「Amazon SageMakerを使用して、マルチクラウド環境でMLモデルをトレーニングおよびデプロイする」
Using Amazon SageMaker to train and deploy ML models in a multi-cloud environment.
お客様はクラウドへの移行とビジネスの変革を加速させる中で、マルチクラウド環境でのITオペレーションの管理が必要な状況に直面することがあります。例えば、異なるクラウドプロバイダーで運用されている企業を買収した場合や、AWSが提供する独自の機能から価値を生み出すワークロードを持っている場合などです。また、独立系ソフトウェアベンダー(ISV)は、エンドカスタマーの利益を得るために異なるクラウドプラットフォームで自社の製品やサービスを提供することがあります。さらに、データ主権やデータの所在地要件を満たすために、主要なクラウドプロバイダーが利用できない地域で組織が運用されている場合、セカンダリクラウドプロバイダーを利用することもあります。
これらのシナリオでは、ジェネレーティブAI、大規模言語モデル(LLM)、および機械学習(ML)技術をビジネスの中核として活用し始めるにつれて、AWSのAIおよびML機能をAWS以外のマルチクラウド環境で活用するオプションを探しているかもしれません。例えば、Amazon SageMakerを使用してMLモデルを構築およびトレーニングしたり、Amazon SageMaker Jumpstartを使用して事前構築された基盤やサードパーティのMLモデルをデプロイしたりすることが考えられます。また、Amazon Bedrockを活用してジェネレーティブAIアプリケーションを構築およびスケールさせたり、機械学習スキルを学ぶ必要のないAWSの事前トレーニング済みAIサービスを利用することもできます。AWSでは、組織が独自のモデルをAmazon SageMakerまたはAmazon SageMaker Canvasに持ち込んで予測する場合にもサポートを提供しています。
この記事では、マルチクラウド環境でAWSの最も幅広く、深いAI/ML機能を活用するための多くのオプションのうちの1つを実証します。AWSでMLモデルを構築およびトレーニングし、別のプラットフォームでモデルをデプロイする方法を示します。Amazon SageMakerを使用してモデルをトレーニングし、モデルのアーティファクトをAmazon Simple Storage Service (Amazon S3)に保存し、Azureでモデルをデプロイおよび実行します。このアプローチは、AWSのMLサービスの最も包括的な機能セットを使用してモデルを実行する必要がありながら、先述した状況のいずれかで別のクラウドプロバイダーでモデルを実行する場合に有益です。
キーコンセプト
Amazon SageMaker Studioは、マシンラーニングのためのウェブベースの統合開発環境(IDE)です。SageMaker Studioを使用すると、データサイエンティスト、MLエンジニア、データエンジニアが1つのウェブインターフェース上でデータの準備、MLモデルの構築、トレーニング、デプロイを行うための専用ツールにアクセスできます。SageMaker Studioノートブックは、SageMakerや他のAWSサービスと統合された専用のMLツールと連携する、クイックスタートで共同作業が可能なノートブックです。
SageMakerは、MLの専門知識に関係なく、ビジネスアナリスト、データサイエンティスト、MLOpsエンジニアがあらゆるユースケースに対応してMLモデルを構築、トレーニング、デプロイするための包括的なMLサービスです。
AWSは、PyTorch、TensorFlow、Apache MXNetなどの人気のあるMLフレームワーク向けのDeep Learning Containers (DLC)を提供しており、これらをSageMakerでトレーニングと推論に使用することができます。DLCはAmazon Elastic Container Registry (Amazon ECR)のDockerイメージとして利用できます。Dockerイメージは、トレーニングと推論に必要な最新バージョンの人気のあるディープラーニングフレームワークおよびその他の依存関係が事前にインストールされ、テストされています。SageMakerが管理する事前構築のDockerイメージの完全なリストについては、「Docker Registry Paths and Example Code」を参照してください。Amazon ECRはセキュリティスキャンをサポートし、Amazon Inspectorの脆弱性管理サービスと統合されており、組織のイメージコンプライアンスのセキュリティ要件を満たし、脆弱性評価スキャンを自動化することができます。組織はまた、MLトレーニングジョブや推論の実行において、より優れた価格性能を実現するためにAWS TrainiumおよびAWS Inferentiaを利用することもできます。
