『Amazon SageMaker Clarifyを使用して、臨床設定で医療上の決定を説明する』
Using Amazon SageMaker Clarify to explain medical decisions in a clinical setting.
機械学習(ML)モデルの説明可能性は、医療領域で使用されるモデルにおいてますます重要となっています。なぜなら、採用を得るために、モデルをさまざまな視点から説明する必要があるからです。これらの視点には、医療、技術、法的な視点、そして最も重要な視点である患者の視点が含まれます。医療領域のテキストで開発されたモデルは統計的に正確になっていますが、個々の患者に最適な治療を提供するためには、これらの予測に関連する弱点の評価が倫理的に求められます。これらの予測の説明可能性は、臨床医が患者ごとに正しい選択をするために必要です。
この記事では、Amazon SageMaker Clarifyを使用して臨床設定でモデルの説明可能性を向上させる方法を示します。
背景
医療領域でのMLアルゴリズムの特定の応用例は、大量のテキストを使用する臨床意思決定支援システム(CDSS)のトリアージです。毎日、患者が入院し、入院記録が作成されます。これらの記録が作成された後、トリアージプロセスが開始され、MLモデルは臨床医に臨床結果の推定を支援することができます。これにより、運用コストを削減し、患者に最適な治療を提供することができます。MLモデルがなぜこれらの意思決定を提案しているのかを理解することは、個々の患者に関連する意思決定に非常に重要です。
この記事の目的は、Amazon SageMakerを使用して予測モデルを展開し、病院の設定内でトリアージの目的で使用し、SageMaker Clarifyを使用してこれらの予測を説明する方法を概説することです。その意図は、多くの医療機関においてCDSS内の予測技術の採用を加速することです。
この記事のノートブックとコードはGitHubで利用できます。自分で実行するには、GitHubリポジトリをクローンし、Jupyterノートブックファイルを開きます。
技術的背景
急性医療機関の重要な資産の一つは臨床ノートです。入院時には、入院記録が作成されます。最近のいくつかの研究では、診断、手術、入院期間、入院中の死亡などの主要な指標の予測性が示されています。これらの予測は、自然言語処理(NLP)アルゴリズム[1]を使用することで、入院記録だけから非常に実現可能になりました。
BERTなどのNLPモデルの進歩により、以前は価値を得るのが難しかった入院記録などのテキストコーパスに対して非常に正確な予測が可能になりました。これらの予測は、CDSSでの使用に非常に適しています。
ただし、新しい予測を効果的に使用するためには、これらの正確なBERTモデルが予測をどのように達成しているのかを説明する必要があります。このようなモデルの予測を説明するためのいくつかの技術があります。そのような技術の一つがSHAP(SHapley Additive exPlanations)です。SHAPは、MLモデルの出力を説明するためのモデルに依存しない技術です。
SHAPとは何か
SHAP値はMLモデルの出力を説明するための技術です。これにより、MLモデルの予測を分解し、各入力特徴が最終的な予測にどれだけ貢献しているかを理解することができます。
SHAP値はゲーム理論に基づいており、特に協力ゲームのShapley値の概念に基づいています。協力ゲームでは、入力空間の各特徴は協力ゲームのプレイヤーと見なされ、モデルの予測は支払いです。 SHAP値は、各特徴が特徴のすべての可能な組み合わせに対してモデル予測への貢献を調査することによって計算されます。すべての特徴のすべての可能な特徴の組み合わせに対する平均的な貢献が計算され、これがその特徴のSHAP値となります。
SHAPを使用することで、モデルの内部構造を理解せずに予測を説明することができます。さらに、これらのSHAPの説明をテキストで表示するための技術もあります。これにより、医療関係者と患者の両方がアルゴリズムが予測に至るまでのプロセスを直感的に理解できるようになります。
SageMaker Clarifyの新機能と、SageMakerで簡単に使用できるHugging Faceの事前学習済みモデルの使用により、モデルトレーニングと説明可能性をすべてAWSで簡単に行うことができます。
エンドツーエンドの例を示すために、入院中の死亡の臨床結果を取り上げ、このプロセスを事前学習済みのHugging Face BERTモデルを使用してAWSで簡単に実装する方法を示します。そして、予測はSageMaker Clarifyを使用して説明されます。
Hugging Faceモデルの選択肢
