「メタのLlama 2の力を明らかにする:創発型AIの飛躍?」
Unveiling the Power of Meta Llama 2 A Leap in Emergent AI?

紹介
人工知能(AI)における最近のブレークスルー、特に生成型AIにおけるブレークスルーは、公衆の関心を引き、これらの技術が新たな経済と社会の機会を創出する可能性を示しています。そのようなブレークスルーの一つが、MetaのLlama 2です。これは、彼らのオープンソースの大規模言語モデルの次世代です。
- 「オムニスピーチは、次世代のAI音声アルゴリズムにより、自動車、モバイル、消費者、およびIoTの顧客により良いサービスを提供するために、ケイデンス・テンシリカ・オーディオ・ソフトウェア・パートナーとなりました」
- 「ユネスコ、AIチップの埋め込みに関するプライバシー懸念を指摘」
- 元GoogleのCEOがAIとメタバースを使って米軍を強化することを発表
MetaのLlama 2は、公に利用可能なデータの混合物でトレーニングされ、OpenAIのChatGPT、Bing Chat、および他の最新のチャットボットなどのアプリケーションを推進するように設計されています。公に利用可能なデータの混合物でトレーニングされたLlama 2は、先行するLlamaモデルよりも性能が大幅に向上しているとMetaは主張しています。このモデルは、AWS、Azure、およびHugging FaceのAIモデルホスティングプラットフォームで事前学習済み形式で微調整が可能であり、よりアクセスしやすく実行しやすくなっています。モデルはこちらからもダウンロードできます。
しかし、Llama 2はその前身や他の大規模言語モデルとは何が違うのでしょうか? その技術的な詳細と意義について探ってみましょう。
技術的な詳細と性能
