トランスフォーマーベースの言語モデルでは、Amazon SageMaker JumpStartを使用することで組織は利益を得ることができます。Amazon SageMaker JumpStartには、事前構築された機械学習モデルのコレクションが提供されています。Amazon SageMaker JumpStartでは、簡単に展開して利用できるさまざまなテキスト生成と質問応答(Q&A)の基礎となるモデルが提供されています。このソリューションでは、FLAN T5-XL Amazon SageMaker JumpStartモデルが統合されていますが、基礎となるモデルを選ぶ際には留意すべき点があります。
ワークフローにセキュリティを統合する
ウェルアーキテクチャフレームワークのセキュリティピラーのベストプラクティスに従い、Amazon Cognitoは認証に使用されます。 Amazon Cognitoユーザープールは、アクセス制御に使用されるいくつかのフレームワーク(OAuth、OIDC、SAML)をサポートするサードパーティのIDプロバイダと統合することができます。ユーザーとそのアクションの特定により、ソリューションは追跡性を維持します。ソリューションではまた、Amazon Comprehendの個人識別情報(PII)検出機能を使用してPIIを自動的に特定および削除します。削除されたPIIには、住所、社会保障番号、メールアドレス、および他の機密情報が含まれます。この設計により、入力クエリを介してユーザーが提供したPIIは削除されます。PIIは格納されず、Amazon Kendraによって使用されず、LLMに供給されません。
ソリューションの概要
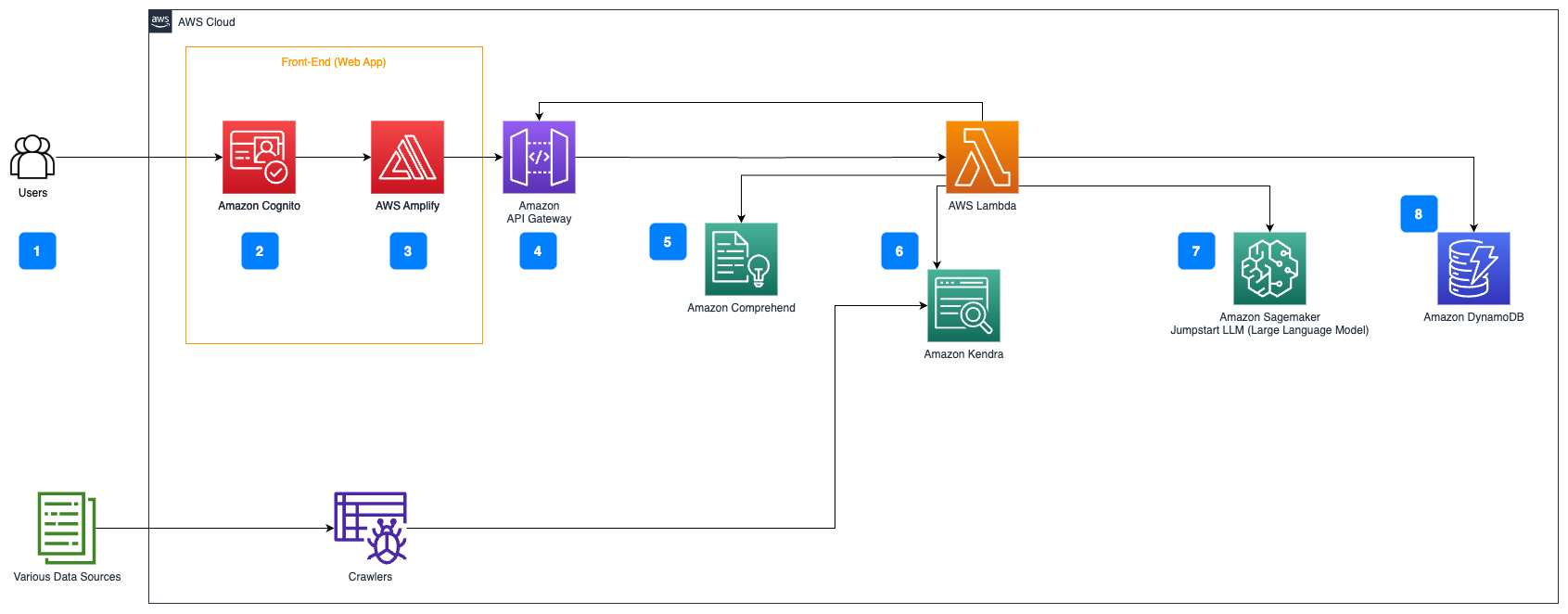
以下の手順は、ドキュメントフロー上の質問応答のワークフローを説明しています:
- ユーザーはウェブインターフェースを介してクエリを送信します。
- 認証にはAmazon Cognitoが使用され、ウェブアプリケーションへの安全なアクセスが確保されます。
- ウェブアプリケーションのフロントエンドはAWS Amplifyでホストされます。
- Amazon API Gatewayは、Amazon Cognitoを使用して認証されたユーザーリクエストを処理するためのさまざまなエンドポイントをホストします。
- Amazon ComprehendによるPII削除:
