Langchainを使用してYouTube動画用のChatGPTを構築する
Using Langchain to build ChatGPT for YouTube videos.
はじめに
ビデオとチャットで話すことができたらどのくらい便利だろうかと考えたことがありますか?私自身、ブログを書く人間として、関連する情報を見つけるために1時間ものビデオを見ることはしばしば退屈に感じます。ビデオから有用な情報を得るために、ビデオを見ることが仕事のように感じることもあります。そこで、YouTubeビデオやその他のビデオとチャットできるチャットボットを作成しました。これは、GPT-3.5-turbo、Langchain、ChromaDB、Whisper、およびGradioによって実現されました。この記事では、Langchainを使用してYouTubeビデオのための機能的なチャットボットを構築するコードの解説を行います。
学習目標
- Gradioを使用してWebインターフェースを構築する
- Whisperを使用してYouTubeビデオを処理し、テキストデータを抽出する
- テキストデータを適切に処理およびフォーマットする
- テキストデータの埋め込みを作成する
- Chroma DBを構成してデータを保存する
- OpenAI chatGPT、ChromaDB、および埋め込み機能を使用してLangchainの会話チェーンを初期化する
- 最後に、Gradioチャットボットに対するクエリとストリーミング回答を行う
コーディングの部分に入る前に、使用するツールや技術に慣れておきましょう。
この記事は、Data Science Blogathonの一部として公開されました。
Langchain
Langchainは、Pythonで書かれたオープンソースのツールで、Large Language Modelsデータに対応したエージェントを作成できます。では、それはどういうことでしょうか?GPT-3.5やGPT-4など、商用で利用可能な大規模言語モデルのほとんどは、トレーニングされたデータに制限があります。たとえば、ChatGPTは、すでに見た質問にしか答えることができません。2021年9月以降のものは不明です。これがLangchainが解決する核心的な問題です。Wordドキュメントや個人用PDFなど、どのデータでもLLMに送信して人間らしい回答を得ることができます。ベクトルDB、チャットモデル、および埋め込み関数などのツールにはラッパーがあり、Langchainだけを使用してAIアプリケーションを簡単に構築できます。
- Earth.comとProvectusがAmazon SageMakerを使用してMLOpsインフラストラクチャを実装する方法
- Amazon SageMaker StudioでAmazon SageMaker JumpStartの独自の基盤モデルを使用してください
- A.I.はいつか医療の奇跡を起こすかもしれませんしかし今のところ、役立つのは書類作業です

Langchainを使用すると、エージェント(LLMボット)を構築することもできます。これらの自律エージェントは、データ分析、SQLクエリ、基本的なコードの記述など、複数のタスクに設定できます。これらのエージェントを使用することで、低レベルな知識作業をLLMに外注することができるため、時間とエネルギーを節約できます。
このプロジェクトでは、Langchainツールを使用して、ビデオ用のチャットアプリを構築します。Langchainに関する詳細については、公式サイトを訪問してください。
Whisper
Whisperは、OpenAIの別の製品です。これは、オーディオまたはビデオをテキストに変換できる汎用音声認識モデルです。多言語翻訳、音声認識、および分類を実行するために、多様なオーディオをトレーニングしています。
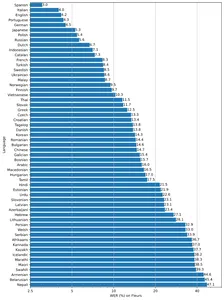
このモデルには、tiny、base、VoAGI、small、largeの5つの異なるサイズがあり、速度と精度のトレードオフがあります。モデルの性能は、言語によっても異なります。以下の図は、large-v2モデルを使用したFleurのデータセットの言語によるWER(Word Error Rate)の分解を示しています。
ベクトルデータベース
ほとんどの機械学習アルゴリズムは、画像、音声、ビデオ、テキストなどの生の非構造化データを処理できません。これらのデータを多次元平面に表すベクトル埋め込みの行列に変換する必要があります。適切な意味をキャプチャする高度なディープラーニングモデルが必要です。これは、どのようなAIアプリにも非常に重要です。これらのデータを格納およびクエリするために、これらを効果的に処理できるデータベースが必要です。これにより、ベクトルデータベースと呼ばれる専用データベースが作成されました。複数のオープンソースデータベースがあります。Chroma、Milvus、Weaviate、FAISSなどが最も人気のあるものの一部です。
また、ベクトルストアのもう一つの特徴は、非構造化データに対して高速な検索操作を実行できることです。埋め込みを取得したら、クラスタリング、検索、ソート、および分類に使用できます。データポイントがベクトル空間にあるため、それらの間の距離を計算して、どの程度関連しているかを知ることができます。Cosine Similarity、Euclidean Distance、KNN、およびANN(Approximate Nearest Neighbour)などの多数のアルゴリズムが、類似したデータポイントを見つけるために使用されます。
私たちは、オープンソースのベクトルデータベースであるChroma vector storeを使用します。ChromaはLangchain統合も持っており、非常に役立ちます。
Gradio
アプリの4番目の要素であるGradioは、機械学習モデルを簡単に共有するためのオープンソースライブラリです。Pythonでそのコンポーネントとイベントを使用してデモWebアプリを構築するのにも役立ちます。
GradioとLangchainに馴染みがない場合は、次の記事を読んでから進んでください。
- Gradioを使ってChatGPTを構築しましょう
- PDF用のChatGPTを構築する
さあ、それを構築しましょう。
開発環境のセットアップ
