「隠れたパターンの解明:階層クラスタリングの紹介」
「隠れたパターンの解明:階層クラスタリングの魅力」
非監視学習のパラダイムに慣れていくと、クラスタリングアルゴリズムについて学びます。クラスタリングの目的は、与えられたラベルのないデータセットにおけるパターンを理解することです。または、データセット内のグループを見つけ出してラベルを付け、ラベルのついたデータセットで教師あり学習を行うことができるようにすることもあります。この記事では、階層的クラスタリングの基礎をカバーします。
階層的クラスタリングとは?
階層的クラスタリングアルゴリズムは、インスタンス間の類似性を見つけ出し(距離メトリックで定量化される)、それらをクラスタと呼ばれるセグメントにグループ化することを目指しています。
このアルゴリズムの目標は、クラスタ内のデータポイントが他のクラスタのデータポイントよりもお互いに似ているほど良いクラスタを見つけることです。
一般的に使われる2つの階層的クラスタリングアルゴリズムがあります。それぞれのアプローチによって異なります。
- 凝集型クラスタリング
- 分割型クラスタリング
凝集型クラスタリング
データセットにn個の異なるデータポイントがあるとします。凝集型クラスタリングの動作は以下の通りです:
- n個のクラスタで開始します。それぞれのデータポイントは1つのクラスタです。
- 類似性に基づいてデータポイントをグループ化します。つまり、距離に基づいて似たクラスタをマージします。
- 一つのクラスタになるまでステップ2を繰り返します。
分割型クラスタリング
名前が示す通り、分割型クラスタリングは凝集型クラスタリングの逆を試みます:
- すべてのn個のデータポイントが1つのクラスタに存在します。