- ユーザークエリ処理:ユーザーがクエリまたは入力を送信すると、まずAmazon Comprehendを通過します。サービスはテキストを分析し、クエリ内に存在するPIIエンティティを特定します。
- PII抽出:Amazon Comprehendは、ユーザークエリから検出されたPIIエンティティを抽出します。
- Amazon Kendraによる関連情報の検索:
- Amazon Kendraは、ユーザーのクエリに対する回答を生成するために使用される情報を含むドキュメントのインデックスを管理するために使用されます。
- LangChain QA検索モジュールは、ユーザーのクエリに関する関連情報を持つ会話チェーンを構築するために使用されます。
- Amazon SageMaker JumpStartとの統合:
- AWS Lambda関数はLangChainライブラリを使用し、コンテキスト付きクエリでAmazon SageMaker JumpStartエンドポイントに接続します。 Amazon SageMaker JumpStartエンドポイントは、推論に使用されるLLMのインタフェースとして機能します。
- 応答の保存とユーザーへの返送:
- LLMからの応答は、ユーザーのクエリ、タイムスタンプ、一意の識別子、および質問カテゴリなどのアイテムのための他の任意の識別子とともにAmazon DynamoDBに格納されます。質問と回答を個別のアイテムとして保存することで、AWS Lambda関数は質問が行われた時刻に基づいてユーザーの会話履歴を簡単に再作成することができます。
- 最後に、応答はAmazon API Gateway REST API統合レスポンスを介してHTTPsリクエストを通じてユーザーに送信されます。
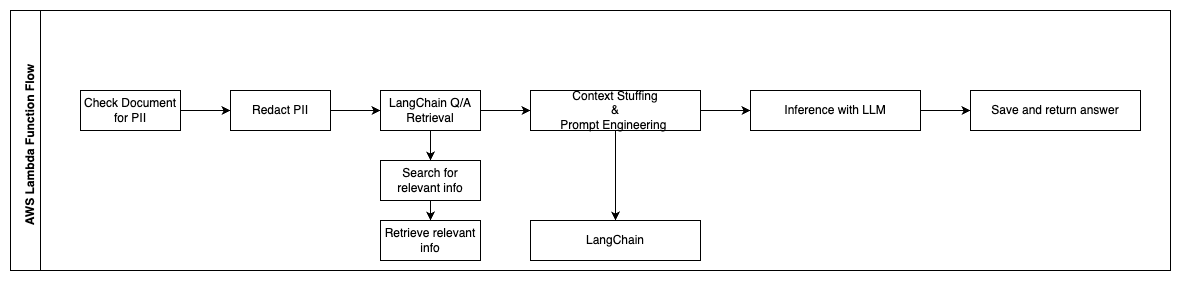
以下の手順は、AWS Lambda関数とそのプロセスを通じたフローを説明しています:
- PII / 機密情報のチェックと削除
- LangChain QA検索チェーン
- 関連情報の検索と取得
- コンテキスト付けとプロンプトの設計
- LangChain
- LLMによる推論
- 応答の返送と保存
ユースケース
このワークフローを顧客が使用できるビジネスユースケースは多数あります。以下のセクションでは、ワークフローが異なる業界や垂直でどのように使用されるかを説明します。