ソリューションの概要
このセクションでは、SageMakerを使用してモデルを構築およびトレーニングし、モデルをAzure Functionsにデプロイする方法について説明します。SageMaker Studioノートブックを使用してモデルを構築、トレーニング、デプロイします。この場合、SageMakerでトレーニングされたモデルをAzureにデプロイしていますが、同じアプローチをオンプレミスや他のクラウドプラットフォームなど、他のプラットフォームにモデルをデプロイする場合にも使用できます。
トレーニングジョブを作成すると、SageMakerはMLコンピューティングインスタンスを起動し、トレーニングコードとトレーニングデータセットを使用してモデルをトレーニングします。トレーニングジョブの入力として指定したS3バケットに、結果のモデルアーティファクトおよびその他の出力を保存します。モデルのトレーニングが完了したら、PyTorchモデルをONNXモデルとしてエクスポートするために、Open Neural Network Exchange (ONNX) ランタイムライブラリを使用します。
最後に、ONNXモデルとPythonで書かれたカスタム推論コードをAzure FunctionsにAzure CLIを使用してデプロイします。ONNXは、ほとんどの一般的に使用されるMLフレームワークとツールをサポートしています。注意すべきは、MLモデルをONNX形式に変換することは、PyTorchからTensorFlowなどの異なるデプロイフレームワークを使用したい場合に便利です。ソースとターゲットの両方で同じフレームワークを使用している場合、モデルをONNX形式に変換する必要はありません。
次の図は、このアプローチのアーキテクチャを示しています。
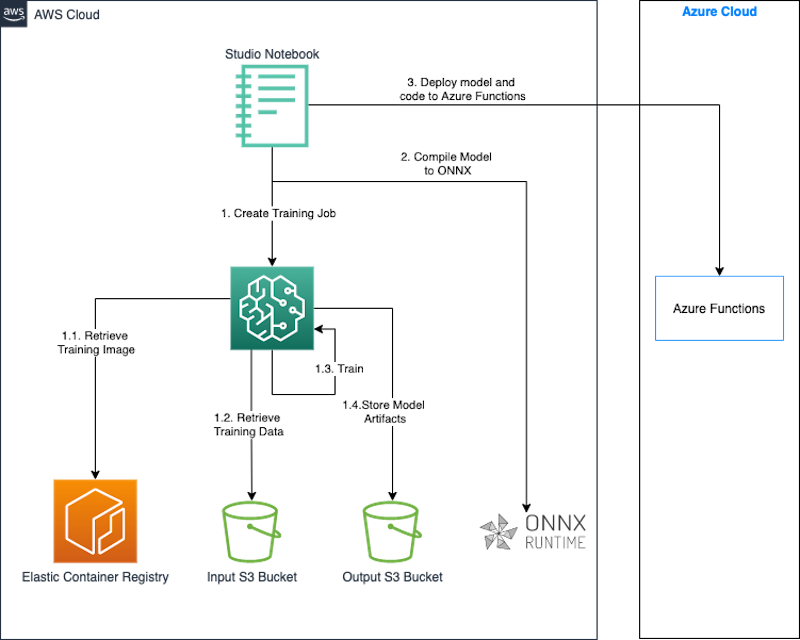
モデルを構築してトレーニングするために、SageMaker StudioノートブックとSageMaker Python SDKを使用します。SageMaker Python SDKは、SageMaker上でMLモデルのトレーニングとデプロイを行うためのオープンソースライブラリです。詳細については、Amazon SageMaker Studioノートブックの作成またはオープンを参照してください。
以下のセクションのコードスニペットは、Data Science 3.0イメージとPython 3.0カーネルを使用してSageMaker Studioノートブック環境でテストされています。
このソリューションでは、以下の手順をデモンストレーションします:
- PyTorchモデルのトレーニング。
- PyTorchモデルをONNXモデルとしてエクスポート。
- モデルと推論コードをパッケージ化。
- モデルをAzure Functionsにデプロイ。
前提条件
以下の前提条件を満たしている必要があります:
- AWSアカウント。
- SageMakerドメインとSageMaker Studioユーザー。これらを作成する手順については、クイックセットアップを使用したAmazon SageMakerドメインへのオンボードを参照してください。
- Azure CLI。
- Azureにアクセスし、Azure Functionsを作成および管理するための権限を持つサービスプリンシパルの資格情報。
PyTorchでモデルをトレーニングする
このセクションでは、PyTorchモデルをトレーニングする手順について詳細を説明します。
依存関係のインストール
モデルのトレーニングとデプロイに必要な手順を実行するためのライブラリをインストールします:
pip install torchvision onnx onnxruntime初期セットアップの完了
PythonのAWS SDK(Boto3)とSageMaker Python SDKをインポートします。セットアップの一環として、以下を定義します:
- SageMakerと自分自身のアカウントのコンテキスト内で利便性の高いメソッドを提供するセッションオブジェクト。
- トレーニングとホスティングサービスにアクセスできるようにするためのS3バケットへのアクセス許可を委任するために使用されるSageMakerのロールARN。データとモデルが保存されているS3バケットにこれらのサービスがアクセスできるようにするためにこれが必要です。ビジネスニーズに応じたロールを作成する手順については、SageMaker Rolesを参照してください。この投稿では、Studioノートブックインスタンスと同じ実行ロールを使用します。これを呼び出すことで、このロールを取得します:
sagemaker.get_execution_role()。 - トレーニングジョブが実行されるデフォルトのリージョン。
- モデルの出力を保存するために使用するデフォルトのバケットとプレフィックス。
以下のコードを参照してください:
import sagemaker
import boto3
import os
execution_role = sagemaker.get_execution_role()
region = boto3.Session().region_name
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = "sagemaker/mnist-pytorch"トレーニングデータセットの作成
公開バケットsagemaker-example-files-prod-{region}にあるデータセットを使用します。データセットには、以下のファイルが含まれています:
- train-images-idx3-ubyte.gz – トレーニングセットの画像を含む
- train-labels-idx1-ubyte.gz – トレーニングセットのラベルを含む
- t10k-images-idx3-ubyte.gz – テストセットの画像を含む
- t10k-labels-idx1-ubyte.gz – テストセットのラベルを含む
データを公開バケットからローカルにダウンロードし、トレーニングデータバケットにアップロードする前に、torchvision.datasetsモジュールを使用します。このバケットの場所をSageMakerトレーニングジョブへの入力として渡します。トレーニングスクリプトは、この場所を使用してトレーニングデータをダウンロードし、準備し、そしてモデルをトレーニングします。以下のコードを参照してください:
MNIST.mirrors = [
f"https://sagemaker-example-files-prod-{region}.s3.amazonaws.com/datasets/image/MNIST/"
]
MNIST(
"data",
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)トレーニングスクリプトの作成
SageMakerを使用すると、スクリプトモードを使用して独自のモデルを持ち込むことができます。スクリプトモードでは、事前に構築されたSageMakerコンテナを使用し、モデルの定義とカスタムライブラリ、依存関係を含むトレーニングスクリプトを提供することができます。SageMaker Python SDKは、スクリプトをentry_pointとしてコンテナに渡し、提供されたスクリプトからトレーニング関数を読み込んでモデルをトレーニングします。
トレーニングが完了すると、SageMakerはトレーニングジョブに指定したS3バケットにモデルの出力を保存します。
トレーニングコードは、以下のPyTorchのサンプルスクリプトを基にしています。次のコードの抜粋は、モデルの定義とトレーニング関数を示しています:
# ネットワークの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# トレーニング
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
breakモデルのトレーニング
環境のセットアップと入力データセット、カスタムトレーニングスクリプトの作成が完了したので、SageMakerを使用してモデルのトレーニングを開始できます。SageMaker Python SDKのPyTorchエスティメータを使用して、SageMakerでトレーニングジョブを開始します。エスティメータに必要なパラメータを渡し、fitメソッドを呼び出します。PyTorchエスティメータのfitを呼び出すと、SageMakerはスクリプトをトレーニングコードとして使用してトレーニングジョブを開始します:
from sagemaker.pytorch import PyTorch
output_location = f"s3://{bucket}/{prefix}/output"
print(f"トレーニングアーティファクトは次の場所にアップロードされます: {output_location}")
hyperparameters={
"batch-size": 100,