- この単一の大きなクラスタを小さなグループに分割します。凝集型クラスタリングではデータポイントのグループ化は類似性に基づいて行われますが、異なるクラスタに分割する場合はデータポイント同士の非類似性に基づいています。
- 各データポイントがそれぞれ1つのクラスタになるまで繰り返します。
距離メトリクス
前述のように、データポイント間の類似性は距離で定量化されます。よく使用される距離メトリクスには、ユークリッド距離およびマンハッタン距離があります。
任意の二つのn次元特徴空間上のデータポイント間のユークリッド距離は以下の式で表されます:
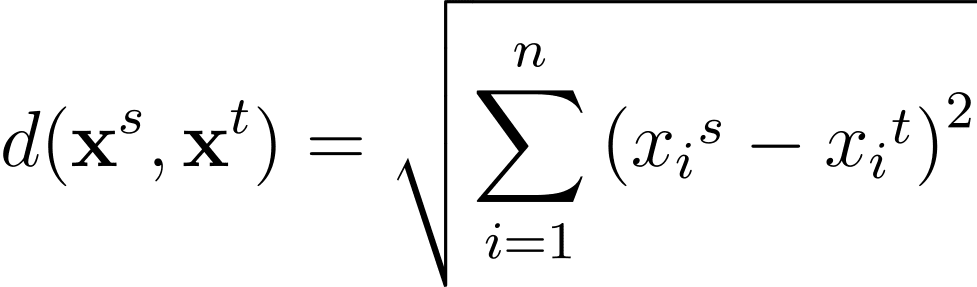
もう一つよく使用される距離メトリクスは、マンハッタン距離です。以下の式で表されます:
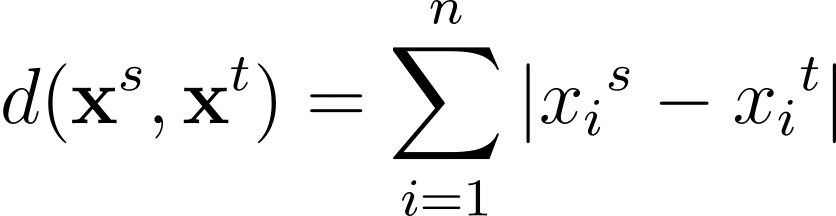
ミンコウスキー距離は、これらの距離メトリクスをn次元空間での一般化(p≥1の一般的なpの値に対して)です:
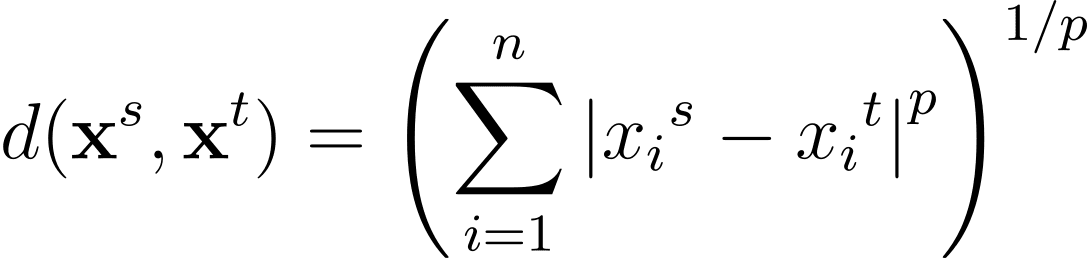
クラスタ間距離:リンケージ基準の理解
距離メトリクスを使用して、データセット内の任意の2つのデータポイント間の距離を計算することはできますが、各ステップでクラスタを「どのように」グループ化するかを決めるために距離を定義する必要があります。
凝集型クラスタリングの各ステップで、最も近い2つのグループをマージします。これはリンケージ基準によって捉えられます。一般的に使用されるリンケージ基準には以下があります:
- 単一リンケージ
- 完全リンケージ
- 平均リンケージ
- ワードリンケージ
単一リンケージ
単一リンケージまたは単一リンククラスタリングでは、2つのグループ/クラスタ間の距離は、それらの2つのクラスタ内のすべてのデータポイントの距離のうち最小の距離として扱われます。
完全連結