従業員支援
設計の良い企業研修は、従業員の満足度を向上させ、新しい従業員のオンボーディングにかかる時間を短縮することができます。組織が成長し、複雑さが増すにつれて、従業員は内部ドキュメントの多くのソースを理解することが困難になります。このコンテキストでは、従業員は内部の問題チケットを進める方法や編集方法について質問があります。従業員は、生成的な人工知能(AI)対話型ボットを使用して、特定のチケットに対して次のステップを尋ねて実行することができます。
具体的な使用例:企業のガイドラインに基づいて従業員の問題解決を自動化します。
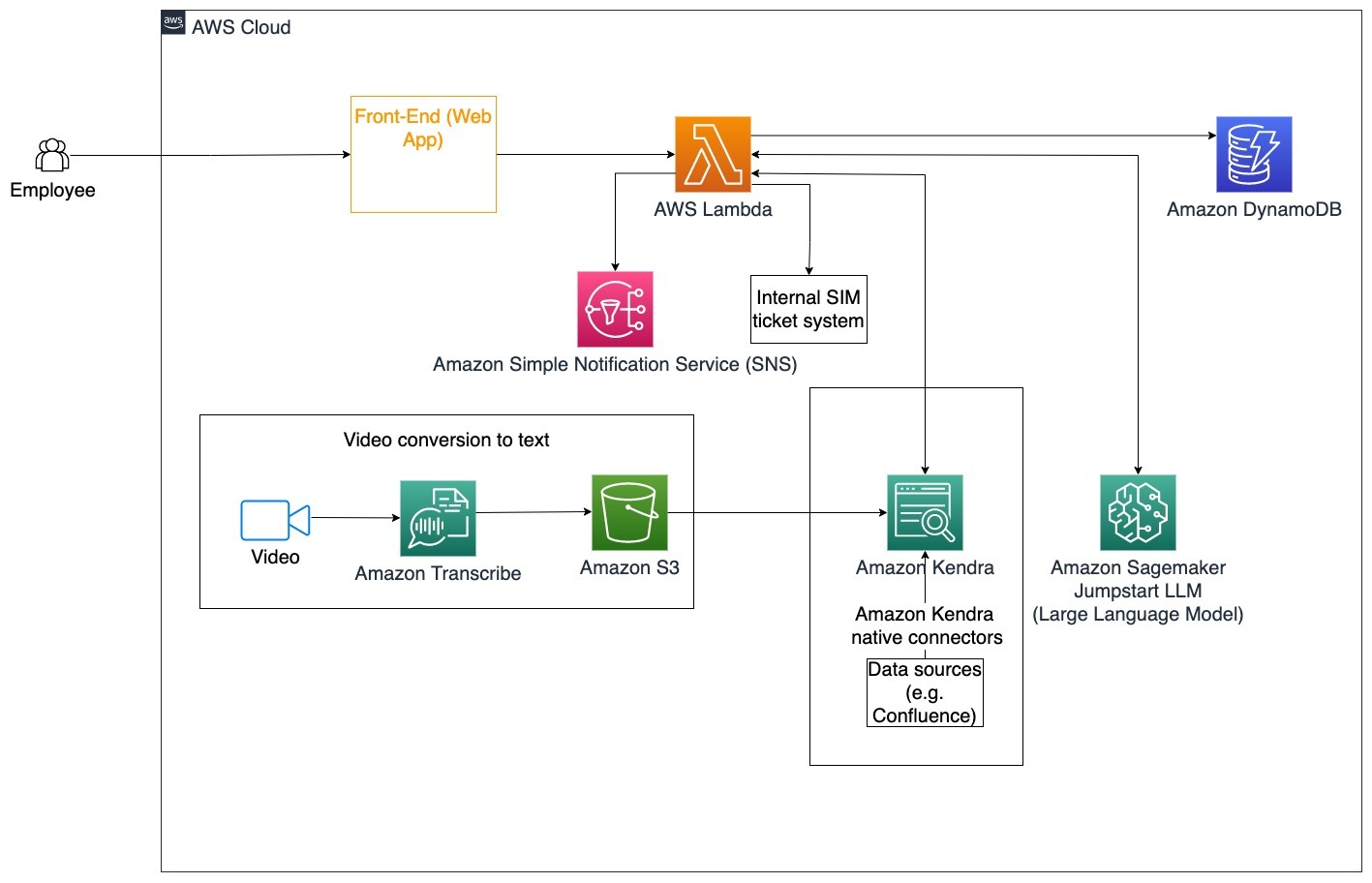
以下の手順は、AWS Lambda関数とその処理の流れを説明しています:
- LangChainエージェントが意図を識別する
- 従業員の要求に基づいて通知を送信する
- チケットのステータスを変更する

このアーキテクチャダイアグラムでは、企業のトレーニングビデオはAmazon Transcribeを介して取り込まれ、これらのビデオのスクリプトのログが収集されます。さらに、さまざまなソース(Confluence、Microsoft SharePoint、Google Drive、Jiraなど)に保存された企業のトレーニングコンテンツは、Amazon Kendraコネクタを介してインデックスを作成するために使用できます。Amazon Kendraのネイティブコネクタの収集については、この記事をお読みください。Amazon Kendraは、これらの他のソースに保存された企業のトレーニングビデオスクリプトとドキュメンテーションの両方を使用して、会社のトレーニングガイドラインに特化した質問に対する会話型ボットのサポートを行います。LangChainエージェントは権限を確認し、チケットのステータスを変更し、Amazon Simple Notification Service(Amazon SNS)を使用して正しい担当者に通知します。
カスタマーサポートチーム