開発環境をセットアップするには、Pythonの仮想環境を作成するか、Dockerでローカルな開発環境を作成してください。
これらの依存関係をすべてインストールしてください。
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314ライブラリのインポート
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, ListWebインターフェースの作成
フロントエンドを構築するために、Gradio Blockとコンポーネントを使用します。以下に、インターフェースを作成する方法を示します。必要に応じてカスタマイズしてください。
with gr.Blocks() as demo:
with gr.Row():
# with gr.Group():
with gr.Column(scale=0.70):
api_key = gr.Textbox(placeholder='OpenAI APIキーを入力してください',
show_label=False, interactive=True).style(container=False)
with gr.Column(scale=0.15):
change_api_key = gr.Button('キーを変更')
with gr.Column(scale=0.15):
remove_key = gr.Button('キーを削除')
with gr.Row():
with gr.Column():
chatbot = gr.Chatbot(value=[]).style(height=650)
query = gr.Textbox(placeholder='ここにクエリを入力',
show_label=False).style(container=False)
with gr.Column():
video = gr.Video(interactive=True,)
start_video = gr.Button('転写を開始')
gr.HTML('または')
yt_link = gr.Textbox(placeholder='YouTubeのリンクを貼り付けてください',
show_label=False).style(container=False)
yt_video = gr.HTML(label=True)
start_ytvideo = gr.Button('転写を開始')
gr.HTML('アプリの使用が終わったら、リソースを削除するためにアプリをリセットしてください。')
reset = gr.Button('アプリをリセット')
if __name__ == "__main__":
demo.launch() インターフェースは以下のように表示されます。
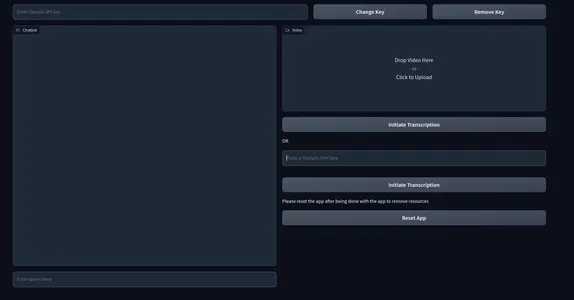
ここでは、OpenAIキーを入力するテキストボックスがあります。APIキーを変更するための2つのキーとキーを削除するためのボックスもあります。左側にはチャットUIがあり、右側にはローカル動画をレンダリングするボックスがあります。ビデオボックスの直下には、YouTubeリンクを要求するボックスと、「転写を開始」というボタンがあります。
Gradioイベント
今度はアプリをインタラクティブにするためのイベントを定義します。以下のコードをgr.Blocks()の最後に追加してください。
start_video.click(fn=lambda :(pause, update_yt),
outputs=[start2, yt_video]).then(
fn=embed_video, inputs=
,
outputs=
).success(
fn=lambda:resume,
outputs=[start2])
start_ytvideo.click(fn=lambda :(pause, update_video),
outputs=[start1,video]).then(
fn=embed_yt, inputs=[yt_link],
outputs = [yt_video, chatbot]).success(
fn=lambda:resume, outputs=[start1])
query.submit(fn=add_text, inputs=[chatbot, query],
outputs=[chatbot]).success(
fn=QuestionAnswer,
inputs=[chatbot,query,yt_link,video],
outputs=[chatbot,query])
api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key)
remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- start_video: クリックすると、ビデオからテキストを取得し、会話チェーンを作成します。
- start_ytvideo: クリックすると、YouTubeビデオから同じことを行い、完了したらそのすぐ下にYouTubeビデオをレンダリングします。
- query: LLMからチャットUIへのストリーミング応答を担当します。
残りのイベントは、APIキーの処理とアプリのリセットを処理するためのものです。
イベントは定義しましたが、イベントをトリガーする責任を持つ関数を定義していません。
バックエンド
複雑にして混乱することを避けるために、バックエンドで扱うプロセスをアウトライン化します。
- APIキーの処理。
- アップロードされたビデオの処理。
- ビデオを転写してテキストを取得する。
- ビデオテキストからチャンクを作成する。
- テキストから埋め込みを作成する。
- ベクトル埋め込みをChromaDBベクトルストアに格納する。
- Langchainを使用した会話検索チェーンを作成する。
- 関連するドキュメントをOpenAIチャットモデル(gpt-3.5-turbo)に送信する。
- 回答を取得してチャットUIにストリームします。
これらのことをいくつかの例外処理とともに行います。
いくつかの環境変数を定義します。
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0
