効率的で安定した拡散微調整のためのLoRAの使用
Using LoRA for efficient and stable diffusion fine-tuning.
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。
DiffusersのためのLoRA 🧨
LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。
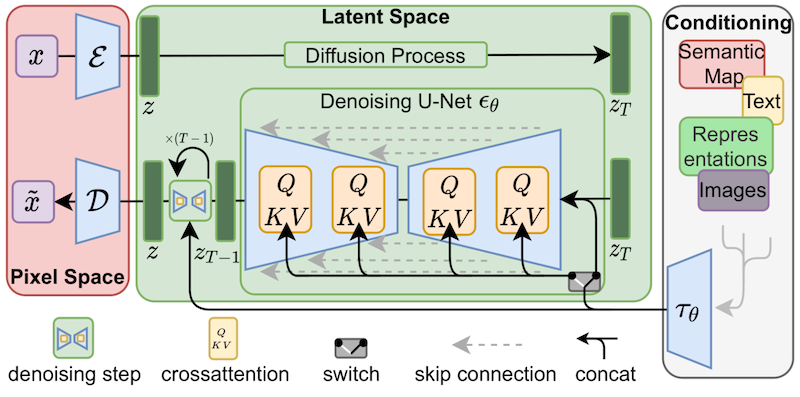
私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。
- 2Dアセット生成:ゲーム開発のためのAI #4
- Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
- ストーリーの生成:ゲーム開発のためのAI #5
クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。
私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します:
- 既に議論されているように、トレーニングがはるかに高速です。
- 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました!
- トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。
私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。
LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。
(@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。
LoRAの微調整
Stable Diffusionの完全なモデルの微調整は遅くて難しかったため、DreamboothやTextual Inversionなどの軽量な方法が非常に人気となっています。LoRAを使用すると、カスタムデータセットでモデルを微調整することがはるかに簡単になります。
Diffusersは、8ビットオプティマイザなどのトリックを使わずに、11 GBのGPU RAMで実行できるLoRA微調整スクリプトを提供しています。以下は、Lambda Labsのポケモンデータセットを使用してモデルを微調整する方法です:
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337ひとつ注意すべき点は、学習率が通常のファインチューニングの学習率(おおよそ1e-6のオーダー)よりもはるかに大きい、つまり1e-4であることです。これは前回の実行のW&Bダッシュボードであり、2080 Ti GPU(11 GBのRAM)で約5時間かかりました。ハイパーパラメータの最適化は試みていないため、自由に試してみてください! SayakはT4(16 GBのRAM)で別の実行を行いましたが、彼の最終モデルはこちらです、そしてそれを使用するデモSpaceはこちらです。

diffusersのLoRAサポートの詳細については、私たちのドキュメントを参照してください。それは常に実装と最新の情報を提供しています。
推論
前述のように、LoRAの主な利点の一つは、元のモデルサイズの何桁も少ない重みを学習することで優れた結果を得ることです。我々は、未加工のStable Diffusionモデルの重みの上に追加の重みをロードするインファレンスプロセスを設計しました。それがどのように機能するか見てみましょう。
まず、Hub APIを使用して、LoRAモデルのファインチューニングに使用されたベースモデルを自動的に特定します。Sayakのモデルを例にすると、次のコードを使用できます:
from huggingface_hub import model_info
# LoRA weights ~3 MB
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
info = model_info(model_path)
model_base = info.cardData["base_model"]
print(model_base) # CompVis/stable-diffusion-v1-4このスニペットは、彼がファインチューニングに使用したモデルであるCompVis/stable-diffusion-v1-4を出力します。私の場合、Stable Diffusionのバージョン1.5を起点にモデルをトレーニングしましたので、同じコードを私のLoRAモデルで実行すると、出力はrunwayml/stable-diffusion-v1-5になります。
ベースモデルに関する情報は、--push_to_hubオプションを使用する場合に、前のセクションで見たファインチューニングスクリプトによって自動的に入力されます。これは、モデルのリポジトリのREADMEファイルにメタデータタグとして記録されています。こちらをご覧ください。
LoRAでファインチューニングしたベースモデルを決定した後、通常のStable Diffusionパイプラインをロードします。非常に高速な推論のためにDPMSolverMultistepSchedulerをカスタマイズします:
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)そして、ここで魔法が起こります。私たちは通常のモデルの重みの上にHubからLoRAの重みをロードし、パイプラインをcudaデバイスに移動して推論を実行します:
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe("Green pokemon with menacing face", num_inference_steps=25).images[0]
image.save("green_pokemon.png")LoRAを使ったDreambooth
Dreamboothでは、安定した拡散モデルに新しい概念を「教える」ことができます。LoRAはDreamboothと互換性があり、プロセスは微調整と似ていますが、いくつかの利点があります:
- トレーニングが速いです。
- トレーニングしたい対象の数枚または数十枚の画像だけで十分です(通常5枚か10枚で十分です)。
- 必要に応じてテキストエンコーダを調整することで、対象に対する忠実度を高めることができます。
LoRAを使用してDreamboothをトレーニングするには、このディフューザースクリプトを使用する必要があります。詳細については、README、ドキュメント、およびハイパーパラメータの探索ブログ記事をご覧ください。
LoRAを使用してDreamboothモデルを素早く、安価で簡単にトレーニングする方法として、hystsのこのスペースを確認してください。それを複製し、GPUを割り当てて高速に実行する必要があります。このプロセスにより、独自のトレーニング環境を設定する手間が省け、数分でモデルをトレーニングすることができます!
その他の方法
簡単な微調整を求める探求は新しいものではありません。Dreamboothに加えて、テキスト反転は訓練された安定した拡散モデルに新しい概念を教える別の人気のある方法です。テキスト反転の使用の主な理由の1つは、訓練された重みも小さく、共有しやすいことです。ただし、テキスト反転は単一の対象(または少数の対象)にしか適用できず、LoRAは汎用的な微調整に使用できるため、新しいドメインやデータセットにも適応することができます。
Pivotal Tuningは、テキスト反転とLoRAを組み合わせようとする方法です。まず、テキスト反転の技術を使用してモデルに新しい概念を教え、それを表現するための新しいトークン埋め込みを取得します。次に、そのトークン埋め込みをLoRAでトレーニングして、両方のメリットを得ます。
まだLoRAとPivotal Tuningを探求していません。誰がチャレンジしましょうか? 🤗
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






