ラマとChatGPTを使用してマルチチャットバックエンドのマイクロサービスを構築する
Using LAMA and ChatGPT to build a microservice for multi-chat backends.
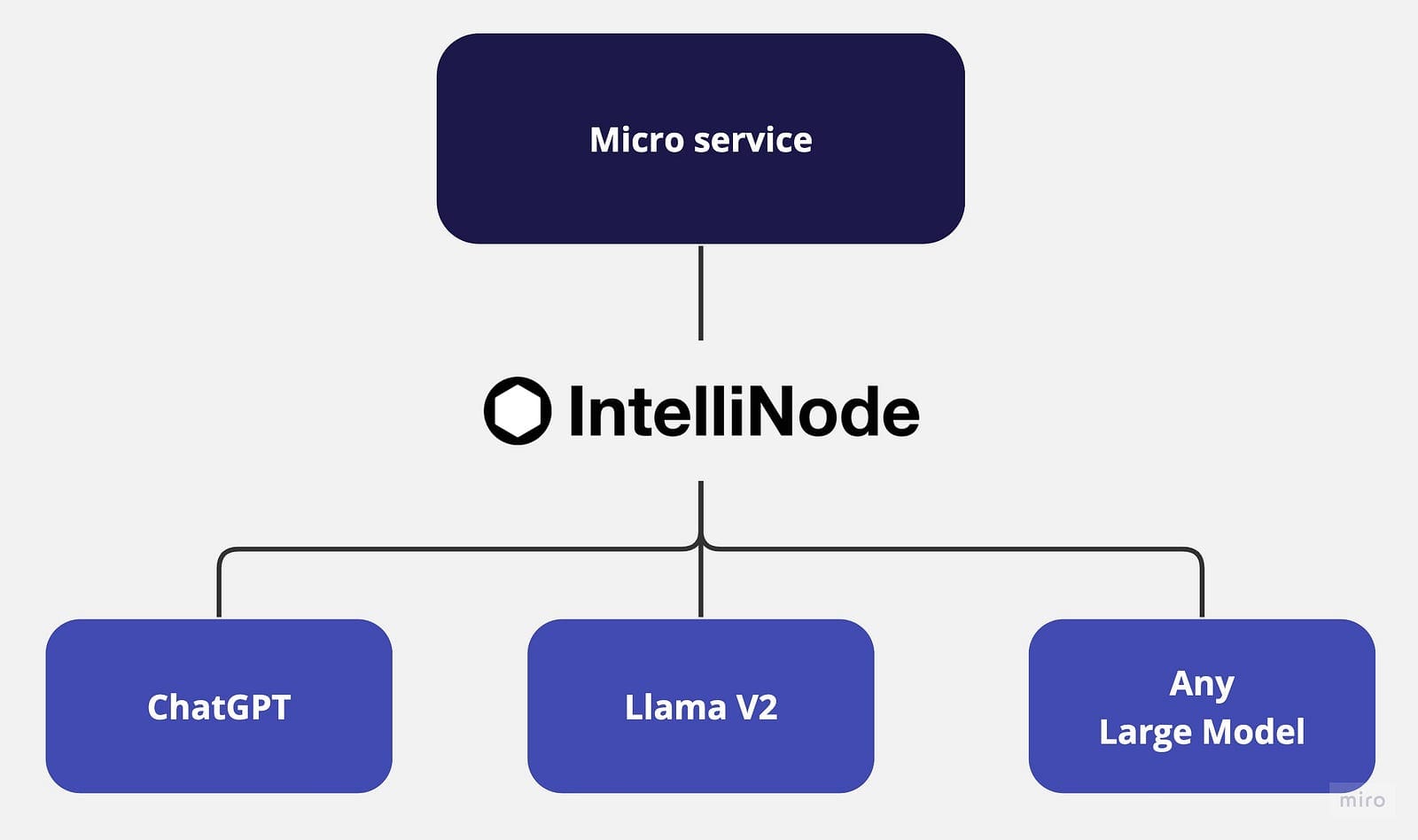
マイクロサービスアーキテクチャは、柔軟で独立したサービスを定義し、それぞれの境界を明確にします。このスケーラブルなアプローチにより、開発者はアプリケーション全体に影響を与えることなく、個々のサービスを維持および進化させることができます。ただし、特にAIパワードのチャットアプリケーションにおいて、メタラマV2やOpenAIのChatGPTなどの最新の大規模言語モデル(LLM)との強力な統合が必要です。さらに、各アプリケーションのユースケースに基づいて公開されたファインチューニングモデルを使用することで、多様なソリューションを提供するためのマルチモデルアプローチが可能となります。
LLMは、多様なデータでのトレーニングに基づいて、人間に似たテキストを生成する大規模モデルです。インターネット上の数十億の単語から学習することで、LLMはコンテキストを理解し、さまざまなドメインでチューニングされたコンテンツを生成します。ただし、さまざまなLLMを単一のアプリケーションに統合することは、各モデルに固有のインターフェース、アクセスエンドポイント、および特定のペイロードが必要となるため、しばしば課題を引き起こします。したがって、さまざまなモデルを処理できる単一の統合サービスを持つことは、アーキテクチャの設計を改善し、独立したサービスのスケールを向上させることになります。