顧客の問い合わせを迅速に解決することは、顧客のエクスペリエンスを向上させ、ブランドのロイヤルティを促進します。忠誠心のある顧客基盤は、売上を推進し、収益を増やし、顧客の関与を高めるのに役立ちます。カスタマーサポートチームは、製品やサービスに関する顧客の問い合わせに対応するために、多くの内部文書や顧客関係管理ソフトウェアを参照するために多くのエネルギーを費やしています。この文脈では、内部文書には一般的な顧客サポートのコールスクリプト、プレイブック、エスカレーションガイドライン、ビジネス情報などが含まれます。生成型AI会話ボットは、顧客サポートチームの代わりにクエリを処理することで、コスト最適化に役立ちます。
具体的な使用例:サービス履歴と購入した顧客サービスプランに基づいたオイル交換のリクエストの処理。
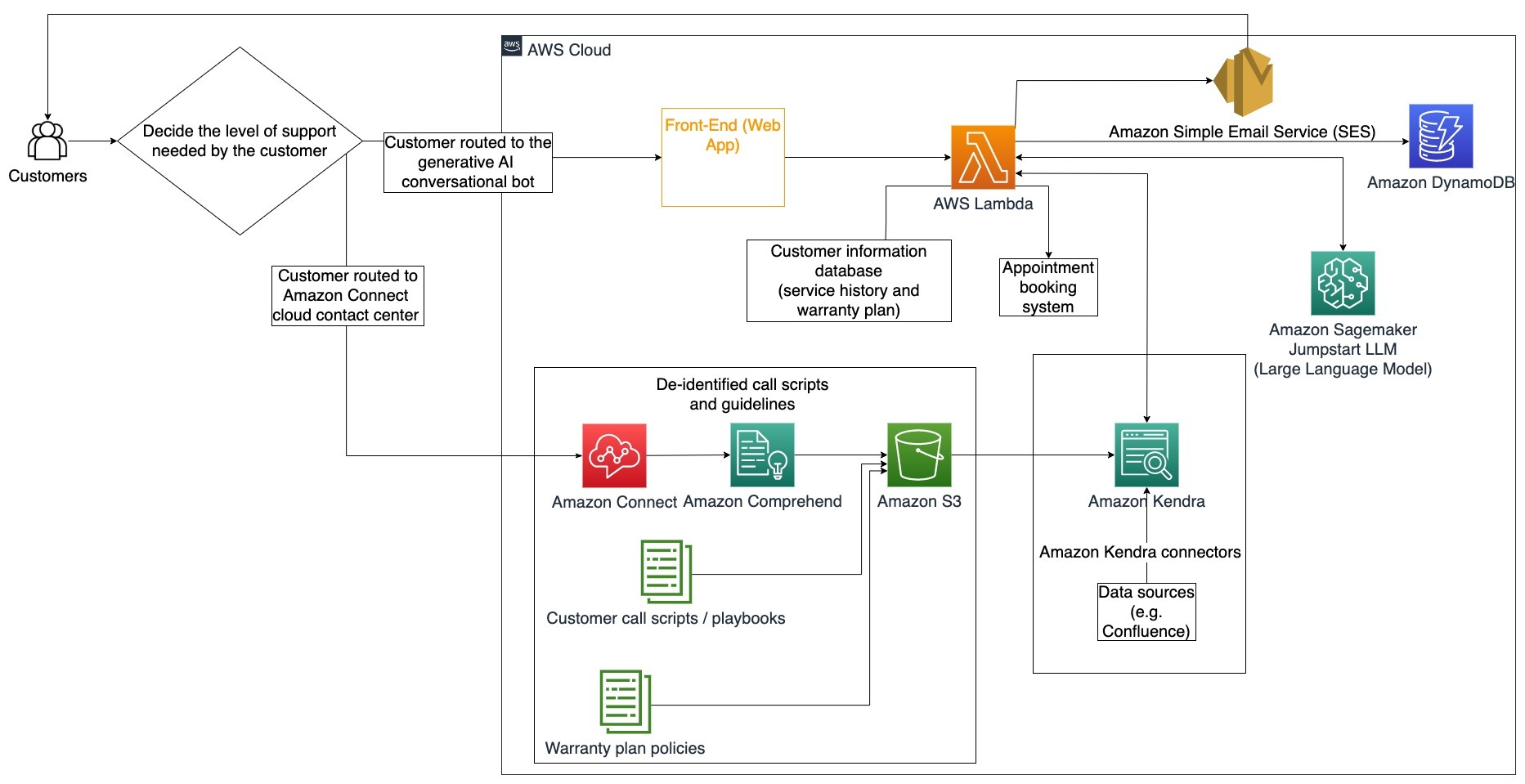
このアーキテクチャダイアグラムでは、顧客は生成型AI会話ボットまたはAmazon Connectコンタクトセンターのいずれかにルーティングされます。この決定は、必要なサポートレベルまたは顧客サポート担当者の利用可能性に基づいて行われる場合があります。LangChainエージェントは顧客の意図を識別し、身元を確認します。LangChainエージェントはまた、サービス履歴と購入したサポートプランをチェックします。
以下の手順は、AWS Lambda関数とその処理の流れを説明しています:
- LangChainエージェントが意図を識別する
- 顧客情報を取得する
- 顧客のサービス履歴と保証情報を確認する
- 予約を入れる、追加情報を提供する、またはコンタクトセンターにルーティングする
- メールで確認を送信する

Amazon Connectは、音声とチャットのログを収集し、Amazon Comprehendはこれらのログから個人を特定できる情報(PII)を削除するために使用されます。その後、Amazon Kendraクローラーは、切り抜かれた音声とチャットのログ、顧客のコールスクリプト、顧客サービスサポートプランポリシーを使用してインデックスを作成できます。決定が下されたら、生成型AI会話ボットは、予約を入れるか、追加情報を提供するか、顧客をコンタクトセンターにルーティングしてさらなるサポートを行うかを決定します。コスト最適化のために、LangChainエージェントは、優先度の低い顧客のクエリに対してトークンの数を減らし、より安価な大規模言語モデルを使用して回答を生成することもできます。
金融サービス
