「Amazon SageMakerを使用して、生成AIを使ってパーソナライズされたアバターを作成する」
Using Amazon SageMaker to create personalized avatars with AI generation.
生成AIは、エンターテイメント、広告、グラフィックデザインなど、さまざまな産業で創造的なプロセスを強化し、加速するための共通ツールとなっています。それにより、観客によりパーソナライズされた体験を提供し、最終製品の全体的な品質を向上させることが可能です。
生成AIの一つの重要な利点は、ユーザーに独自でパーソナライズされた体験を提供することです。たとえば、ストリーミングサービスでは、ユーザーの関与を高め、ユーザーの視聴履歴や好みに基づいてタイトルの視覚的な要素を生成するために、生成AIが使用されています。システムは、タイトルのアートワークの数千のバリエーションを生成し、それらをテストしてユーザーの注意を最も引くバージョンを決定します。一部の場合では、TVシリーズのためのパーソナライズされたアートワークは、パーソナライズされていないアートワークを持つ番組と比較して、クリックスルー率と視聴率を大幅に向上させました。
この記事では、Amazon SageMakerを使用してStable Diffusionなどの生成AIモデルを使用して、パーソナライズされたアバターソリューションを構築し、同時に推論コストを節約する方法を示します。このソリューションでは、自分自身の10〜12枚の画像をアップロードすることにより、任意のテキストプロンプトに基づいてアバターを生成することができるパーソナライズされたモデルを微調整する方法を示します。この例ではパーソナライズされたアバターが生成されますが、特定のオブジェクトやスタイルに微調整することで、このテクニックを他の創造的なアート生成にも適用することができます。
 |
ソリューションの概要
以下のアーキテクチャ図は、アバタージェネレーターのエンドツーエンドソリューションを示しています。
- メタは、AIを活用した「パーソナ」と呼ばれる機能を自社サービスに統合する予定です
- 「MITのPhotoGuardは、AI画像操作に対抗するためにAIを使用します」
- 「アジア太平洋地域でAIスタートアップを創出する女性のための新たなファンド」
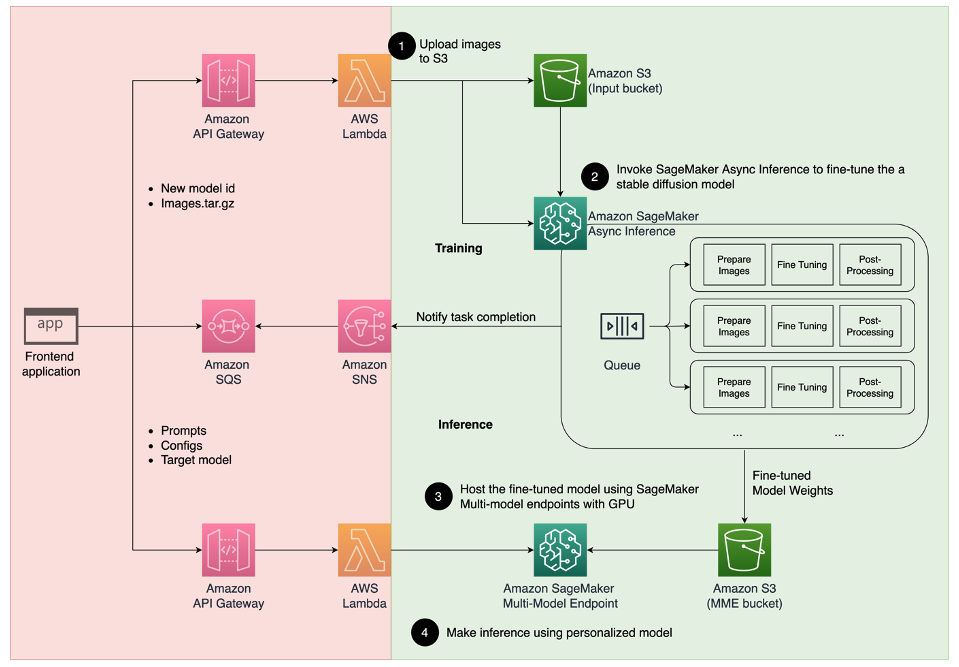
この記事と提供するサンプルのGitHubコードでは、モデルのトレーニングと推論のオーケストレーション(前の図の緑色のセクション)に焦点を当てています。完全なソリューションアーキテクチャを参照し、提供する例の上に構築することができます。
モデルのトレーニングと推論は、以下の4つのステップに分けることができます:
- Amazon Simple Storage Service(Amazon S3)に画像をアップロードします。このステップでは、自分自身の高解像度の画像を少なくとも10枚提供してもらいます。画像が多いほど結果はよくなりますが、トレーニングにかかる時間も長くなります。
- SageMaker非同期推論を使用してStable Diffusion 2.1ベースモデルを微調整します。なぜ推論エンドポイントをトレーニングに使用するのかについては、この記事の後半で説明します。微調整プロセスは、画像の準備から始まり、顔の切り取り、背景の変化、モデルへのリサイズなどを行います。次に、大規模言語モデル(LLM)のためのパラメータ効率の良い微調整テクニックであるLow-Rank Adaptation(LoRA)を使用してモデルを微調整します。最後に、ポストプロセッシングでは、微調整されたLoRAの重みを推論スクリプトと設定ファイル(tar.gz)と一緒にパッケージ化し、SageMaker MMEのS3バケットの場所にアップロードします。
- SageMaker MMEを使用して微調整されたモデルをホストします。SageMakerは、各モデルへの推論トラフィックに基づいて、Amazon S3の場所からモデルを動的にロードしキャッシュします。
- 微調整されたモデルを推論に使用します。微調整の完了を示すAmazon Simple Notification Service(Amazon SNS)の通知が送信された後、アバターを作成するためにMMEを呼び出す際に
target_modelパラメーターを指定することで、直ちにそのモデルを使用することができます。
各ステップについて詳しく説明し、いくつかのサンプルコードスニペットを説明します。
画像の準備