完全連結または完全連結クラスタリングでは、2つのクラスタ間の距離は、2つのクラスタ内のすべての点の距離のうち最大の距離として選択されます。
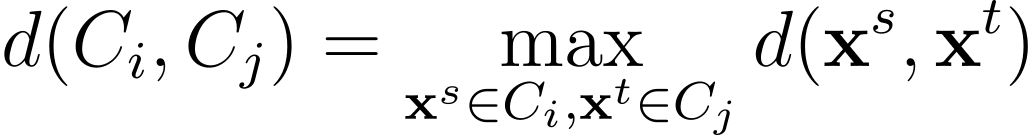
平均連結
平均連結を使用する場合もあります。平均連結では、2つのクラスタ内のすべてのデータ点間の距離の平均を使用します。
ウォード法
ウォード法は、マージされたクラスタ内の分散を最小化することを目指します。マージされた後の分散の増加を最小限に抑えるように、クラスタをマージします。これにより、よりコンパクトでよく分離されたクラスタが得られます。
マージされるクラスタの分散の増加(分散)の合計二乗偏差を考慮して、2つのクラスタ間の距離が計算されます。アイデアは、マージ前の個々のクラスタの分散と比較して、マージされたクラスタの分散がどれだけ増加するかを測定することです。
Pythonで階層的クラスタリングをコーディングする際にも、ウォード法を使用します。
デンドログラムとは何ですか?
クラスタリングの結果をデンドログラムとして視覚化することができます。デンドログラムは、データポイントやクラスタがアルゴリズムの進行に従ってどのようにグループ化またはマージされるかを理解するのに役立つ階層的ツリー構造です。
階層的ツリー構造では、葉はデータセット内のインスタンスまたはデータポイントを表します。グループ化またはマージが行われる対応する距離は、y軸から推測できます。
リンケージのタイプによってデータポイントのグループ化方法が異なるため、異なるリンケージ基準では異なるデンドログラムが生成されます。
距離に基づいて、デンドログラムを特定のポイントでカットまたはスライスして必要な数のクラスタを取得することができます。
一部のクラスタリングアルゴリズム(K-Meansクラスタリングなど)とは異なり、階層的クラスタリングでは事前にクラスタの数を指定する必要はありません。ただし、大規模なデータセットを使用する場合、集約型クラスタリングは計算コストが非常に高くなる場合があります。
