「PyTorch ProfilerとTensorBoardを使用して、データ入力パイプラインのボトルネックを解消する」
Using PyTorch Profiler and TensorBoard to resolve data input pipeline bottlenecks.
PyTorchモデルのパフォーマンス分析と最適化 — 第4部
これは、GPUベースのPyTorchワークロードのパフォーマンス分析と最適化に関するシリーズ記事の第4回目です。この記事では、トレーニングデータ入力パイプラインに焦点を当てます。通常のトレーニングアプリケーションでは、ホストのCPUがデータをロードし、前処理し、まとめてからGPUに送る前にデータを供給します。入力パイプラインのボトルネックは、ホストがGPUの速度に追いつけない場合に発生します。これにより、トレーニングセットアップで最も高価なリソースであるGPUが待機時間中にアイドル状態になります。これまでの記事(例:こちら)では、入力パイプラインのボトルネックについて詳しく説明し、それらを解決するための異なる方法(例:MLワークロードに最適なインスタンスタイプを選択するためのヒントなど)について検討しました。
- ワークロードにより適したCPUからGPUの計算比率を持つトレーニングインスタンスを選択する(例:MLワークロードに最適なインスタンスタイプを選択するための前回の記事を参照)
- CPUとGPUのワークロードバランスを改善するために、一部のCPU前処理をGPUに移動する
- CPUの計算を補助的なCPUワーカーデバイスにオフロードする(例:こちらを参照)
もちろん、データ入力パイプラインのパフォーマンスボトルネックに対処するための最初のステップは、それを特定し理解することです。この記事では、PyTorch Profilerとその関連するTensorBoardプラグインを使用してこれを実行する方法を示します。
前の記事と同様に、トイモデルを定義し、そのパフォーマンスを繰り返しプロファイリングし、ボトルネックを特定し、修正しようとします。実験はAmazon EC2 g5.2xlargeインスタンス(NVIDIA A10G GPUと8 vCPUを搭載)と公式のAWS PyTorch 2.0 Dockerイメージで実行されます。説明する行動の一部は、PyTorchのバージョンによって異なる場合があることを念頭に置いてください。
この記事に貢献してくれたYitzhak Leviさんに感謝します。
トイモデル
以下のブロックでは、デモンストレーションに使用するトイの例を紹介します。まず、単純な画像分類モデルを定義します。モデルへの入力は、256×256のYUV画像のバッチであり、出力は関連するクラスの予測バッチです。
from math import log2import torchimport torch.nn as nnimport torch.nn.functional as Fimg_size = 256num_classes = 10hidden_size = 30# トイCNN分類モデルclass Net(nn.Module): def __init__(self, img_size=img_size, num_classes=num_classes): super().__init__() self.conv_in = nn.Conv2d(3, hidden_size, 3, padding='same') num_hidden = int(log2(img_size)) hidden = [] for i in range(num_hidden): hidden.append(nn.Conv2d(hidden_size, hidden_size, 3, padding='same')) hidden.append(nn.ReLU()) hidden.append(nn.MaxPool2d(2)) self.hidden = nn.Sequential(*hidden) self.conv_out = nn.Conv2d(hidden_size, num_classes, 3, padding='same') def forward(self, x): x = F.relu(self.conv_in(x)) x = self.hidden(x) x = self.conv_out(x) x = torch.flatten(x, 1) return x以下のコードブロックには、データセットの定義が含まれています。データセットには、1万個のjpeg画像ファイルパスとそれに関連する(ランダムに生成された)意味的なラベルが含まれています。デモンストレーションを簡素化するために、すべてのjpegファイルパスがこの記事の上部にあるカラフルな「ボトルネック」の画像を指すものとします。
import numpy as npfrom PIL import Imagefrom torchvision.datasets.vision import VisionDatasetinput_img_size = [533, 800]class FakeDataset(VisionDataset): def __init__(self, transform): super().__init__(root=None, transform=transform) size = 10000 self.img_files = [f'0.jpg' for i in range(size)] self.targets = np.random.randint(low=0,high=num_classes, size=(size),dtype=np.uint8).tolist() def __getitem__(self, index): img_file, target = self.img_files[index], self.targets[index] with torch.profiler.record_function('PIL open'): img = Image.open(img_file) if self.transform is not None: img = self.transform(img) return img, target def __len__(self): return len(self.img_files)ファイルリーダーをtorch.profiler.record_functionのコンテキストマネージャでラッピングしたことに注意してください。