自分自身のイメージの画像を生成するために、Stable Diffusionを微調整するためには、通常、さまざまな角度から、さまざまな表情、さまざまな背景で、自分自身の大量で多様な写真を提供する必要があります。しかし、私たちの実装では、10枚の入力画像でも高品質の結果を得ることができます。また、各写真から自分自身の顔を自動的に抽出するための自動前処理も追加しました。複数の視点から自分自身の外観の本質を明確に捉える必要があります。正面からの写真、各側面からのプロフィール写真、およびその間の角度からの写真を含める必要があります。また、笑顔、しかめ面、中立的な表情など、さまざまな表情の写真も含める必要があります。さまざまな表情を持つことで、モデルはあなたの個性的な顔の特徴をより正確に再現することができます。入力画像は、生成するアバターの品質を決定します。これが適切に行われるようにするために、ユーザーが画像のキャプチャとアップロードのプロセスを案内する直感的なフロントエンドUI体験をお勧めします。
以下は、異なる角度と表情のさまざまなセルフィー画像の例です。

安定した拡散モデルを微調整する
画像がAmazon S3にアップロードされた後、SageMaker非同期推論エンドポイントを呼び出してトレーニングプロセスを開始できます。非同期エンドポイントは、ペイロードが大きい(最大1 GB)および処理時間が長い(最大1時間)推論ユースケースに対応しています。また、リクエストをキューに入れる組み込みのキューイングメカニズムや、Amazon SNSを介したタスク完了通知メカニズムなど、SageMakerホスティングの他のネイティブ機能も提供しています。
微調整は推論ユースケースではありませんが、ここではSageMakerトレーニングジョブの代わりに利用することを選択しました。これは、組み込みのキューイングと通知メカニズム、および管理された自動スケーリング(サービスが使用されていない場合には0インスタンスまでスケールダウンする能力を含む)を備えているためです。これにより、簡単に大量の同時ユーザーに対して微調整サービスをスケーリングでき、追加のコンポーネントの実装と管理の必要性がなくなります。ただし、1 GBのペイロードと1時間の最大処理時間の制約があります。テストでは、ml.g5.2xlargeインスタンス上で約10枚の入力画像で20分の時間が十分で、合理的な結果が得られることがわかりました。ただし、より大規模な微調整ジョブの場合は、SageMakerトレーニングが推奨されます。
非同期エンドポイントをホストするには、いくつかの手順を完了する必要があります。最初の手順は、モデルサーバーを定義することです。この記事では、Large Model Inference Container(LMI)を使用します。LMIは、高性能でプログラミング言語に依存しないモデルサービングソリューションであるDJL Servingによって提供されています。SageMaker管理型推論コンテナには、Hugging Face DiffusersやAccelerateなどの多くのトレーニングライブラリがすでに備わっているため、このオプションを選択しました。これにより、微調整ジョブにカスタマイズするための作業量が大幅に削減されます。
次のコードスニペットは、例で使用したLMIコンテナのバージョンを示しています:
inference_image_uri = (
f"763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117"
)
print(f"使用されるイメージは ---- > {inference_image_uri}")さらに、推論エンジンの使用、モデルアーティファクトの場所、ダイナミックバッチングなどのサービングプロパティを設定するserving.propertiesファイルを用意する必要があります。最後に、モデルを推論エンジンにロードし、モデルのデータ入力と出力を準備するmodel.pyファイルが必要です。この例では、model.pyファイルを使用して微調整ジョブを開始しますが、詳細については後のセクションで説明します。serving.propertiesファイルとmodel.pyファイルは、training_serviceフォルダに用意されています。
モデルサーバーを定義した後の次のステップは、非同期推論がどのように提供されるかを定義するエンドポイント構成を作成することです。この例では、最大同時呼び出し制限と出力S3の場所のみを定義しています。ml.g5.2xlargeインスタンスでは、メモリ不足(OOM)例外が発生せずに最大2つのモデルを同時に微調整できることがわかっているため、max_concurrent_invocations_per_instanceを2に設定しています。この数値は、異なる調整パラメータセットや小さなインスタンスタイプを使用する場合に調整する必要があります。Amazon CloudWatchでGPUメモリの使用状況を監視し、最初に1に設定することをおすすめします。