"epochs": 1,
"lr": 0.1,
"gamma": 0.9,
"log-interval": 100
}
instance_type = "ml.c4.xlarge"
estimator = PyTorch(
entry_point="train.py",
source_dir="code", # トレーニングスクリプトのディレクトリ
role=execution_role,
framework_version="1.13",
py_version="py39",
instance_type=instance_type,
instance_count=1,
volume_size=250,
output_path=output_location,
hyperparameters=hyperparameters
)
estimator.fit(inputs = {
'training': f"{inputs}",
'testing': f"{inputs}"
})トレーニング済みモデルをONNXモデルとしてエクスポートする
トレーニングが完了し、モデルがAmazon S3の事前定義された場所に保存されたら、ONNXランタイムを使用してモデルをONNXモデルにエクスポートします。
ONNXへのモデルのエクスポートコードは、トレーニングが完了した後に実行されるようにトレーニングスクリプトに含まれています。
PyTorchは、入力を使用してモデルを実行し、出力を計算するために使用される演算子のトレースを記録することで、モデルをONNXにエクスポートします。PyTorchのtorch.onnx.export関数を使用して、モデルをONNXにエクスポートします。また、入力の最初の次元を動的に指定して、モデルが推論中に可変のbatch_sizeの入力を受け入れるようにします。
def export_to_onnx(model, model_dir, device):
logger.info("モデルをONNX形式にエクスポートします。")
dummy_input = torch.randn(1, 1, 28, 28).to(device)
input_names = [ "input_0" ]
output_names = [ "output_0" ]
path = os.path.join(model_dir, 'mnist-pytorch.onnx')
torch.onnx.export(model, dummy_input, path, verbose=True, input_names=input_names, output_names=output_names,
dynamic_axes={'input_0' : {0 : 'batch_size'}, # 可変長の軸
'output_0' : {0 : 'batch_size'}})ONNXは、PyTorch、Microsoft Cognitive Toolkit(CNTK)などの深層学習フレームワーク間の相互運用性を可能にする、深層学習モデルのオープン標準形式です。これにより、これらのフレームワークのいずれかを使用してモデルをトレーニングし、事前トレーニング済みモデルをONNX形式でエクスポートすることができます。モデルをONNX形式にエクスポートすることで、より幅広いデプロイメントデバイスやプラットフォームを選択できる利点が得られます。
モデルアーティファクトのダウンロードと抽出
トレーニングスクリプトによって保存されたONNXモデルは、SageMakerによってトレーニングジョブを開始したときに指定した出力場所に、Amazon S3にコピーされます。モデルアーティファクトは、model.tar.gzという名前の圧縮アーカイブファイルとして保存されています。このアーカイブファイルをStudioノートブックインスタンスのローカルディレクトリにダウンロードし、モデルアーティファクト、つまりONNXモデルを抽出します。
import tarfile
local_model_file = 'model.tar.gz'
model_bucket,model_key = estimator.model_data.split('/',2)[-1].split('/',1)
s3 = boto3.client("s3")
s3.download_file(model_bucket,model_key,local_model_file)
model_tar = tarfile.open(local_model_file)
model_file_name = model_tar.next().name
model_tar.extractall('.')