金融サービス企業は、競争力を維持し、金融規制に適合するために情報をタイムリーに活用する必要があります。生成型AI会話ボットを使用することで、金融アナリストやアドバイザーはテキスト情報と対話的にやり取りし、より良い情報に基づいた意思決定にかかる時間と労力を削減することができます。投資や市場調査のほかにも、生成型AI会話ボットは、従来よりも多くの人的労力と時間を必要とするタスクを処理することで、人間の能力を補完することができます。たとえば、個人ローンに特化した金融機関は、ローンの処理速度を向上させながら、顧客に対してより良い透明性を提供することができます。
具体的な使用例:顧客の金融履歴と以前のローン申請を使用して、ローンの決定を行い説明する。
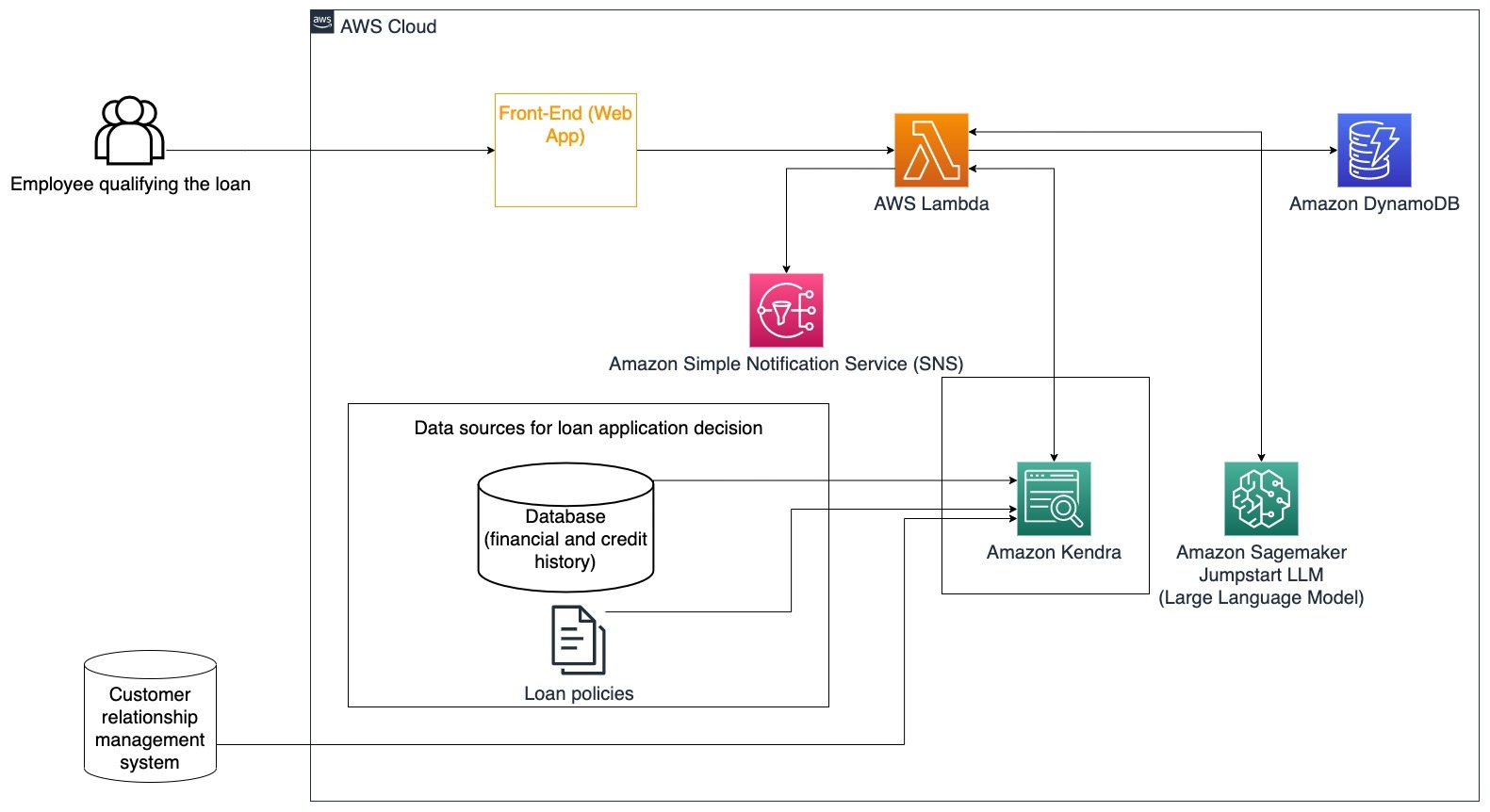
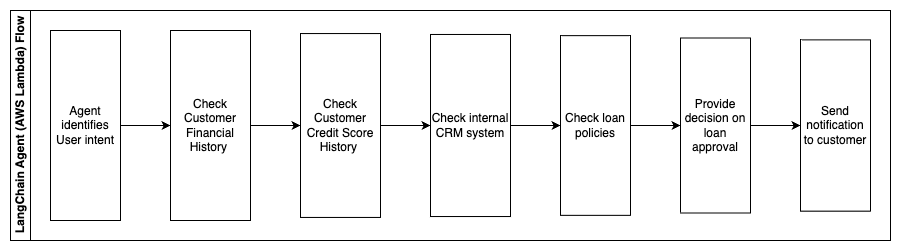
以下の手順は、AWS Lambda関数とそのプロセスを通じてのフローを説明しています:
- LangChainエージェントによる意図の特定
- 顧客の金融および信用スコア履歴の確認
- 内部顧客関係管理システムの確認
- 標準のローンポリシーの確認とローンの資格を持つ従業員に対する意思決定の提案
- 顧客への通知の送信
このアーキテクチャでは、データベースに格納された顧客の金融データと顧客関係管理(CRM)ツールに格納されたデータが組み込まれています。これらのデータポイントは、会社の内部ローンポリシーに基づいた意思決定に使用されます。顧客は、自分が資格を持つローンやローンの条件を理解するための明確な質問をすることができます。生成型AI対話ボットがローン申請を承認できない場合、ユーザーはクレジットスコアの向上や代替の資金調達オプションについての質問をすることができます。
政府
生成型AI対話ボットは、政府機関のコミュニケーション、効率、意思決定プロセスの迅速化に大きな利益をもたらすことができます。生成型AI対話ボットは、政府職員が迅速に情報、ポリシー、手続き(資格基準、申請手続き、市民サービスとサポートなど)を取得するための内部知識ベースへの即時アクセスも提供できます。1つの解決策は、納税者と税務専門家が税金に関連する詳細や特典を簡単に見つけることができるインタラクティブなシステムです。ユーザーの質問を理解し、税金関連書類を要約し、対話的な会話を通じて明確な回答を提供するために使用することができます。
ユーザーは次のような質問をすることができます:
- 相続税はどのように機能し、税の閾値は何ですか?