# 非同期エンドポイント構成を作成する
async_config = AsyncInferenceConfig(
output_path=f"s3://{bucket}/{s3_prefix}/async_inference/output" , # 結果の保存先
max_concurrent_invocations_per_instance=2,
notification_config={
"SuccessTopic": "...",
"ErrorTopic": "...",
}, # 通知の設定
)最後に、SageMakerモデルを作成し、コンテナ情報、モデルファイル、AWS Identity and Access Management(IAM)ロールを1つのオブジェクトにパッケージ化します。モデルは、前に定義したエンドポイント構成を使用して展開されます:
モデル = Model(
image_uri=image_uri,
model_data=model_data,
role=role,
env=env
)
モデル.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
async_inference_config=async_inference_config
)
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session
)エンドポイントが準備できたら、次のサンプルコードを使用して非同期エンドポイントを呼び出し、ファインチューニングプロセスを開始します:
sm_runtime = boto3.client("sagemaker-runtime")
input_s3_loc = sess.upload_data("data/jw.tar.gz", bucket, s3_prefix)
response = sm_runtime.invoke_endpoint_async(
EndpointName=sd_tuning.endpoint_name,
InputLocation=input_s3_loc)SageMakerでLMIについての詳細は、「DJLServingおよびDeepSpeedモデルパラレル推論を使用したAmazon SageMakerでの大規模モデルの展開」を参照してください。
呼び出し後、非同期エンドポイントはファインチューニングジョブをキューに入れます。各ジョブは次の手順を実行します:画像の準備、DreamboothおよびLoRAのファインチューニング、モデルアーティファクトの準備。ファインチューニングプロセスについて詳しく説明します。
画像の準備
前述のように、入力画像の品質はファインチューニングモデルの品質に直接影響を与えます。アバターの場合、モデルは顔の特徴に焦点を当てる必要があります。ユーザーに厳選されたサイズと内容の画像を提供することを要求する代わりに、コンピュータビジョンの技術を使用してこの負担を軽減する前処理ステップを実装します。前処理ステップでは、まず顔検出モデルを使用して各画像の最大の顔を分離します。次に、モデルに必要なサイズ(512 x 512ピクセル)に画像をトリミングおよびパディングします。最後に、顔を背景から分離し、ランダムな背景変動を追加します。これにより、背景ではなく顔自体からモデルが学習できるようになり、顔の特徴を強調することができます。次の画像は、このプロセスの3つのステップを示しています。
 |
 |
 |
| ステップ1: コンピュータビジョンを使用した顔検出 | ステップ2: 512 x 512ピクセルにトリミングおよびパディング | ステップ3(オプション): セグメント化および背景変動の追加 |
DreamboothおよびLoRAのファインチューニング
ファインチューニングでは、DreamboothとLoRAの技術を組み合わせています。Dreamboothでは、ユニークな識別子を使用して安定した拡散モデルを個別にカスタマイズし、モデルの出力ドメインに主体を埋め込み、モデルの言語ビジョン辞書を拡張します。モデルは、主体のクラス(この場合は人)の意味的な知識を保持するための事前保存という方法を使用して、クラス内の他のオブジェクトを使用して最終的な画像出力を改善します。これにより、Dreamboothは、主体のわずかな入力画像で高品質の結果を実現することができます。
