「GPUを使用してAmazon SageMakerのマルチモデルエンドポイントで数千のモデルアンサンブルを展開し、ホスティングコストを最小限に抑えます」
Using GPUs on Amazon SageMaker's multi-model endpoint, deploy thousands of model ensembles and minimize hosting costs.
人工知能(AI)の採用は、さまざまな産業とユースケースで加速しています。深層学習(DL)、大規模言語モデル(LLM)、生成型AIの最近の科学的なブレイクスルーにより、顧客はほぼ人間のような性能を持つ高度な最新のソリューションを利用することができるようになりました。これらの複雑なモデルは、リアルタイムアプリケーションで深層ニューラルネットワークを使用する際に、高速なトレーニングだけでなく、高速な推論も可能にするため、ハードウェアのアクセラレーションを必要とします。GPUの大量の並列処理コアは、これらのDLタスクに適しています。
ただし、モデルの呼び出しに加えて、これらのDLアプリケーションでは、推論パイプラインでの前処理や後処理も必要となります。たとえば、オブジェクト検出のユースケースでは、コンピュータビジョンモデルに提供する前に、入力画像をリサイズしたりトリミングしたりする必要がある場合があります。また、LLMで使用する前にテキスト入力をトークン化する必要がある場合もあります。NVIDIA Tritonは、ユーザーがこのような推論パイプラインを有向非巡回グラフ(DAG)の形式でモデルのアンサンブルとして定義できるオープンソースの推論サーバーです。CPUとGPUの両方でモデルをスケールアップして実行するように設計されています。Amazon SageMakerは、Tritonのシームレスなデプロイをサポートしており、Tritonの機能を利用しながら、SageMakerの機能も活用できます。それには、MLOpsツールの統合、ホストされたモデルの自動スケーリングなど、管理された安全な環境が含まれます。
AWSは、お客様が最高の節約を実現するために、価格オプションや費用最適化の積極的なサービスだけでなく、マルチモデルエンドポイント(MME)などのコスト削減機能を提供することに取り組んでいます。MMEは、同じリソースフリートと共有のサービングコンテナを使用して大量のモデルを展開するための費用対効果の高いソリューションです。複数の単一モデルエンドポイントを使用する代わりに、単一の推論環境のみで複数のモデルを展開することで、ホスティングコストを削減することができます。さらに、MMEはエンドポイントへのトラフィックパターンに基づいてモデルをメモリにロードし、スケーリングするため、展開のオーバーヘッドも削減されます。
この投稿では、SageMaker MMEを使用してGPUインスタンスで複数の深層学習アンサンブルモデルを実行する方法を示します。この例に従うには、公開されたSageMakerのサンプルリポジトリでコードを見つけることができます。
SageMaker MMEとGPUの動作方法
MMEでは、単一のコンテナに複数のモデルがホストされます。SageMakerは、MMEにホストされたモデルのライフサイクルを制御し、モデルをコンテナのメモリにロードおよびアンロードします。エンドポイントインスタンスにすべてのモデルをダウンロードする代わりに、SageMakerはモデルを呼び出されるたびに動的にロードしてキャッシュします。
特定のモデルの呼び出しリクエストが行われると、SageMakerは次のような処理を行います:
- まず、リクエストをエンドポイントインスタンスにルーティングします。
- モデルがロードされていない場合、モデルアーティファクトをAmazon Simple Storage Service(Amazon S3)からインスタンスのAmazon Elastic Block Storageボリューム(Amazon EBS)にダウンロードします。
- モデルをGPUアクセラレートされたコンテナのメモリにロードします。モデルが既にコンテナのメモリにロードされている場合、呼び出しはより高速になります。
さらにモデルをロードする必要があり、インスタンスのメモリ使用率が高い場合、SageMakerはそのインスタンスのコンテナから未使用のモデルをアンロードしてメモリを確保します。これらのアンロードされたモデルは、S3バケットから再度ダウンロードする必要がないため、インスタンスのEBSボリュームに保持されます。ただし、インスタンスのストレージボリュームが容量に達した場合、SageMakerはストレージボリュームから未使用のモデルを削除します。MMEが多くの呼び出しリクエストを受け取り、別のインスタンス(または自動スケーリングポリシー)が存在する場合、SageMakerは高トラフィックに対応するために推論クラスター内の他のインスタンスに一部のリクエストをルーティングします。
これにより、コストの節約だけでなく、新しいモデルを動的に展開し、古いモデルを廃止することも可能になります。新しいモデルを追加するには、MMEが構成されているS3バケットにアップロードし、呼び出します。モデルを削除するには、リクエストを送信を停止し、S3バケットから削除します。MMEからモデルを追加または削除する場合、エンドポイント自体を更新する必要はありません!