- 所得税の概念を説明してください。
- 第二の不動産を売却する際の税の影響は何ですか?
さらに、ユーザーはシステムに税務フォームを提出する便利さも享受することができ、提供された情報の正確性を検証するのに役立ちます。
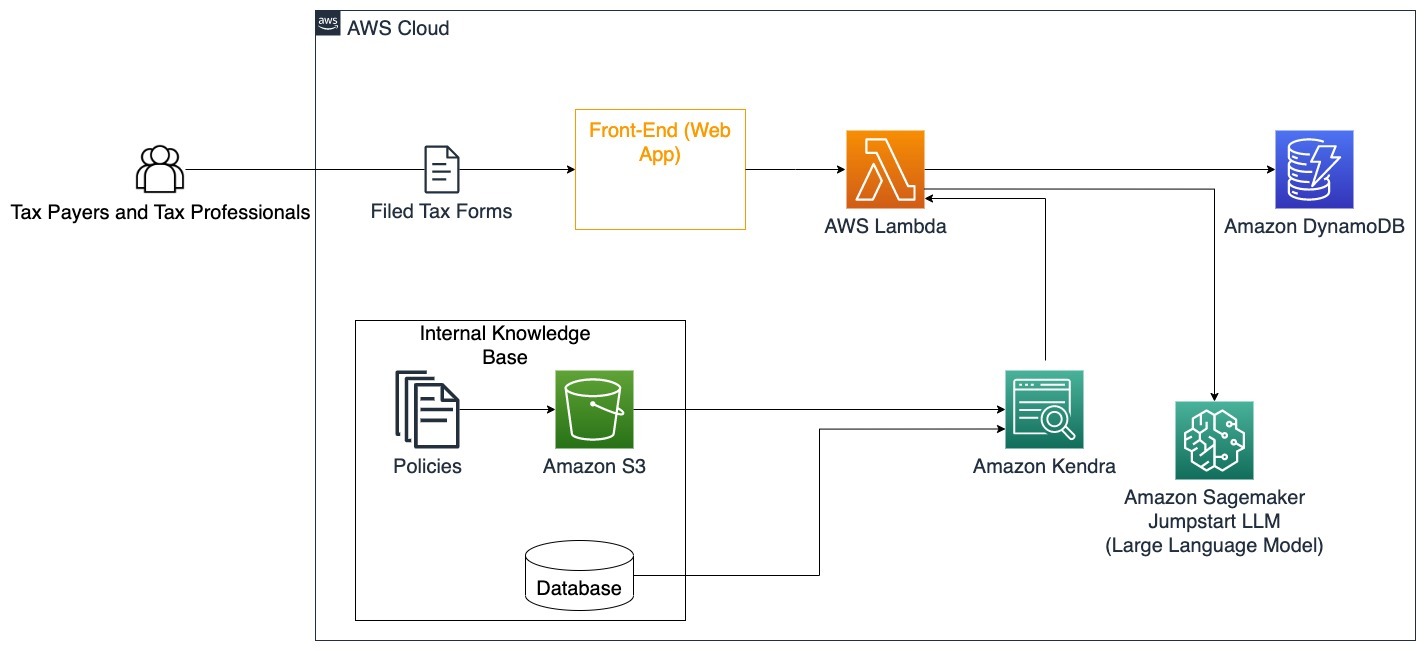
このアーキテクチャは、ユーザーが完成した税務フォームをソリューションにアップロードし、必要な情報の対話的な検証と正確な入力方法に関するガイダンスに利用できることを示しています。
医療
医療企業は、内部の患者情報の大量使用を自動化する機会を持ちながら、治療オプション、保険請求、臨床試験、製薬研究などの使用例に関する一般的な質問にも対応することができます。生成型AI対話ボットを使用することで、提供された知識ベースからの健康情報に関する回答を迅速かつ正確に生成することができます。たとえば、一部の医療専門家は保険請求を行うために多くの時間を費やしています。
同様の状況では、臨床試験の管理者や研究者は治療オプションに関する情報を見つける必要があります。生成型AI対話ボットは、製薬会社や大学による進行中の研究で公開された数百万の文書から最も関連性の高い情報をAmazon Kendraの事前構築コネクタを使用して取得することができます。
具体的な使用例:保険フォームの記入と送信に必要なエラーと時間を削減する。
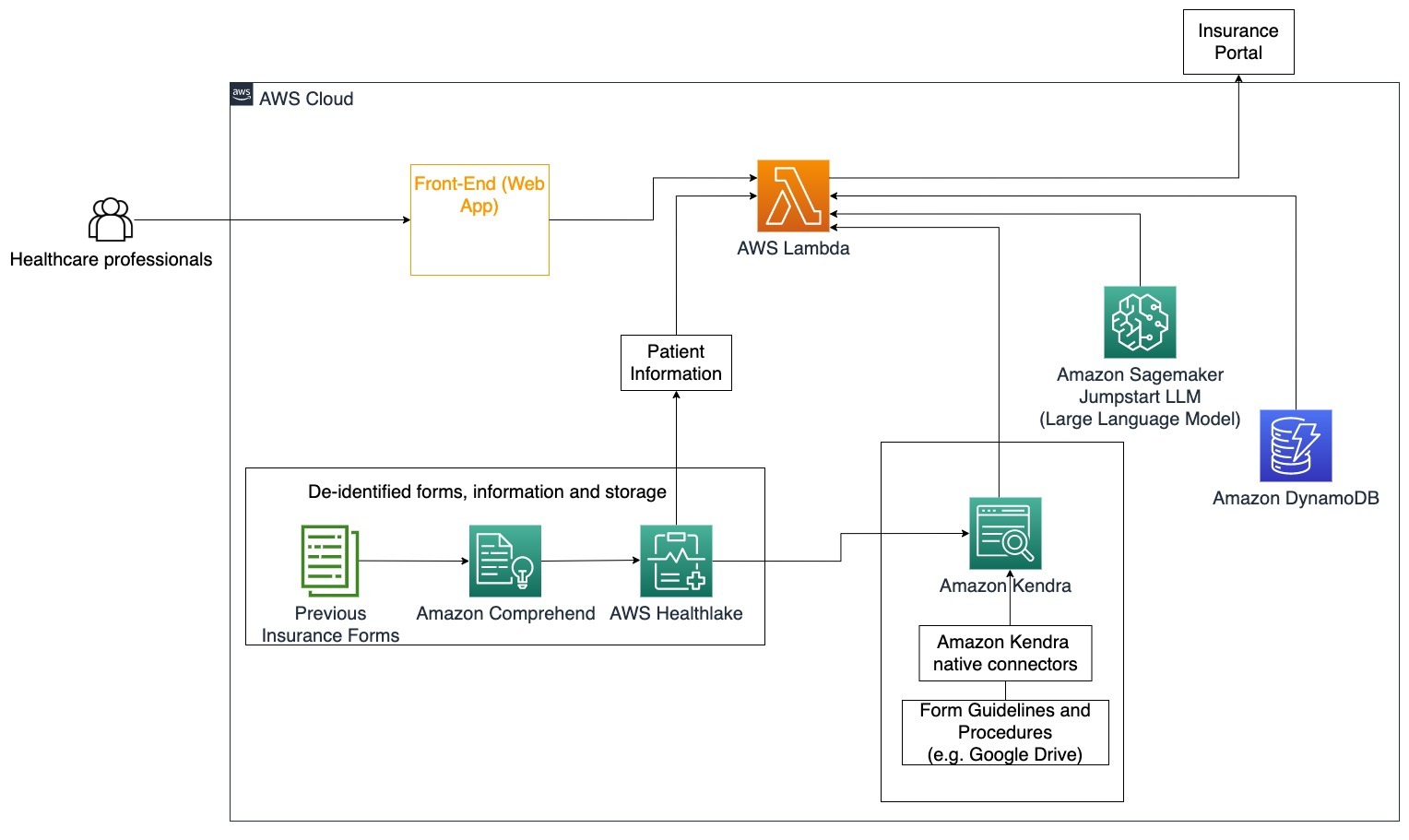
このアーキテクチャ図では、医療専門家は生成型AI対話ボットを使用して保険のためにどのフォームを記入する必要があるかを判断することができます。その後、LangChainエージェントは適切なフォームを取得し、患者の必要な情報を追加し、保険ポリシーと以前のフォームに基づいてフォームの記述部分に対する応答も提供します。医療専門家は、フォームを承認し、保険ポータルに送信する前にLLMが提供した応答を編集することができます。
以下の手順は、AWS Lambda関数とそのプロセスを通過するフローを説明しています:
- LangChainエージェントによる意図の特定
- 必要な患者情報の取得
- 患者情報とフォームガイドラインに基づいて保険申請書を記入する
- ユーザーの承認後、申請書を保険ポータルに送信する
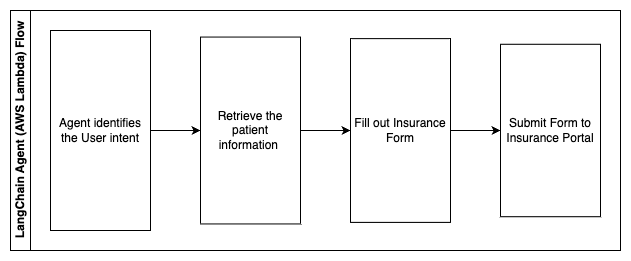