次のコードスニペットは、アバターソリューションのtrainer.pyクラスへの入力を示しています。ユニークな識別子として<<TOK>>を選択しました。これは、モデルの辞書にすでに存在する可能性のある名前を選択しないようにするためです。名前が既に存在する場合、モデルは主体を忘れて再学習する必要があり、ファインチューニングの結果が悪くなる可能性があります。主体クラスは“a photo of person”に設定されており、これにより、ファインチューニングプロセス中に追加の入力として人の写真を生成して供給することができます。これにより、モデルは事前保存方法を使用して、人物の前の知識を保持しようとする際の過学習を減らすのに役立ちます。
status = trn.run(base_model="stabilityai/stable-diffusion-2-1-base",
resolution=512,
n_steps=1000,
concept_prompt="<<TOK>>の写真", # <<対象の一意の識別子
learning_rate=1e-4,
gradient_accumulation=1,
fp16=True,
use_8bit_adam=True,
gradient_checkpointing=True,
train_text_encoder=True,
with_prior_preservation=True,
prior_loss_weight=1.0,
class_prompt="人の写真", # <<対象クラス
num_class_images=50,
class_data_dir=class_data_dir,
lora_r=128,
lora_alpha=1,
lora_bias="none",
lora_dropout=0.05,
lora_text_encoder_r=64,
lora_text_encoder_alpha=1,
lora_text_encoder_bias="none",
lora_text_encoder_dropout=0.05
)構成でメモリを節約するために、fp16、use_8bit_adam、およびgradient accumulationのオプションが有効になっています。これにより、メモリの使用量が12 GB未満になり、ml.g5.2xlargeインスタンスで最大2つのモデルを同時に微調整することが可能です。
LoRAは、事前学習済みLLMのほとんどの重みを固定し、小さなアダプターネットワークを事前学習済みLLMの特定のレイヤーに接続する効率的な微調整技術です。Stable Diffusionでは、アダプターは推論パイプラインのテキストエンコーダーとU-Netコンポーネントに接続されます。テキストエンコーダーは入力プロンプトをU-Netモデルが理解できる潜在空間に変換し、U-Netモデルは潜在的な意味を使用して次の拡散プロセスで画像を生成します。微調整の出力は、text_encoderとU-Netアダプターの重みだけです。推論時には、これらの重みを基本のStable Diffusionモデルに再接続して、微調整の結果を再現することができます。
以下の図は、元の著者であるCheng-Han Chiang、Yung-Sung Chuang、Hung-yi Leeの提供するLoRA微調整の詳細図です。「AACL_2022_tutorial_PLMs」、2022年
 |
 |
両方の方法を組み合わせることで、パラメータの数を桁違いに減らしながら個別のモデルを生成することができました。これにより、トレーニング時間が大幅に短縮され、GPUの利用率が低下しました。また、アダプターの重みのサイズはわずか70 MBであり、完全なStable Diffusionモデルの6 GBに比べて99%のサイズ削減が実現されました。
モデルアーティファクトの準備
微調整が完了したら、後処理のステップでLoRAの重みをNVIDIA Tritonの他のモデルサービングファイルとともにTARします。Pythonのバックエンドを使用しているため、Tritonの設定ファイルと推論に使用されるPythonスクリプトが必要です。ただし、Pythonスクリプトの名前はmodel.pyである必要があります。最終的なモデルTARファイルのファイル構造は以下のようになります:
|--sd_lora
|--config.pbtxt
|--1\
|--model.py
|--output #LoRAの重み
|--text_encoder\
|--unet\
|--train.shGPUを使用したSageMaker MMEを使用して微調整されたモデルをホストする
