「Azureの「Prompt Flow」を使用して、GPTモードで文書コーパスをクエリする」
Using Azure's 'Prompt Flow' to query document corpus in GPT mode.
コンテンツを自動的にベクトル化し、LangChainのようなメカニズムを作成して、文書のコーパスを効率的にクエリする方法
GPTの熱狂
世界中のテック愛好家は、ChatGPTを使って遊んできました…
- 彼らの多くは、非常に賢明な知識データベースとして使用しました🔎
- 一部の人は、「プロンプトエンジニアリング」と呼ばれる方法を探求し、より関連性の高い結果を得るために、自分自身のデータを使用したりしました🤖
- しかし、LangChainのようなソリューションを活用して、複雑なワークフローを構築し、現実のアプリケーションを作成したのはほんの一部です📚
そして、実際にLLMのパワーを解放することを妨げる、埋め込みやベクトルストアのような概念をマスターすることは、多くの人にとって複雑に思えるかもしれません。
ここで、「Prompt Flow」が助けになります!
さあ、Azureでローコードで強力なQ&Aツールを構築する方法を発見しましょう!
前提条件
このチュートリアルのために必要なリソースを作成する権限があることを前提とします。最も重要なものは、「Azure Machine Learning Studio Workspace」を持っていることです。
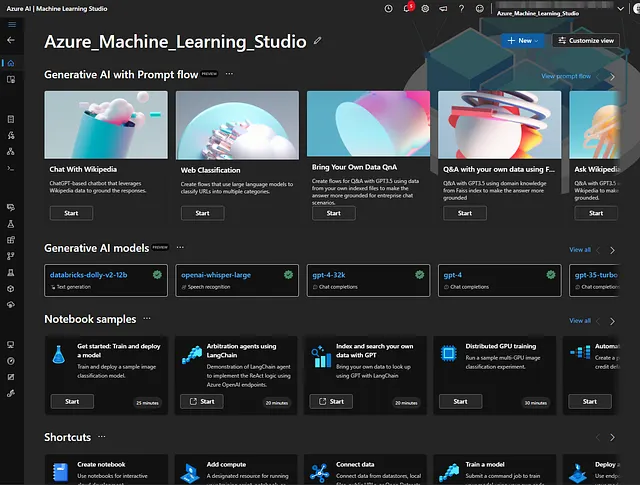
「Prompt Flow」機能や「モデルカタログ」(Azure、Hugging Face、MetaなどがキュレーションしたLLMを展開できる)は、現在プライベートまたはパブリックプレビューであり、使用するためには待ちリストに参加する必要があります。
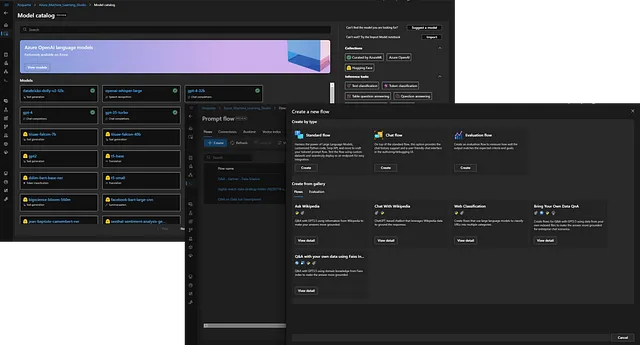
ベクトルインデックスの構築
埋め込みの理解
大量のコーパスを効率的に処理し、現在のモデルのトークン制限を克服するために、各ドキュメントをチャンク(例:各ページ)に分割し、変換する必要があります…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






