GPUを活用した特徴量エンジニアリングにおいてRAPIDS cuDFを使用する
Use RAPIDS cuDF for feature engineering utilizing GPU.
特定の手法が問題の解決に成功したとしても、異なるスケールでは同じ結果にはならないかもしれません。距離が変わると、靴も変わる必要があります。
機械学習において、モデルの成功を保証するためには、データとデータ処理が重要であり、特徴量エンジニアリングもその一部です。データが少ない場合、古典的なPandasライブラリはCPU上でどんな処理タスクでも簡単に処理できます。しかし、Pandasは大量のデータを処理する際には遅すぎる場合があります。データ処理と特徴量エンジニアリングの速度と効率を向上させるための1つの解決策は、RAPIDSです。
「RAPIDSは、グラフィックス処理ユニット(GPU)上で完全に実行されるエンドツーエンドのデータサイエンスおよび分析パイプラインのためのオープンソースソフトウェアライブラリのスイートです。RAPIDSは、データサイエンスパイプラインを加速して、より生産的なワークフローを作成します。[1]」

- JPLは、マルウェア研究を支援するためのPDFアーカイブを作成しました
- データ解析の刷新:OpenAI、LangChain、LlamaIndexで簡単に抽出
- Power BI vs Tableau:類似点と相違点
RAPIDSのcuDFというツールは、特徴量エンジニアリングとデータ前処理で効率的に表形式データを操作するためのものです。RAPIDS cuDFは、GPUデータフレームの作成や、インデックス、グループ化、マージ、文字列処理など、いくつかのPandas操作を実行できます。RAPIDSのウェブサイトによれば、次のように定義されています。
「cuDFは、Apache Arrow列指向メモリフォーマット上に構築されたPython GPU DataFrameライブラリであり、pandasのスタイルでDataFrameスタイルAPIを使用して表形式データをロード、結合、集計、フィルタリング、およびその他の操作を行うことができます。[2]」
この記事では、実際のデータセットを使用して、cuDFを使用してGPU上でデータフレームを作成および操作し、特徴量エンジニアリングを適用する方法について説明します。
私たちのデータセットはKaggleのOptiver Realized Volatility Predictionに属します。これには、金融市場で取引を実施するための関連株式市場データが含まれており、オーダーブックのスナップショットと実行された取引が含まれています[3]。
次のセクションで、データについて詳しく説明します。その後、Google ColabをKaggleとRAPIDSに統合します。第3セクションでは、PandasとcuDFを使用してこのデータセットで特徴量エンジニアリングを実行する方法について説明し、両方のライブラリの比較パフォーマンスレビューを提供します。最後のセクションでは、結果をプロットして評価します。
データ
使用するデータは、2つのファイルセットから構成されています[3]。
- book_[train/test].parquet: 株式IDでパーティションされたParquetファイルであり、市場に入力された最も競争力のある買い注文と売り注文に関するオーダーブックデータを提供します。このファイルには、受動的な買い注文/売り注文の更新が含まれています。
book_[train/test].parquetの特徴量カラム:
- stock_id – 株のIDコード。Parquetは、この列をロードするときにカテゴリデータ型に強制変換します。
- time_id – 時間バケットのIDコード。時間IDは必ずしも連続的ではありませんが、すべての株で一貫しています。
- seconds_in_bucket – バケットの開始からの秒数で、常に0から開始します。
- bid_price[1/2] – 最も競争力のある買いレベル/2番目に競争力のある買いレベルの正規化された価格。
- ask_price[1/2] – 最も競争力のある売りレベル/2番目に競争力のある売りレベルの正規化された価格。
- bid_size[1/2] – 最も競争力のある買いレベル/2番目に競争力のある買いレベルの株式数。
- ask_size[1/2] – 最も競争力のある売りレベル/2番目に競争力のある売りレベルの株式数。
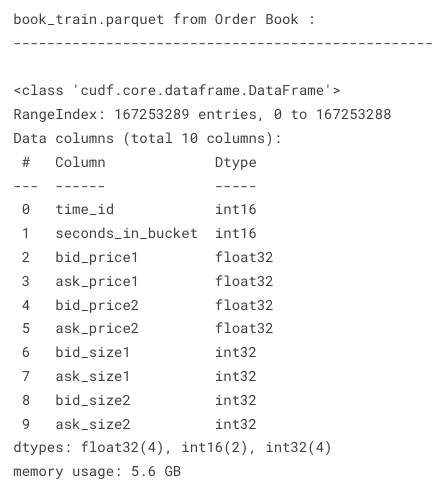
このファイルは5.6 GBで、1億6700万以上のエントリーが含まれています。112の株と3830の10分間のタイムウィンドウ(time_id)があります。各時間ウィンドウ(バケット)は最大で600秒です。株ごとに1秒あたり1回の取引意向が発生する可能性があるため、上記の数値の乗算が何百万ものエントリーがある理由を説明しています。注意すべきは、特定のタイムウィンドウのすべての秒において取引意向が発生するわけではないため、特定のタイムウィンドウの一部の秒は欠落していることです。
- trade_[train/test].parquet: 株式IDでパーティションされたParquetファイルであり、実際に実行された取引に関するデータが含まれます。
trade_[train/test].parquetの特徴量カラム:
- stock_id – 上記と同じ。
- time_id – 上記と同じ。
- seconds_in_bucket – 上記と同じ。トレードとブックのデータが同じタイムウィンドウから取得され、トレードデータは一般的により疎ですので、このフィールドは必ずしも0から開始されません。
- price – 1秒あたりに発生する実行取引の平均価格。価格は正規化され、平均は各トランザクションで取引された株式数で重み付けされています。
- size – 取引された株式数の合計。
- order_count – 実行されたユニークなトレードオーダーの数。

trade_[train/test].parquetファイルはbook_[train/test].parquetよりもはるかに小さいです。前者は512.5 MBで、3800万以上のエントリーがあります。実際の取引が意図に一致する必要はないため、取引データはより疎でエントリー数が少なくなります。