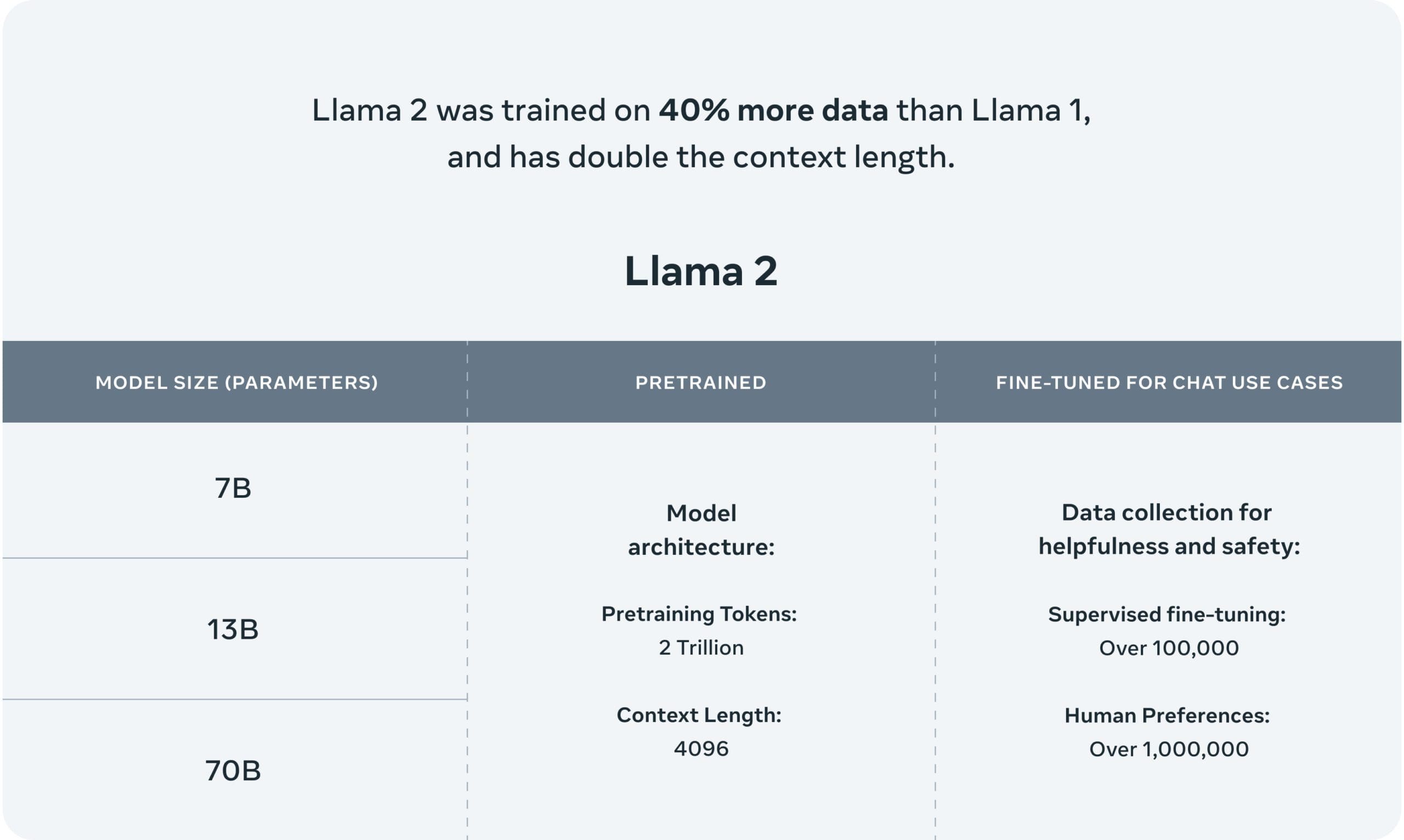
Llama 2には2つのバリエーションがあります:Llama 2とLlama-2-Chatです。Llama-2-Chatは、双方向の会話に適した微調整が施されています。両バージョンとも、さまざまな洗練度のモデルにさらに分割されています:70億パラメータ、130億パラメータ、および700億パラメータのモデルです。これらのモデルは、第一世代のLlamaモデルよりも40%多い2兆のトークン、および100万を超える人間のアノテーションを含むデータでトレーニングされました。
Llama 2のコンテキスト長は4096であり、Llama-Chat-2のトレーニングにおいて特に安全性と支援性のために人間のフィードバックから強化学習を採用しています。Metaによれば、Llama 2は、推論、コーディング、熟練度、および知識テストの領域で、FalconやMPTなどの他のLLMよりも優れた性能を発揮します。
さらに、Llama 2は、Windows上およびQualcommのSnapdragon搭載のスマートフォンやPC上でローカルに実行するように最適化されており、2024年からクラウドサービスに頼らないAIパワードのアプリが期待できます。
“これらの新しいSnapdragonによるオンデバイスAI体験は、接続がないエリアや飛行機モードでも動作することができます。”
—Qualcomm(出典:CNET)
オープンソースと安全性
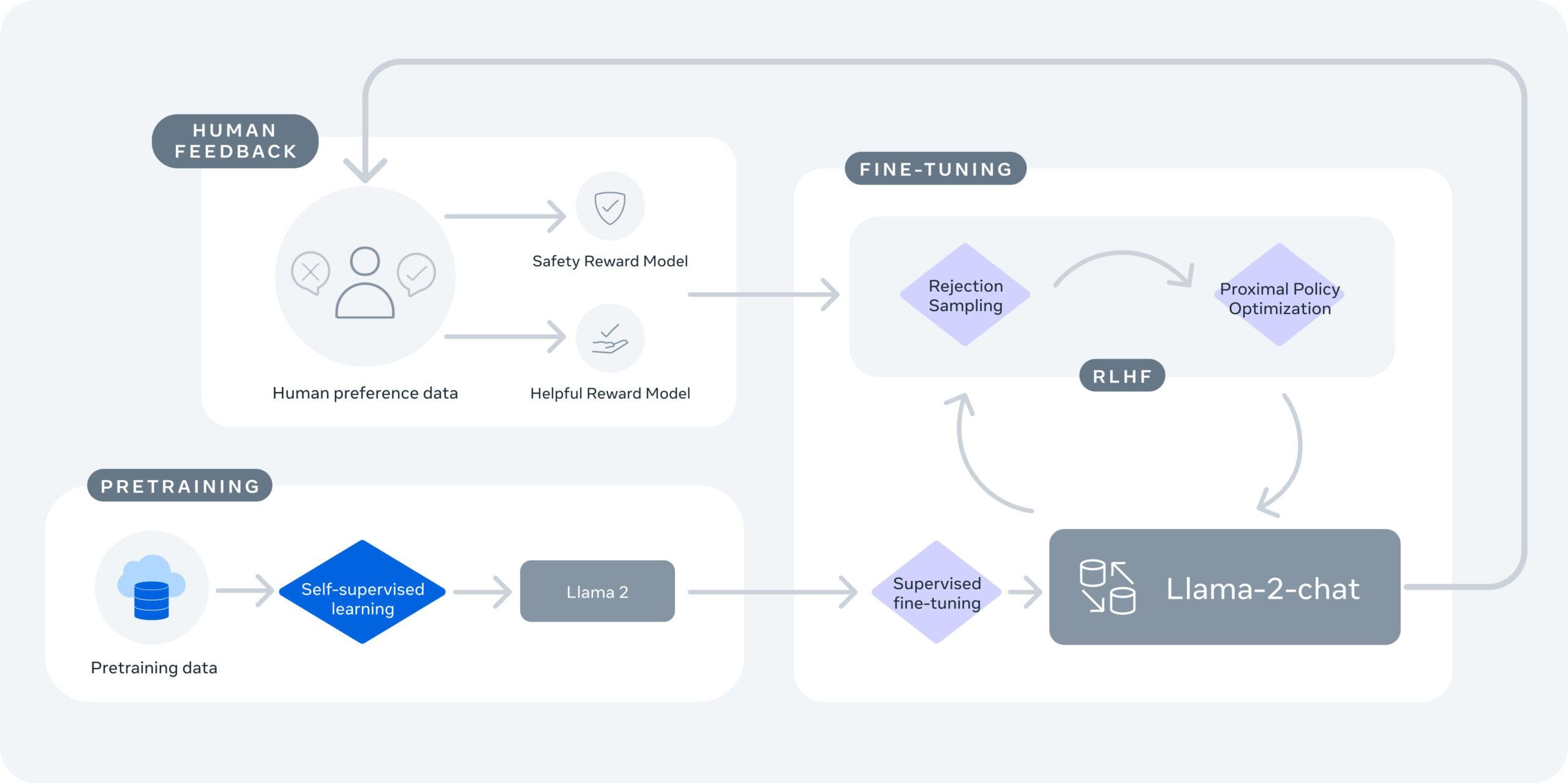
Llama 2の鍵となる要素の一つは、そのオープンソース性です。Metaは、AIモデルを公開することで、誰もが利益を得ることができると考えています。この開発により、ビジネス界と研究界の両方が、自分たちで開発とスケールを行うのが困難になるツールにアクセスできるようになり、研究、実験、開発のための数多くの機会が生まれます。