モデルが微調整された後、SageMaker MMEを使用してパーソナライズされたStable Diffusionモデルをホストします。SageMaker MMEは、単一のエンドポイントの背後に複数のモデルを1つのコンテナでホストする強力なデプロイメント機能です。トラフィックとルーティングを自動的に管理し、リソースの利用を最適化し、コストを節約し、数千のエンドポイントを管理する操作の負荷を最小化します。この例では、GPUインスタンスで実行し、SageMaker MMEはTriton Serverを使用してGPUをサポートしています。これにより、単一のGPUデバイスで複数のモデルを実行し、高速な計算を活用することができます。SageMaker MMEでStable Diffusionをホストする方法の詳細については、「Amazon SageMakerを使用して高品質の画像を安価に生成するStable Diffusionモデルを作成する」を参照してください。
例えば、コールドスタートの状況下でファインチューニングされたモデルを高速にロードするために、追加の最適化を行いました。これは、LoRAのアダプタ設計のおかげです。ベースモデルの重みとConda環境はすべてのファインチューニングされたモデルで同じですので、これらの共通のリソースをホスティングコンテナに事前にロードして共有することができます。これにより、Tritonの設定ファイル、Pythonバックエンド(model.py)、およびLoRAアダプタの重みだけが最初の呼び出し後にAmazon S3から動的にロードされます。以下の図は、並べて比較したものです。

これにより、モデルのTARファイルのサイズが約6GBから70MBに大幅に削減され、ロードと展開がはるかに高速になります。この例では、事前ロードを行うために、models/model_setupにユーティリティPythonバックエンドモデルを作成しました。スクリプトでは単純にベースのStable DiffusionモデルとConda環境をAmazon S3から共有するための共通の場所にコピーします。以下は、このタスクを実行するコードの一部です:
def initialize(self, args):
#conda env setup
self.conda_pack_path = Path(args['model_repository']) / "sd_env.tar.gz"
self.conda_target_path = Path("/tmp/conda")
self.conda_env_path = self.conda_target_path / "sd_env.tar.gz"
if not self.conda_env_path.exists():
self.conda_env_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy(self.conda_pack_path, self.conda_env_path)
#base diffusion model setup
self.base_model_path = Path(args['model_repository']) / "stable_diff.tar.gz"
try:
with tarfile.open(self.base_model_path) as tar:
tar.extractall('/tmp')
self.response_message = "Model env setup successful."
except Exception as e:
# print the exception message
print(f"Caught an exception: {e}")
self.response_message = f"Caught an exception: {e}"その後、各ファインチューニングされたモデルは、コンテナ上の共有の場所を指すようになります。Conda環境はconfig.pbtxtで参照されます。
name: "pipeline_0"
backend: "python"
max_batch_size: 1
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "/tmp/conda/sd_env.tar.gz"}
}Stable Diffusionベースモデルは、各model.pyファイルのinitialize()関数からロードされます。その後、パーソナライズされたLoRAの重みをunetとtext_encoderモデルに適用して、各ファインチューニングされたモデルを再現します:
...
