AWSとPower BIを使用して、米国のフライトを調査する
Using AWS and Power BI to investigate flights in the United States.
ETLとBIを使用してどのような洞察を得ることができるのでしょうか?
目次
∘ イントロダクション ∘ 問題のステートメント ∘ データ ∘ AWSアーキテクチャ ∘ AWS S3を使用したデータストレージ ∘ スキーマの設計 ∘ AWS Glueを使用したETL処理 ∘ AWS Redshiftを使用したデータウェアハウジング ∘ AWS Redshiftを使用した洞察の抽出 ∘ Power BIを使用したデータの可視化 ∘ 今後のステップ ∘ 結論 ∘ 参考文献
イントロダクション
航空旅行は私たちの生活の重要な一部となりました。ビジネスのネットワーキングや商取引の手段、家族の愛する人を訪ねたり旅行したりするための手段として利用されています。
その影響力にもかかわらず、航空業界は激動の時代を迎えています。経済の停滞や拡大、気候変動、COVID-19パンデミック、再生可能エネルギー源への依存度の向上など、外部要因による持続的な変化にさらされています。
このような変化と航空旅行への影響を認識するためには、時間をかけてこれらのフライトを追跡する価値があります。このような取り組みには、頑強なデータウェアハウジング、データ分析、データ可視化の戦略が必要です。
問題のステートメント
このプロジェクトには2つの主な目標があります。1つ目は、Amazon Web Services(AWS)が提供するリソースを活用して、米国のフライトデータのストレージ、変換、分析を容易にするデータパイプラインを構築することです。
2つ目は、Power BIを使用して、データからの主要な知見を効果的に表現するビジュアライゼーションツールを構築することです。
データ
このプロジェクトで使用するデータセットは、運輸統計局から入手されます。主に2003年から2023年までの空港と航空会社のフライト数、遅延数、キャンセル数などを報告しています。
以下はデータセットのプレビューです:

一見すると、生のデータセットにはいくつかの問題があります。
まず、airport_nameフィールドの情報は複数の情報から構成されています。これは空港の名前だけでなく、都市と州の情報も含まれています。この情報に簡単にアクセスするためには、このフィールドを3つの別々のフィールドに分割する必要があります。
さらに、このデータは現在フラットなモデル(つまり、1つのテーブル)を採用しています。しかし、データには関係を持つ複数のエンティティが含まれているため、これは最適なセットアップではありません。
これらの課題は、データを分析や可視化に利用する前に解決する必要があります。
AWSアーキテクチャ
データパイプラインを構築するために必要なAWSアーキテクチャについて説明しましょう。
必要なリソースは次のダイアグラムで最もよく説明されます:

このクラウドソリューションでは、生データおよび変換データを保管するためにAmazon S3、データを変換するためのETLジョブを作成するためのAWS Glue、データからの洞察をSQLで抽出するためのクラウドデータウェアハウスであるAWS Redshift、データの主要なメトリクスをダッシュボード形式で表示するためにPower BIが使用されます。
AWS S3を使用したデータストレージ
このプロジェクトでは、2つのS3バケット「flights-data-raw」と「flights-data-processed」を使用します。

「flights-data-raw」バケットには生データセットが含まれています。

「flights-data-processed」バケットにはデータが変換された後のデータが含まれます(現在は空です)。
スキーマの設計
次に、このデータに適したスキーマを決定することが重要です。生データはフラットファイルに保存されており、単一のテーブルを含んでいます。
残念ながら、このスキーマには日付、空港、航空会社などの複数のエンティティで構成される単一のテーブルしかありません。データの迅速な検索のためにデータベースを最適化するために、このフラットスキーマを次元モデリングを使用してスタースキーマに変換することができます。
この新しいスキーマでは、flightsテーブルが事実テーブルとして機能し、date、carrier、airportテーブルが次元テーブルとして機能します。
AWS GlueによるETL
AWS Glueで作成されたETLジョブは、生データを事実テーブルと次元テーブルに変換し、それらをflights-data-processedバケットにロードすることができます。
ETLジョブでは、Pythonスクリプトをインポートして次元モデリングを実行します。
スクリプトはPython SDKであるboto3を使用して、flights-data-rawバケット内の生データセットを抽出し、スタースキーマ内の4つのテーブルを作成し、それらをcsvファイルとしてflights-data-processedバケットにロードします。
例えば、次のスニペットはcarrierテーブルを作成するために使用されます。
スキーマ内の4つのテーブルを作成するために使用される完全なスクリプトは、GitHubリポジトリでアクセスできます。
ETLジョブは問題なく実行されます。

