「Amazon SageMaker StudioでAmazon SageMaker JumpStartを使用して安定したDiffusion XLを利用する」
Using Amazon SageMaker Studio and Amazon SageMaker JumpStart for stable Diffusion XL
今日は、Stability AIから最新の画像生成モデルであるStable Diffusion XL 1.0(SDXL 1.0)がAmazon SageMaker JumpStartを通じて顧客に提供されることをお知らせします。SDXL 1.0の強化機能には、さまざまなアスペクト比でのネイティブな1024ピクセル画像生成が含まれています。これはプロフェッショナルな使用を想定しており、高解像度の写真のような写実的な画像に調整されています。SDXL 1.0は、マーケティング、デザイン、画像生成など、さまざまな業界の使用ケースで使用できる事前設定済みのアートスタイルを提供しています。これらのモデルを簡単に試して、SageMaker JumpStartと組み合わせて使用することができます。SageMaker JumpStartは、アルゴリズム、モデル、および機械学習(ML)ソリューションへのアクセスを提供するMLハブであり、迅速にMLを開始することができます。
この記事では、SageMaker JumpStartを介してSDXL 1.0モデルを使用する方法について説明します。
Stable Diffusion XL 1.0(SDXL 1.0)とは何ですか
SDXL 1.0は、画像のための生成的AIの進化です。SDXLは、写実主義を含むさまざまなアートスタイルで複雑な概念を持つ見事な画像を生成することができます。これは、現在利用可能な最高の画像モデルを超える品質レベルでの生成が可能です。オリジナルのStable Diffusionシリーズと同様に、SDXLは高度にカスタマイズ可能であり(パラメータに関して)、Amazon SageMakerインスタンスに展開することができます。
次の画像は、この記事の後半で詳しく説明する簡単なプロンプトを使用してSDXL 1.0を使用して生成されたライオンの画像です。
- 「AIによる完全自律戦争の未来がここにある」
- 「コヒアーがコーラルを導入:最も戦略的なチームの生産性向上を目指す企業向けの知識アシスタント」
- AWS Inferentia2を使用して、安定したディフュージョンのパフォーマンスを最大化し、推論コストを低減します

SDXL 1.0モデルには、次のハイライトが含まれています:
- 表現の自由 – 最高品質の写真写実主義だけでなく、ほとんどすべてのアートスタイルで高品質なアートを生成する能力。モデルによって与えられる特定の感触がなく、スタイルの絶対的な自由を保証します。
- 芸術的知性 – 画像モデルにとって難解なコンセプト(例:手とテキスト、または空間的に配置されたオブジェクトと人々)を生成する能力が最高クラスです。
- シンプルなプロンプティング – 他の生成的画像モデルとは異なり、SDXLではわずか数語で複雑で詳細で美しい画像を作成することができます。長い修飾文は不要です。
- より正確な生成 – SDXLのプロンプティングは単純だけでなく、プロンプトの意図に忠実です。SDXLの改良されたCLIPモデルはテキストを非常に効果的に理解するため、「The Red Square」と「a red square」などの概念を区別できます。この正確さにより、高度な機能や安定拡散の有名な微調整を使用する前に、テキストから直接完璧な画像を作成するためにさらに多くの作業を行うことができます。
SageMaker JumpStartとは何ですか
SageMaker JumpStartでは、MLプラクティショナーはコンテンツ作成、画像生成、コード生成、質問応答、コピーライティング、要約、分類、情報検索などのユースケースに適した最新のモデルを幅広く選択することができます。MLプラクティショナーは、ネットワーク隔離された環境から専用のSageMakerインスタンスに基盤モデルを展開し、SageMakerを使用してモデルのトレーニングと展開をカスタマイズすることができます。SDXLモデルは現在Amazon SageMaker Studioで検索可能であり、この記事の執筆時点では、us-east-1、us-east-2、us-west-2、eu-west-1、ap-northeast-1、ap-southeast-2リージョンで利用可能です。
ソリューションの概要
この記事では、SDXL 1.0をSageMakerに展開し、テキストから画像、画像から画像までのプロンプトを使用して画像を生成する方法を紹介します。
SageMaker Studioは、MLのためのWebベースの統合開発環境(IDE)であり、MLモデルの構築、トレーニング、デバッグ、展開、モニタリングを行うことができます。SageMaker Studioの開始方法や設定方法の詳細については、Amazon SageMaker Studioを参照してください。
Once you are in the SageMaker Studio UI, access SageMaker JumpStart and search for Stable Diffusion XL. Choose the SDXL 1.0 model card, which will open up an example notebook. This means you will be only be responsible for compute costs. There is no associated model cost. Closed weight SDXL 1.0 offers SageMaker optimized scripts and container with faster inference time and can be run on smaller instance compared to the open weight SDXL 1.0. The example notebook will walk you through steps, but we also discuss how to discover and deploy the model later in this post.