class TritonPythonModel:
def initialize(self, args):
self.output_dtype = pb_utils.triton_string_to_numpy(
pb_utils.get_output_config_by_name(json.loads(args["model_config"]),
"generated_image")["data_type"])
self.model_dir = args['model_repository']
device='cuda'
self.pipe = StableDiffusionPipeline.from_pretrained('/tmp/stable_diff',
torch_dtype=torch.float16,
revision="fp16").to(device)
# Load the LoRA weights
self.pipe.unet = PeftModel.from_pretrained(self.pipe.unet, unet_sub_dir)
if os.path.exists(text_encoder_sub_dir):
self.pipe.text_encoder = PeftModel.from_pretrained(self.pipe.text_encoder, text_encoder_sub_dir)ファインチューニングされたモデルを推論に使用する
MMEエンドポイントを呼び出すことで、ファインチューニングされたモデルを試すことができます。例では、prompt、negative_prompt、gen_argsを公開した入力パラメータを使用しています。以下のコードスニペットに示すように、各入力アイテムのデータ型と形状を辞書に設定し、それらをJSON文字列に変換します。最後に、文字列ペイロードとTargetModelをリクエストに渡してアバター画像を生成します。
import random
prompt = """<<TOK>> epic portrait, zoomed out, blurred background cityscape, bokeh,
perfect symmetry, by artgem, artstation ,concept art,cinematic lighting, highly
detailed, octane, concept art, sharp focus, rockstar games, post processing,
picture of the day, ambient lighting, epic composition"""
negative_prompt = """
beard, goatee, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred,
watermark, grainy, signature, cut off, draft, amateur, multiple, gross, weird, uneven, furnishing, decorating, decoration, furniture, text, poor, low, basic, worst, juvenile,
unprofessional, failure, crayon, oil, label, thousand hands
"""
seed = random.randint(1, 1000000000)
gen_args = json.dumps(dict(num_inference_steps=50, guidance_scale=7, seed=seed))
inputs = dict(prompt = prompt,
negative_prompt = negative_prompt,
gen_args = gen_args)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_lora.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
original_image = decode_image(output[0]["data"][0])
original_imageクリーンアップ
この投稿の一部として提供されたリソースを削除するために、ノートブックのクリーンアップセクションの手順に従ってください。インファレンスインスタンスのコストに関する詳細については、Amazon SageMakerの料金に関する情報を参照してください。
結論
この投稿では、SageMakerで安定したディフュージョンを使用してパーソナライズされたアバターソリューションを作成する方法を示しました。わずかな画像で事前学習済みモデルを微調整することで、各ユーザーの個性と人格を反映したアバターを生成することができます。これは、ジェネレーティブAIを使用してユーザーにカスタマイズされたユニークなエクスペリエンスを提供する方法の一例にすぎません。可能性は無限であり、この技術を試して創造的なプロセスを向上させるための可能性を探求することをお勧めします。この投稿が有益で刺激的であったことを願っています。ソーシャルプラットフォームでハッシュタグ #sagemaker #mme #genai を使用して、例を試して作成物を共有することをお勧めします。私たちはあなたの作品を拝見することを楽しみにしています。
Stable Diffusionに加えて、Amazon SageMaker JumpStartには他の多くのジェネレーティブAIモデルが利用可能です。その機能を探索するには、Amazon SageMaker JumpStartの入門ガイドを参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「デリー政府、提案された電子都市にAIハブを建設する計画」
- 2023年6月のVoAGIトップ投稿:GPT4Allは、あなたのドキュメント用のローカルチャットGPTであり、無料です!
- 創造力を解き放つ:ジェネレーティブAIとAmazon SageMakerがビジネスを支援し、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
- 「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
- 「AIの創造性の測定」 AIの創造性を測定する
- 「アルゴリズムを使用して数千件の患者請求を不適切に拒否した」として、シグナが告発されました
- 「巨大な望遠鏡が知能化されたメンテナンスロボットを採用」