SciPyを使用したPythonでの階層的クラスタリング
次に、組み込みのワインデータセットに対して階層的クラスタリングを逐次実行します。これには、SciPyのクラスタリングパッケージであるscipy.clusterを利用します。
ステップ1 – 必要なライブラリのインポート
まず、scikit-learnおよびSciPyのライブラリと必要なモジュールをインポートしましょう。
# importsimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_winefrom sklearn.preprocessing import MinMaxScalerfrom scipy.cluster.hierarchy import dendrogram, linkageステップ2 – データセットの読み込みと前処理
次に、ワインデータセットをpandasのデータフレームに読み込みます。これはシンプルなデータセットであり、scikit-learnのdatasetsに含まれており、階層的クラスタリングの探索に役立ちます。
# Load the datasetdata = load_wine()X = data.data# Convert to DataFramewine_df = pd.DataFrame(X, columns=data.feature_names)データフレームの最初のいくつかの行を確認しましょう。
wine_df.head()
 ワイン_df.head()の抜き出し出力
ワイン_df.head()の抜き出し出力
データセット内のグループを発見するために、出力ラベルではなく、特徴のみを読み込んでクラスタリングを行うことに注意してください。
データフレームの形状をチェックしましょう:
print(wine_df.shape)
データフレームには178の記録と14の特徴があります:
Output >>> (178, 14)
データセットには異なる範囲に広がる数値が含まれているため、データセットを前処理しましょう。各特徴を[0, 1]の範囲の値に変換するために、MinMaxScalerを使用します。
# 特徴をMinMaxScalerを使用してスケーリングscaler = MinMaxScaler()X_scaled = scaler.fit_transform(X)
ステップ3 – 階層的クラスタリングを行い、デンドログラムをプロットする
リンケージ行列を計算し、クラスタリングを行い、デンドログラムをプロットしましょう。リンケージ行列はWardのリンケージに基づいて計算するために、階層モジュールのリンケージを使用できます(methodを’ward’に設定)。
前述のように、Wardのリンケージは各クラスタ内の分散を最小化します。そして、デンドログラムを使って階層的クラスタリングプロセスを可視化します。
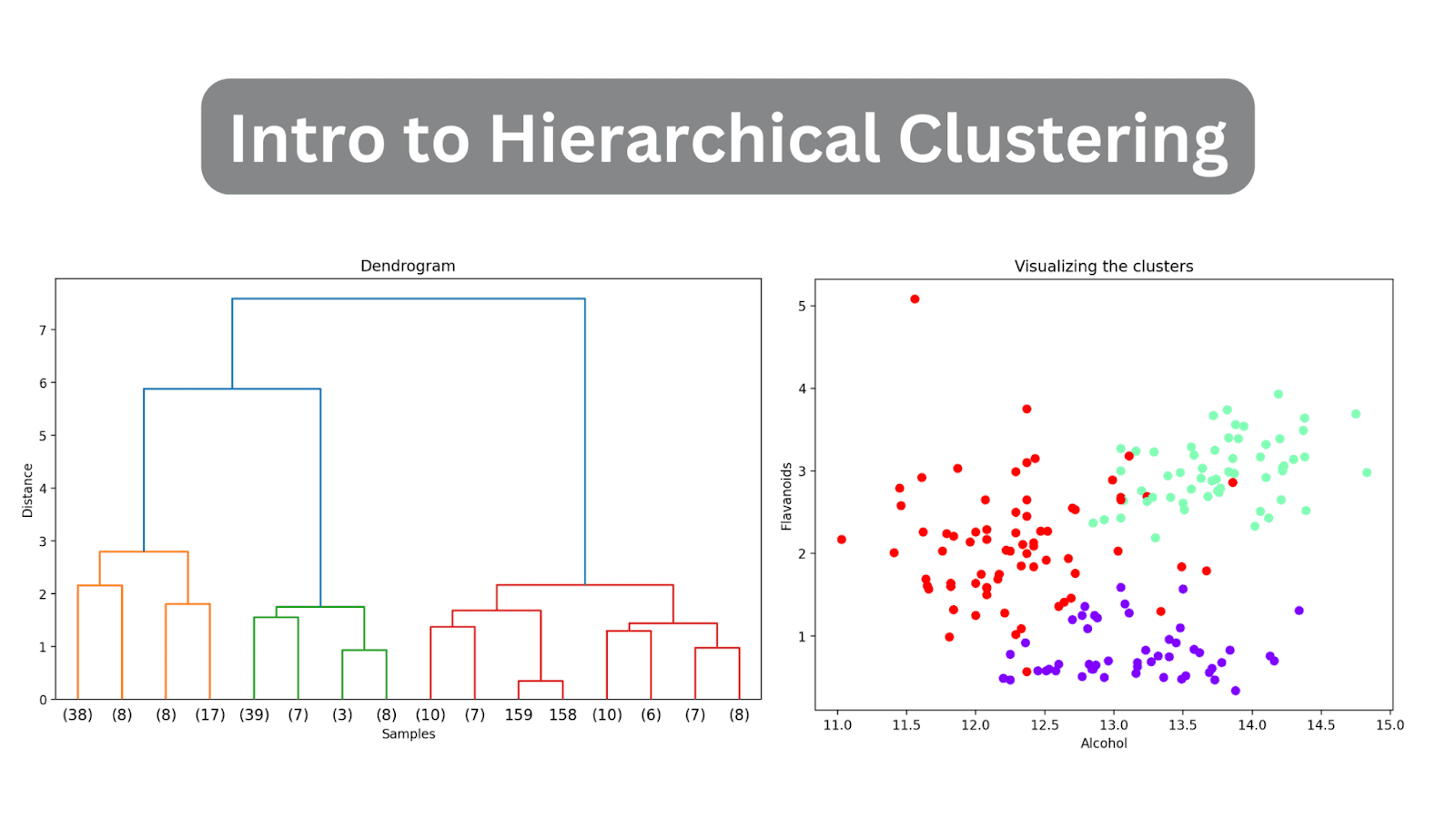
# リンケージ行列を計算linked = linkage(X_scaled, method='ward')# デンドログラムをプロットplt.figure(figsize=(10, 6),dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)plt.title('デンドログラム')plt.xlabel('サンプル')plt.ylabel('距離')plt.show()
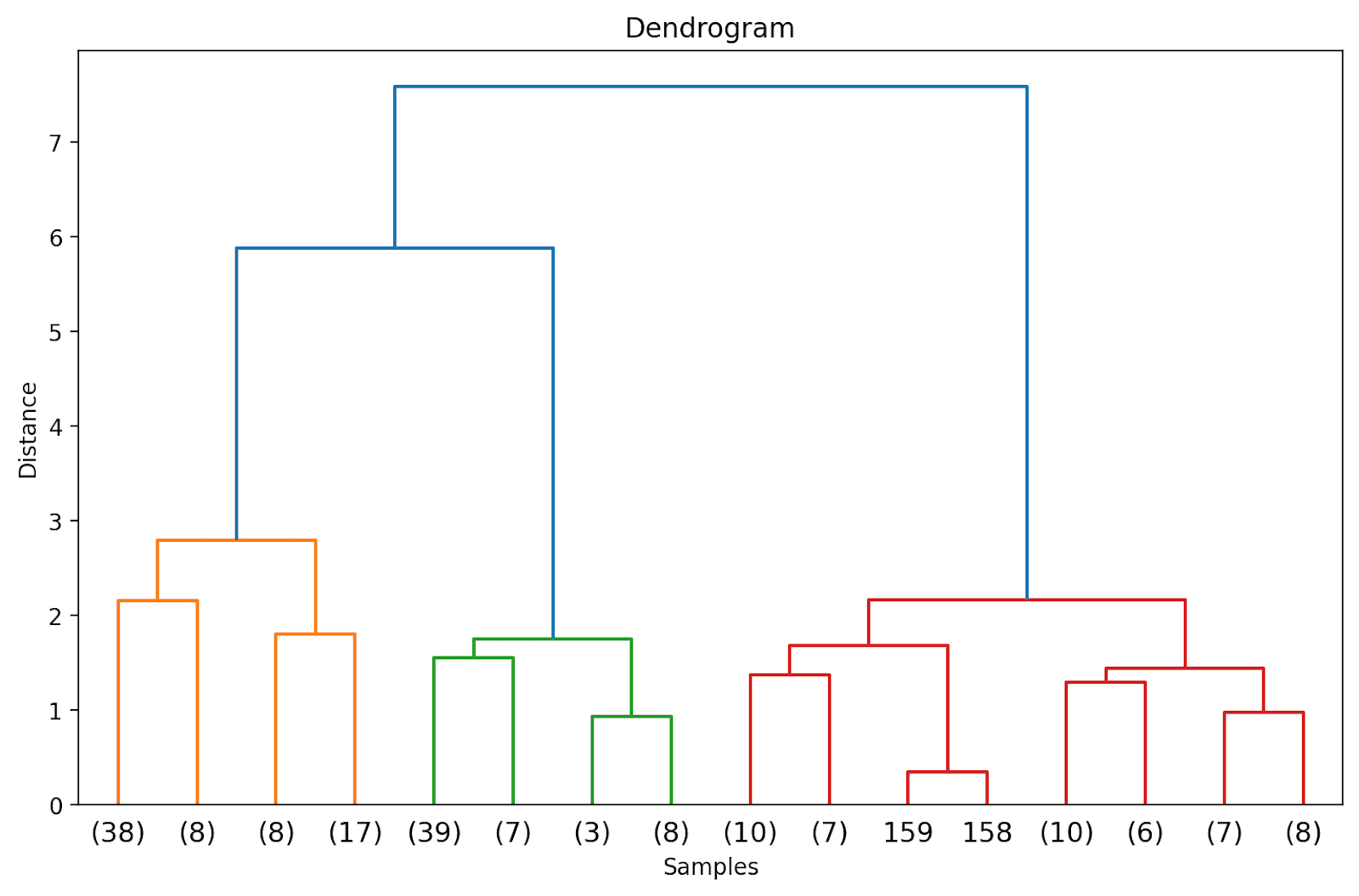