Tritonのアンサンブル
Tritonモデルアンサンブルは、1つのモデル、前処理および後処理ロジック、およびそれらの間の入力および出力テンソルの接続から構成されるパイプラインを表します。アンサンブルへの単一の推論リクエストは、アンサンブルスケジューラを使用してステップのシリーズとしてパイプライン全体の実行をトリガーします。スケジューラは各ステップの出力テンソルを収集し、仕様に従って他のステップの入力テンソルとして提供します。外部からの観点では、アンサンブルモデルはまだ単一のモデルとして表示されます。
Tritonサーバーアーキテクチャには、モデルリポジトリが含まれています。これは、Tritonが推論に使用するモデルのファイルシステムベースのリポジトリです。Tritonは、1つ以上のローカルにアクセス可能なファイルパスまたはAmazon S3のようなリモート場所からモデルにアクセスすることができます。
モデルリポジトリの各モデルには、モデルに関する必須およびオプションの情報を提供するモデル構成が含まれている必要があります。通常、この構成は、ModelConfigプロトコルバッファとして指定されたconfig.pbtxtファイルで提供されます。最小限のモデル構成では、プラットフォームまたはバックエンド(PyTorchやTensorFlowなど)とmax_batch_sizeプロパティ、およびモデルの入力と出力テンソルを指定する必要があります。
SageMaker上のTriton
SageMakerを使用してTritonサーバーをカスタムコードと共にモデル展開することができます。この機能は、SageMaker管理されたTriton推論サーバーコンテナを介して利用できます。これらのコンテナは一般的な機械学習(ML)フレームワーク(TensorFlow、ONNX、PyTorchなど)およびSageMakerでパフォーマンスを最適化するための便利な環境変数をサポートしています。SageMaker Deep Learning Containers(DLC)のイメージの使用をお勧めします。これらのイメージは、セキュリティパッチが定期的に適用され、メンテナンスされています。
ソリューションの概要
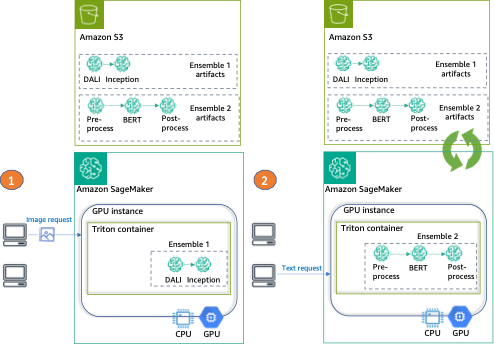
この投稿では、Tritonと単一のSageMakerエンドポイントを使用して、2つの異なるタイプのアンサンブルをGPUインスタンス上に展開します。
最初のアンサンブルは、画像の前処理にDALIモデルを使用し、実際の推論にはTensorFlow Inception v3モデルを使用します。パイプラインアンサンブルは、エンコードされた画像を入力として受け取り、デコード、299×299の解像度にリサイズ、および正規化する必要があります。この前処理はDALIモデルによって処理されます。DALIは、デコードやデータ拡張などの一般的な画像および音声の前処理タスクのためのオープンソースライブラリです。Inception v3は、対称および非対称畳み込み、平均および最大プーリング完全接続層から構成される画像認識モデルであり、GPU使用に最適です。
2番目のアンサンブルは、生の自然言語の文を埋め込みに変換するためのもので、3つのモデルで構成されています。まず、入力テキストのトークン化には前処理モデルが適用されます(Pythonで実装)。次に、Hugging Face Model Hubから事前学習されたBERT(uncased)モデルを使用してトークンの埋め込みを抽出します。BERTは、マスク言語モデリング(MLM)目的でトレーニングされた英語モデルです。最後に、前のステップからの生のトークン埋め込みを文の埋め込みに結合するための後処理モデルを適用します。
これらのアンサンブルをTritonで構成した後、SageMaker MMEの設定と実行方法を示します。
最後に、次の図に示すように、各アンサンブル呼び出しの例を提供します:
- アンサンブル1 – 画像を指定してエンドポイントを呼び出し、DALI-Inceptionをターゲットアンサンブルとして指定します
- アンサンブル2 – テキスト入力で同じエンドポイントを呼び出し、前処理-BERT-後処理アンサンブルを要求します
環境の設定
まず、必要な環境を設定します。これには、AWSライブラリ(Boto3やSageMaker SDKなど)の更新、アンサンブルをパッケージ化し、Tritonを使用して推論を実行するために必要な依存関係のインストール、およびSageMaker SDKのデフォルトの実行ロールの使用が含まれます。このロールは、SageMakerがAmazon S3(モデルアーティファクトの保存先)およびコンテナレジストリ(NVIDIA Tritonイメージの使用先)にアクセスできるようにするために使用されます。次のコードを参照してください:
import boto3, json, sagemaker, time
from sagemaker import get_execution_role
import nvidia.dali as dali
import nvidia.dali.types as types
# SageMaker variables
sm_client = boto3.client(service_name="sagemaker")
runtime_sm_client = boto3.client("sagemaker-runtime")
sagemaker_session = sagemaker.Session(boto_session=boto3.Session())
role = get_execution_role()
# Other Variables
instance_type = "ml.g4dn.4xlarge"
sm_model_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_config_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())アンサンブルの準備
次のステップでは、2つのアンサンブルを準備します。TensorFlow(TF)のInceptionとDALI前処理、Python前処理と後処理を使用したBERTです。
これには、事前学習済みモデルのダウンロード、Tritonの設定ファイルの提供、展開前にAmazon S3に保存するためのアーティファクトのパッケージ化が含まれます。
TFとDALIのアンサンブルの準備
まず、モデルと構成を保存するディレクトリを準備します。TF Inception(inception_graphdef)、DALI前処理(dali)、およびアンサンブル(ensemble_dali_inception)のためのディレクトリです。Tritonはモデルのバージョニングをサポートしているため、ディレクトリパスにモデルのバージョンも追加します(1つのバージョンしかないため、1と表記されています)。Tritonのバージョンポリシーについては、バージョンポリシーを参照してください。次に、Inception v3モデルをダウンロードし、展開してinception_graphdefモデルディレクトリにコピーします。以下のコードを参照してください。
!mkdir -p model_repository/inception_graphdef/1
!mkdir -p model_repository/dali/1
!mkdir -p model_repository/ensemble_dali_inception/1
!wget -O /tmp/inception_v3_2016_08_28_frozen.pb.tar.gz \
https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz
!(cd /tmp && tar xzf inception_v3_2016_08_28_frozen.pb.tar.gz)
!mv /tmp/inception_v3_2016_08_28_frozen.pb model_repository/inception_graphdef/1/model.graphdef次に、Tritonを使用してアンサンブルパイプラインを設定します。 config.pbtxtファイルで、入力と出力のテンソルの形状と型、およびTritonスケジューラが実行する手順(DALI前処理と画像分類のためのInceptionモデル)を指定します。
%%writefile model_repository/ensemble_dali_inception/config.pbtxt
name: "ensemble_dali_inception"
platform: "ensemble"
max_batch_size: 256
input [
{
name: "INPUT"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1001 ]
}
]
ensemble_scheduling {
step [
{
model_name: "dali"
model_version: -1
input_map {
key: "DALI_INPUT_0"
value: "INPUT"
}
output_map {
key: "DALI_OUTPUT_0"
value: "preprocessed_image"
}
},
{
model_name: "inception_graphdef"