AWS HealthLakeは、以前の保険申請書と患者情報を含む健康データを安全に保存するために使用され、Amazon Comprehendは以前の保険申請書から個人を特定できる情報(PII)を削除するために使用されます。その後、Amazon Kendraクローラーは、保険申請書とガイドラインのセットを使用してインデックスを作成できます。生成されたAIによってフォームが記入された後、医療専門家によってレビューされたフォームは保険ポータルに送信できます。
コストの見積もり
ベースソリューションを概念実証として展開する場合のコストは、次の表に示されています。ベースソリューションは概念実証と見なされるため、低コストなオプションとしてAmazon Kendra Developer Editionが使用されました。Amazon Kendra Developer Editionのアクティブな時間は1か月間で730時間と想定されています。
Amazon SageMakerについては、リアルタイムの推論にml.g4dn.2xlargeインスタンスを使用し、インスタンスごとに単一の推論エンドポイントを使用するという仮定をしました。Amazon SageMakerの価格と利用可能な推論インスタンスタイプの詳細については、こちらをご覧ください。
| サービス | 利用リソース | 月間のUSDでの見積もりコスト |
| AWS Amplify | ビルド時間150分 データ提供1 GB リクエスト数50万件 | 15.71 |
| Amazon API Gateway | REST API呼び出し数100万件 | 3.5 |
| AWS Lambda | リクエスト数100万件 リクエストあたりの実行時間5秒 メモリ割り当て2 GB | 160.23 |
| Amazon DynamoDB | 読み取り数100万回 書き込み数100万回 ストレージ100 GB | 26.38 |
| Amazon Sagemaker | ml.g4dn.2xlargeを使用したリアルタイムの推論 | 676.8 |
| Amazon Kendra | Developer Editionで1か月あたり730時間、スキャンされるドキュメント数1万件、1日のクエリ数5,000件 | 821.25 |
| . | . | 総コスト:1703.87 |
* Amazon Cognitoは、Cognitoユーザープールを使用する月間アクティブユーザー数が50,000人またはSAML 2.0 IDプロバイダを使用する月間アクティブユーザー数が50人の無料利用枠があります
クリーンアップ
コストを節約するために、チュートリアルの一環として展開したリソースをすべて削除してください。SageMakerコンソールを介して作成したSageMakerエンドポイントを削除することができます。Amazon Kendraインデックスを削除しても、元のドキュメントはストレージから削除されませんのでご注意ください。