デンドログラムをまだ切り詰めていないため、178のデータポイントが単一のクラスタにグループ化されている様子を視覚化することができます。これは解釈が難しいようですが、3つの異なるクラスタが存在することがわかります。
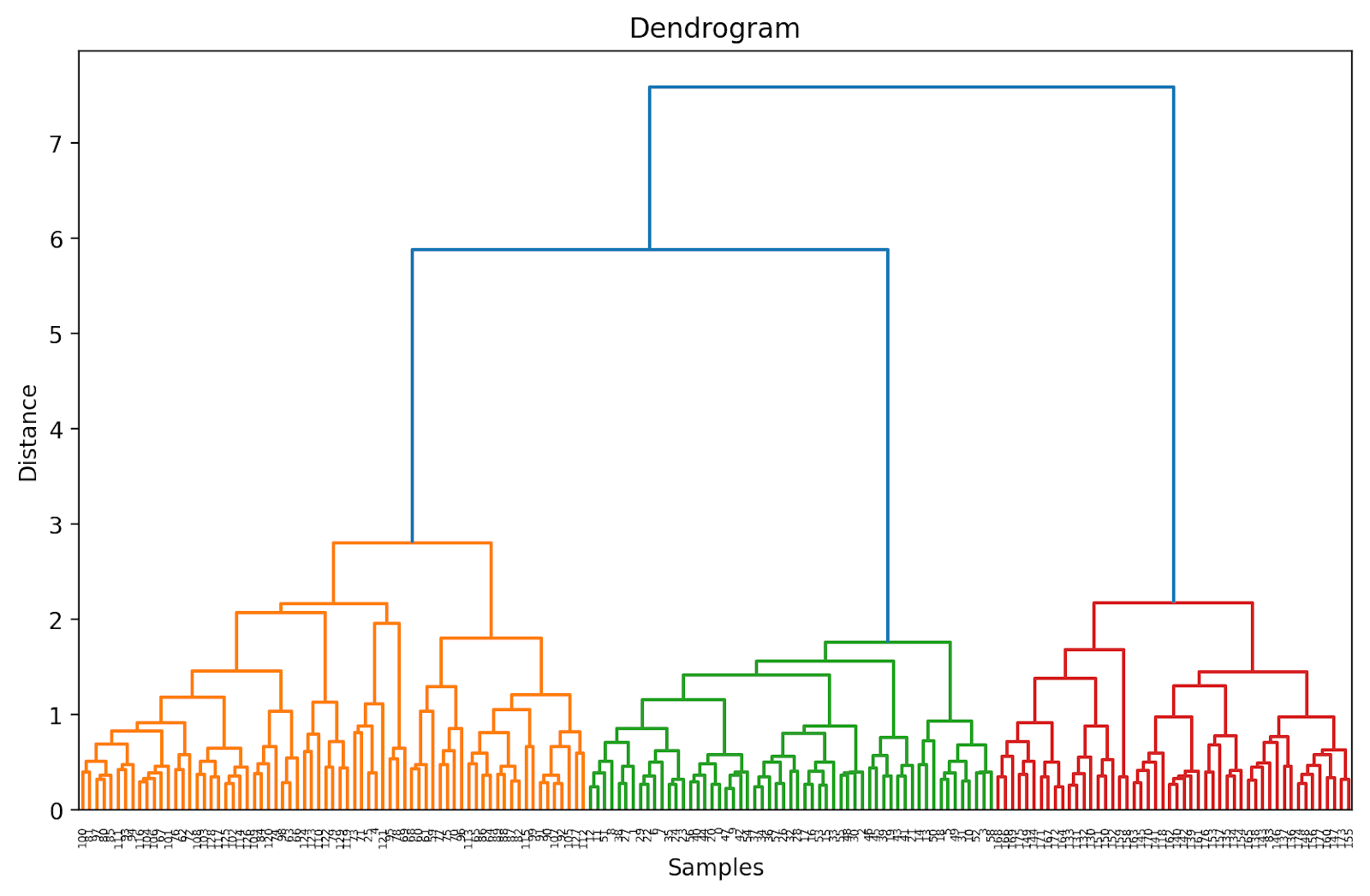
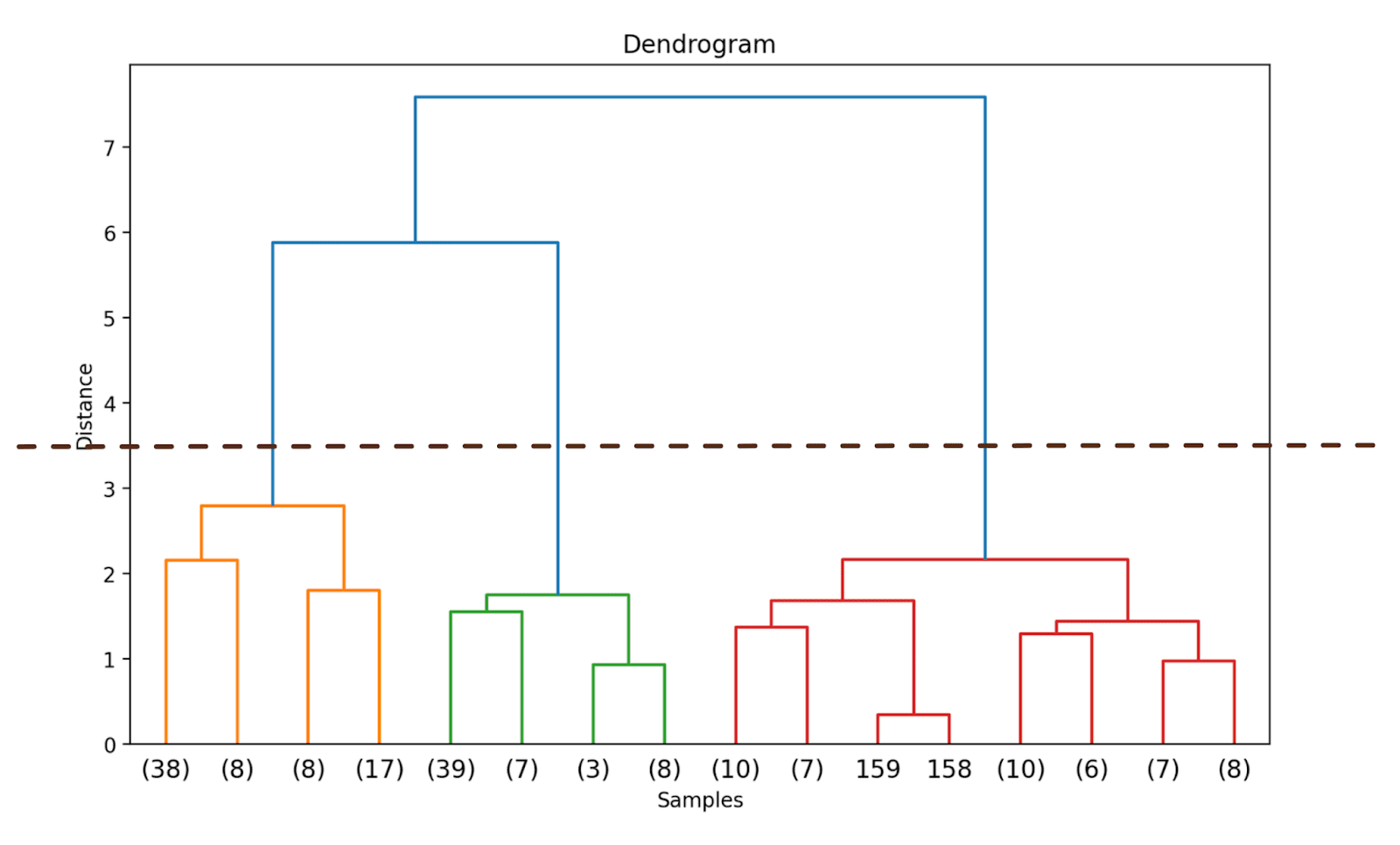
デンドログラムの切り詰めてより簡単に視覚化する
実際には、完全なデンドログラムの代わりに、解釈と理解が容易な切り詰めたバージョンを視覚化することができます。
デンドログラムを切り詰めるには、truncate_modeを’level’に設定し、p = 3とします。
# リンケージ行列を計算linked = linkage(X_scaled, method='ward')# デンドログラムをプロットplt.figure(figsize=(10, 6),dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', truncate_mode='level', p=3, show_leaf_counts=True)plt.title('デンドログラム')plt.xlabel('サンプル')plt.ylabel('距離')plt.show()
これにより、デンドログラムは、最終的なマージから3レベル以内のクラスタのみを含むように切り詰められます。
上記のデンドログラムでは、158と159などの一部のデータポイントが個別に表示されていることがわかります。一方、他のデータポイントは括弧内に表示されています。これらは個々のデータポイントではなく、クラスタ内のデータポイントの数です。 (k) はk個のサンプルを含むクラスタを示します。
ステップ4 – 最適なクラスタ数の特定
デンドログラムは、最適なクラスタ数を選ぶのに役立ちます。