入力データパイプラインには、次の画像変換が含まれます:
- PILToTensorはPIL画像をPyTorch Tensorに変換します。
- RandomCropは画像内のランダムなオフセットで256×256のクロップを返します。
- RandomMaskは、ランダムな256×256のブールマスクを作成し、画像に適用するカスタム変換です。変換には、マスク上の4近傍膨張操作が含まれます。
- ConvertColorは、画像形式をRGBからYUVに変換するカスタム変換です。
- Scaleは、ピクセルを範囲[0,1]にスケーリングするカスタム変換です。
class RandomMask(torch.nn.Module): def __init__(self, ratio=0.25): super().__init__() self.ratio=ratio def dilate_mask(self, mask): # マスクの4近傍膨張を実行する with torch.profiler.record_function('dilation'): from scipy.signal import convolve2d dilated = convolve2d(mask, [[0, 1, 0], [1, 1, 1], [0, 1, 0]], mode='same').astype(bool) return dilated def forward(self, img): with torch.profiler.record_function('random'): mask = np.random.uniform(size=(img_size, img_size)) < self.ratio dilated_mask = torch.unsqueeze(torch.tensor(self.dilate_mask(mask)),0) dilated_mask = dilated_mask.expand(3,-1,-1) img[dilated_mask] = 0. return img def __repr__(self): return f"{self.__class__.__name__}(ratio={self.ratio})"class ConvertColor(torch.nn.Module): def __init__(self): super().__init__() self.A=torch.tensor( [[0.299, 0.587, 0.114], [-0.16874, -0.33126, 0.5], [0.5, -0.41869, -0.08131]] ) self.b=torch.tensor([0.,128.,128.]) def forward(self, img): img = img.to(dtype=torch.get_default_dtype()) img = torch.matmul(self.A,img.view([3,-1])).view(img.shape) img = img + self.b[:,None,None] return img def __repr__(self): return f"{self.__class__.__name__}()"class Scale(object): def __call__(self, img): return img.to(dtype=torch.get_default_dtype()).div(255) def __repr__(self): return f"{self.__class__.__name__}()"変換をチェーンするために、各変換呼び出しの周りにtorch.profiler.record_functionコンテキストマネージャが含まれるように、Composeクラスを微調整した形で使用しています。
import torchvision.transforms as Tclass CustomCompose(T.Compose): def __call__(self, img): for t in self.transforms: with torch.profiler.record_function(t.__class__.__name__): img = t(img) return imgtransform = CustomCompose( [T.PILToTensor(), T.RandomCrop(img_size), RandomMask(), ConvertColor(), Scale()])以下のコードブロックでは、データセットとデータローダーを定義しています。デフォルトのコラート関数をtorch.profiler.record_functionコンテキストマネージャでラップするカスタムコラート関数をDataLoaderに使用するように構成しています。
train_set = FakeDataset(transform=transform)def custom_collate(batch): from torch.utils.data._utils.collate import default_collate with torch.profiler.record_function('collate'): batch = default_collate(batch) image, label = batch return image, labeltrain_loader = torch.utils.data.DataLoader(train_set, batch_size=256, collate_fn=custom_collate, num_workers=4, pin_memory=True)最後に、モデル、損失関数、オプティマイザ、およびトレーニングループを定義し、プロファイラのコンテキストマネージャでラップしています。