In the following sections, we show how you can use SDXL 1.0 to create photorealistic images with shorter prompts and generate text within images. Stable Diffusion XL 1.0 offers enhanced image composition and face generation with stunning visuals and realistic aesthetics.
Stable Diffusion XL 1.0 パラメータ
以下はSXDL 1.0で使用されるパラメータです:
- cfg_scale – ダイフュージョンプロセスがプロンプトテキストにどれだけ厳密に従うか。
- height and width – 画像の高さと幅(ピクセル単位)。
- steps – 実行するダイフュージョンステップの数。
- seed – ランダムノイズのシード。シードが提供されると、生成された画像は決定論的になります。
- sampler – ダイフュージョンプロセスに使用するサンプラー。
- text_prompts – 生成に使用するテキストプロンプトの配列。
- weight – 各プロンプトに特定の重みを与える
詳細については、Stability AIのテキストから画像へのドキュメンテーションを参照してください。
以下のコードは、プロンプトとともに提供される入力データのサンプルです:
{
"cfg_scale": 7,
"height": 1024,
"width": 1024,
"steps": 50,
"seed": 42,
"sampler": "K_DPMPP_2M",
"text_prompts": [
{
"text": "新鮮なバジルとトマトをのせたピザの写真、伝統的なオーブンで焼いたもの",
"weight": 1
}
]
}このポストのすべての例は、Stability Diffusion XL 1.0のサンプルノートブックに基づいています。Stability AIのGitHubリポジトリで見つけることができます。
SDXL 1.0を使用して画像を生成する
以下の例では、Stability Diffusion XL 1.0モデルの機能に焦点を当てています。優れた写真のリアリズム、強化された画像構成、現実的な顔の生成能力について説明します。また、大幅に改善されたビジュアルエステティックスについても探求します。さらに、短いプロンプトの使用により、より簡単に記述的なイメージを作成することができます。最後に、画像内のテキストがより読みやすくなり、生成されたコンテンツの全体的な品質をさらに高めることを示します。
以下の例は、簡単なプロンプトを使用して詳細な画像を取得する方法を示しています。プロンプトの数語だけを使用して、提供されたプロンプトに似た、複雑で詳細な美しい画像を作成することができました。
text = "猫のラテアートの写真"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
seed=5,
height=640,
width=1536,
sampler="DDIM",
))
decode_and_show(output)
次に、SDXL 1.0でのみ使用可能なstyle_preset入力パラメータの使用方法を示します。 style_presetパラメータを渡すことで、画像生成モデルを特定のスタイルに導くことができます。
利用可能なstyle_presetパラメータの一部はenhance、anime、photographic、digital-art、comic-book、fantasy-art、line-art、analog-film、neon-punk、isometric、low-poly、origami、modeling-compound、cinematic、3d-mode、pixel-art、tile-textureです。スタイルプリセットのリストは変更される可能性があります。最新のリリースとドキュメントを参照してください。
この例では、style_presetをorigamiとして指定してティーポットを生成するためにプロンプトを使用します。提供されたアートスタイルで高品質な画像を生成することができました。
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text="teapot")],
style_preset="origami",
seed = 3,
height = 1024,
width = 1024
))
さらに異なるプロンプトを使用していくつかのスタイルプリセットを試してみましょう。次の例では、「portrait of an old and tired lion real pose」というプロンプトでstyle_preset="photographic"のスタイルプリセットを使用して肖像生成を行います。
text = "portrait of an old and tired lion real pose"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))
次に、同じプロンプト(「portrait of an old and tired lion real pose」)をスタイルプリセットとしてモデリングコンパウンドを使用してみましょう。出力される画像は、モデルによって与えられる特定の感触を持たない、絶対的なスタイルの自由を保証する独自の画像です。

SDXL 1.0でのマルチプロンプティング
これまで見てきたように、モデルの核心的な基盤の一つは、プロンプトを使用して画像を生成する能力です。SDXL 1.0では、マルチプロンプティングがサポートされています。マルチプロンプティングでは、各プロンプトに特定の重みを割り当てることで、概念を組み合わせることができます。以下の生成された画像を見ると、ジャングルの背景に背の高い明るい緑色の草が描かれています。この画像は、以下のプロンプトを使用して生成されました。これを以前の単一のプロンプトと比較することができます。
text1 = "portrait of an old and tired lion real pose"
text2 = "jungle with tall bright green grass"
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text1),
TextPrompt(text=text2, weight=0.7)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))
空間認識生成画像とネガティブプロンプト
次に、詳細なプロンプトを使用したポスターデザインを見てみましょう。先ほど見たように、マルチプロンプティングを使用すると、概念を組み合わせて新しいユニークな結果を作り出すことができます。
この例では、対象の位置、外見、期待、周囲について非常に詳細なプロンプトです。また、ネガティブプロンプトの助けを借りて、歪んだ画像や不完全にレンダリングされた画像を避けようとしています。生成された画像は、空間に配置されたオブジェクトや被写体を示しています。
text = “A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. But in the reflection, the cat sees not itself, but a mighty lion. The mirror illuminated with a soft glow against a pure white background.”