目標は、同じstock_id/time_idの下で、フィーチャーデータから次の10分間の実現株価の波動性を予測することです。このプロジェクトには、大規模なデータセットで実行する必要がある多くの特徴量エンジニアリングが必要です。新しいフィーチャーを開発することは、データのサイズと計算の複雑さを増加させます。その対策の一つは、Pandasライブラリの代わりにcuDFを使用することです。
このブログでは、PandasとcuDFを両方使用して、いくつかの特徴量エンジニアリングタスクとデータフレーム操作を行い、そのパフォーマンスを比較します。ただし、すべてのデータではなく、単一の株のレコードのみを使用して、模範的な実装を見てみましょう。すべての特徴量エンジニアリング作業が完了したノートブックを確認することができます。
Google Colabでコードを実行するので、ノートブックをKaggleとRAPIDSに統合するように最初に構成する必要があります。
Google Colabノートブックの構成
Colabノートブックを構成するには、次の手順が必要です。
- KaggleアカウントでAPIトークンを作成して、ノートブックをKaggleサービスと認証します。
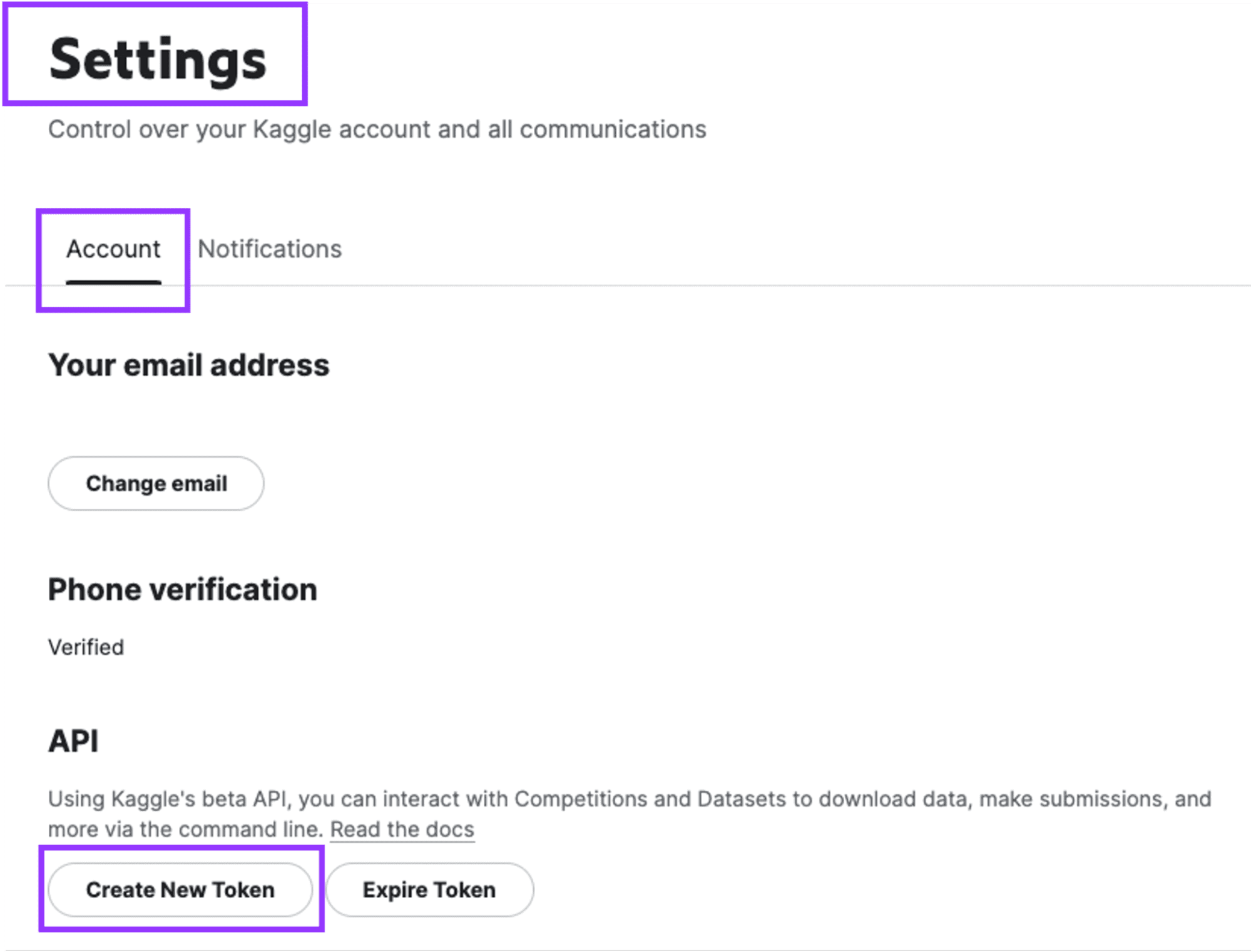
設定に移動して、「新しいトークンを作成」をクリックします。ユーザー名とAPIキーが含まれる「kaggle.json」という名前のファイルがダウンロードされます。
- Google Colabで新しいノートブックを開始し、kaggle.jsonファイルをアップロードします。
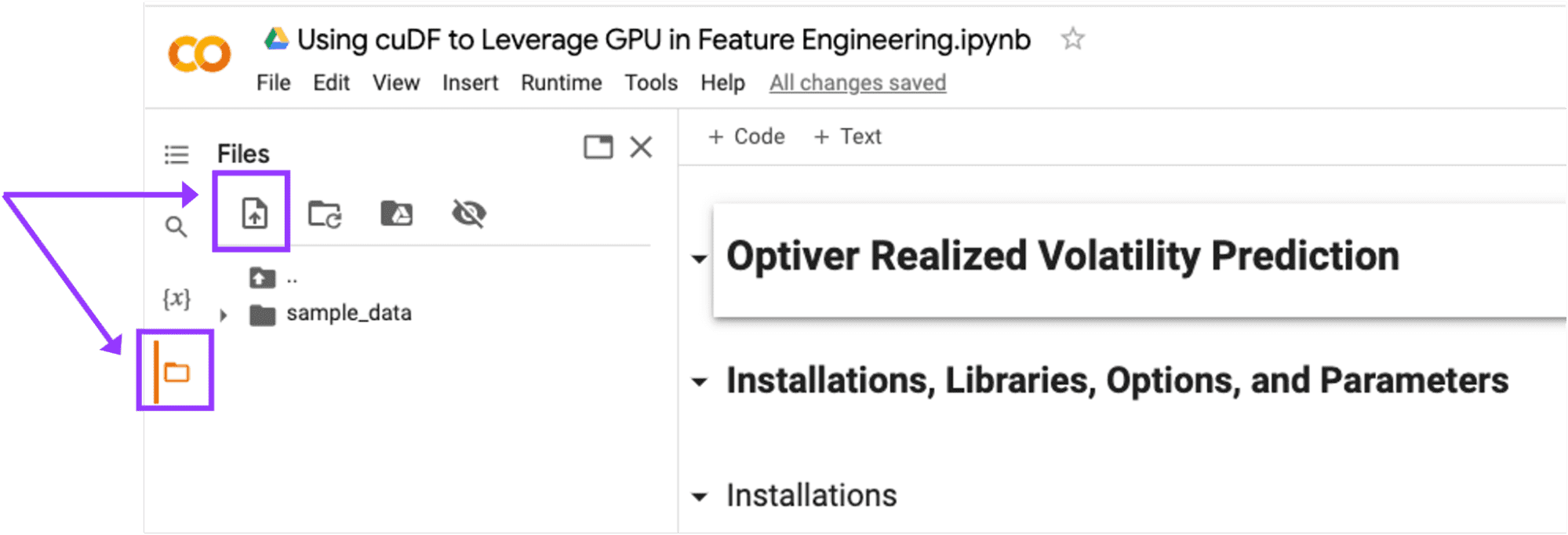
「セッションストレージにアップロードする」アイコンをクリックして、kaggle.jsonファイルをGoogle Colabにアップロードします。
- ページ上部の「ランタイム」ドロップダウンをクリックし、「ランタイムのタイプを変更」をクリックして、インスタンスタイプがGPUであることを確認します。
- 以下のコマンドを実行し、出力を確認してTesla T4、P4、またはP100が割り当てられていることを確認します。
!nvidia-smi- RAPIDS-Colabインストールファイルを取得し、GPUを確認します:
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git
!python rapidsai-csp-utils/colab/pip-install.pyこのセルの出力で、ColabインスタンスがRAPIDS互換であることを確認してください。
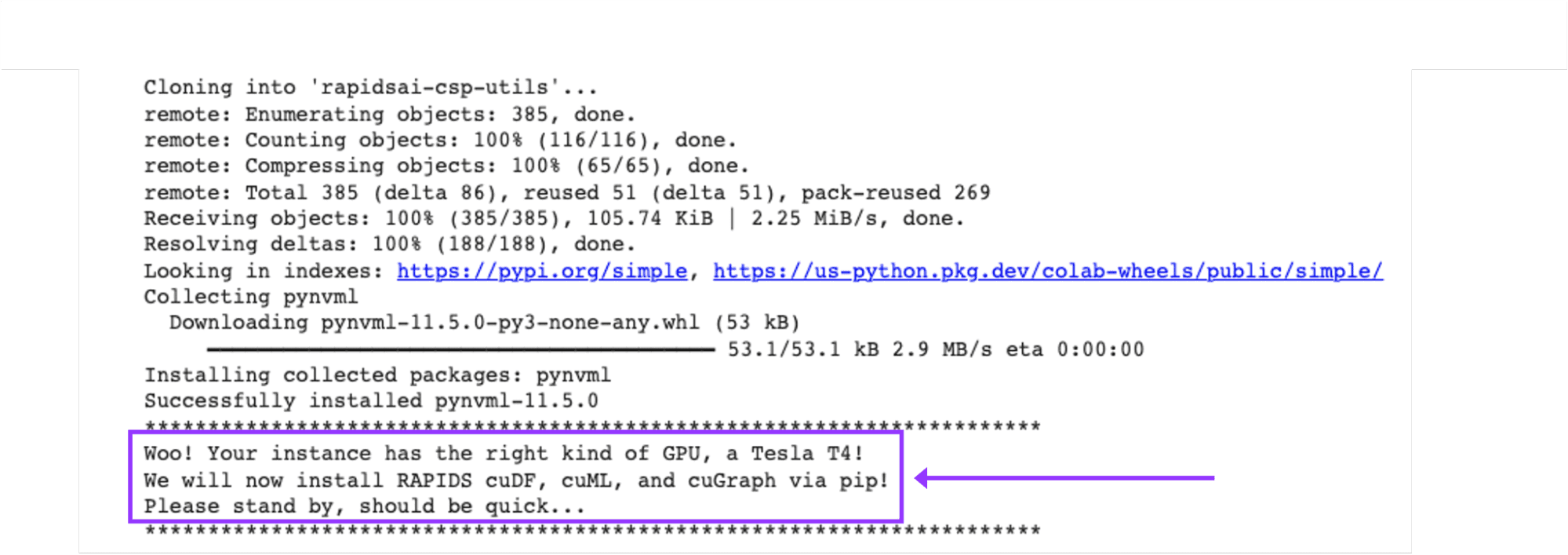
- RAPIDSライブラリが正しくインストールされているかどうかを確認します:
import cudf, cuml
cudf.__version__セットアップにエラーがない場合、Google Colabの構成が完了です。これで、Kaggleデータセットをアップロードできます。
Kaggleデータセットのインポートとアップロード
データセットをKaggleからインポートするために、Colabインスタンスでいくつかの準備をする必要があります。
- Kaggleライブラリをインストールします:
!pip install -q kaggle- 「.kaggle」という名前のディレクトリを作成します:
!mkdir ~/.kaggle- この新しいディレクトリに「kaggle.json」をコピーします:
!cp kaggle.json ~/.kaggle/- このファイルに必要な許可を割り当てます:
!chmod 600 ~/.kaggle/kaggle.json- Kaggleからデータセットをダウンロードします:
!kaggle competitions download optiver-realized-volatility-prediction- 解凍されたデータのためのディレクトリを作成します:
!mkdir train- 新しいディレクトリにデータを解凍します:
!unzip optiver-realized-volatility-prediction.zip -d train- 必要な全てのライブラリをインポートします:
import glob
import numpy as np
import pandas as pd
from cudf import DataFrame
import matplotlib.pyplot as plt
from matplotlib import style
from collections import defaultdict
from IPython.display import display
import gc
import time
import warnings
%matplotlib inline- Pandasのオプションを設定します:
pd.set_option("display.max_colwidth", None)
pd.set_option("display.max_columns", None)
warnings.filterwarnings("ignore")
print("Threshold:", gc.get_threshold())
print("Count:", gc.get_count())- パラメータを定義します:
# ファイルを含むデータディレクトリ
DIR = "/content/train/"
# 実行回数
ROUNDS = 30- ファイルを取得します:
# 注文と取引のブックを取得します
order_files = glob.glob(DIR + "book_train.parquet" + "/*")
trade_files = glob.glob(DIR + "trade_train.parquet" + "/*")
print(order_files[:5])
print("\n")
print(trade_files[:5])
print("\n")
# stock_idsをリストで取得します
stock_ids = sorted([int(file.split('=')[1]) for file in order_files])
print(f"{len(stock_ids)} stocks: \n {stock_ids} \n")ここで、私たちのノートブックはすべてのデータフレームタスクを実行し、特徴量エンジニアリングを実行する準備ができています。