from statistics import mean, variancefrom time import timedevice = torch.device("cuda:0")model = Net().cuda(device)criterion = nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()t0 = time()times = []with torch.profiler.profile( schedule=torch.profiler.schedule(wait=10, warmup=2, active=10, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'), record_shapes=True, profile_memory=True, with_stack=True) as prof: for step, data in enumerate(train_loader): with torch.profiler.record_function('h2d copy'): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) if step >= 40: break outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step() prof.step() times.append(time()-t0) t0 = time()print(f'average time: {mean(times[1:])}, variance: {variance(times[1:])}')以下のセクションでは、PyTorch Profilerとそれに関連するTensorBoardプラグインを使用して、モデルのパフォーマンスを評価します。私たちの焦点はプロファイラレポートのトレースビューにあります。他のセクションの使用方法については、シリーズの最初の投稿をご覧ください。
初期パフォーマンス結果
定義したスクリプトによって報告される平均ステップ時間は1.3秒であり、平均GPU利用率は非常に低い18.21%です。以下の画像では、TensorBoardプラグインのトレースビューで表示されるパフォーマンス結果をキャプチャしています:
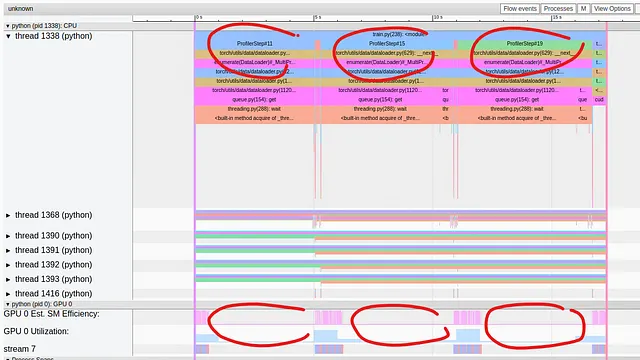
すべての第4トレーニングステップには、GPUが完全にアイドル状態になる長い(約5.5秒)データローディング期間が含まれていることがわかります。これが毎4回のステップで発生する理由は、私たちが選んだDataLoaderワーカーの数(4)と直接関係しています。毎4回目のステップでは、次のバッチのサンプルを生成するためにすべてのワーカーがビジー状態になり、GPUが待機します。これは、データ入力パイプラインにボトルネックが存在する明確な証拠です。問題はどのように分析するかです。さらに複雑になるのは、コードに挿入した多くのrecord_functionマーカーがプロファイルトレースに見当たらないことです。
DataLoaderで複数のワーカーを使用することは、パフォーマンスを最適化するために重要です。残念ながら、これはプロファイリングプロセスをより困難にします。マルチプロセスの分析をサポートするプロファイラ(例えば、VizTracerをチェックしてみてください)も存在しますが、この投稿では、シングルプロセスモード(つまり、DataLoaderワーカーをゼロに設定)でモデルを実行、分析、最適化し、その最適化をマルチワーカーモードに適用する方法を取ります。確かに、スタンドアロン関数の速度を最適化しても、同じ関数の複数(並列)呼び出しも同様に利益をもたらすわけではありません。しかし、この投稿で見るように、この戦略を適用することで、それ以外には特定できなかったいくつかの基本的な問題を特定し解決することができ、少なくともここで議論されている問題に関しては、2つのモード間のパフォーマンスへの影響に強い相関関係が見つかります。ただし、この戦略を適用する前に、ワーカーの数の選択を調整してみましょう。
最適化1:マルチプロセス戦略の調整
マルチプロセス/マルチスレッドのアプリケーション(私たちの場合)におけるスレッドまたはプロセスの最適な数を決定するのは難しいことがあります。一方で、数が低すぎるとCPUリソースの利用が不十分になる可能性があります。一方で、数が高すぎると、オペレーティングシステムが複数のスレッディング/処理を管理するためにほとんどの時間を費やし、コードの実行よりも管理に時間を費やすという望ましくない状況に陥る可能性があります。PyTorchのトレーニングワークロードの場合、DataLoaderのnum_workers設定について異なる選択肢をテストすることをお勧めします。開始する良い方法は、ホストのCPUの数に基づいて数を設定することです(例:num_workers:=num_cpus/num_gpus)。私たちの場合、Amazon EC2 g5.2xlargeは8つのvCPUを持っており、実際にDataLoaderのワーカー数を8に増やすと、平均ステップ時間が1.17秒(11%向上)とやや改善されます。
重要なのは、データ入力パイプラインで使用されるスレッドやプロセスの数に影響を与える可能性のある他の、あまり明白でない設定も注意することです。例えば、コンピュータビジョンワークロードで一般的に使用される画像前処理のためのライブラリであるopencv-pythonは、cv2.setNumThreads(int)関数を含んでおり、スレッドの数を制御するために使用することができます。
以下の画像では、num_workersをゼロに設定してスクリプトを実行したときのトレースビューの一部をキャプチャしています。

この方法でスクリプトを実行すると、設定したrecord_functionのラベルが表示され、各個別のサンプルの取得において最も時間がかかる操作であるRandomMaskトランスフォーム、具体的には私たちの膨張関数を特定することができます。
最適化2:膨張関数の最適化
現在の膨張関数の実装では、2D畳み込みが使用されています。通常、これは行列の乗算を使用して実装され、CPU上で特に高速に実行されるわけではありません。一つのオプションは、GPU上で膨張を実行することです(この記事で説明されています)。ただし、ホストデバイスのトランザクションに関連するオーバーヘッドは、この種のソリューションから得られる潜在的なパフォーマンスの向上を上回る可能性があります。また、GPUへの負荷を増やしたくないということもあります。
以下のコードブロックでは、畳み込みではなくブール演算を使用した、よりCPUに優しい膨張関数の代替案を提案しています:
def dilate_mask(self, mask): # マスクに4方向の膨張を実行する with torch.profiler.record_function('dilation'): padded = np.pad(mask, [(1,1),(1,1)]) dilated = padded[0:-2,1:-1] | padded[1:-1,1:-1] | padded[2:,1:-1] | padded[1:-1,0:-2]| padded[1:-1,2:] return dilatedこの変更後、ステップの時間は0.78秒に短縮され、さらに50%の改善があります。更新されたシングルプロセスのトレースビューは以下の通りです:

膨張操作が大幅に縮小され、最も時間がかかる操作がPILToTensor変換になったことがわかります。
PILToTensor関数(こちらを参照)を詳しく調べると、次の3つの基本的な操作が行われていることがわかります:
- PIL画像のロード – Image.openの遅延読み込みの性質により、画像はここで読み込まれます。
- PIL画像をnumpy配列に変換します。
- numpy配列をPyTorch Tensorに変換します。
画像の読み込みが時間の大部分を占めていることは確かですが、その後の操作をフルサイズの画像に適用してすぐに切り取るという非常に無駄なことがわかります。これが次の最適化へとつながります。
最適化3:変換の順序変更
幸いなことに、RandomCrop変換はPIL画像に直接適用できるため、パイプラインの最初の操作として画像サイズの縮小を適用できます:
transform = CustomCompose( [T.RandomCrop(img_size), T.PILToTensor(), RandomMask(), ConvertColor(), Scale()])この最適化により、ステップの時間が0.72秒に短縮され、さらに8%の最適化が行われます。以下のトレースビューのキャプチャでは、RandomCrop変換が主要な操作になっていることがわかります:

実際には、前と同様に、ボトルネックはランダムクロップではなくPIL画像(遅延読み込み)のロードです。
理想的には、興味のある範囲のみで読み込み操作を制限することでさらに最適化できるはずですが、torchvisionはこのオプションをサポートしていないため、現時点ではできません。将来の記事では、独自のカスタムdecode_and_crop PyTorchオペレーターを実装することで、この不足をどのように克服できるかを示します。
最適化4:バッチ変換の適用
現在の実装では、各画像変換は個々の画像に適用されます。ただし、一部の変換は、バッチ全体に一度に適用するとより最適に実行される場合があります。以下のコードブロックでは、ColorTransformationおよびScale変換をカスタムのcollate関数内で画像のバッチに適用するようにパイプラインを変更しています:
def batch_transform(img): img = img.to(dtype=torch.get_default_dtype()) A = torch.tensor( [[0.299, 0.587, 0.114], [-0.16874, -0.33126, 0.5], [0.5, -0.41869, -0.08131]] ) b = torch.tensor([0., 128., 128.]) A = torch.broadcast_to(A, ([img.shape[0],3,3])) t_img = torch.bmm(A,img.view(img.shape[0],3,-1)) t_img = t_img + b[None,:, None] return t_img.view(img.shape)/255def custom_collate(batch): from torch.utils.data._utils.collate import default_collate with torch.profiler.record_function('collate'): batch = default_collate(batch) image, label = batch with torch.profiler.record_function('batch_transform'): image = batch_transform(image) return image, labelこの変更の結果、ステップ時間がわずかに増加し、0.75秒になりました。おもちゃのモデルの場合には役に立ちませんが、バッチ変換として特定の操作を適用する能力は、特定のワークロードを最適化する可能性を持っています。
結果
この記事で行った連続した最適化により、ランタイム性能が80%向上しました。ただし、より軽度ですが、入力パイプラインにはまだボトルネックが残り、GPUの利用率は非常に低いままです(約30%)。このような問題に対処するための追加の方法については、以前の記事(例:こちら)をご覧ください。
概要
この記事では、トレーニングデータの入力パイプラインのパフォーマンスの問題に焦点を当てました。このシリーズの以前の記事と同様に、私たちはPyTorch Profilerとそれに関連するTensorBoardプラグインを選択し、トレーニングの速度を加速するための使用方法を示しました。特に、DataLoaderをゼロのワーカーで実行することで、データ入力パイプラインのボトルネックを特定し、分析し、最適化する能力が向上することを示しました。
以前の記事と同様に、トレーニングプロジェクトの詳細(モデルアーキテクチャやトレーニング環境など)に基づいて、成功した最適化への道筋は大きく異なることを強調します。実際には、ここで示した例よりも目標を達成することはより困難かもしれません。説明した技術のいくつかは、パフォーマンスにほとんど影響を与えないか、逆に悪化させる可能性もあります。また、私たちが選んだ具体的な最適化および適用順序は、多少恣意的であることにも注意してください。プロジェクトの具体的な詳細に基づいて、自分自身のツールと技術を開発して最適化目標に到達することを強くお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「サンフランシスコ大学データサイエンスカンファレンス2023年データソン(Datathon)は、AWSおよびAmazon SageMaker Studio Labと提携して開催されます」
- 「Androidのための10最高のデータ復旧ツール」
- 「AIと大学フットボールの未来」
- AIはETLの再発明に時間を浪費する必要はない
- 「データサイエンスの熱狂者にとっての必聴ポッドキャスト10選」
- 2023年の練習のためのトップ18のPower BIプロジェクトアイデア
- 「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