model_tar.close()ONNXモデルの検証
ONNXモデルは、トレーニングスクリプトによってmnist-pytorch.onnxという名前のファイルにエクスポートされます。このファイルをダウンロードして抽出した後、オプションでonnx.checkerモジュールを使用してONNXモデルを検証することができます。このモジュールのcheck_model関数は、モデルの整合性をチェックします。テストに失敗した場合は、例外が発生します。
import onnx
onnx_model = onnx.load("mnist-pytorch.onnx")
onnx.checker.check_model(onnx_model)モデルと推論コードのパッケージ化
この記事では、Azure Functionsの.zipデプロイメントを使用します。この方法では、モデル、関連するコード、およびAzure Functionsの設定を.zipファイルにパッケージ化し、Azure Functionsに公開します。次のコードは、デプロイメントパッケージのディレクトリ構造を示しています:
mnist-onnx ├── function_app.py ├── model │ └── mnist-pytorch.onnx └── requirements.txt
依存関係のリスト
推論コードの依存関係を、パッケージのルートにあるrequirements.txtファイルに記載します。このファイルは、パッケージを公開する際にAzure Functionsの環境を構築するために使用されます。
azure-functions numpy onnxruntime
推論コードの作成
次の推論コードは、ONNX Runtimeライブラリを使用してモデルをロードし、推論を実行するためにPythonを使用して記述されています。これにより、Azure Functionsアプリが/classifyという相対パスでエンドポイントを利用できるようになります。
import logging
import azure.functions as func
import numpy as np
import os
import onnxruntime as ort
import json
app = func.FunctionApp()
def preprocess(input_data_json):
# JSONデータをテンソル入力に変換する
return np.array(input_data_json['data']).astype('float32')
def run_model(model_path, req_body):
session = ort.InferenceSession(model_path)
input_data = preprocess(req_body)
logging.info(f"入力データの形状は{input_data.shape}です。")
input_name = session.get_inputs()[0].name # モデルの最初の入力のIDを取得する
try:
result = session.run([], {input_name: input_data})
except (RuntimeError) as e:
print("形状={0}、エラー={1}".format(input_data.shape, e))
return result[0]
def get_model_path():
d=os.path.dirname(os.path.abspath(__file__))
return os.path.join(d , './model/mnist-pytorch.onnx')
@app.function_name(name="mnist_classify")
@app.route(route="classify", auth_level=func.AuthLevel.ANONYMOUS)
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTPトリガー関数がリクエストを処理しました。')
# ポストからimgの値を取得する
try:
req_body = req.get_json()
except ValueError:
pass
if req_body:
# モデルを実行する
result = run_model(get_model_path(), req_body)
# 出力を整数にマッピングし、結果の文字列を返す
digits = np.argmax(result, axis=1)
logging.info(type(digits))
return func.HttpResponse(json.dumps({"digits": np.array(digits).tolist()}))
else:
return func.HttpResponse(
"HTTPトリガー関数は正常に実行されました。",
status_code=200
)Azure Functionsへのモデルのデプロイ
必要な.zip形式にコードがパッケージ化されたので、Azure Functionsに公開する準備が整いました。Azure CLIを使用してそれを行います。Azure CLIは、Azureリソースを作成および管理するためのコマンドラインユーティリティです。次のコードでAzure CLIをインストールします。
!pip install -q azure-cli次に、以下の手順を完了します。
-
Azureにログインします:
!az login -
リソース作成パラメータを設定します:
import random random_suffix = str(random.randint(10000,99999)) resource_group_name = f"multicloud-{random_suffix}-rg" storage_account_name = f"multicloud{random_suffix}" location = "ukwest" sku_storage = "Standard_LRS" functions_version = "4" python_version = "3.9" function_app = f"multicloud-mnist-{random_suffix}" -
次のコマンドを使用して、Azure Functionsアプリと前提条件のリソースを作成します:
!az group create --name {resource_group_name} --location {location} !az storage account create --name {storage_account_name} --resource-group {resource_group_name} --location {location} --sku {sku_storage} !az functionapp create --name {function_app} --resource-group {resource_group_name} --storage-account {storage_account_name} --consumption-plan-location "{location}" --os-type Linux --runtime python --runtime-version {python_version} --functions-version {functions_version} -
Functionsパッケージをデプロイする際に、
requirements.txtファイルがアプリケーションの依存関係のビルドに使用されるようにAzure Functionsを設定します:!az functionapp config appsettings set --name {function_app} --resource-group {resource_group_name} --settings @./functionapp/settings.json -
Functionsアプリを設定して、Python v2モデルを実行し、.zipデプロイメント後に受け取ったコードでビルドを実行するようにします:
{ "AzureWebJobsFeatureFlags": "EnableWorkerIndexing", "SCM_DO_BUILD_DURING_DEPLOYMENT": true } -
リソースグループ、ストレージコンテナ、および適切な構成のFunctionsアプリがある場合、コードをFunctionsアプリに公開します:
!az functionapp deployment source config-zip -g {resource_group_name} -n {function_app} --src {function_archive} --build-remote true
モデルのテスト
MLモデルをAzure FunctionsにHTTPトリガーとしてデプロイしたため、FunctionsアプリのURLを使用してHTTPリクエストを送信し、関数を呼び出してモデルを実行できます。
入力を準備するために、SageMakerの例のファイルバケットからテスト画像ファイルをダウンロードし、モデルが要求する形式のサンプルセットを準備します:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
test_dataset = datasets.MNIST(root='../data', download=True, train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=True)
test_features, test_labels = next(iter(test_loader))リクエストライブラリを使用して、サンプル入力を推論エンドポイントにPOSTリクエストで送信します。推論エンドポイントの形式は、次のコードに示すようになります:
import requests, json
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
url = f"https://{function_app}.azurewebsites.net/api/classify"
response = requests.post(url,
json.dumps({"data":to_numpy(test_features).tolist()})
)
predictions = json.loads(response.text)['digits']クリーンアップ
モデルのテストが完了したら、リソースグループとそれに含まれるリソース(ストレージコンテナおよびFunctionsアプリを含む)を削除します:
!az group delete --name {resource_group_name} --yesさらに、コストを削減するために、SageMaker Studio内のアイドルリソースをシャットダウンすることをお勧めします。詳細については、「Amazon SageMaker Studio内のアイドルリソースを自動的にシャットダウンしてコストを節約する」を参照してください。
結論
この記事では、SageMakerを使用してMLモデルを構築し、別のクラウドプロバイダーにデプロイする方法を紹介しました。この解決策では、SageMaker Studioのノートブックを使用しましたが、本番のワークロードでは、MLOpsを使用して繰り返し可能なトレーニングワークフローを作成し、モデルの開発とデプロイを加速することをお勧めします。
この記事では、マルチクラウド環境でモデルをデプロイして実行するためのすべての可能な方法を紹介していません。たとえば、モデルをコンテナイメージにパッケージ化し、推論コードと依存ライブラリとともにモデルをコンテナ化アプリケーションとしてどのプラットフォームでも実行することもできます。このアプローチの詳細については、「Amazon CodeCatalystを使用したマルチクラウド環境でのコンテナアプリケーションのデプロイ」を参照してください。この記事は、組織がマルチクラウド環境でAWSのAI/ML機能を活用する方法を示すことを目的としています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「GANやVAEを超えたNLPにおける拡散モデルの探求」
- 「Amazon SageMaker Feature Store Feature Processorを使用して、MLの洞察を解き放つ」
- 「VirtuSwapがAmazon SageMaker StudioのカスタムコンテナとAWS GPUインスタンスを使用して、Pandasベースの取引シミュレーションを加速する方法」
- 「Amazon SageMakerとHugging Faceを使用して、FetchはML処理の遅延を50%削減します」
- 「アジア競技大会、eスポーツがオリンピックの夢に火をつける新たな節目となる」
- 「科学者たちが歴史的なコードを解読し、失われた秘密を明らかにする方法」
- ウェイブは、LINGO-1という新しいAIモデルを開発しましたこのモデルは、運転シーンにコメントをすることができ、質問に対しても回答することができます