text = "A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. But in the reflection, the cat sees not itself, but a mighty lion. The mirror illuminated with a soft glow against a pure white background."
negative_prompts = ['distorted cat features', 'distorted lion features', 'poorly rendered']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="enhance",
seed=43,
height=640,
width=1536,
steps=100,
cfg_scale=7,
negative_prompts=negative_prompts
))
別の例を試してみましょう。同じネガティブプロンプトを保ちながら、詳細なプロンプトとスタイルプリセットを変更します。生成された画像は、オーナメントの施された金の鏡と主体の反射などの詳細にも注意を払いながら、オブジェクトを空間的に配置するだけでなく、スタイルプリセットも変更されています。
text = "キュートでふわふわの白い猫が後ろ足で立ち、オーナメントの施された金の鏡を興味深そうにのぞき込んでいます。反射の中で、猫は自分自身を見ています。"
negative_prompts = ['歪んだ猫の特徴', '歪んだライオンの特徴', '下手に描かれた']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="ネオンパンク",
seed=4343434,
height=640,
width=1536,
steps=150,
cfg_scale=7,
negative_prompts=negative_prompts
))
SDXL 1.0を使用した顔生成
この例では、SDXL 1.0が手と指などのリアルな特徴を持つ画像コンポジションと顔生成を作成する方法を示しています。生成された画像は、明らかに上げられた手を持つAIによって作成された人物像です。指の細部やポーズに注目してください。このようなAIによる生成画像は、本来は非具体的であったでしょう。
text = "手を上げた老人の写真、本物のポーズ。"
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="写真的",
seed=11111,
height=640,
width=1536,
steps=100,
cfg_scale=7,
))
SDXL 1.0を使用したテキスト生成
SDXLは、イメージ内のテキスト生成を含む複雑なイメージデザインワークフローに最適化されています。この例では、この機能を紹介します。SDXLを使用したテキスト生成のクリアさに注目してください。スタイルプリセットは映画的です。
text = "次の単語を書いてください:夢"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="映画的",