model_version: -1
input_map {
key: "input"
value: "preprocessed_image"
}
output_map {
key: "InceptionV3/Predictions/Softmax"
value: "OUTPUT"
}
}
]
}次に、各モデルを設定します。まず、DALIバックエンドのモデル構成です。
%%writefile model_repository/dali/config.pbtxt
name: "dali"
backend: "dali"
max_batch_size: 256
input [
{
name: "DALI_INPUT_0"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "DALI_OUTPUT_0"
data_type: TYPE_FP32
dims: [ 299, 299, 3 ]
}
]
parameters: [
{
key: "num_threads"
value: { string_value: "12" }
}
]次に、前にダウンロードしたTensorFlow Inception v3のモデル構成です。
%%writefile model_repository/inception_graphdef/config.pbtxt
name: "inception_graphdef"
platform: "tensorflow_graphdef"
max_batch_size: 256
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NHWC
dims: [ 299, 299, 3 ]
}
]
output [
{
name: "InceptionV3/Predictions/Softmax"
data_type: TYPE_FP32
dims: [ 1001 ]
label_filename: "inception_labels.txt"
}
]
instance_group [
{
kind: KIND_GPU
}
]これは分類モデルなので、Inceptionモデルのラベルもモデルリポジトリのinception_graphdefディレクトリにコピーする必要があります。これらのラベルには、ImageNetデータセットからの1,000のクラスラベルが含まれています。
!aws s3 cp s3://sagemaker-sample-files/datasets/labels/inception_labels.txt model_repository/inception_graphdef/inception_labels.txt次に、前処理を処理するDALIパイプラインを構成してシリアライズします。前処理には、画像の読み取り(CPUを使用)、デコード(GPUを使用して高速化)、および画像のリサイズと正規化が含まれます。
@dali.pipeline_def(batch_size=3, num_threads=1, device_id=0)
def pipe():
"""画像とマスクを読み取り、画像をデコードして返すパイプラインを作成します。"""
images = dali.fn.external_source(device="cpu", name="DALI_INPUT_0")
images = dali.fn.decoders.image(images, device="mixed", output_type=types.RGB)
images = dali.fn.resize(images, resize_x=299, resize_y=299) #デフォルトの299x299サイズに画像をリサイズ
images = dali.fn.crop_mirror_normalize(
images,
dtype=types.FLOAT,
output_layout="HWC",
crop=(299, 299), #デフォルトの299x299サイズに画像をクロップ
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], #画像の中央領域をクロップ
std=[0.229 * 255, 0.224 * 255, 0.225 * 255], #画像の中央領域をクロップ
)
return images
pipe().serialize(filename="model_repository/dali/1/model.dali")最後に、アーティファクトを一緒にパッケージ化し、Amazon S3に単一のオブジェクトとしてアップロードします:
!tar -cvzf model_tf_dali.tar.gz -C model_repository .