このチュートリアルでは、Node.jsとExpressを使用したマイクロサービスアーキテクチャでのChatGPTとLLaMA V2のIntelliNode統合を紹介します。
- 「Anthropicは、AIチャットボットプラットフォームのClaudeの有料サブスクリプションを導入します」
- 「ジェネレーティブAIをマスターしたいなら、すべてを無視して(ただ2つだけを除いて)ツールに集中せよ」という文です
- 「お知らせ:フォーカスエンターテイメントがゲームパスのタイトルをGeForce NOWに提供します」
チャットボットの統合オプション
IntelliNodeが提供するいくつかのチャット統合オプションは次のとおりです:
- LLaMA V2: LLaMA V2モデルをReplicateのAPIを介して統合するか、AWS SageMakerホストを介して統合することができます。
LLaMA V2は、最大70Bのパラメータで事前にトレーニングおよびファインチューニングされた強力なオープンソースの大規模言語モデル(LLM)です。プログラミングや創造的な執筆など、さまざまなドメインでの複雑な推論タスクに優れています。そのトレーニング手法は、自己教師ありデータと人間のフィードバックを組み合わせた強化学習を通じた人間の好みとの一致に基づいています。LLaMA V2は既存のオープンソースモデルを上回り、ChatGPTやBARDなどのクローズドソースモデルとも利便性と安全性において比較可能です。