結論
この記事では、複数のリポジトリからの情報のアクセスを簡素化する方法を、リアルタイムで要約することによって紹介しました。商業向けLLMsの最近の進展により、生成AIの可能性がより明確になりました。この記事では、質問に答えるために生成AIを使用するサーバーレスチャットボットを作成するためにAWSサービスを使用する方法を紹介しました。このアプローチは、認証レイヤーとAmazon ComprehendのPII検出を組み合わせて、ユーザーのクエリに提供される機密情報をフィルタリングします。医療の個人が保険請求を理解するためのニュアンスや、HRが特定の企業全体の規制を理解するためのアプローチは、複数の産業や垂直市場でメリットを得ることができます。Amazon SageMaker JumpStartの基礎モデルはチャットボットのエンジンであり、内部ドキュメントへのより正確な参照を確保するために、RAGテクニックを使用したコンテキストスタッフィングアプローチが使用されています。
AWSでジェネレーティブAIを使用する方法についての詳細は、AWSでのジェネレーティブAIのビルディングに関する新ツールの発表を参照してください。 AWSサービスとともにRAGテクニックを使用するためのより詳細なガイダンスについては、Amazon Kendra、LangChain、および大規模な言語モデルを使用した企業データに対する高精度のジェネレーティブAIアプリケーションを迅速に構築することを参照してください。このブログのアプローチはLLMに依存しないため、推論には任意のLLMを使用できます。次の投稿では、Amazon BedrockとAmazon Titan LLMを使用してこのソリューションを実装する方法について説明します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
- 「アメリカがGoogleの検索支配に挑戦する」
- 「GPT-4と説明可能なAI(XAI)によるAIの未来の解明」
- コンテンツを人間味を持たせ、AIの盗作を克服する方法
- 「Amazon QuickSightでワードクラウドとしてAmazon Comprehendの分析結果を可視化する」
- 「Hugging Faceを使用してAmazon SageMakerでのメール分類により、クライアントの成功管理を加速する」
- 「Amazon SageMakerは、個々のユーザーのためにAmazon SageMaker Studioのセットアップを簡素化します」