データセットは、csvファイルの形式で1つの事実テーブルと3つの次元テーブルに変換され、すべてがflights-data-processedバケットに保存されます。

AWS Redshiftを使用したデータウェアハウス
AWS Glueを使用すると、元々フラットモデルであったデータをデータウェアハウス内の適切なスタースキーマで表現することができます。
このデータのクラウドデータウェアハウスは、AWS Redshift Serverlessで作成されます。これには、「flights-namespace」という名前空間、および「dev」という名前のデータベースが作成されます。さらに、SQLクエリを書くために使用される「flights-workgroup」という名前のワークグループも必要です。
注:ワークグループは、VPC外のデバイスがデータベースにアクセスできるように構成されています。これは、Power BIを使用して可視化を作成する際に便利です。

さて、Redshiftのクエリエディタを開き、devデータベース内でファクトテーブルとディメンションテーブルを作成できます。
まず、スキーマ内の4つのテーブルを以下のコマンドを使用してデータウェアハウスに作成する必要があります:
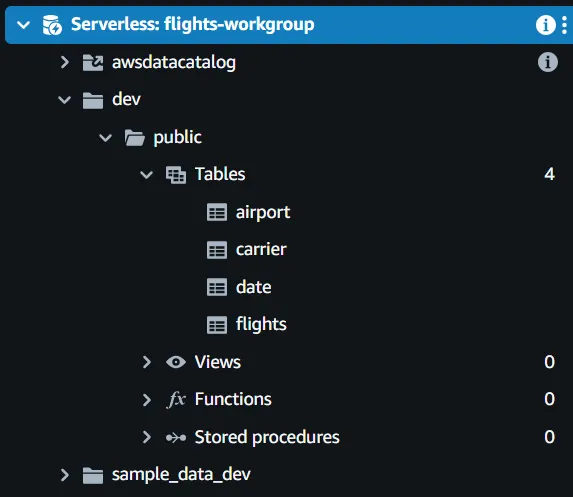
4つのテーブルはデータウェアハウスに存在しますが、データはまだflights-data-processedバケットにありますので、すべて空です。
データは、COPYコマンドを使用してこのデータウェアハウスにコピーできます。
たとえば、flights.csvのデータを以下のコマンド構文を使用してflightsテーブルにコピーできます:
注:
iam_role変数は、ワークグループの作成時に選択されたIAMロールに割り当てる必要があります。
COPYコマンドを実行することで、flights-data-processedバケット内の各csvファイルに対して、4つのテーブルに必要なデータが入ります。
例えば、次は空港テーブルのプレビューです:

AWS Redshiftを使用したインサイトの抽出
すべてのテーブルがデータでロードされたので、SQLクエリを使用して分析を実行できます!
データは事前にスタースキーマとディメンションモデリングに変換されているため、実行時間が短く効率的にデータを取得できるため、アドホックな分析に最適なセットアップです。
以下は、SQLクエリで回答できるいくつかの質問の例です。
- 2022年に最も多くのフライトが発生した空港はどこですか?