seed=15,
height=640,
width=1536,
sampler="DDIM",
steps=32,
))
SageMaker JumpStartからSDXL 1.0を見つける
SageMaker JumpStartは、アクセス、カスタマイズ、およびMLライフサイクルに統合するための基盤モデルをオンボードします。一部のモデルは、モデルの重みやスクリプトにアクセスして変更できるオープンウェイトモデルであり、一部はモデルプロバイダーのIPを保護するためにアクセスできないクローズドウェイトモデルです。クローズドウェイトモデルを使用するには、AWS Marketplaceモデル詳細ページからモデルにサブスクライブする必要があります。現時点ではSDXL 1.0はクローズドウェイトモデルです。このセクションでは、SageMaker Studioからクローズドウェイトモデルを発見、サブスクライブ、デプロイする方法について説明します。
SageMaker Studioのホームページで、Prebuilt and automated solutionsの下のJumpStartを選択してSageMaker JumpStartにアクセスできます。
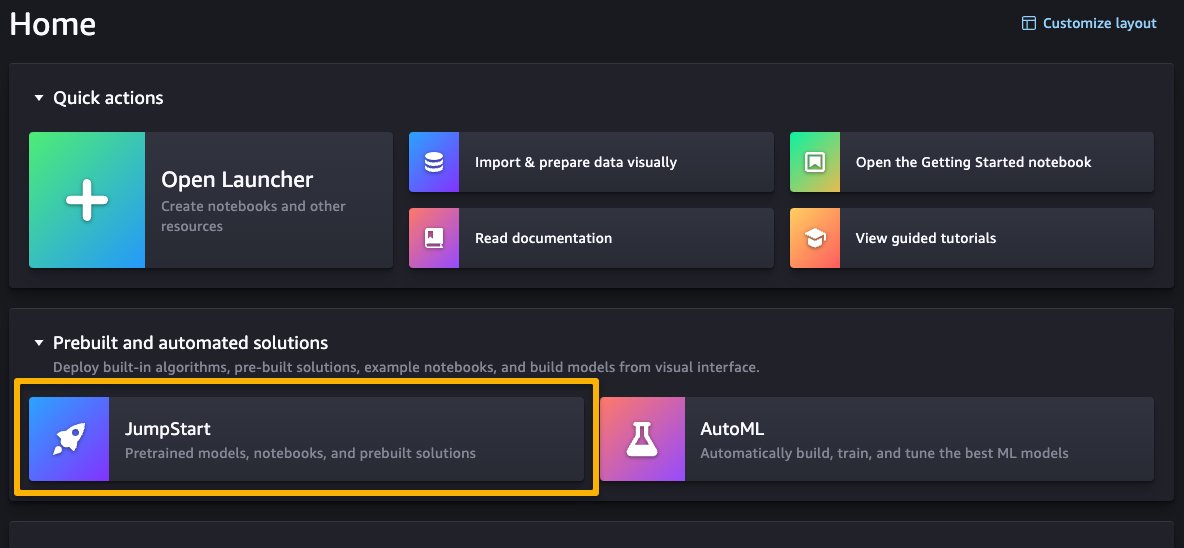
SageMaker JumpStartのランディングページから、ソリューション、モデル、ノートブック、その他のリソースを閲覧することができます。以下のスクリーンショットは、ソリューションと基礎モデルが一覧表示されたランディングページの例です。