- ChatGPT: OpenAIのAPIキーを提供するだけで、IntelliNodeモジュールを使用してモデルとシンプルなチャットインタフェースを統合することができます。GPT 3.5またはGPT 4モデルを介してChatGPTにアクセスできます。これらのモデルは大量のデータでトレーニングされ、高度にコンテキストに沿った正確な応答を提供するようにファインチューニングされています。
ステップバイステップの統合
まず、新しいNode.jsプロジェクトを初期化しましょう。ターミナルを開き、プロジェクトのディレクトリに移動し、次のコマンドを実行します:
npm init -y
このコマンドにより、アプリケーションのための新しい`package.json`ファイルが作成されます。
次に、HTTPリクエストとレスポンスを処理するために使用されるExpress.jsと、LLMモデルの接続に使用されるintellinodeをインストールします:
npm install express
npm install intellinode
インストールが完了したら、プロジェクトのルートディレクトリに`app.js`という新しいファイルを作成します。次に、`app.js`にExpressの初期化コードを追加します。
著者によるコード
ReplicateのAPIを使用したLlama V2の統合
Replicateは、APIキーを介してLlama V2との迅速な統合パスを提供し、IntelliNodeはチャットボットインタフェースを提供することで、ビジネスロジックをReplicateのバックエンドから切り離し、異なるチャットモデル間を切り替えることができます。
まず、ReplicaのバックエンドにホストされているLlamaとの統合を開始しましょう:
著者によるコード
統合を有効にするために、replicate.comからトライアルキーを取得してください。
AWS SageMakerを使用したLlama V2の統合
次に、AWS SageMakerを介したLlama V2の統合について説明します。これにより、プライバシーと追加の制御が提供されます。
統合には、まずAWSアカウントからAPIエンドポイントを生成する必要があります。まずは、マイクロサービスアプリに統合コードをセットアップしましょう:
著者:コード
以下の手順は、アカウントにLlamaエンドポイントを作成するためのものです。APIゲートウェイを設定した後、’ /llama/aws ‘サービスを実行するために使用するURLをコピーします。
AWSアカウントにLlama V2エンドポイントをセットアップするには:
1- SageMakerサービス: AWSアカウントからSageMakerサービスを選択し、ドメインをクリックします。