enable_box = gr.Textbox.update(value=None,placeholder= 'OpenAI APIキーをアップロードしてください',
interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI APIキーが設定されました',
interactive=False)
remove_box = gr.Textbox.update(value = 'APIキーの削除に成功しました',
interactive=False)
pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None)
update_yt = gr.HTML.update(value=None) APIキーの処理
ユーザーがキーを送信すると、環境変数として設定され、テキストボックスをさらに入力できないようにします。キーの変更を押すと、再び変更可能になります。キーの削除をクリックすると、キーが削除されます。
enable_box = gr.Textbox.update(value=None,placeholder= 'OpenAI APIキーをアップロードしてください',
interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI APIキーが設定されました',interactive=False)
remove_box = gr.Textbox.update(value = 'APIキーの削除に成功しました',
interactive=False)
def set_apikey(api_key):
os.environ['OPENAI_API_KEY'] = api_key
return disable_box
def enable_api_box():
return enable_box
def remove_key_box():
os.environ['OPENAI_API_KEY'] = ''
return remove_boxビデオの処理
次に、アップロードされたビデオとYouTubeリンクを扱います。各場合に対して別々の関数を持つことになります。YouTubeリンクの場合、iframe埋め込みリンクが作成されます。各場合について、チェーンを作成する責任を持つ別の関数make_chain()を呼び出します。
これらの関数は、ビデオをアップロードしたり、YouTubeリンクを提供してトランスクライブボタンを押したりした場合にトリガーされます。
def embed_yt(yt_link: str):
# この関数はYouTubeビデオをページに埋め込みます。
# YouTubeリンクが有効かどうかを確認します。
if not yt_link:
raise gr.Error('YouTubeリンクを貼り付けてください')
# グローバル変数`run_once_flag`をFalseに設定します。
# これは、関数が1回以上呼び出されないようにするために使用されます。
run_once_flag = False
# グローバル変数`call_to_load_video`を0に設定します。
# これは、関数が呼び出された回数を追跡するために使用されます。
call_to_load_video = 0
# YouTubeリンクを使用してチェーンを作成します。
make_chain(url=yt_link)
# YouTubeビデオのURLを取得します。
url = yt_link.replace('watch?v=', '/embed/')
# 埋め込みYouTubeビデオのHTMLコードを作成します。
embed_html = f"""<iframe width="750" height="315" src="{url}"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write;
encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>"""
# HTMLコードと空のリストを返します。
return embed_html, []
def embed_video(video=str | None):
# この関数はビデオをページに埋め込みます。
# ビデオが有効かどうかを確認します。
if not video:
raise gr.Error('ビデオをアップロードしてください')
# グローバル変数`run_once_flag`をFalseに設定します。
# これは、関数が1回以上呼び出されないようにするために使用されます。
run_once_flag = False
# ビデオを使用してチェーンを作成します。
make_chain(video=video)
# ビデオと空のリストを返します。
return video, []チェーンの作成
これは全てのステップの中でも最も重要なステップの1つです。これには、ChromaベクトルストアとLangchainチェーンを作成することが含まれます。私たちは、Conversational retrieval chainを使用します。OpenAIの埋め込みを使用しますが、実際の展開では、Huggingface sentence encodersなどの無料の埋め込みモデルを使用してください。
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None):
global chain, run_once_flag
# YouTubeリンクまたはビデオが提供されているかどうかを確認する
if not url and not video:
raise gr.Error('YouTubeリンクまたはビデオを提供してください。')
if not run_once_flag:
run_once_flag = True
# YouTubeリンクまたはビデオからタイトルを取得する
title = get_title(url, video).replace(' ','-')
# ビデオからテキストを処理する
grouped_texts, time_list = process_text(url=url) if url else process_text(video=video)
# metadata形式にtime_listを変換する
time_list = [{'source': str(t.time())} for t in time_list]