2. 2019年以降の総遅延に最も貢献した遅延のタイプは何ですか?
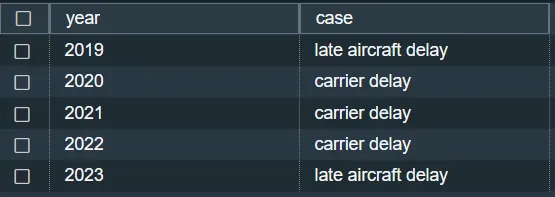
3. ジョン・F・ケネディ空港では、各年の遅延のパーセント変化は何ですか?
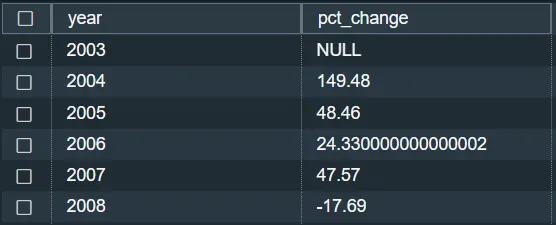
Power BIを使用したデータの可視化
現在のクラウドデータウェアハウスは、ユーザーがわずかな時間とコストで重要な質問に答えることができるようになっています。
ただし、これをさらに進めることができ、エンドユーザーが同様の質問に答えるために使用できる可視化を作成することができます。
これを実現する方法の1つは、非常に人気のあるBIツールであるPower BIを使用してダッシュボードを作成することです。
可視化を通じて発掘できるメトリクスは多数ありますが、ダッシュボードでは以下の点に焦点を当てます:
- フライト数、遅延数、キャンセル数のサマリー
- 時間の経過に伴うフライト数、遅延数、キャンセル数のトラッキング
- 最も利用されている空港とキャリアの特定
- さまざまな種類の遅延の内訳
さらに、ダッシュボードには、ユーザーが特定の時間と場所をターゲットにできるフィルターも含まれます。
これらの機能を以下のようなダッシュボードの形式で組み合わせることができます:

このようなツールを使用することで、データへのアクセス権限やSQLの知識がないユーザーでも、少ない努力で重要な質問に答えることができます。
このような質問には以下が含まれます:
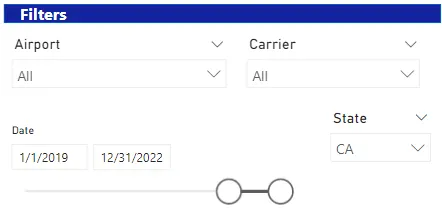
- JFK空港で最も多くのフライトを運航しているキャリアはどれですか?
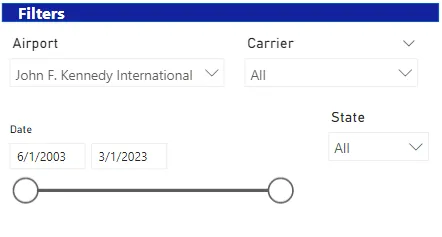

2. 2019年から2022年までのカリフォルニアでキャンセルされたフライトはいくつですか?

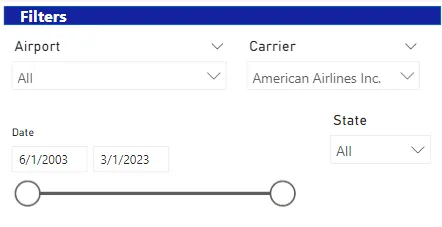
3. アメリカン航空で最も遅延の原因となっている遅延の種類は何ですか?

今後の手順

AWSとPower BIの現在のセットアップは、迅速かつ低コストなデータ分析と可視化を促進しています。ただし、将来のデータに対する新しい応用を考慮する価値があります。
- 新しいデータソースの統合
新しいデータソースを統合する場合、スキーマを適宜変更する必要があります。さらに、これらのソースからのデータを既存のデータウェアハウスにシームレスに統合するために、追加のETLジョブを作成する必要があります。
2. 時系列分析の実施
BTSが提供するデータは時系列データです。そのため、将来の航空需要を予測するために、時系列分析を考慮し、予測モデルを構築することにメリットがあります。
結論
BTSが提供するような豊富な記録を持つデータセットは、管理が難しいものです。しかし、AWSが提供するリソースを利用することで、データパイプラインを構築し、データを処理して効果的な形式で構造化することができます。
さらに、作成したPower BIのダッシュボードのような可視化は、特定の指標をコンテキストに置き、観衆にインパクトのあるストーリーを作り出すための効果的な手法です。
AWS GlueでETLジョブを構築するために使用したコードや、テーブルを作成し分析を実行するために使用したSQLクエリについては、GitHubリポジトリをご覧ください。
GitHub – anair123/Tracking-U.S.-Flights-With-AWS-and-Power-BI
GitHubでanair123/Tracking-U.S.-Flights-With-AWS-and-Power-BIの開発に貢献するには、GitHubでアカウントを作成してください。
github.com
お読みいただきありがとうございました!
参考文献
- Airline On-Time Statistics and Delay Causes . BTS. (n.d.). https://www.transtats.bts.gov/ot_delay/OT_DelayCause1.asp?20=E
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