2- SageMakerドメインの作成:AWS SageMakerで新しいドメインを作成します。このステップは、SageMakerの操作のための制御されたスペースを確立します。
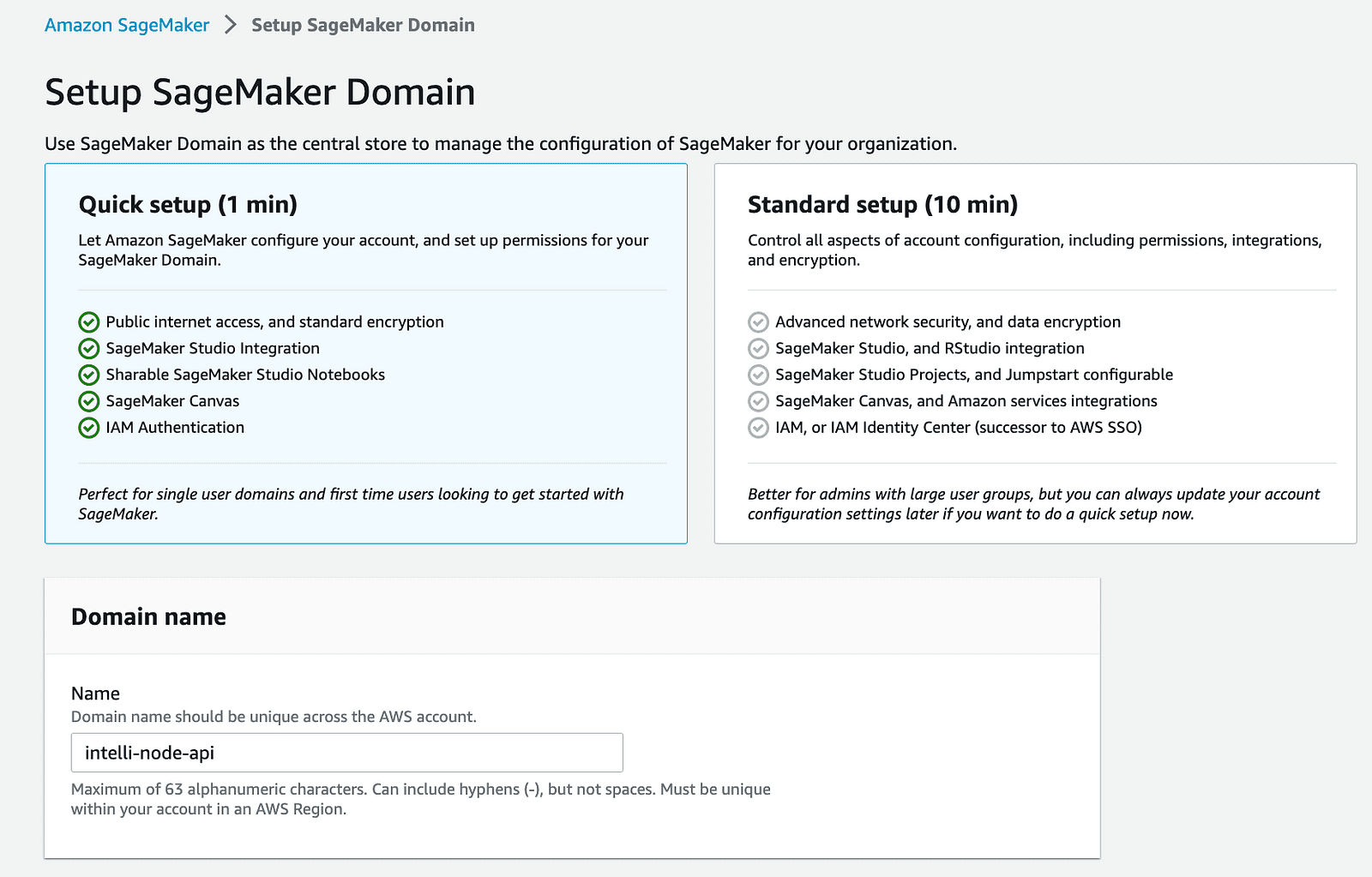
3- Llamaモデルのデプロイ:SageMaker JumpStartを利用して統合するLlamaモデルをデプロイします。70Bモデルの実行には月額コストが高いため、2Bモデルから始めることをお勧めします。
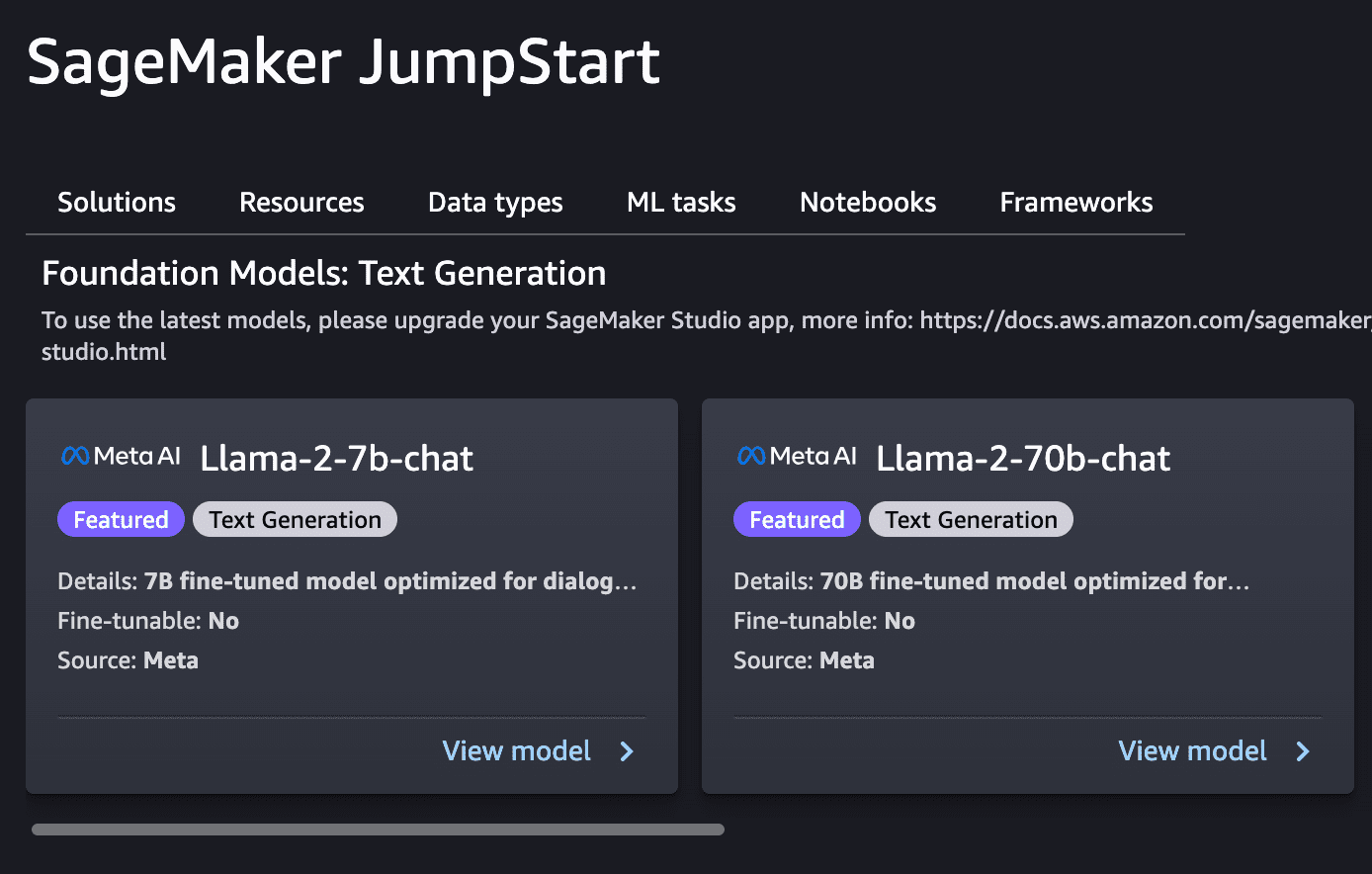
4- エンドポイント名のコピー:モデルをデプロイしたら、将来の手順に不可欠なエンドポイント名を必ずメモしておいてください。
5- Lambda関数の作成:AWS Lambdaを使用してバックエンドのコードをサーバー管理せずに実行できます。デプロイされたモデルを統合するためにNode.jsのLambda関数を作成します。
6- 環境変数の設定:Lambda内でllama_endpointという名前の環境変数を作成し、その値にSageMakerのエンドポイントを設定します。
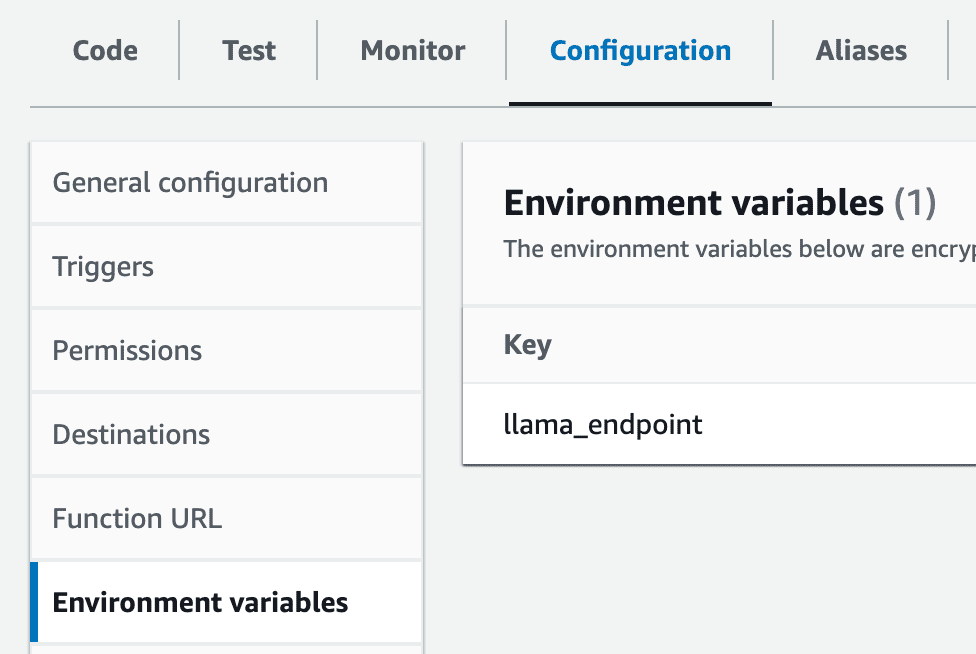
7- Intellinode Lambdaのインポート:SageMaker Llamaデプロイメントへの接続を確立する準備が整ったLambdaのzipファイルをインポートする必要があります。このエクスポートはzipファイルであり、lambda_llama_sagemakerディレクトリ内にあります。