# metadataを含む処理されたテキストからベクトルストアを作成する
vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test',
embedding=OpenAIEmbeddings(),
metadatas=time_list)
# ベクトルストアからConversationalRetrievalChainを作成する
chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0),
retriever=
vector_stores.as_retriever(
search_kwargs={"k": 5}),
return_source_documents=True)
return chain- YouTube URLまたはビデオファイルからテキストとメタデータを取得します。
- テキストとメタデータからChromaベクトルストアを作成します。
- OpenAI gpt-3.5-turboとChromaベクトルストアを使用してチェーンを構築します。
- チェーンを返します。
テキストの処理
このステップでは、ビデオからテキストを適切にスライスし、上記のチェーン構築プロセスで使用したメタデータオブジェクトを作成します。
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]:
global call_to_load_video
if call_to_load_video == 0:
print('yes')
# URLまたはビデオに基づいてprocess_video関数を呼び出す
result = process_video(url=url) if url else process_video(video=video)
call_to_load_video += 1
texts, start_time_list = [], []
# 結果の各セグメントからテキストと開始時間を抽出する
for res in result['segments']:
start = res['start']
text = res['text']
start_time = dt.datetime.fromtimestamp(start)
start_time_formatted = start_time.strftime("%H:%M:%S")
texts.append(''.join(text))
start_time_list.append(start_time_formatted)
texts_with_timestamps = dict(zip(texts, start_time_list))
# タイムスタンプをdatetimeオブジェクトに変換する
formatted_texts = {
text: dt.datetime.strptime(str(timestamp), '%H:%M:%S')
for text, timestamp in texts_with_timestamps.items()
}
grouped_texts = []
current_group = ''
time_list = [list(formatted_texts.values())[0]]
previous_time = None
time_difference = dt.timedelta(seconds=30)
# 時間差に基づいてテキストをグループ化する
for text, timestamp in formatted_texts.items():
if previous_time is None or timestamp - previous_time <= time_difference:
current_group += text
else:
grouped_texts.append(current_group)
time_list.append(timestamp)
current_group = text
previous_time = time_list[-1]
# 最後のテキストグループを追加する
if current_group:
grouped_texts.append(current_group)
return grouped_texts, time_list- process_text関数は、URLまたはビデオパスを取ります。このビデオはprocess_video関数で転写され、最終的なテキストを取得します。
- その後、各文の開始時間(Whisperから)を取得し、30秒ごとにグループ化します。
- 最後に、グループ化されたテキストと各グループの開始時間を返します。
ビデオの処理
このステップでは、ビデオまたはオーディオファイルを転写してテキストを取得します。転写にはWhisperベースモデルを使用します。
def process_video(video=None, url=None) -> dict[str, str | list]:
if url:
file_dir = load_video(url)
else:
file_dir = video
print('Whisperベースモデルを使用してビデオを転写しています')
model = whisper.load_model("base")
result = model.transcribe(file_dir)
return resultYouTubeビデオについては、直接処理することができないため、別途処理する必要があります。Pytubeというライブラリを使用して、YouTubeビデオのオーディオまたはビデオをダウンロードします。以下は、その方法です。
def load_video(url: str) -> str:
# この関数はYouTubeビデオをダウンロードし、ダウンロードしたファイルのパスを返します。
# 指定されたURLのYouTubeオブジェクトを作成する。
yt = YouTube(url)
# ターゲットディレクトリを取得する。
target_dir = os.path.join('/tmp', 'Youtube')
# ターゲットディレクトリが存在しない場合は、作成する。
if not os.path.exists(target_dir):