Metaはまた、安全性と透明性を重視しています。Llama 2は「レッドチーム」でテストされ、モデルの微調整のために敵対的なプロンプトを生成することで安全性が確認されています。Metaはモデルの評価と調整方法を開示し、開発プロセスの透明性を促進しています。
結論
Llama 2は、生成型AIの分野におけるMetaの視点を継続するために最善を尽くしています。改善されたパフォーマンス、オープンソース性、安全性と透明性への取り組みにより、Llama 2は幅広いアプリケーションにおいて有望なモデルとなっています。より多くの開発者や研究者がアクセスできるようになるにつれて、革新的なAIパワードのソリューションの急増が期待されます。
今後も、AIモデルに固有の課題やバイアスに取り組み続けることは重要です。ただし、Metaの安全性と透明性への取り組みは、業界にとって良い先例となっています。Llama 2のリリースにより、生成型AIのアーセナルに利用可能な別のツールが追加され、オープンアクセスが継続的な取り組みとなります。
Matthew Mayo (@mattmayo13) はデータサイエンティストであり、VoAGIの編集長です。VoAGIは、オンラインのデータサイエンスと機械学習のリソースです。彼の関心は、自然言語処理、アルゴリズム設計と最適化、教師なし学習、ニューラルネットワーク、および自動化アプローチにあります。Matthewはコンピュータサイエンスの修士号とデータマイニングの修士課程を取得しています。彼には、editor1 at VoAGI[dot]comで連絡することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