特徴量エンジニアリング
このセクションでは、PandasデータフレームとcuDFに対する13個の典型的なエンジニアリング操作について説明します。これらの操作がどのくらい時間がかかり、どのくらいのメモリを使用するかを見ていきます。まずは、データをロードすることから始めましょう。
1. データをロードします
def load_dataframe(files, dframe=0):
print("LOADING DATA FRAMES", "\n")
# pandasデータフレームをロードします
if dframe == 0:
print("Loading pandas dataframe..", "\n")
start = time.time()
df_pandas = pd.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"For pandas dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n")
return df_pandas, elapsed_time
# cuDFデータフレームをロードします
else:
print("Loading cuDF dataframe..", "\n")
start = time.time()
df_cudf = cudf.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"For cuDF dataframe: \n start time: {start} \n end time: {end} \n elapsed time: {elapsed_time} \n ")
return df_cudf, elapsed_timedframe=0の場合はPandasデータフレームとしてデータがロードされ、それ以外の場合はcuDFとしてロードされます。例えば、
Pandas:
# パンダ注文のデータフレームをロードして時間を計算します
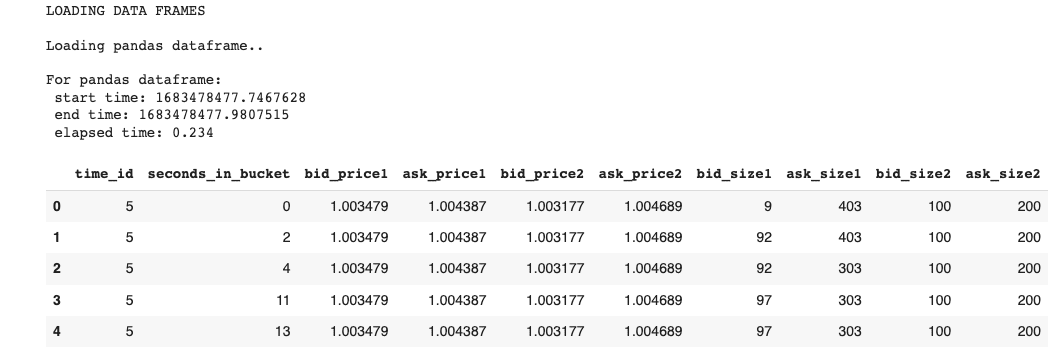
df_pd_order, _ = load_dataframe(order_files, dframe=0)
display(df_pd_order.head())これにより、注文ブック(book_[train/test].parquet)の最初の5レコードが返されます。
cuDF:
# cuDFブックデータフレームをロードして時間を計算します
df_cudf_order, _ = load_dataframe(order_files, dframe=1)
display(df_cudf_order.head())出力:
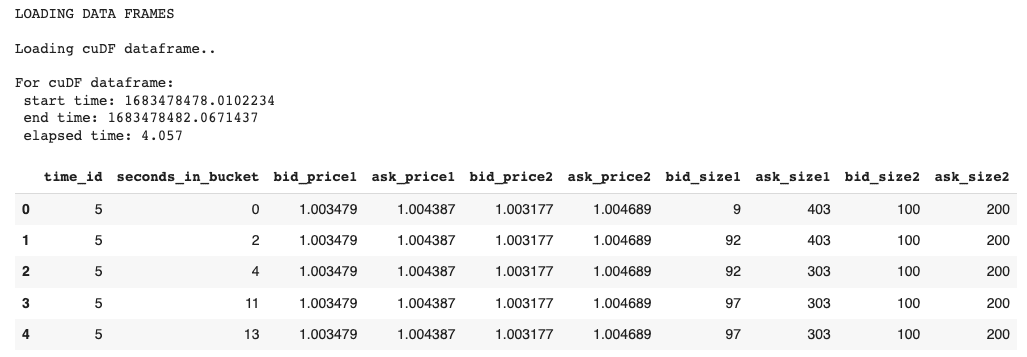 Exhibit-7: cuDFとしてデータをロードする(著者による画像)
Exhibit-7: cuDFとしてデータをロードする(著者による画像)
パンダのバージョンから注文帳のデータに関する情報を取得しましょう:
# 注文のデータフレーム情報
display(df_pd_order.info())出力:
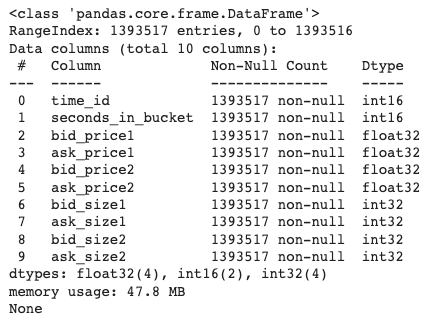 Exhibit-8: 最初の株式の注文帳のデータに関する情報(著者による画像)
Exhibit-8: 最初の株式の注文帳のデータに関する情報(著者による画像)
上記の画像によれば、最初の株式には約140万のエントリーがあり、47.8 MBのメモリスペースを占有しています。スペースを減らし、速度を上げるために、後でデータ型をより小さいフォーマットに変換する必要があります。
同様に、トレードブック(trade_[train/test].parquet)データを注文帳データと同様に両方のデータフレームライブラリに読み込みます。データとその情報は以下のようになります:
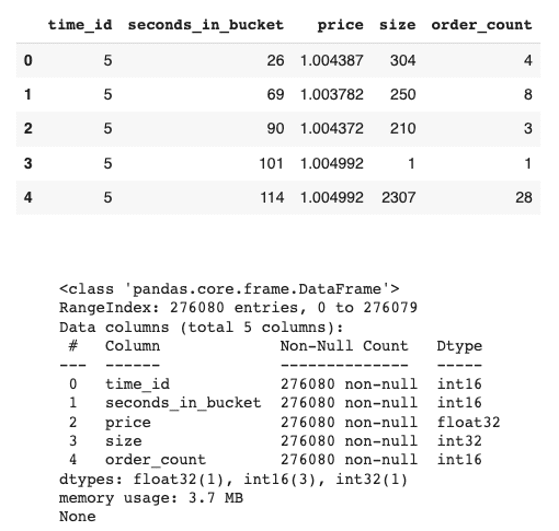 Exhibit-9: 最初の株式の取引帳のデータとデータ情報(著者による画像)
Exhibit-9: 最初の株式の取引帳のデータとデータ情報(著者による画像)
最初の株式の取引データは3.7 MBで、27.6万以上のレコードがあります。
注文帳と取引帳の両方のファイルにおいて、すべての時間ウィンドウに600秒のポイントがあるわけではありません。つまり、10分間隔のある特定の時間バケットには、取引または入札がいくつかの秒数しかない場合があります。そのため、両方のファイルには一部の秒数が欠落する疎データが含まれています。欠落している秒数のすべての列を前方充填して空白を修正する必要があります。Pandasは前方充填を許可しますが、cuDFにはその機能がありません。したがって、Pandasで前方充填を行い、前方充填されたPandasデータフレームからcuDFを再作成します。このブログの中心的な目的は、cuDFがPandasを凌駕する方法を示すことです。過去にこの問題を何度も調べた結果、Pandasで実装されているcuDFの方法に対応するものを見つけることはできなかったため、私たちは前方充填を以下のように行います[4]:
# データの前方充填
def ffill(df, df_name="order"):
# 前方充填
df_pandas = df.set_index(['time_id', 'seconds_in_bucket'])
if df_name == "order":
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']), method='ffill')
df_pandas = df_pandas.reset_index()
else:
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']))
# nan値を0で埋める
df_pandas = df_pandas.fillna(0)
df_pandas = df_pandas.reset_index()
# cuDFデータフレームに変換
df_cudf = cudf.DataFrame.from_pandas(df_pandas)
return df_pandas, df_cudf注文データを例にとって、処理方法を説明しましょう:
# 注文データフレームを前方充填
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
display(expanded_df_cudf_order.head()) Exhibit-10: 注文データの前方充填(著者による画像)
Exhibit-10: 注文データの前方充填(著者による画像)
Exhibit 7のデータとは異なり、Exhibit 10の前方充填されたデータには、時間バケット「5」のすべての600秒が含まれます。取引データについても同じ操作を行います。
2. データフレームのマージ
注文と取引の2つのデータセットがあり、どちらも前方充填されています。両方のデータセットはPandasとcuDFフレームワークで表されています。次に、注文と取引のデータセットをtime_idとseconds_in_bucketsでマージします。
def merge_dataframes(df1, df2, dframe=0):
print("データフレームのマージ", "\n")
if dframe == 0:
df_type = "Pandas"
else:
df_type = "cuDF"
# データフレームのマージ
print(f"{df_type}のデータフレームをマージしています..", "\n")
start = time.time()
df = df1.merge(df2, how="left", on=["time_id", "seconds_in_bucket"], sort=True)
end = time.time()
elapsed_time = round(end-start, 3)
print(f"{df_type}のデータフレームの場合: \n 開始時間: {start} \n 終了時間: {end} \n 経過時間: {elapsed_time} \n")
return df, elapsed_timecuDFは以下のコマンドを実行します:
# cuDFのorderとtradeデータフレームをマージする
df_cudf、cudf_merge_time = merge_dataframes(expanded_df_cudf_order、expanded_df_cudf_trade、dframe=1)
display(df_cudf.head())expanded_df_cudf_tradeは、forward-filledされた取引データであり、expanded_df_pd_orderまたはexpanded_df_cudf_orderと同じ方法で取得されます。マージ操作により、以下のように結合されたデータフレームが作成されます。
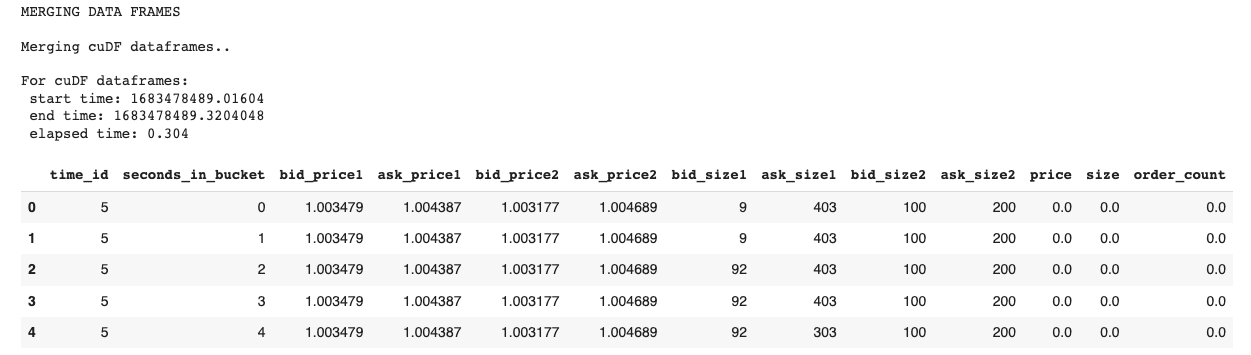 Exhibit-11: データフレームのマージ(著者による画像)
Exhibit-11: データフレームのマージ(著者による画像)
両データセットのすべての列が1つに結合されます。Pandasのデータフレームに対してもマージ操作が繰り返されます。

3. Dtypeの変更
一部の列のデータ型を変更して、メモリスペースを減らし、計算速度を上げたいと思います。
# dtypeの変更
def change_dtype(df、dframe=0):
print("DTYPEの変更", "\n")
convert_dict = {"time_id": "int16",
"seconds_in_bucket": "int16",
"bid_size1": "int16",
"ask_size1": "int16",
"bid_size2": "int16",
"ask_size2": "int16",
"size": "int16",
"order_count": "int16"
}
df = df.astype(convert_dict)
return df、dframe以下のコマンドを実行すると、
# cuDFデータフレームのdtypeを変更する
df_cudf、_ = change_dtype(df_cudf)
display(df_cudf.info())以下の出力が得られます:
 Exhibit-12: Dtypeの変更(著者による画像)
Exhibit-12: Dtypeの変更(著者による画像)
データは、Dtypeの変更が行われなかった場合、より多くのメモリスペースを使用します。それでも、それはforward-fillおよびmerge操作の後であり、13の列と230万のエントリーが生成された結果です。
Pandas DFとcuDFの両方の特徴量エンジニアリングタスクを実行します。ここでは、cuDFのみを例として示しました。
4. ユニークな時間IDの取得
このセクションでは、uniqueメソッドを使用してtime_idを抽出します。
# time_id列のユニークな値を取得してリストに入れる
def get_unique_timeids(df、dframe=0):
global time_ids
print("ユニークな値の取得", "\n")
# ユニークなtime_idを取得する
if dframe == 0:
print(f"Pandasデータフレームからソートされたユニークなtime_idを取得する..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().tolist())
end = time.time()
elapsed_time = round(end-start、3)
print(f"Pandasデータフレームからのユニークなtime_id: \n 開始時間:{start} \n 終了時間:{end} \n 経過時間:{elapsed_time} \n")
else:
print(f"cuDFデータフレームからソートされたユニークなtime_idを取得する..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().to_arrow().to_pylist())
end = time.time()
elapsed_time = round(end-start、3)
print(f"cuDFデータフレームからのユニークなtime_id: \n 開始時間:{start} \n 終了時間:{end} \n 経過時間:{elapsed_time} \n")
print(f"{len(time_ids)}のタイムバケット:\n{time_ids[:10]}...")