Hugging Faceは、臨床ノートでの使用に特化したさまざまな事前学習済みBERTモデルを提供しています。この記事では、bigbird-base-mimic-mortalityモデルを使用します。このモデルは、GoogleのBigBirdモデルのチューニングバージョンであり、MIMIC ICU入院記録を使用して死亡率を予測するために特に適応されています。このモデルのタスクは、入院記録に基づいて特定のICU滞在中に患者が生存しない可能性を判断することです。このBigBirdモデルの重要な利点の一つは、より大きなコンテキスト長を処理できる能力です。つまり、切り捨てる必要なく、完全な入院記録を入力することができます。
私たちの手順は、この微調整モデルをSageMaker上に展開することを含みます。そして、このモデルをリアルタイムの予測の説明に組み込むためのセットアップに取り入れます。この説明性のレベルを達成するために、私たちはSageMaker Clarifyを使用しています。
ソリューションの概要
SageMaker Clarifyは、ML開発者に対して特化したツールを提供し、彼らのMLトレーニングデータとモデルに対するより深い洞察を得ることができます。SageMaker Clarifyは、コンピュータビジョン(CV)およびNLPモデルが行ったグローバルおよびローカルの予測を説明し、意思決定を説明します。
次のダイアグラムは、説明要求を提供するエンドポイントをホストするためのSageMakerのアーキテクチャを示しています。エンドポイント、モデルコンテナ、およびSageMaker Clarifyの説明者の間の相互作用が含まれています。
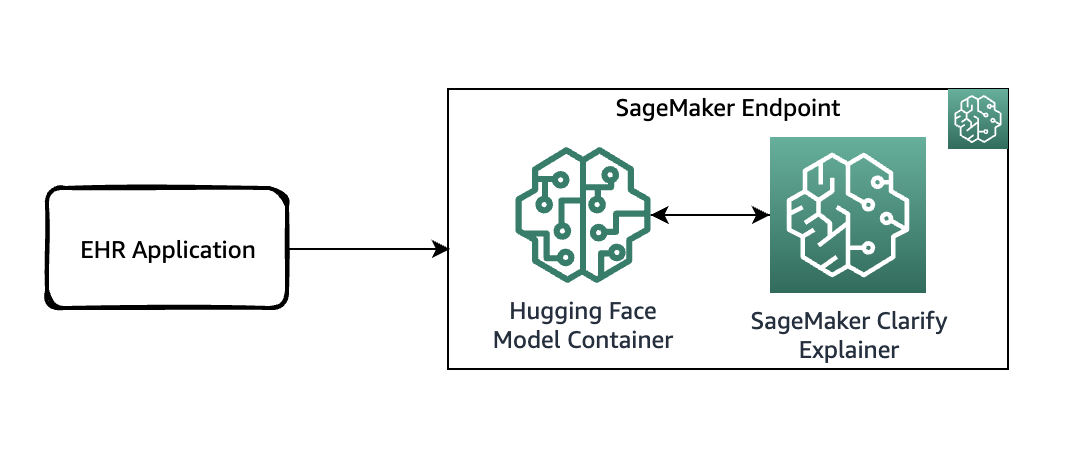
サンプルコードでは、機能を紹介するためにJupyterノートブックを使用しています。ただし、実世界のユースケースでは、電子健康記録(EHR)やその他の病院のケアアプリケーションは、同じ応答を得るために直接SageMakerエンドポイントを呼び出します。Jupyterノートブックでは、Hugging FaceモデルコンテナをSageMakerエンドポイントに展開します。そして、展開されたモデルから得られた結果を説明するためにSageMaker Clarifyを使用します。
前提条件
以下の前提条件が必要です:
- AWSアカウント
- SageMaker Jupyterノートブックインスタンス
GitHubリポジトリからコードにアクセスして、ノートブックインスタンスにアップロードします。また、Amazon SageMaker Studio環境でノートブックを実行することもできます。これは、ML開発のための統合開発環境(IDE)です。SageMaker StudioではPython 3(Data Science)カーネル、またはSageMakerノートブックインスタンスではconda_python3カーネルを使用することをお勧めします。
SageMaker Clarifyを有効にしてモデルを展開する
最初のステップとして、Hugging Faceからモデルをダウンロードし、Amazon Simple Storage Service(Amazon S3)バケットにアップロードします。その後、HuggingFaceModelクラスを使用してモデルオブジェクトを作成します。これにより、Hugging FaceモデルをSageMakerに展開するプロセスが簡素化されたプリビルドコンテナが使用されます。また、カスタムの推論スクリプトをコンテナ内で予測するために使用します。次のコードは、HuggingFaceModelクラスに渡される引数として渡されるスクリプトを示しています:
from sagemaker.huggingface import HuggingFaceModel
# Hugging Faceモデルクラスを作成する
huggingface_model = HuggingFaceModel(
model_data = model_path_s3,
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
role=role,
source_dir = "./{}/code".format(model_id),
entry_point = "inference.py"
)次に、このモデルを展開するインスタンスタイプを定義できます:
instance_type = "ml.g4dn.xlarge"
container_def = huggingface_model.prepare_container_def(instance_type=instance_type)
