「コードを使用して、大規模な言語モデルを使って、どんなPDFや画像ファイルでもチャットする方法」
Using code to chat with any PDF or image file using a large-scale language model
どんなファイルに関する質問でも答えられるAIアシスタントの構築完全ガイド
イントロダクション
PDFや画像ファイルには非常に貴重な情報が含まれています。幸いなことに、私たちの頭脳はこれらのファイルを処理して特定の情報を見つけることができる強力な能力を持っています。
しかし、私たちの内部には、与えられたドキュメントに関するどんな質問でも答えられるツールを持ちたいと思う人はどれだけいるでしょうか?
それがこの記事の目的です。PDFや画像ファイルとチャットできるシステムをステップバイステップで構築する方法を説明します。
動画を視聴する方は以下のリンクをチェックしてください:
プロジェクトの一般的なワークフロー
構築するシステムの主要なコンポーネントを明確に理解することは常に良いことです。では、始めましょう。
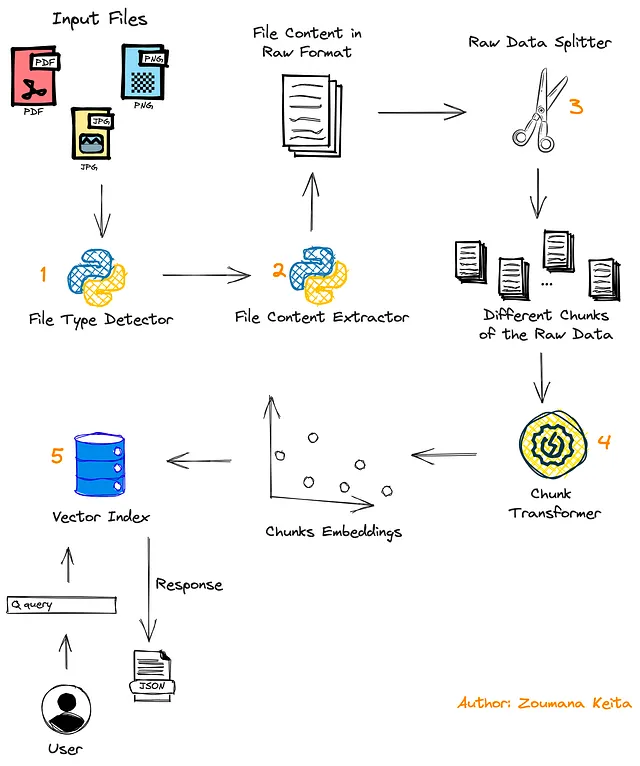
- まず、ユーザーは処理するドキュメントを提出します。これはPDF形式または画像形式のどちらでも構いません。
- ファイルの形式を検出するために、第2のモジュールが使用されて関連するコンテンツ抽出関数が適用されます。
- ドキュメントのコンテンツは、
Data Splitterモジュールを使用して複数のチャンクに分割されます。 - それらのチャンクは最終的に
Chunk Transformerを使用して埋め込みに変換され、ベクトルストアに保存されます。 - プロセスの終わりに、ユーザーのクエリを使用して、そのクエリに対する回答が含まれる関連するチャンクを見つけ、結果をJSON形式でユーザーに返します。
1. ドキュメントの形式を検出する
各入力ドキュメントに対して、そのタイプに応じて特定の処理が適用されます。それがPDFまたはimageであるかどうかによります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