os.mkdir(target_dir)
# ビデオのオーディオストリームを取得する。
stream = yt.streams.get_audio_only()
# オーディオストリームをターゲットディレクトリにダウンロードする。
print('----AUDIO FILEをダウンロードしています----')
stream.download(output_path=target_dir)
# ダウンロードしたファイルのパスを取得する。
path = target_dir + '/' + yt.title + '.mp4'
# ダウンロードしたファイルのパスを返す。
return path- 指定されたURLのYouTubeオブジェクトを作成する。
- 一時的なターゲットディレクトリパスを作成する。
- パスが存在するかどうかを確認し、存在しない場合はディレクトリを作成する。
- ファイルのオーディオをダウンロードする。
- ビデオのパスディレクトリを取得する。
これは、ビデオからテキストを取得してチェーンを作成するためのボトムアッププロセスでした。これで、チャットボットを設定するだけです。
チャットボットを設定する
今必要なのは、クエリとチャット履歴を送信して回答を取得するだけです。したがって、クエリが送信されたときにのみトリガーされる関数を定義します。
def add_text(history, text):
if not text:
raise gr.Error('テキストを入力してください')
history = history + [(text,'')]
return history
def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]:
# この関数は、モデルのチェーンを使用して質問に答えます。
# YouTubeリンクまたはローカルビデオファイルが提供されているかどうかを確認する。
if video and url:
# YouTubeリンクとローカルビデオファイルの両方が提供された場合は、エラーを発生させる。
raise gr.Error('ビデオまたはYouTubeリンクをアップロードしてください。両方は不可。')
elif not url and not video:
# 入力がない場合はエラーを発生させる。
raise gr.Error('YouTubeリンクを提供するか、ビデオをアップロードしてください。')
# ビデオの処理結果を取得する。
result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True)
# 質問と回答をチャット履歴に追加する。
chat_history += [(query, result["answer"])]
# 回答の各文字に対して、履歴の最後の要素に追加する。
for char in result['answer']:
history[-1][-1] += char
yield history, ''クエリとチャット履歴を提供して、会話の文脈を維持します。最後に、回答をチャットボットにストリーミングすることができます。そして、すべての値をリセットする機能を定義することを忘れないでください。
これで、アプリケーションを起動してビデオとチャットすることができます。
最終製品は、以下のようになります。
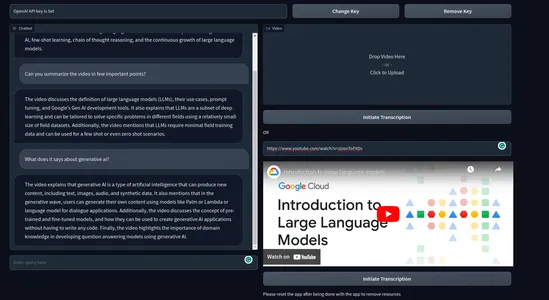
ビデオデモ:
実際の使用例
エンドユーザーがビデオやオーディオとチャットできるアプリケーションには、幅広い使用例があります。以下は、このチャットボットの実際の使用例のいくつかです。
- 教育:学生はしばしば数時間にわたるビデオ講義を受けます。このチャットボットは、学生が講義ビデオから学び、有用な情報を素早く抽出し、時間とエネルギーを節約するのに役立ちます。これにより、学習体験が大幅に向上します。
- 法律:法律のプロフェッショナルは、しばしば長時間の法的手続きや証言を通じて、事件を分析し、文書を準備し、調査するか、コンプライアンス監視を行います。このようなタスクを整理するために、このようなチャットボットが役立ちます。
- コンテンツ要約:このアプリは、ビデオコンテンツを分析して要約されたテキストバージョンを生成できます。これにより、ユーザーはビデオを完全に視聴せずにハイライトを把握できます。
- 顧客インタラクション:ブランドは、製品やサービスのビデオチャットボット機能を組み込むことができます。これは、高額な製品や説明が必要な製品やサービスを販売するビジネスに役立ちます。
- ビデオ翻訳:テキストコーパスを他の言語に翻訳することができます。これにより、異なる言語間のコミュニケーション、言語学習、または非ネイティブスピーカーのアクセシビリティが促進されます。
これらは私が考えられる潜在的な使用例の一部です。ビデオのためのチャットボットのさらに多くの有用なアプリケーションがあるかもしれません。
結論
これで、ビデオ用チャットボットの機能的なデモWebアプリを構築する方法について説明しました。本記事では、多くの概念について取り上げました。以下は、記事のキーポイントです。
- AIアプリケーションを簡単に作成するための人気のあるツールであるLangchainについて学びました。
- OpenAIによる強力な音声認識モデルであるWhisperについて学びました。音声やビデオをテキストに変換できるオープンソースモデルです。
- ベクトルデータベースによって、ベクトル埋め込みの効果的な格納とクエリが可能であることを学びました。
- Langchain、Chroma、およびOpenAIモデルを使用して、完全に機能するWebアプリをゼロから構築しました。
- チャットボットの潜在的な実用例についても議論しました。
以上がすべてです。お気に入りいただけたら嬉しいです。開発に関するその他の情報については、Twitterでのフォローをご検討ください。
GitHubリポジトリ:sunilkumardash9/chatgpt-for-videos。これが役に立った場合は、リポジトリに⭐を付けてください。
よくある質問
この記事で表示されるメディアはAnalytics Vidhyaに所属しておらず、著者の裁量によって使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






