「教師なし学習の解明」
Unsupervised Learning Exploration

非教師あり学習とは何ですか?
機械学習において、非教師あり学習は、ラベルの付いていないデータセットでアルゴリズムを訓練するパラダイムです。つまり、監視やラベル付けされた出力はありません。
非教師あり学習では、ラベル付きの例に基づいて予測や分類を行うのではなく、データ自体の中にあるパターン、構造、または関係を発見することが目標です。複雑な情報を理解し、洞察を得るためにデータの固有の構造を探索します。
このガイドでは、非教師あり学習について紹介します。まず、教師あり学習と非教師あり学習の違いを説明し、その後、主な非教師あり学習の技術とそれに含まれる人気のあるアルゴリズムについて説明します。
教師あり学習と非教師あり学習
教師あり学習と非教師あり学習は、人工知能とデータ分析の分野で使用される2つの異なるアプローチです。以下に、その主な違いを簡単にまとめます。
トレーニングデータ
教師あり学習では、アルゴリズムはラベル付きのデータセットでトレーニングされます。入力データは対応する目的変数(ラベルまたはターゲット値)とペアになっています。
一方、非教師あり学習では、ラベルのないデータセットで作業を行います。事前に定義された出力ラベルはありません。
目標
教師あり学習アルゴリズムの目標は、入力から出力空間への関係を学ぶことです。マッピングが学習されたら、モデルを使用して未知のデータポイントの出力値またはクラスラベルを予測することができます。
非教師あり学習では、データ内のパターン、構造、または関係を見つけることが目標です。これは、データポイントをグループ化するためのクラスタリング、探索的な分析、または特徴抽出などを含みます。
一般的なタスク
教師あり学習では、分類(事前に定義されたカテゴリの1つにクラスラベルを割り当てる)と回帰(連続値の予測)が一般的なタスクです。
非教師あり学習では、クラスタリング(類似したデータポイントのグループ化)と次元削減(重要な情報を保持しながら特徴の数を減らす)が一般的なタスクです。これについては、後で詳しく説明します。
使用する場合
教師あり学習は、望ましい出力が既知で明確な場合に広く使用されます。例えば、スパムメールの検出、画像分類、医療診断などです。
非教師あり学習は、データについて限られたまたは事前の知識がない場合に使用され、データそのものから隠れたパターンを明らかにしたり、洞察を得たりすることが目的です。
以下に違いのまとめを示します:
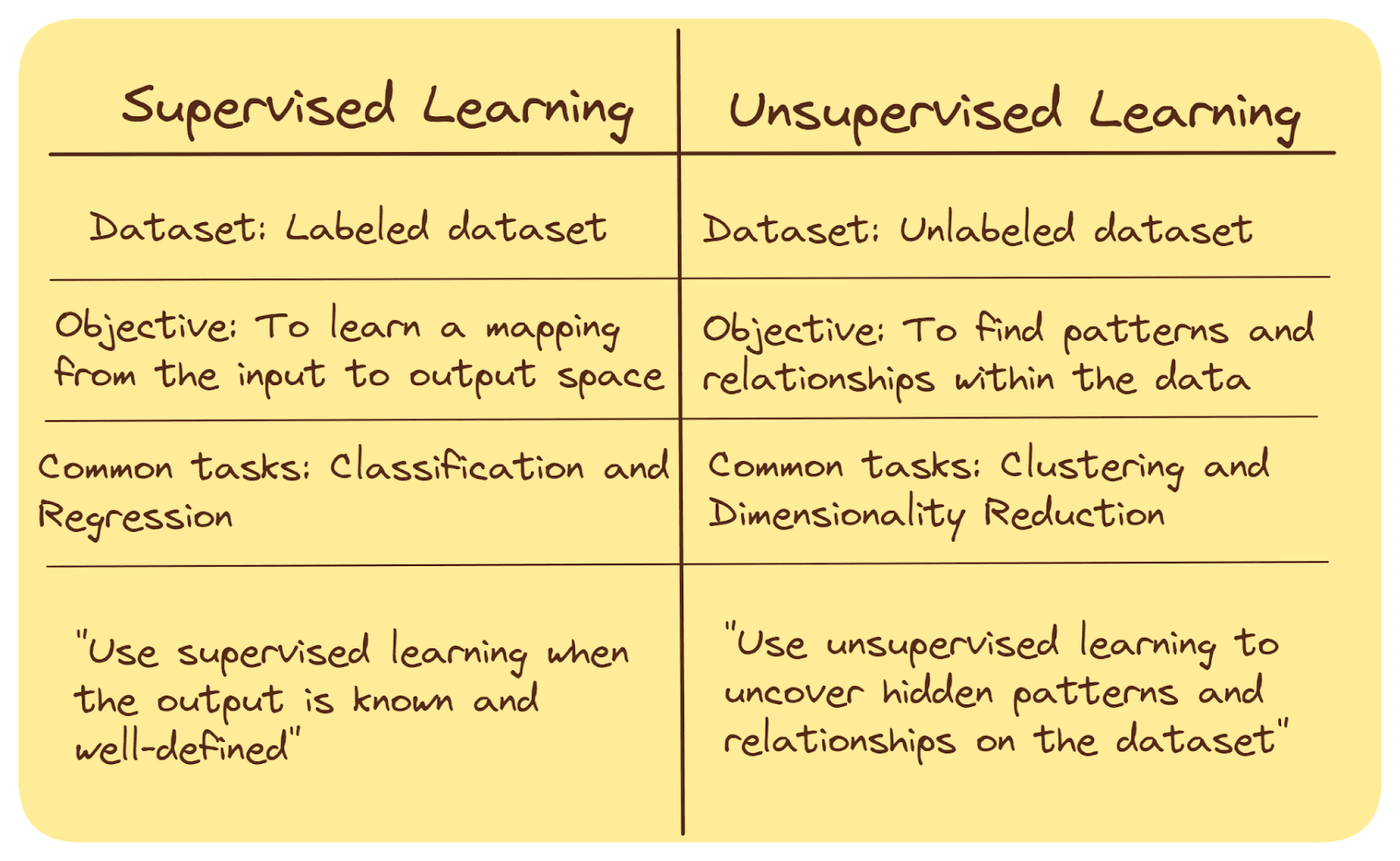
まとめると:教師あり学習は、ラベル付きデータから学習して予測や分類を行うことに重点を置いていますが、非教師あり学習は、ラベルのないデータからパターンや関係を発見しようとします。それぞれのアプローチは、データの性質と問題に応じて異なる応用があります。
非教師あり学習の技術
先ほど説明したように、非教師あり学習では、入力データがあり、そのデータ内の意味のあるパターンや表現を見つけるというタスクが与えられます。非教師あり学習アルゴリズムは、事前定義されたカテゴリやラベルが与えられない状態で、データポイント間の類似性、相違点、および関係を特定することでこれを実現します。
この議論では、以下の2つの主要な非教師あり学習の技術について説明します:
- クラスタリング
