スケッチベースの画像対画像変換:GANを使用して抽象的なスケッチを写実的な画像に変換する
Using GANs to transform abstract sketches into realistic images through sketch-based image-to-image conversion.


スケッチに長けた人もいれば、他の仕事に才能を持つ人もいます。靴の画像が提示された場合、個人は写真を示す簡単な線を引くことができますが、スケッチの品質は異なる場合があります。それに対して、人間は抽象的な描画でも現実的なイメージを視覚化するという固有の能力を持っており、これは数百万年の進化の過程で開発されたスキルです。
AIと生成モデルの登場により、抽象的なスケッチから写真のようなリアルなイメージを生成することは、画像から画像への変換の文献の広義の文脈に含まれます。これに関しては、pix2pix、CycleGAN、MUNIT、BicycleGANなどの先行研究で探究されてきました。これらの先行手法の中には、スケッチ固有の変種も含まれており、写真のエッジマップを生成しています。エッジマップは細かい描画であり、これらのモデルは抽象的なスケッチではなく、洗練されたスケッチに焦点を当てていることを意味しています。
本記事で紹介されている論文は、先行手法とは異なる重要な点を持つスケッチベースの画像から画像への変換に焦点を当てています。この論文の著者によれば、エッジマップでトレーニングされたモデルは、エッジマップとともに高品質の写真を生成することができますが、アマチュアの人間のスケッチでは現実的な結果が得られません。これは、これまでのアプローチが変換中にピクセルの整列を前提としているためです。その結果、生成された結果は個人の描画スキル(または不足)を正確に反映し、非アーティストの場合には劣った結果になります。
- 「機械学習モデルを展開する」とはどういう意味ですか?
- 機械学習の簡素化と標準化のためのトップツール
- AIHelperBotとの出会い 秒単位でSQLクエリを構築する人工知能(AI)ベースのSQLエキスパート
したがって、これらのモデルでは訓練を受けていないアーティストは決して満足のいく結果を得ることはありません。しかし、本記事で紹介されている新しいAIアプローチは、スケッチから写真を生成する技術を民主化することを目指しています。
そのアーキテクチャは以下の図に示されています。
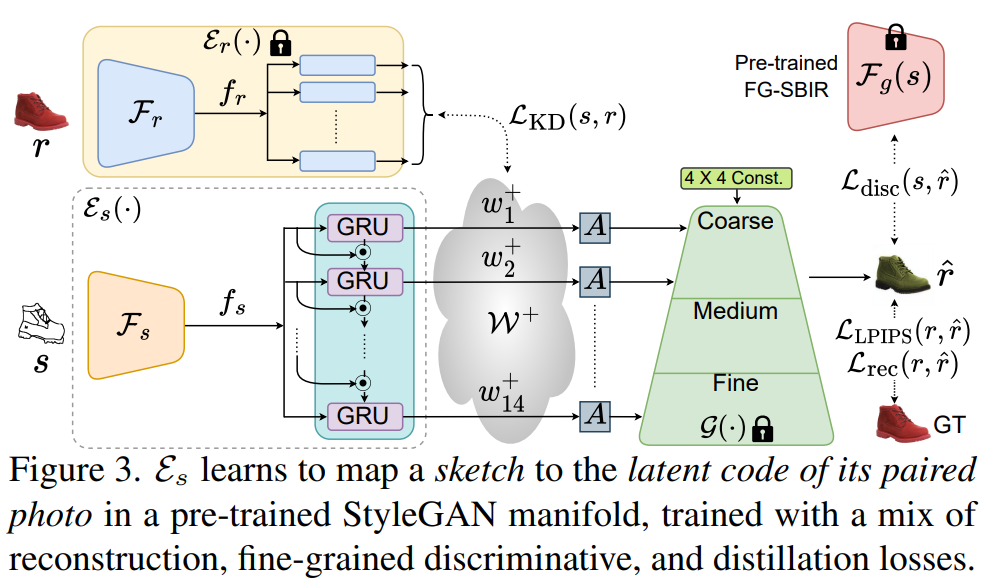
この技術により、スケッチの品質に関係なく、写真のようなリアルなイメージを生成することが可能となります。著者らは、以前のアプローチで見られたピクセル整列のアーティファクトは、エンコーダ-デコーダのアーキテクチャをエンドツーエンドでトレーニングすることから生じると結論付けました。これにより、生成された結果は入力スケッチ(エッジマップ)で定義された境界に厳密に従い、結果の品質が制約されることになります。この問題に対処するために、彼らは分離されたエンコーダ-デコーダのトレーニング方法を導入しました。研究者たちは、StyleGANを写真のみで事前トレーニングし、その後それを凍結しました。これにより、生成された結果はStyleGANの多様体からサンプリングされた写真のようなリアルな品質を持つことが保証されました。
もう一つの重要な側面は、抽象的なスケッチと現実的な写真の間のギャップです。この問題を克服するために、彼らはエンコーダを訓練して、通常の写真ではなく、スケッチの表現をStyleGANの潜在空間にマッピングするようにしました。彼らはグラウンドトゥルースのスケッチ-写真のペアを使用し、入力スケッチと生成された写真の間に新しい細かい識別損失を課し、正確なマッピングを保証するために従来の再構成損失を追加しました。さらに、彼らはスケッチの抽象的な性質を扱うために部分的な認識を意識した拡張戦略を導入しました。これは、完全なスケッチの部分的なバージョンをレンダリングし、部分的な情報のレベルに基づいて潜在ベクトルを適切に割り当てることを含んでいます。
彼らの生成モデルをトレーニングした後、研究者たちはいくつかの興味深い特性を観察しました。生成された写真の抽象度は、予測された潜在ベクトルの数やガウスノイズの追加によって簡単に制御できることがわかりました。また、部分的な認識を意識したスケッチの拡張戦略により、ノイズや部分的なスケッチに対して堅牢性を示しました。さらに、モデルは入力スケッチの抽象化レベルの異なる状況においても良好な汎化性能を示しました。
提案手法と最先端の手法による結果の多様性を以下に報告します。

これは、抽象的な人間のスケッチから写真のようなリアルなイメージを合成するための新しいAI生成画像対画像モデルの要約でした。もしこの研究に興味があり、さらに詳細な情報を知りたい場合は、以下のリンクをクリックして詳細をご覧いただけます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「人間によるガイド付きAIフレームワークが、新しい環境でのロボットの学習を迅速化することを約束します」
- 「DifFaceに会ってください:盲目の顔の修復のための新しい深層学習拡散モデル」
- 「トップの画像処理Pythonライブラリ」
- このAI論文は、周波数領域での差分プライバシーを利用したプライバシー保護顔認識手法を提案しています
- 「Baichuan-13Bに会いましょう:中国のオープンソースの大規模言語モデル、OpenAIに対抗する」
- スタビリティAIチームが、新しいオープンアクセスの大規模言語モデル(LLM)であるFreeWilly1とFreeWilly2を紹介します
- 「ラマ-2、GPT-4、またはクロード-2;どの人工知能言語モデルが最も優れているのか?」