print("\n")
return df、time_ids上記のコードは、Pandas DFおよびcuDFからユニークなtime_idを取得します。
# cuDFデータフレームからtime_idを取得する
time_ids = get_unique_timeids(df_cudf_order、dframe=1)cuDFの出力は以下のようになります:
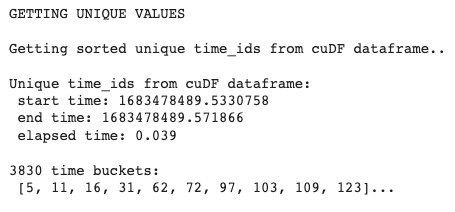 Exhibit-13: ユニークな時間IDの取得(著者による画像)
Exhibit-13: ユニークな時間IDの取得(著者による画像)
5. Null値のチェック
データフレーム内のNull値をチェックします。
# dfのNull値をチェック
def check_null_values(df, dframe=0):
print("Null値のチェック", "\n")
print("データフレームのNull値をチェック中..", "\n")
display(df.isna().values.any())
display(df.isnull().sum())
return df, dframecuDFのNull値チェックの例:
# cuDFデータフレームのNull値をチェック
df_cudf, _ = check_null_values(df_cudf, dframe=0)そして出力は以下のようになります:
 Exhibit-14: Null値のチェック (Image by Author)
Exhibit-14: Null値のチェック (Image by Author)
6. 列の追加
より多くの特徴量を作成するために、いくつかの列を追加します。
# 列の追加
def add_column(df, dframe=0):
print("列の追加", "\n")
# WAPを計算する
df['wap1'] = (df['bid_price1'] * df['ask_size1'] + df['ask_price1'] * df['bid_size1']) / (df['bid_size1'] + df['ask_size1'])
df['wap2'] = (df['bid_price2'] * df['ask_size2'] + df['ask_price2'] * df['bid_size2']) / (df['bid_size2'] + df['ask_size2'])
# 注文のボリュームを計算する
df['bid1_volume'] = df['bid_price1'] * df['bid_size1']
df['bid2_volume'] = df['bid_price2'] * df['bid_size2']
df['ask1_volume'] = df['ask_price1'] * df['ask_size1']
df['ask2_volume'] = df['ask_price2'] * df['ask_size2']
# ボリュームインバランスを計算する
df['imbalance'] = np.absolute((df['ask_size1'] + df['ask_size2']) - (df['bid_size1'] + df['bid_size2']))
# 取引ボリュームインバランスを計算する
df['volume_imbalance'] = np.absolute((df['bid_price1'] * df['bid_size1']) - (df['ask_price1'] * df['ask_size1']))
return df, dframeこれにより、重み付け平均価格(wap1およびwap2)、注文ボリューム、およびボリュームインバランスなどの新しい特徴量が作成されます。合計で、以下を実行することでデータフレームに8つの列が追加されます:
# cuDFデータフレームに列を追加
df_cudf, _ = add_column(df_cudf)
display(df_cudf.head())それにより、以下が得られます:
 Exhibit-15: 列と特徴量の追加 (Image by Author)
Exhibit-15: 列と特徴量の追加 (Image by Author)
7. 列の削除
2つの特徴量、wap1およびwap2を削除することにしました:
# 列の削除
def drop_column(df, dframe=0):
print("列の削除", "\n")
df.drop(columns=['wap1', 'wap2'], inplace=True)
return df, dframe列を削除する実装は以下のようになります:
# cuDFデータフレームに列を削除
df_cudf, _ = drop_column(df_cudf)
display(df_cudf.head())これにより、wap1およびwap2の列がなくなったデータフレームが残ります!