8- API Gatewayの設定:Lambda関数ページで「トリガーの追加」オプションをクリックし、利用可能なトリガーのリストから「API Gateway」を選択します。
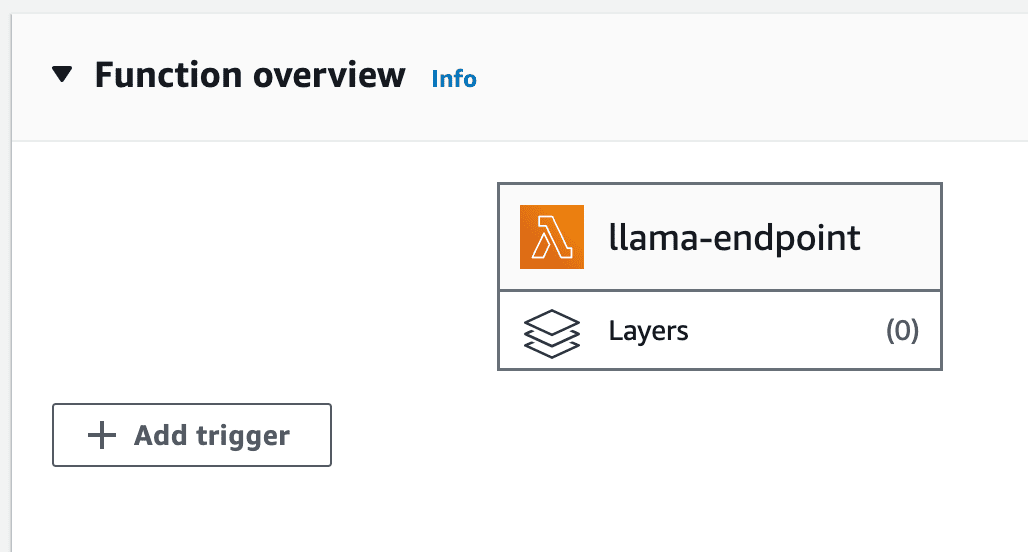 awsアカウント-lambdaトリガー
awsアカウント-lambdaトリガー
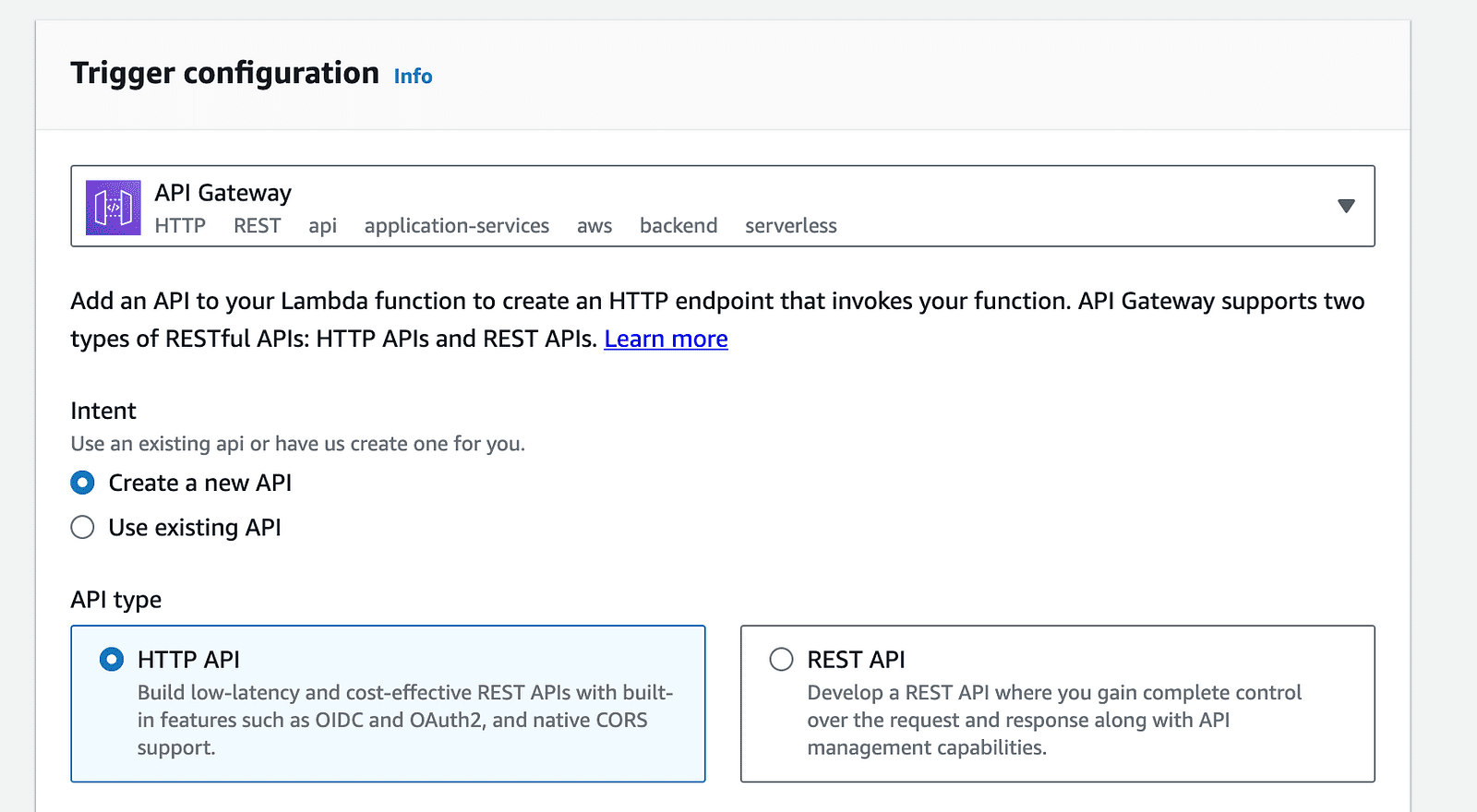 awsアカウント-API Gatewayトリガー
awsアカウント-API Gatewayトリガー
9- Lambda関数の設定:Lambdaのロールを更新して、SageMakerエンドポイントにアクセスするために必要な権限を付与します。また、関数のタイムアウト期間を処理時間に合わせて延長する必要があります。これらの調整はLambda関数の「設定」タブで行います。
役割名をクリックして権限を更新し、SageMakerへのアクセス権限を提供します:
 awsアカウント-lambdaロール
awsアカウント-lambdaロール
ChatGPTの統合
最後に、マイクロサービスアーキテクチャにおける別のオプションとしてOpenai ChatGPTを統合する手順を示します:
著者:コード
platform.openai.comからトライアルキーを取得してください。
実行実験
まず、ターミナルでAPIキーをエクスポートします:
著者:コード
次に、nodeアプリを実行します:
node app.js
ブラウザで以下のURLを入力して、chatGPTサービスをテストします:
http://localhost:3000/chatgpt?message=hello
Llama V2やOpenAIのChatGPTなどの大規模言語モデルの能力を活用したマイクロサービスを構築しました。この統合により、高度なAIによって可能となる無限のビジネスシナリオを活用することができます。
機械学習の要件を切り離されたマイクロサービスに変換することで、アプリケーションは柔軟性とスケーラビリティの利点を得ることができます。モノリシックなモデルの制約に合わせて操作を構成する代わりに、言語モデルの機能は個別に管理および開発することができます。これにより、より効率的なトラブルシューティングやアップグレード管理が約束されます。
参考文献
- ChatGPT API: リンク
- Replica API: リンク
- SageMaker Llama Jump Start: リンク
- IntelliNode Get Started: リンク
- フルコードのGitHubリポジトリ: リンク
Ahmad Albarqawiは、イリノイ大学アーバナ・シャンペーン校のエンジニアであり、データサイエンスの修士です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