model_uri = sagemaker_session.upload_data(
path="model_tf_dali.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("S3モデルURI:{}".format(model_uri))TensorRTとPythonアンサンブルの準備
この例では、transformersライブラリから事前学習済みモデルを使用します。
すべてのモデル(前処理と後処理、およびconfig.pbtxtファイル)はensemble_hfフォルダにあります。ファイルシステムの構造には、4つのディレクトリ(各モデルステップ用の3つとアンサンブル用の1つ)とそれぞれのバージョンが含まれます:
ensemble_hf
├── bert-trt
| |── model.pt
| |──config.pbtxt
├── ensemble
│ └── 1
| └── config.pbtxt
├── postprocess
│ └── 1
| └── model.py
| └── config.pbtxt
├── preprocess
│ └── 1
| └── model.py
| └── config.pbtxtワークスペースフォルダには、モデルをONNX形式に変換する最初のスクリプト(onnx_exporter.py)とTensorRTコンパイルスクリプト(generate_model_trt.sh)があります。
TritonはTensorRTランタイムをネイティブにサポートしており、選択したGPUアーキテクチャに最適化するためにTensorRTエンジンを簡単にデプロイできます。
Tritonコンテナ内のTensorRTバージョンと依存関係と互換性のあるものを使用するために、モデルをNVIDIAの対応するバージョンのPyTorchコンテナイメージを使用してコンパイルします:
model_id = "sentence-transformers/all-MiniLM-L6-v2"
! docker run --gpus=all --rm -it -v `pwd`/workspace:/workspace nvcr.io/nvidia/pytorch:22.10-py3 /bin/bash generate_model_trt.sh $model_id次に、モデルアーティファクトを以前に作成したディレクトリにコピーし、パスにバージョンを追加します:
! mkdir -p ensemble_hf/bert-trt/1 && mv workspace/model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf workspace/model.onnx workspace/core*Triton Pythonバックエンドで前処理と後処理に使用するConda環境を生成するために、Condaパックを使用します:
!bash conda_dependencies.sh
!cp processing_env.tar.gz ensemble_hf/postprocess/ && cp processing_env.tar.gz ensemble_hf/preprocess/
!rm processing_env.tar.gz最後に、モデルアーティファクトをAmazon S3にアップロードします:
!tar -C ensemble_hf/ -czf model_trt_python.tar.gz .
model_uri = sagemaker_session.upload_data(
path="model_trt_python.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("S3モデルURI: {}".format(model_uri))SageMaker MME GPUインスタンスでアンサンブルを実行する
アンサンブルアーティファクトがAmazon S3に保存されたので、SageMaker MMEを設定して起動することができます。
まず、TensorRTモデルのコンパイルに使用されるリージョンのコンテナレジストリと一致するTriton DLCイメージのコンテナイメージURIを取得します:
account_id_map = {
"us-east-1": "785573368785",
"us-east-2": "007439368137",
"us-west-1": "710691900526",
"us-west-2": "301217895009",
"eu-west-1": "802834080501",
"eu-west-2": "205493899709",
"eu-west-3": "254080097072",
"eu-north-1": "601324751636",
"eu-south-1": "966458181534",
"eu-central-1": "746233611703",
"ap-east-1": "110948597952",
"ap-south-1": "763008648453",
"ap-northeast-1": "941853720454",
"ap-northeast-2": "151534178276",
"ap-southeast-1": "324986816169",
"ap-southeast-2": "355873309152",
"cn-northwest-1": "474822919863",
"cn-north-1": "472730292857",
"sa-east-1": "756306329178",
"ca-central-1": "464438896020",
"me-south-1": "836785723513",
"af-south-1": "774647643957",
}
region = boto3.Session().region_name
if region not in account_id_map.keys():
raise ("サポートされていないリージョンです")
base = "amazonaws.com.cn" if region.startswith("cn-") else "amazonaws.com"
triton_image_uri = "{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:23.03-py3".format(
account_id=account_id_map[region], region=region, base=base
)次に、SageMakerでモデルを作成します。 create_model リクエストでは、使用するコンテナとモデルアーティファクトの場所を指定し、Mode パラメータでこれがマルチモデルであることを指定します。
container = {
"Image": triton_image_uri,
"ModelDataUrl": models_s3_location,
"Mode": "MultiModel",
}
create_model_response = sm_client.create_model(
ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container