8. グループごとの統計量の計算
次に、time_idごとに平均、中央値、最大値、最小値、標準偏差、および一部の特徴量の合計を計算します。これには、groupbyおよびaggメソッドを使用します。
# 選択された特徴量による統計値の計算
def calc_agg_stats(df, dframe=0):
print("統計量の計算", "\n")
# 計算する統計量
operations = ["mean", "median", "max", "min", "std", "sum"]
# 統計計算を行う特徴量
features_list = ["bid1_volume", "bid2_volume", "ask1_volume", "ask2_volume"]
# 特徴量と計算のペアを格納する辞書の作成
stats_dict = defaultdict(list)
for feature in features_list:
stats_dict[feature].extend(operations)
# 集計統計量の計算
df_stats = df.groupby('time_id', as_index=False, sort=True).agg(stats_dict)
return df, df_statsfeatures_listという名前のリストを作成し、数学的な計算が実行される特徴を指定します。
# Calculate statistics by selected features in cuDF dataframe
_, df_cudf_stats = calc_agg_stats(df_cudf)
display(df_cudf_stats.head())その結果、以下の出力が得られます: Exhibit-16: 計算統計(著者による画像)
Exhibit-16: 計算統計(著者による画像)
返されたテーブルは新しいデータフレームです。元のデータフレーム(df_cudf)とマージする必要があります。それをPandasを使用して実行します:
# Merge data frame with stats
def merge_dataframes_2(df, dframe=0):
if dframe == 0:
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
else:
df = df.to_pandas()
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
df = cudf.DataFrame.from_pandas(df)
return df, dframe
# Merge cuDF data frames
df_cudf, _ = merge_dataframes_2(df_cudf, dframe=1)
display(df_cudf.head())上記のスニペットは、df_pd_statsとdf_pdを1つのデータフレームに置き、df_cudfとして保存します。
いつものように、Pandasに対して同じタスクを繰り返します。
次のステップは、2つの列の間の相関関係を計算することです:
# Calculate correlation between two selected features
def calc_corr(df, dframe=0):
correlation = df[["bid1_volume", "ask1_volume"]].corr()
print(f"'bid1_volume'と'ask1_volume'の相関関係は{correlation}です。\n")
return df, correlationこのコード
# Calculate correlation in cuDF dataframe
_ = calc_corr(df_cudf)以下の出力を返します:
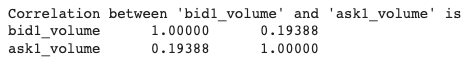 Exhibit-17: 2つの特徴の相関関係の計算(著者による画像)
Exhibit-17: 2つの特徴の相関関係の計算(著者による画像)
9. 列の名前変更
混乱を避けるために、2つの列の名前を変更する必要があります。
# Rename columns
def rename_cols(df, dframe=0):
print("RENAMING COLUMNS", "\n")
df = df.rename(columns={"imbalance": "volume_imbalance", "volume_imbalance": "trade_volume_imbalance"})
return df, dframeColumns imbalanceとvolume_imbalanceは、それぞれvolume_imbalanceとtrade_volume_imbalanceとして名前が変更されます。
10. 列のビニング
行いたいもう1つのデータ操作は、bid1_volumeをビン化して、新しい列に格納することです。
# Bin a selected column
def bin_col(df, dframe=0):
print("BINNING A COLUMN", "\n")
if dframe == 0:
df['bid1_volume_cut'] = pd.cut(df["bid1_volume"], bins=5, labels=["very high", "high", "average", "low", "very low"], ordered=True)
else:
df['bid1_volume_cut'] = cudf.cut(df["bid1_volume"], bins=5, labels=["very high", "high", "average", "low", "very low"], ordered=True)
return df, dframe以下の行を実行することで、
# Bin a selected column in cuDF dataframe
df_cudf, _ = bin_col(df_cudf, dframe=1)
display(df_cudf.head())出力として、以下のようなデータフレームを取得できます:
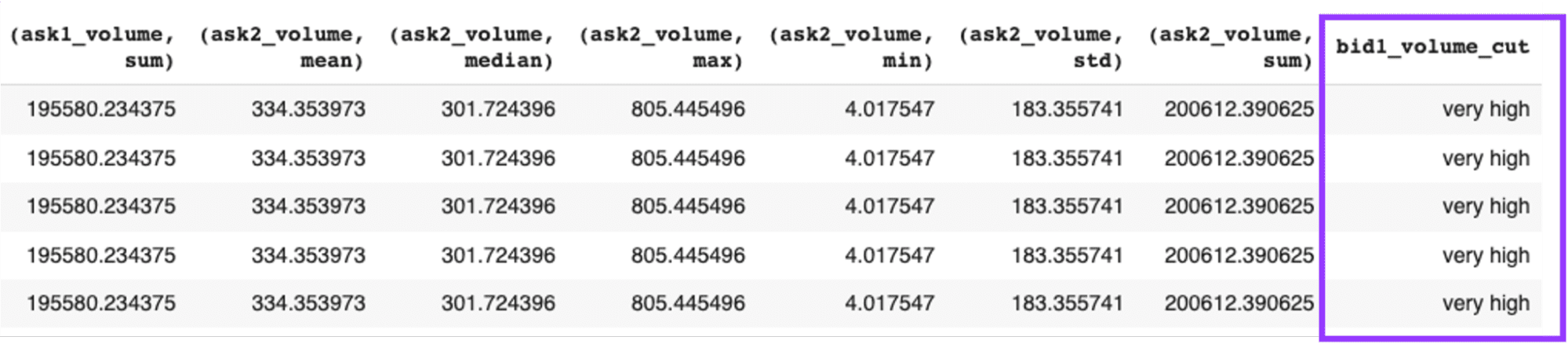 Exhibit-18: 列のビニング(著者による画像)
Exhibit-18: 列のビニング(著者による画像)
11. データフレームの表示
特徴エンジニアリングのステップが完了したら、データフレームを表示できます。このセクションには、データフレームの表示、情報の取得、および説明が含まれます。
# データフレームの表示
def display_df(df, dframe=0):
print("データフレームの表示", "\n")
display(df.head())
print("\n")
return df, dframe
# データフレームの情報を表示
def display_info(df, dframe=0):
print("データフレームの情報を表示", "\n")
display(df.info())
print("\n")
return df, dframe
# データフレームを記述
def describe_df(df, dframe=0):
print("データフレームを記述", "\n")
display(df.describe())
print("\n")
return df, dframe以下のコードは、これらの3つのタスクを完了します:
# cuDFデータフレームと情報を表示
_, _ = display_df(df_cudf, dframe=1)
_, _ = display_info(df_cudf, dframe=1)
_, _ = describe_df(df_cudf, dframe=1)特徴量エンジニアリングは完了しました。
シングルラン実行
まとめると、私たちの特徴量エンジニアリングの取り組みは、以下のタスクに焦点を当てています:
- データフレームの読み込み
- データフレームのマージ
- データ型の変更
- ユニークなtime_idの取得
- ヌル値の確認
- 列の追加
- 列の削除
- 統計量の計算
- 相関の計算
- 列の名前を変更する
- 列をビン化する
- データフレームの表示
- データの情報を表示
- データフレームの記述
タスクは全部で13個ありますが、「相関の計算」をここで別のものとして言及しました。今、これらのタスクを1つのランで順次実行することを目的としています。以下に示します:
def run_and_report():
# 経過時間を格納する辞書を作成する
time_dict = defaultdict(list)
# 実行する操作をリスト化する
labels = ["changing_dtype",
"getting_unique_timeids",
"checking_null_values",
"adding_column",
"dropping_column",
"calculating_agg_stats",
"merging_dataframes",
"renaming_columns",
"binning_col",
"calculating_corr",
"displaying_dfs",
"displaying_info",
"describing_dfs"]
# Pandasオーダーデータフレームをロードして時間を計算する
df_pd_order, pd_order_loading_time = load_dataframe(order_files, dframe=0)
print("-"*150, "\n")
# cuDFブックデータフレームをロードして時間を計算する
df_cudf_order, cudf_order_loading_time = load_dataframe(order_files, dframe=1)
print("-"*150, "\n")
# Pandasトレードデータフレームをロードして時間を計算する
df_pd_trade, pd_trade_loading_time = load_dataframe(trade_files, dframe=0)
print("-"*150, "\n")