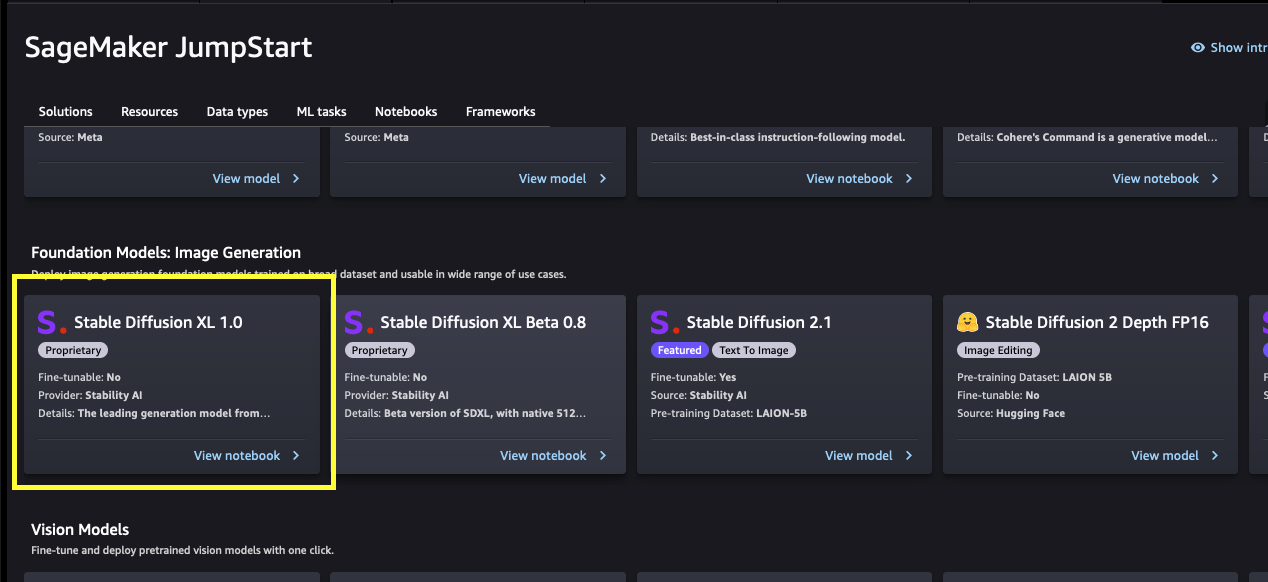
各モデルには、以下のスクリーンショットに示されるモデルカードがあります。モデルカードには、モデル名、ファインチューニングが可能かどうか、プロバイダ名、モデルについての短い説明が含まれています。Stable Diffusion XL 1.0モデルは、Foundation Model: Image Generationのカルーセル内にあるか、検索ボックスで検索することで見つけることができます。
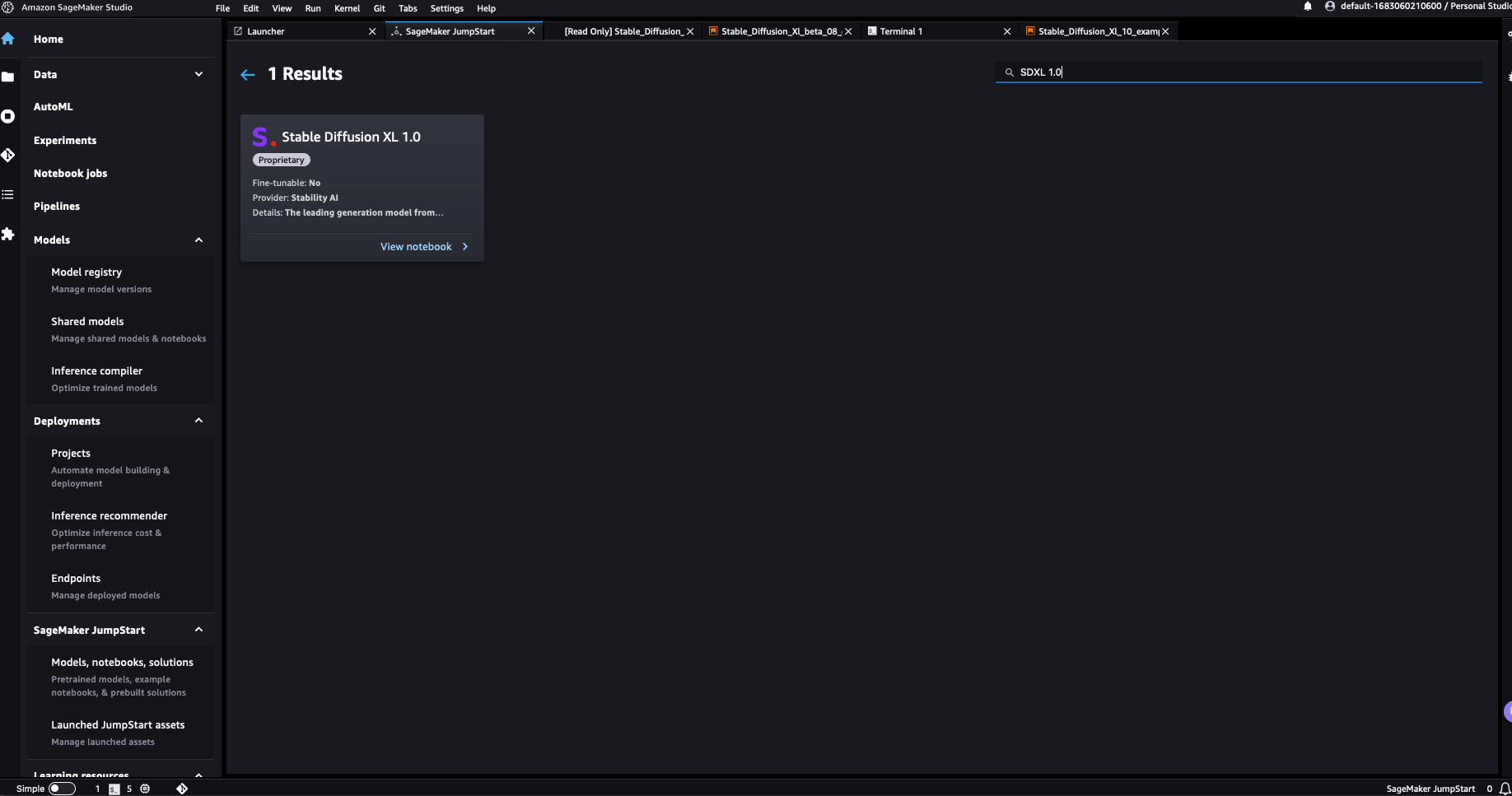
Stable Diffusion XL 1.0を選択すると、SDXL 1.0モデルの使用方法を説明するサンプルノートブックが開きます。サンプルノートブックは読み取り専用モードで開かれるため、実行するにはノートブックのインポートを選択する必要があります。

ノートブックをインポートした後、コードを実行する前に適切なノートブック環境(イメージ、カーネル、インスタンスタイプなど)を選択する必要があります。
SageMaker JumpStartからSDXL 1.0をデプロイする
このセクションでは、モデルの購読とデプロイの手順を説明します。
- サンプルノートブック内のリンクを使用して、AWS Marketplaceのモデルリストページを開きます。
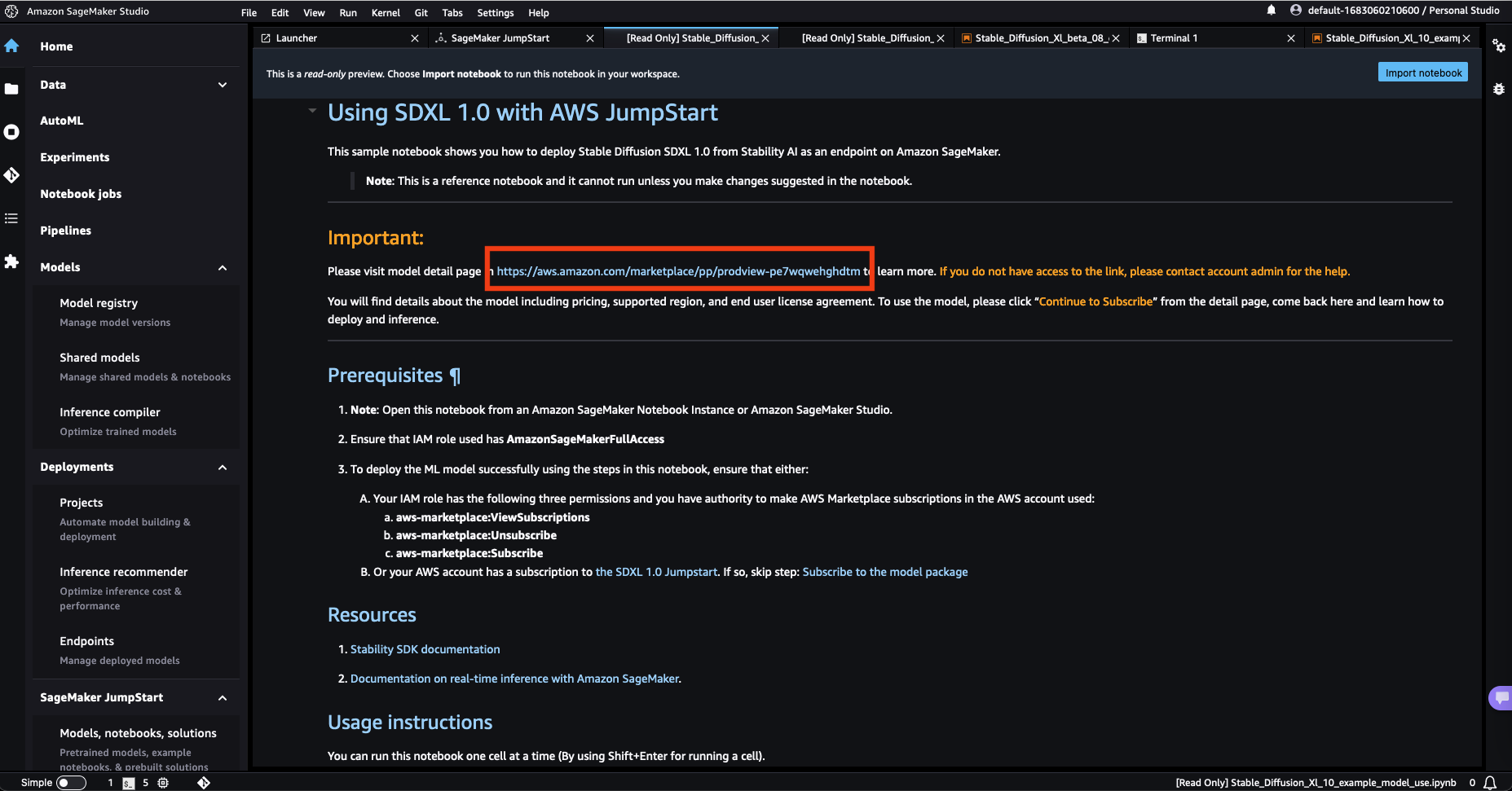
- AWS Marketplaceのリストで、Continue to subscribeを選択します。