y軸に沿った距離が急激に増加する箇所を観察し、その点でデンドログラムを切り詰め、距離をクラスタを形成するための閾値として使用できます。
この例では、最適なクラスタ数は3です。
ステップ5 – クラスタを形成する
最適なクラスタ数を決定したら、対応するy軸上の距離(しきい値距離)を使用します。これにより、しきい値距離以上では、クラスタは結合されません。しきい値距離として3.5を選択します(デンドログラムから推測された値です)。
その後、criterionを’distance’に設定してfclusterを使用して、すべてのデータポイントのクラスタ割り当てを取得します:
from scipy.cluster.hierarchy import fcluster# デンドログラムに基づいてしきい値距離を選択threshold_distance = 3.5 # クラスタラベルを取得するためにデンドログラムを切断cluster_labels = fcluster(linked, threshold_distance, criterion='distance')# クラスタラベルをDataFrameに割り当てwine_df['cluster'] = cluster_labels
これで、すべてのデータポイントのクラスタラベル({1、2、3}のいずれか)が表示されるはずです:
print(wine_df['cluster'])
出力 >>>0 21 22 23 24 3 ..173 1174 1175 1176 1177 1Name: cluster, Length: 178, dtype: int32
ステップ6 – クラスタを可視化する
各データポイントがクラスタに割り当てられたので、特徴の一部とそれらのクラスタ割り当てを可視化できます。以下は、二つの特徴とそれらのクラスタマッピングの散布図です:
plt.figure(figsize=(8, 6))scatter = plt.scatter(wine_df['alcohol'], wine_df['flavanoids'], c=wine_df['cluster'], cmap='rainbow')plt.xlabel('アルコール')plt.ylabel('フラボノイド')plt.title('クラスタの可視化')# 凡例を追加legend_labels = [f'クラスタ{i + 1}' for i in range(n_clusters)]plt.legend(handles=scatter.legend_elements()[0], labels=legend_labels)plt.show() 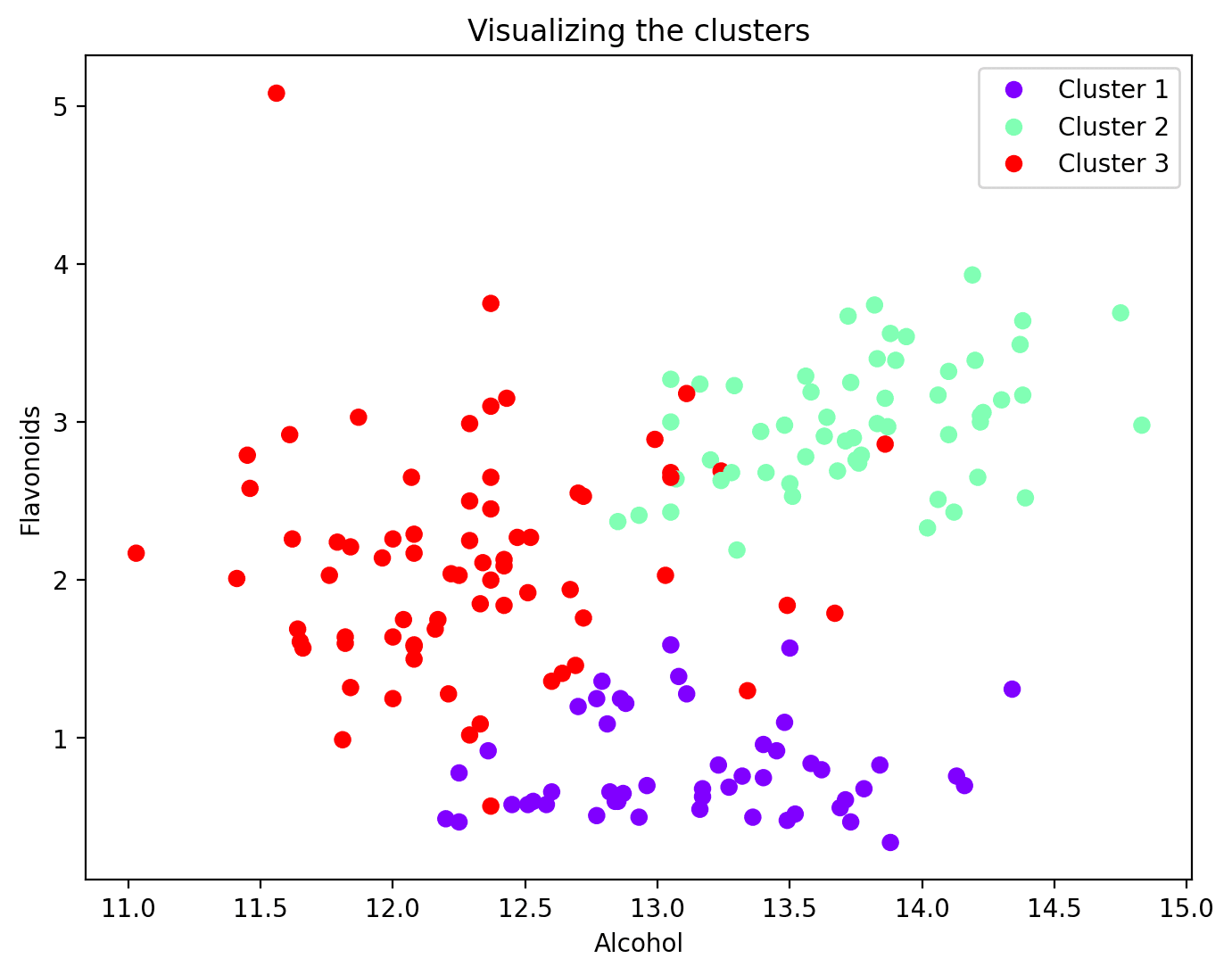
まとめ
以上が全部です!このチュートリアルでは、詳細な手順をカバーするためにSciPyを使用して階層的クラスタリングを行いました。代わりに、scikit-learnのクラスタモジュールからAgglomerativeClusteringクラスを使用することもできます。クラスタリングを楽しんでコーディングしましょう!
参考文献
[1] 機械学習入門
[2] 統計学習の概要(ISLR) Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。彼女の関心と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、コーヒーを楽しんでいます!現在、彼女はチュートリアル、ハウツーガイド、意見記事などを執筆することで開発者コミュニティと知識を共有するための学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