# cuDFトレードデータフレームをロードして時間を計算する
df_cudf_trade, cudf_trade_loading_time = load_dataframe(trade_files, dframe=1)
print("-"*150, "\n")
# Pandasデータフレームからtime_idを取得する
_, time_ids = get_unique_timeids(df_pd_order, dframe=0)
print("-"*150, "\n")
# cuDFデータフレームからtime_idを取得する
_, time_ids = get_unique_timeids(df_cudf_order, dframe=1)
print("-"*150, "\n")
# ローディング時間を格納する
time_dict["loading_dfs"].extend([pd_order_loading_time, cudf_order_loading_time])
# orderデータフレームを前方埋めする
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
# tradeデータフレームを前方埋めする
expanded_df_pd_trade, expanded_df_cudf_trade = ffill(df_pd_trade, df_name="trade")
# Pandas orderデータフレームとtradeデータフレームをマージする
df_pd, pd_merge_time = merge_dataframes(expanded_df_pd_order, expanded_df_pd_trade, dframe=0)
print("-"*150, "\n")
# cuDF orderデータフレームとtradeデータフレームをマージする
df_cudf, cudf_merge_time = merge_dataframes(expanded_df_cudf_order, expanded_df_cudf_trade, dframe=1)
print("-"*150, "\n")
# マージ時間を格納する
time_dict["merging_dfs"].extend([pd_merge_time, cudf_merge_time])
# 関数を適用する
functions = [change_dtype,
get_unique_timeids,
check_null_values,
add_column,
drop_column,
calc_agg_stats,
merge_dataframes_2,
rename_cols,
bin_col,
calc_corr,
display_df,
display_info,
describe_df]
for label, function in enumerate(functions):
# Pandas用の関数
start_pd = time.time()
df_pd, x = function(df_pd, dframe=0)
end_pd = time.time()
elapsed_time_for_pd = round(end_pd-start_pd, 3)
print(f"Pandasデータフレーム用: \n 開始時間: {start_pd} \n 終了時間: {end_pd} \n 経過時間: {elapsed_time_for_pd} \n")
# cuDF用の関数
start_cudf = time.time()
df_cudf, x = function(df_cudf, dframe=1)
end_cudf = time.time()
elapsed_time_for_cudf = round(end_cudf-start_cudf, 3)
print(f"cuDFデータフレーム用: \n 開始時間: {start_cudf} \n 終了時間: {end_cudf} \n 経過時間: {elapsed_time_for_cudf} \n")
print("-"*150, "\n")
# 経過時間を格納する
time_dict[labels[label]].extend([elapsed_time_for_pd, elapsed_time_for_cudf])
# 不要な時間間隔を削除する
del time_dict["merging_dataframes"]
labels.remove("merging_dataframes")
labels.insert(0, "merging_dfs")
labels.insert(0, "loading_dfs")
print(time_dict)
return time_dict, labels, df_pd, df_cudfrun_and_report関数は、以前と同じ出力を与えますが、単一の実行コマンドで完全なレポートを提供します。PandasとcuDFの両方で14のタスクを実行し、両方のデータフレームの時間を記録します。
time_dict、labels、df_pd、df_cudf = run_and_report()両方のデータライブラリの性能の相対的な違いをより大胆に見るために、複数のサイクルを実行する必要がある場合があります。
最終評価
たとえば、ラウンドのようにrun_and_reportを複数回実行すると、PandasとcuDFのパフォーマンスの違いをよりよく把握できます。 したがって、ラウンドを30に設定します。 次に、すべての操作、ラウンド、およびデータライブラリの時間を記録し、最終的に結果を評価します。
def calc_exec_times():
exec_times_by_round = {}
# Calculate execution times of operations in each round
for round_no in range(1, ROUNDS+1):
# cycle_no += 1
time_dict, labels, df_pd, df_cudf = run_and_report()
exec_times_by_round[round_no] = time_dict
print("exec_times_by_round: ", exec_times_by_round)
# Get durations by operation for each data frame
pd_summary, cudf_summary = get_statistics(exec_times_by_round, labels)
# Get durations by rounds for each data frame
round_total = get_total(exec_times_by_round)
print("\n"*3)
# Plot durations
plt.style.use('dark_background')
X_axis = np.arange(len(labels))
# Plot average duration of operation
plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis)
print("\n"*3)
# Plot total and difference in duration by operation
plot_diff_by_df(pd_summary, cudf_summary, labels)
print("\n"*3)
# Plot total and difference in duration by round
plot_total_by_df(round_total)
print("\n"*3)calc_exec_times関数は、いくつかのタスクを実行します。最初に、各データライブラリの「操作ごとの平均および合計時間」を30ラウンドごとに取得するためにget_statisticsを呼び出します。
def get_statistics(exec_times_by_round, labels):
# Separate and store duration statistics by data frame
pd_performance = defaultdict(list)
cudf_performance = defaultdict(list)
# Get and store durations for each operation by data frame
for label in labels:
for key, values in exec_times_by_round.items():
pd_performance[label].append(values[label][0])
cudf_performance[label].append(values[label][1])
print("pd_performance: ", pd_performance)
print("cudf_performance: ", cudf_performance)
# Compute average and total durations for each operation by data frame
pd_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in pd_performance.items()}
cudf_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in cudf_performance.items()}
print("pd_summary: ", pd_summary)
print("cudf_summary: ", cudf_summary)
return pd_summary, cudf_summary次に、それぞれのデータフレームについて「ラウンド別の合計時間」を計算します。
def get_total(exec_times_by_round):
def get_round_total(stat_list):
# Get total duration by round for each data frame
pd_round_total = round(sum([x[0] for x in stat_list]), 3)
cudf_round_total = round(sum([x[1] for x in stat_list]), 3)