モデルを表示または購読するための必要な権限がない場合は、AWS管理者または調達担当者に連絡してください。多くの企業では、AWS Marketplaceの権限を制限して、AWS Marketplace管理ポータルで実行できるアクションを制御しています。
- Continue to Subscribeを選択します。
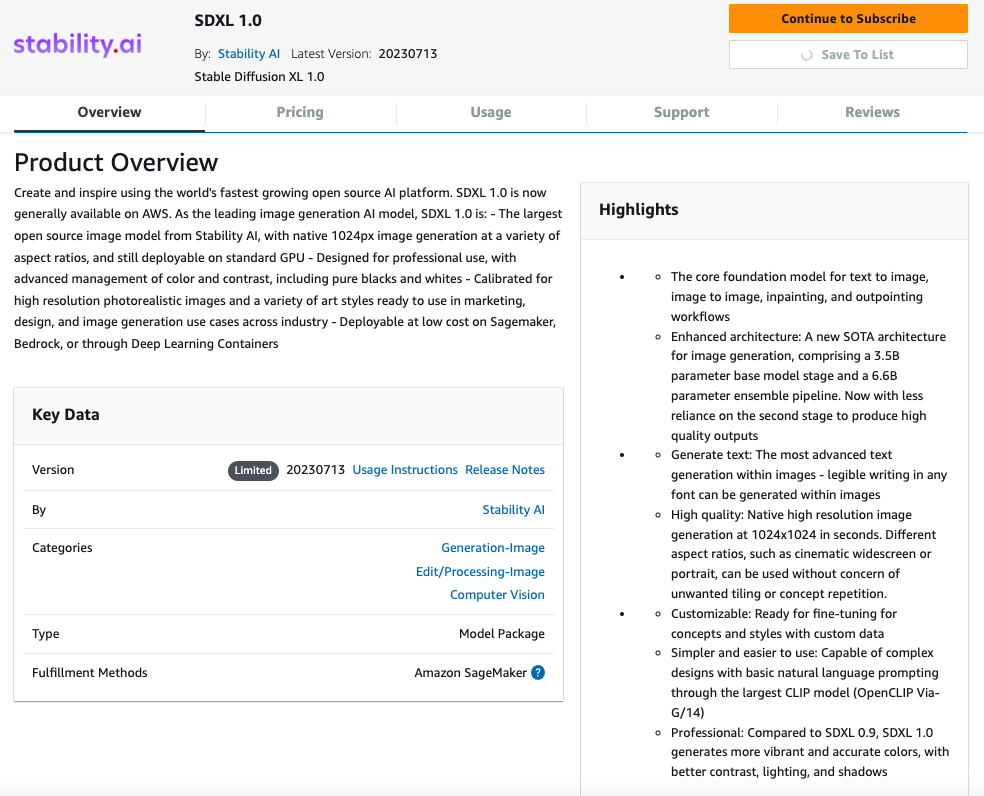
- Subscribe to this softwareページで、価格詳細とエンドユーザーライセンス契約(EULA)を確認します。同意できる場合は、Accept offerを選択します。
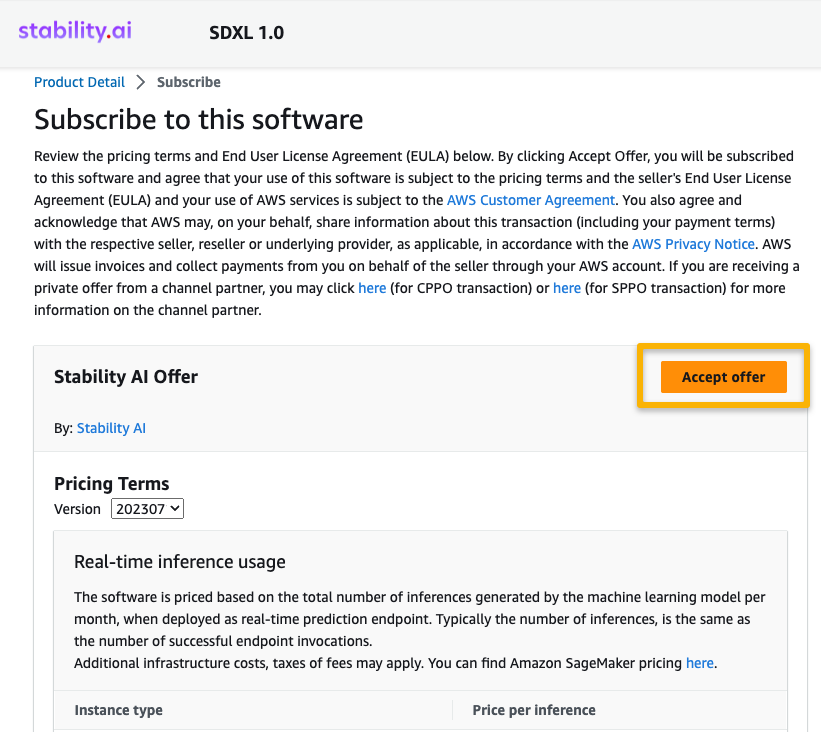
- Continue to configurationを選択してモデルの構成を開始します。
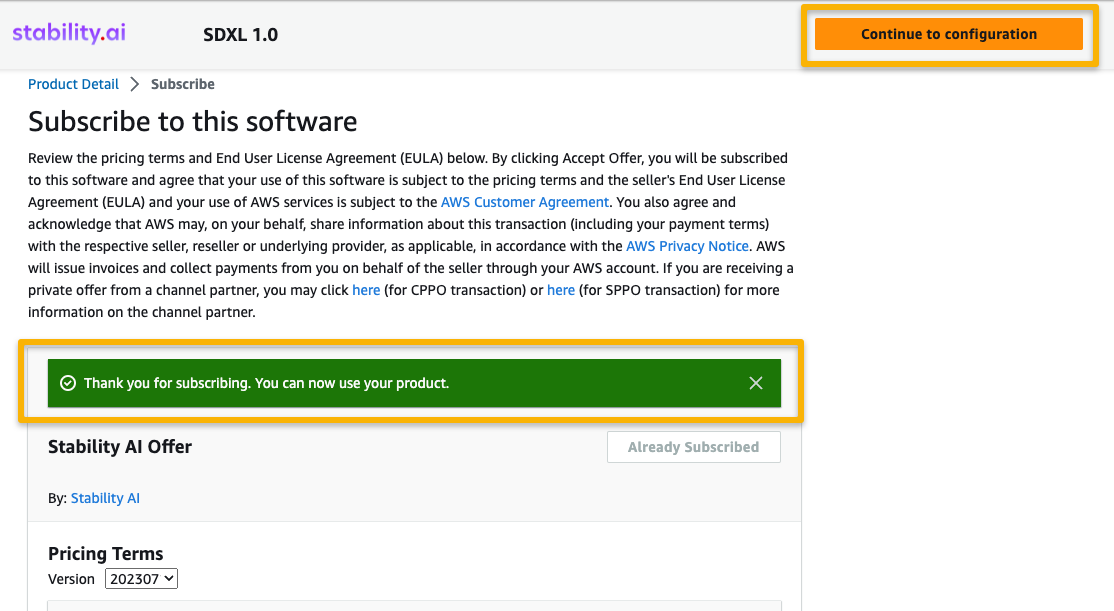
- サポートされているリージョンを選択します。
製品のARNが表示されます。これは、Boto3を使用して展開可能なモデルを作成する際に指定する必要があるモデルパッケージARNです。
- リージョンに対応するARNをコピーし、ノートブックのセルの指示に同じARNを指定します。
ARNの情報は、サンプルノートブックに既に利用可能かもしれません。
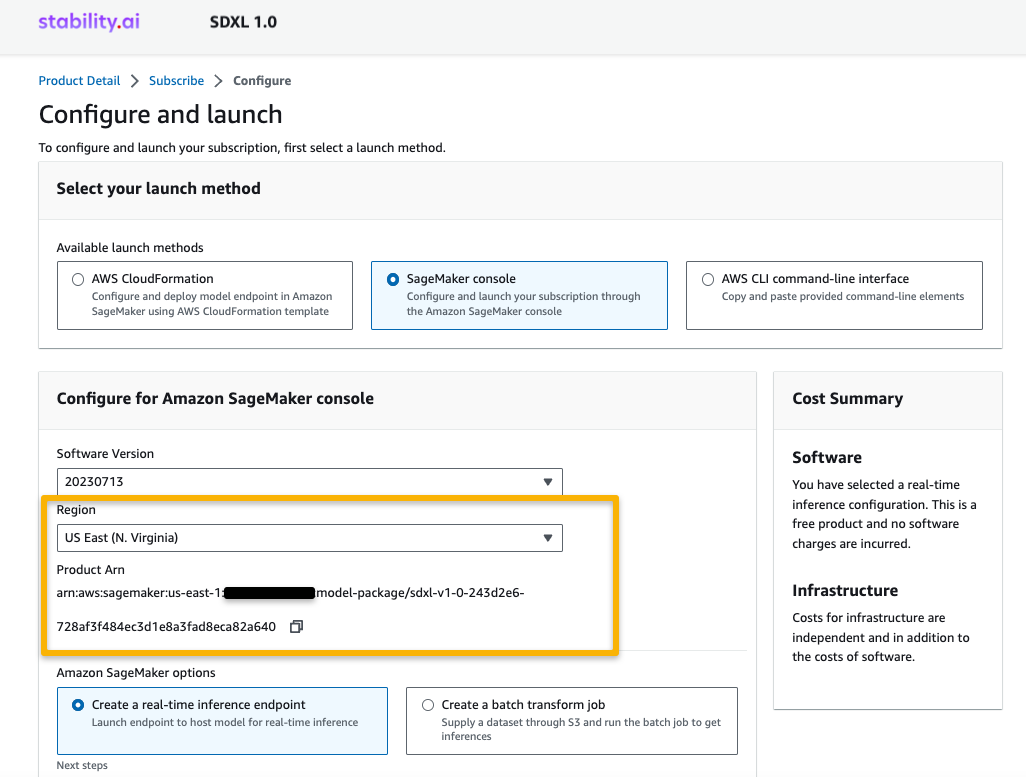
- 例のノートブックの実行を開始する準備が整いました。
AWS Marketplace からも続けることができますが、デプロイメントの動作をより理解するためには、SageMaker Studio の例のノートブックに従うことをおすすめします。
クリーンアップ
作業が終了したら、エンドポイントを削除して、それに関連付けられた Amazon Elastic Compute Cloud(Amazon EC2)インスタンスを解放し、課金を停止することができます。
AWS CLI を使用して、SageMaker エンドポイントのリストを取得します。
!aws sagemaker list-endpoints次に、エンドポイントを削除します。
deployed_model.sagemaker_session.delete_endpoint(endpoint_name)結論
この記事では、SageMaker Studio で新しい SDXL 1.0 モデルを使い始める方法を紹介しました。このモデルを使用すると、SDXL が提供するさまざまな機能を活用して、リアルな画像を作成することができます。基礎モデルは事前にトレーニングされているため、トレーニングとインフラストラクチャのコストを抑えることができ、ユースケースに合わせたカスタマイズも可能です。
リソース
- SageMaker JumpStart
- JumpStart Foundation Models
- SageMaker JumpStart 製品ページ
- SageMaker JumpStart モデルカタログ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






