「PythonでCuPyを使ってGPUのパワーを最大限に活用する」
「PythonとCuPyを組み合わせ、GPUパワーを最大限に活用する方法」

CuPyとは?
CuPyは、NumPyやSciPyの配列と互換性のあるPythonライブラリで、GPUアクセラレーションを目的として設計されています。CuPyの構文でNumPyを置き換えることにより、NVIDIA CUDAやAMD ROCmプラットフォーム上でコードを実行することができます。これにより、GPUアクセラレーションを使用して配列関連のタスクを高速に処理することができます。
数行のコードの変更だけで、インデックス付け、正規化、行列乗算などの配列操作を大幅に高速化するために、GPUの大規模並列処理能力を活用することができます。
CuPyはまた、低レベルのCUDA機能へのアクセスを可能にします。RawKernelsを使用して既存のCUDA C/C++プログラムにndarraysを渡したり、Streamsでパフォーマンスを最適化したり、CUDA Runtime APIを直接呼び出したりすることができます。
CuPyのインストール
CuPyはpipを使用してインストールすることができますが、それより前に、以下のコマンドを使用して正しいCUDAバージョンを調べる必要があります。
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
現在のGoogle ColabのバージョンはCUDAバージョン11.8を使用しているようです。したがって、cupy-cuda11xバージョンをインストールすることにします。
古いCUDAバージョンで実行している場合は、以下の表を参考にして適切なCuPyパッケージをインストールできます。
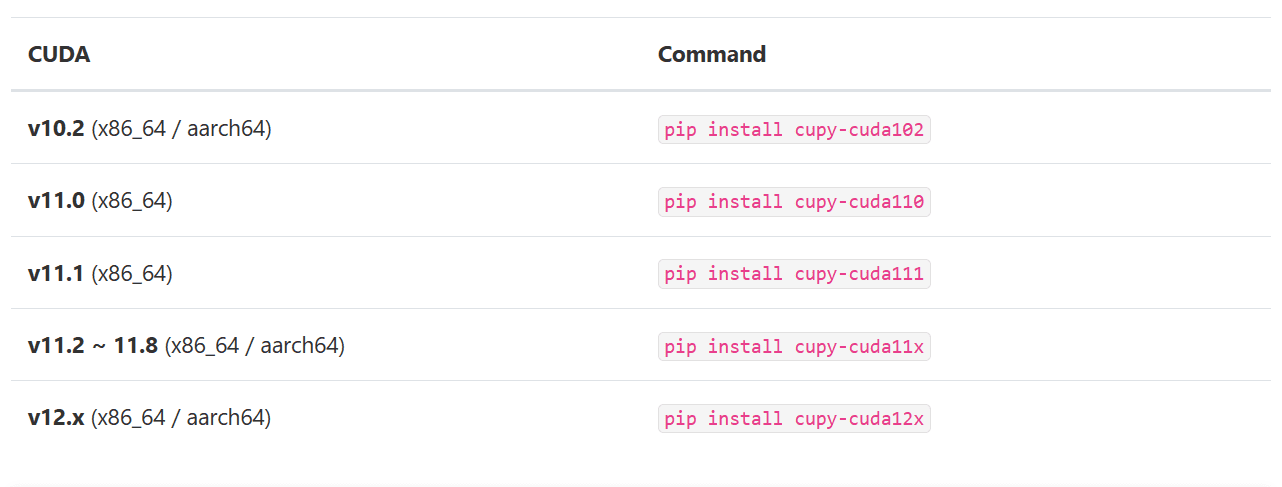
適切なバージョンを選んだら、pipを使用してPythonパッケージをインストールします。
pip install cupy-cuda11x
Anacondaがインストールされている場合は、condaコマンドを使用して正しいバージョンのCuPyパッケージを自動的に検出およびインストールすることもできます。
conda install -c conda-forge cupy
CuPyの基礎
このセクションでは、CuPyの構文をNumPyと比較し、95%類似していることを説明します。使用するのはnpではなく、cpです。
まず、Pythonリストを使用してNumPyとCuPyの配列を作成します。その後、ベクトルのノルムを計算します。
import cupy as cp
import numpy as np
x = [3, 4, 5]
x_np = np.array(x)
x_cp = cp.array(x)
l2_np = np.linalg.norm(x_np)
l2_cp = cp.linalg.norm(x_cp)
print("Numpy: ", l2_np)
print("Cupy: ", l2_cp)
<p結果を見ると、同様の結果が得られました。
Numpy: 7.0710678118654755
Cupy: 7.0710678118654755
NumPyをCuPy配列に変換するには、単にcp.asarray(X)を使用します。
x_array = np.array([10, 22, 30])
x_cp_array = cp.asarray(x_array)
type(x_cp_array)
cupy.ndarray
または、CuPyをNumPy配列に変換するには.get()を使用します。
x_np_array = x_cp_array.get()
type(x_np_array)
numpy.ndarray
パフォーマンス比較
このセクションでは、NumPyとCuPyのパフォーマンスを比較します。
コードの実行時間を測定するためにtime.time()を使用します。その後、3DのNumPy配列を作成し、いくつかの数学的な関数を実行します。
import time# NumPyとCPUのランタイム = time.time()x_cpu = np.ones((1000, 100, 1000))np_result = np.sqrt(np.sum(x_cpu**2, axis=-1))e = time.time()np_time = e - sprint("NumPyの処理時間:", np_time)
NumPyの処理時間:0.5474584102630615
同様に、3DのCuPy配列を作成し、数学的な演算を行い、パフォーマンスのために時間を計測します。
# CuPyとGPUのランタイム = time.time()x_gpu = cp.ones((1000, 100, 1000))cp_result = cp.sqrt(cp.sum(x_gpu**2, axis=-1))e = time.time()cp_time = e - sprint("\nCuPyの処理時間:", cp_time)
CuPyの処理時間:0.001028299331665039
差を計算するために、NumPyの時間をCuPyの時間で割ります。CuPyを使用すると、500倍以上のパフォーマンス向上が得られたようです。
diff = np_time/cp_timeprint(f'\nCuPyはNumPyよりも{diff: .2f}倍高速です。')
CuPyはNumPyよりも532.39倍高速です。
注意:より良い結果を得るために、タイミングの変動を最小限に抑えるために、いくつかのウォームアップランを実行することが推奨されます。
速度の利点に加えて、CuPyは優れたマルチGPUサポートを提供し、複数のGPUの集合パワーを活用することができます。
また、結果を比較したい場合は、Colabのノートブックをチェックすることもできます。
結論
CuPyは、NumPyのコードをNVIDIAのGPUで高速化するための簡単な方法を提供しています。NumPyをCuPyに入れ替えるだけで、配列計算で桁違いの高速化を体験することができます。このパフォーマンス向上により、より大きなデータセットとモデルで作業し、より高度な機械学習や科学計算を行うことが可能になります。
リソース
- ドキュメント: CuPy – NumPy & SciPy for GPU — CuPy 12.2.0 documentation
- GitHub: cupy/cupy
- 例: cupy/examples
- API: APIリファレンス
****[Abid Ali Awan](https://www.polywork.com/kingabzpro)****(@1abidaliawan)は、機械学習モデルの構築が大好きな認定データサイエンティストのプロフェッショナルです。現在、彼はコンテンツの作成と機械学習やデータサイエンス技術に関する技術ブログの執筆に注力しています。Abidはテクノロジー管理の修士号と通信工学の学士号を保持しています。彼のビジョンは、メンタルヘルスの問題に悩む学生のためにグラフニューラルネットワークを使用したAI製品を構築することです。
</p結果を見ると、同様の結果が得られました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