container_def次に、ExecutionRoleArn、ModelName、およびPrimaryContainerフィールドを設定してモデルを作成します。
model_name = "hospital-triage-model"
sagemaker_client.create_model(
ExecutionRoleArn=role,
ModelName=model_name,
PrimaryContainer=container_def,
)
print(f"Model created: {model_name}")次に、create_endpoint_config APIを呼び出してエンドポイント構成を作成します。ここでは、create_model API呼び出しで使用したmodel_nameを指定します。create_endpoint_configは、SageMaker Clarifyの説明者を有効にするための追加パラメータClarifyExplainerConfigをサポートしています。SHAPベースラインは必須です。インラインベースラインデータ(ShapBaselineパラメータ)またはS3ベースラインファイル(ShapBaselineUriパラメータ)のいずれかを指定できます。オプションのパラメータについては、開発者ガイドを参照してください。
次のコードでは、特別なトークンをベースラインとして使用しています:
baseline = [["<UNK>"]]
print(f"SHAP baseline: {baseline}")TextConfigは、文レベルの粒度(各文が特徴量であり、良い可視化のためにレビューごとにいくつかの文が必要です)および言語を英語に設定されています:
endpoint_config_name = "hospital-triage-model-ep-config"
csv_serializer = sagemaker.serializers.CSVSerializer()
json_deserializer = sagemaker.deserializers.JSONDeserializer()
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "MainVariant",
"ModelName": model_name,
"InitialInstanceCount": 1,
"InstanceType": instance_type,
}
],
ExplainerConfig={
"ClarifyExplainerConfig": {
"InferenceConfig": {"FeatureTypes": ["text"]},
"ShapConfig": {
"ShapBaselineConfig": {"ShapBaseline": csv_serializer.serialize(baseline)},
"TextConfig": {"Granularity": "sentence", "Language": "en"},
},
}
},
)最後に、モデルとエンドポイント設定が完了したら、create_endpoint APIを使用してエンドポイントを作成します。 endpoint_nameは、AWSアカウントのリージョン内で一意である必要があります。 create_endpoint APIは同期的な性質を持ち、エンドポイントの状態が作成中であることを示す即時の応答を返します。
endpoint_name = "hospital-triage-prediction-endpoint"
sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)予測の説明
オンラインの説明可能性を有効にしてエンドポイントを展開したので、いくつかの例を試すことができます。 invoke_endpointメソッドを使用してリアルタイムエンドポイントを呼び出し、この場合はいくつかのサンプル入院ノートをシリアル化ペイロードとして提供します:
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="text/csv",
Accept="text/csv",
Body=csv_serializer.serialize(sample_admission_note.iloc[:1, :].to_numpy())
)
result = json_deserializer.deserialize(response["Body"], content_type=response["ContentType"])
pprint.pprint(result)最初のシナリオでは、次の医療入院ノートが医療従事者によって作成されたと仮定します:
“患者は急性胸痛を訴える25歳の男性です。患者は仕事中に突然痛みが始まり、それ以来一貫しています。患者は痛みを8/10の重症度と評価しています。患者は痛みの放射線、呼吸困難、吐き気、嘔吐を否定しています。患者は胸痛の既往歴はありません。以下のバイタルサインが観察されました:血圧140/90 mmHg、心拍数92回/分、呼吸数18回/分、酸素飽和度96%(常息時)。身体検査では、前胸部の触診でわずかな触痛があり、肺野は透明です。EKGでは、ST上昇またはST降下のない洞調律の頻脈が示されています。”次のスクリーンショットは、モデルの結果を示しています。

この情報がSageMakerエンドポイントに転送されると、ラベル0が予測され、これは死亡リスクが低いことを示します。つまり、0はモデルによれば入院患者が非急性状態であることを意味します。しかし、その予測の根拠が必要です。そのために、応答としてSHAP値を使用できます。応答には、入力ノートのフレーズに対応するSHAP値が含まれており、SHAP値が予測にどのように寄与するかに応じてさらにグリーンまたはレッドで色分けされることができます。この場合、予測0に一致するグリーンのフレーズ、「患者は胸痛の既往歴はありません」と「EKGでは、ST上昇またはST降下のない洞調律の頻脈が示されています」といったフレーズが赤よりも多く見られます。
第2のシナリオでは、次の医療入院ノートが医療従事者によって作成されたと仮定します:
“患者は敗血症と敗血性ショックの重症な訴えを持つ72歳の女性です。患者は過去3日間、発熱、寒気、倦怠感、尿量減少、混乱を訴え、慢性閉塞性肺疾患(COPD)の既往歴と肺炎の最近の入院歴があります。以下のバイタルサインが観察されました:血圧80/40 mmHg、心拍数130回/分、呼吸数30回/分、酸素飽和度82%(鼻カニューラ経由で酸素4L)。身体検査では、下肢に広範な紅斑と温感があり、敗血症の陽性所見である意識障害、頻脈、頻呼吸があります。血液培養が採取され、適切な薬物療法が開始されました。”次のスクリーンショットは、私たちの結果を示しています。
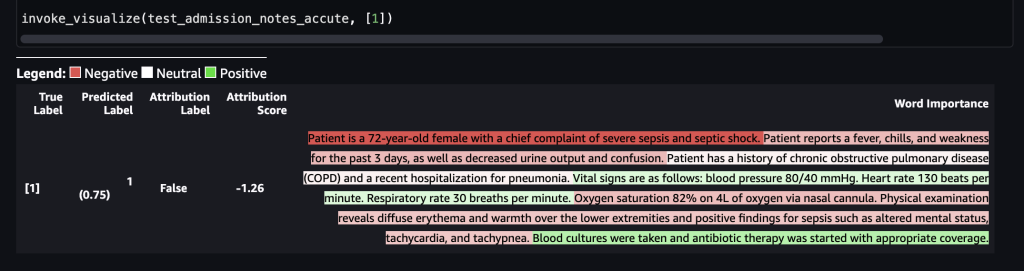
これがSageMakerエンドポイントに転送された後、ラベルは1と予測され、死亡リスクが高いことを示しています。これは、モデルによれば入院患者が急性状態にあることを意味します。ただし、その予測の根拠が必要です。再び、応答としてSHAP値を使用できます。応答には、入力ノートのフレーズに対応するSHAP値が含まれており、さらにカラーコード化することができます。この場合、私たちは「患者は過去3日間、発熱、寒気、倦怠感、尿量の減少、混乱を報告しています」と「患者は重症敗血症ショックの主訴を持つ72歳の女性です」といった赤いフレーズが多く見られ、予測の1と一致しているということです。
臨床ケアチームは、これらの説明を使用して、各個別患者の治療プロセスに関する意思決定を支援することができます。
クリーンアップ
このソリューションの一部として作成されたリソースをクリーンアップするには、次のステートメントを実行します:
huggingface_model.delete_model()
predictor = sagemaker.Predictor(endpoint_name="triage-prediction-endpoint")
predictor.delete_endpoint()結論
この投稿では、SageMaker Clarifyを使用して、トリアージプロセスのさまざまな段階で記録された医療ノートに基づいて、医療ケースでの意思決定を説明する方法を紹介しました。このソリューションは、既存の意思決定支援システムに統合することで、ICUへの入院を評価する際に臨床医にとって別のデータポイントを提供できます。医療業界でAWSサービスを使用する方法についてもっと学ぶには、以下のブログ記事をご覧ください:
- AWS Well-Architected Frameworkのためのヘルスケア業界レンズの紹介
- Telescope Healthがクラウド上で仮想診療を効率化する方法
- AWS上の手術室分析によるより良い外科医療のためのパスウェイ
- Amazon SageMaker Pipelinesでのマルチモデルトレーニングを使用した糖尿病患者の再入院予測
- Pieces TechnologiesがAWSサービスを活用して患者の転帰を予測する方法
参考文献
[1] https://aclanthology.org/2021.eacl-main.75/
[2] https://arxiv.org/pdf/1705.07874.pdf
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