)アンサンブルをホストするために、create_endpoint_config API呼び出しでエンドポイント構成を作成し、create_endpoint APIでエンドポイントを作成します。その後、SageMakerはホスティング環境でモデルのために定義したすべてのコンテナをデプロイします。
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": instance_type,
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name
)この例では、モデルをホストするために単一のインスタンスを設定していますが、SageMaker MMEは自動スケーリングポリシーの設定に完全に対応しています。この機能の詳細については、「Amazon SageMakerマルチモデルエンドポイントでGPU上で複数のディープラーニングモデルを実行する」を参照してください。
リクエストペイロードを作成し、各モデルにMMEを呼び出す
リアルタイムのMMEが展開されたら、使用したモデルアンサンブルごとにエンドポイントを呼び出す時間です。
まず、DALI-Inceptionアンサンブルのためのペイロードを作成します。SageMakerの公開データセットであるペットの画像からshiba_inu_dog.jpg画像を使用します。この画像をエンコードされたバイト配列として読み込んで、DALIバックエンドで使用します(詳細はImage Decoderの例を参照してください)。
sample_img_fname = "shiba_inu_dog.jpg"
import numpy as np
s3_client = boto3.client("s3")
s3_client.download_file(
"sagemaker-sample-files", "datasets/image/pets/shiba_inu_dog.jpg", sample_img_fname
)
def load_image(img_path):
"""
画像をエンコードされたバイト配列として読み込みます。
これは、DALIバックエンドで使用する典型的なアプローチです。
"""
with open(img_path, "rb") as f:
img = f.read()
return np.array(list(img)).astype(np.uint8)
rv = load_image(sample_img_fname)
print(f"画像の形状 {rv.shape}")
rv2 = np.expand_dims(rv, 0)
print(f"拡張された画像配列の形状 {rv2.shape}")
payload = {
"inputs": [
{
"name": "INPUT",
"shape": rv2.shape,
"datatype": "UINT8",
"data": rv2.tolist(),
}
]
}エンコードされた画像とペイロードの準備ができたので、エンドポイントを呼び出します。
ここで、ターゲットアンサンブルをmodel_tf_dali.tar.gzアーティファクトに指定します。TargetModelパラメータは、MMEと単一モデルのエンドポイントを区別し、リクエストを正しいモデルに誘導する機能を提供します。
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/octet-stream", Body=json.dumps(payload), TargetModel="model_tf_dali.tar.gz"
)レスポンスには呼び出しに関するメタデータ(モデル名とバージョンなど)と、出力オブジェクトのデータ部分に含まれる実際の推論結果が含まれています。この例では、1,001個の値の配列を取得します。各値は画像が所属するクラスの確率です(1,000クラスとその他のための1つの追加クラスがあります)。次に、MMEを再度呼び出し、今度は2番目のアンサンブルを対象とします。ここでは、データは2つのシンプルなテキスト文だけです。
text_inputs = ["文1", "文2"]Tritonとの通信を簡略化するために、Tritonプロジェクトはいくつかのクライアントライブラリを提供しています。このライブラリを使用してリクエストのペイロードを準備します。
import tritonclient.http as http_client
text_inputs = ["文1", "文2"]
inputs = []
inputs.append(http_client.InferInput("INPUT0", [len(text_inputs), 1], "BYTES"))
batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]
input0_real = np.array(batch_request, dtype=np.object_)
inputs[0].set_data_from_numpy(input0_real, binary_data=True)
outputs = []
outputs.append(http_client.InferRequestedOutput("finaloutput"))
request_body, header_length = http_client.InferenceServerClient.generate_request_body(
inputs, outputs=outputs
)エンドポイントを呼び出す準備ができました。今回は、ターゲットモデルはmodel_trt_python.tar.gzアンサンブルです。
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/vnd.sagemaker-triton.binary+json;json-header-size={}".format(
header_length
),
Body=request_body,
TargetModel="model_trt_python.tar.gz"
)レスポンスは、さまざまな自然言語処理(NLP)アプリケーションで使用できる文の埋め込みです。
クリーンアップ
最後に、エンドポイント、エンドポイント構成、およびモデルをクリーンアップして削除します。
sm_client.delete_endpoint(EndpointName=endpoint_name)
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm_client.delete_model(ModelName=sm_model_name)結論
この記事では、GPUアクセラレートインスタンスでSageMaker MMEとTritonアンサンブルを構成、展開、および呼び出す方法を示しました。1つのリアルタイム推論環境に2つのアンサンブルをホストし、コストを50%削減しました(年間の節約額は13,000ドル以上に相当)。この例では2つのパイプラインのみを使用しましたが、SageMaker MMEは数千のモデルアンサンブルをサポートできるため、非常に効果的なコスト削減メカニズムです。さらに、SageMaker MMEの動的なモデルのロード(およびアンロード)の能力を活用して、本番環境でのモデルデプロイの運用オーバーヘッドを最小限に抑えることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