return pd_round_total, cudf_round_total
# Collect total durations by round
for key, value in exec_times_by_round.items():
round_total = {key: get_round_total(list(value.values())) for key, value in exec_times_by_round.items()}
print("round_total", round_total)
return round_total最後に、結果をプロットします。ここでは、最初のプロットは両方のライブラリに対して「操作ごとの平均時間」です。
def plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis):
# Figure size
fig = plt.subplots(figsize =(10, 4))
# Average duration by operation for each data frame
pd_avg = [value[1] for key, value in pd_summary.items()]
cudf_avg = [value[1] for key, value in cudf_summary.items()]
plt.bar(X_axis - 0.2, pd_avg, 0.4, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(X_axis + 0.2, cudf_avg, 0.4, color = '#C8C8FF', label = 'cuDF', align='center')
plt.xticks(X_axis, labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("Operations", fontsize=10)
plt.ylabel("Average Duration in Seconds", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Average Duration of Operation by Data Frame", fontsize=12)
plt.legend()
plt.show()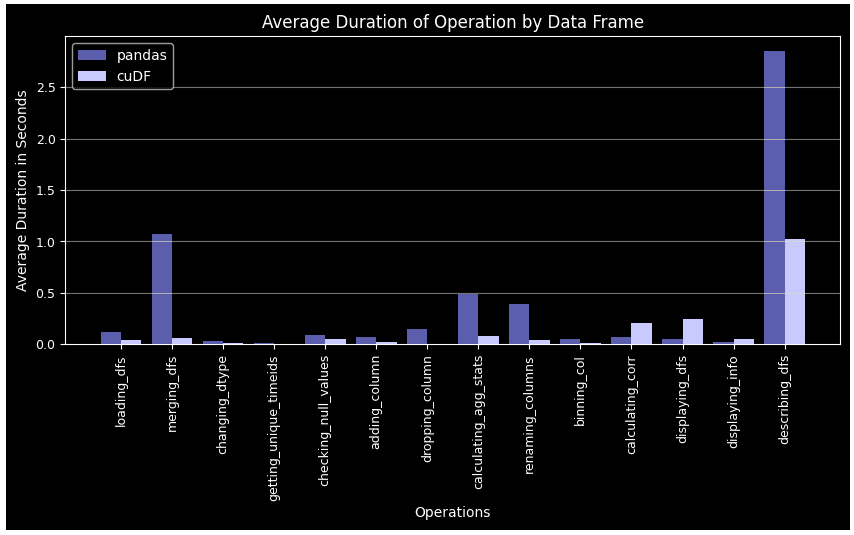 Exhibit-19: PandasデータフレームとcuDFの操作ごとの平均所要時間(Image by Author)
Exhibit-19: PandasデータフレームとcuDFの操作ごとの平均所要時間(Image by Author)
2番目のプロットは「操作ごとの総所要時間」であり、各タスクが30ラウンド全体でかかった合計時間を示します。
def plot_diff_by_df(pd_summary, cudf_summary, labels):
# Figure size
fig = plt.subplots(figsize =(12, 6))
# 各データフレームの操作ごとの総所要時間
pd_total = [value[0] for key, value in pd_summary.items()]
cudf_total = [value[0] for key, value in cudf_summary.items()]
# データフレームごとの総所要時間の差
diff = [x[0]-x[1] for x in zip(pd_total, cudf_total)]
# バーの幅を設定
barWidth = 0.25
# X軸のバーの位置を設定
br1 = np.arange(len(labels))
br2 = [x + barWidth for x in br1]
br3 = [x + barWidth for x in br2]
plt.bar(br1, pd_total, barWidth, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(br2, cudf_total, barWidth, color = '#C8C8FF', label = 'cuDF', align='center')
plt.bar(br3, diff, barWidth, color = '#AA1E1E', label = '差', align='center')
plt.xticks([r + barWidth for r in range(len(labels))], labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("操作", fontsize=10)
plt.ylabel("総所要時間(秒)", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("データフレームごとの操作の総所要時間", fontsize=12)
plt.legend()
plt.show()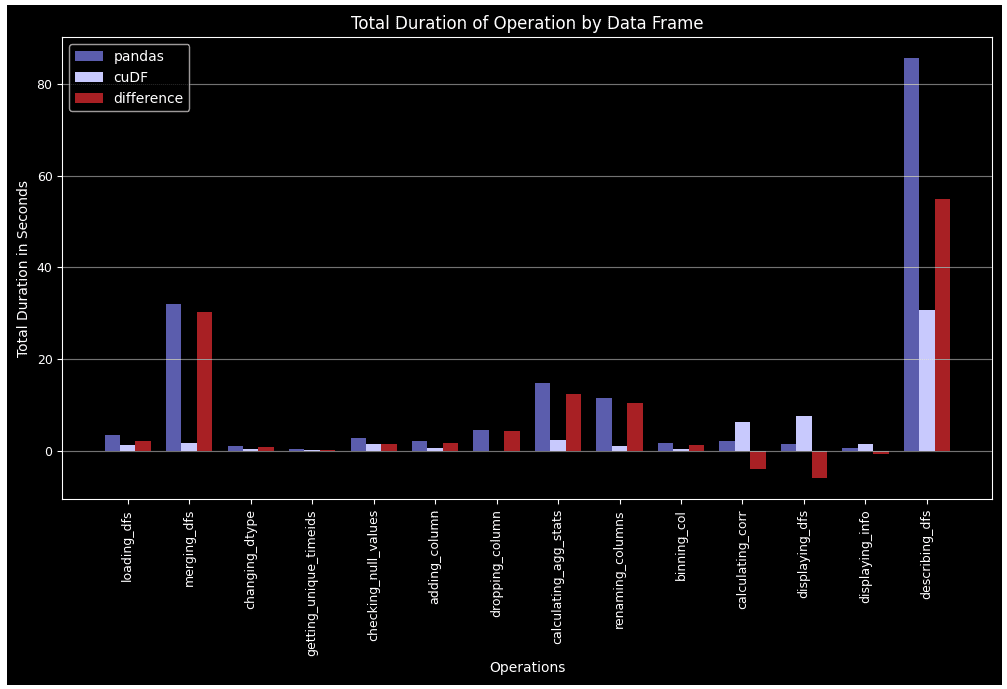 Exhibit-20: PandasデータフレームとcuDFの操作ごとの30ラウンドの総所要時間(Image by Author)
Exhibit-20: PandasデータフレームとcuDFの操作ごとの30ラウンドの総所要時間(Image by Author)
最後のプロットは「ラウンドごとの総所要時間」であり、各ラウンドですべての操作にかかった合計時間を示します。
def plot_total_by_df(round_total):
# Figure size
fig = plt.subplots(figsize =(10, 6))
X_axis = np.arange(1, ROUNDS+1)
# 各データフレームのラウンドごとの総所要時間
pd_round_total = [value[0] for key, value in round_total.items()]
cudf_round_total = [value[1] for key, value in round_total.items()]
# データフレームごとのラウンドごとの総所要時間の差
diff = [x[0]-x[1] for x in zip(pd_round_total, cudf_round_total)]
plt.plot(X_axis, pd_round_total, linestyle="-", linewidth=3, color = '#5A5AAF', label = "pandas")
plt.plot(X_axis, cudf_round_total, linestyle="-", linewidth=3, color = '#B0B05A', label = "cuDF")
plt.plot(X_axis, diff, linestyle="--", linewidth=3, color = '#AA1E1E', label = "差")
plt.xticks(X_axis, fontsize=9)
plt.yticks(fontsize=9)
plt.xlabel("ラウンド", fontsize=10)
plt.ylabel("総所要時間(秒)", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("ラウンドごとの総所要時間", fontsize=12)
plt.legend()
plt.show()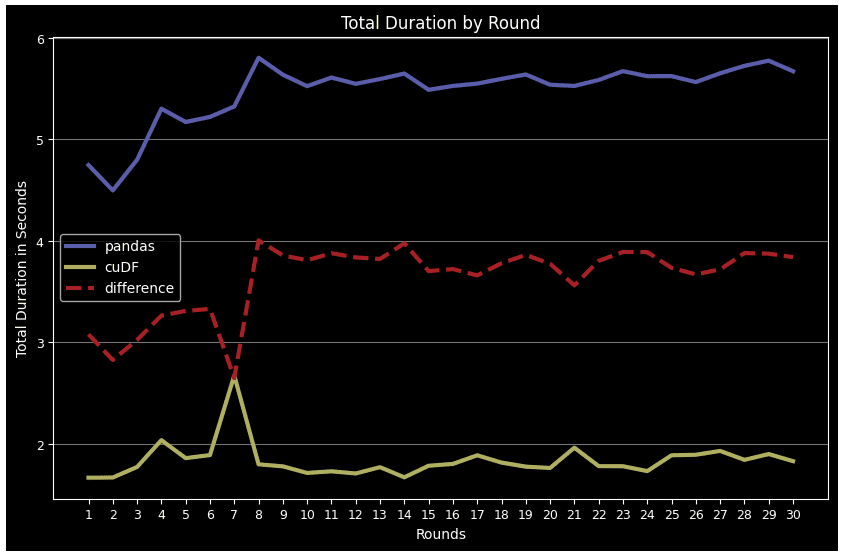 Exhibit-21: PandasデータフレームとcuDFの各ラウンドの全操作の総所要時間(Image by Author)
Exhibit-21: PandasデータフレームとcuDFの各ラウンドの全操作の総所要時間(Image by Author)
私たちはデータセットに対して実行された全ての特徴量エンジニアリングタスクをカバーしているわけではありませんが、これらはここで示したものと同じまたは類似しています。14の操作を個別に説明することで、PandasデータフレームとcuDFの相対的なパフォーマンスを文書化し、再現性を確保しようとしました。
相関計算とデータフレームの表示以外のすべての場合において、cuDFはPandasを上回っています。グループバイ、マージ、agg、describeなどの複雑なタスクでは、このパフォーマンスの差はより著しくなります。また、Pandas DFはより多くのラウンドが経過するにつれて疲れてしまうのに対し、cuDFはより安定したパターンに従います。
1つの銘柄のみを例として扱っていることに注意してください。112の株をすべて処理すると、cuDFが有利になるより大きなパフォーマンス差が予想されます。株式の人口が数百になると、cuDFのパフォーマンスはさらに劇的になる可能性があります。並列タスクの実行が可能なビッグデータの場合、cuDF GPUデータフレームをパラレルコンピューティングに拡張するDask-cuDFのような分散フレームワークが適切なツールになる可能性があります。
参考文献
[1] RAPIDS Definition, https://www.heavy.ai/technical-glossary/rapids
[2] 10 Minutes to cuDF and Dask-cuDF, https://docs.rapids.ai/api/cudf/stable/user_guide/10min/
[3] Optiver Realized Volatility Prediction, https://www.kaggle.com/competitions/optiver-realized-volatility-prediction/data
[4] Forward filling book data, https://www.kaggle.com/competitions/optiver-realized-volatility-prediction/discussion/251277 Hasan Serdar Altan はデータサイエンティストであり、AWSクラウドアーキテクトアソシエイトです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