- 次元削減
クラスタリングとは何ですか?
クラスタリングは、類似したデータポイントを類似性の尺度に基づいてグループ化することを意味します。アルゴリズムは、データ内のデータポイントが他のクラスターのデータポイントよりもお互いに類似している自然なグループやカテゴリを見つけることを目指しています。
データセットを異なるクラスターにグループ化した後、それらにラベルを付けることができます。必要な場合は、クラスタリングされたデータセット上で教師あり学習を行うこともできます。
次元削減とは何ですか?
次元削減は、重要な情報を保持しながらデータ内の特徴量(次元)の数を減らす技術を指します。高次元データは複雑で扱いにくいため、次元削減はデータを分析するためにデータを単純化するのに役立ちます。
クラスタリングと次元削減の両方は、教師なし学習の強力な手法であり、貴重な洞察を提供し、複雑なデータをさらなる分析やモデリングのために単純化します。
本文の残りでは、重要なクラスタリングおよび次元削減のアルゴリズムについて説明します。
クラスタリングアルゴリズム概要
先述のように、クラスタリングは、類似したデータポイントをグループ化する教師なし学習の基本的な手法であり、同じクラスタ内のデータポイントは他のクラスタ内のデータポイントよりもお互いに類似しています。クラスタリングは、データ内の自然な区分を特定し、パターンや関係性を洞察するのに役立ちます。
クラスタリングにはさまざまなアルゴリズムがあり、それぞれ独自のアプローチと特性があります:
K-Meansクラスタリング
K-Meansクラスタリングは、シンプルでロバストで一般的に使用されるアルゴリズムです。データを事前に定義されたクラスタ(K個)に分割し、各クラスタ内のデータポイントの平均に基づいてクラスタの中心を反復的に更新します。
クラスタの割り当てを収束するまで反復的に改善します。
以下は、K-Meansクラスタリングアルゴリズムの動作方法です:
- K個のクラスタの中心を初期化します。
- 選択した距離尺度に基づいて、各データポイントを最も近いクラスタの中心に割り当てます。
- 各クラスタ内のデータポイントの平均を計算して中心を更新します。
- 収束するか、定義された反復回数に達するまでステップ2と3を繰り返します。
階層的クラスタリング
階層的クラスタリングは、データポイントの類似性を捉え、複数の粒度レベルでデータポイントのツリー構造であるデンドログラムを作成します。アゴルメラティブクラスタリングは、最も一般的に使用される階層的クラスタリングアルゴリズムです。それは個々のデータポイントを別々のクラスタとして開始し、距離や類似性などのリンケージ基準に基づいて徐々にクラスタを結合していきます。
以下は、アゴルメラティブクラスタリングアルゴリズムの動作方法です:
- 各データポイントを個別のクラスタとして開始します。
- 最も近いデータポイント/クラスタを大きなクラスタに結合します。
- 1.を繰り返します。単一のクラスタが残るか、定義されたクラスタ数に達するまで。
- デンドログラムのヘルプを使用して結果を解釈することができます。
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCANは、近傍のデータポイントの密度に基づいてクラスタを特定します。任意の形状のクラスタを見つけることができ、ノイズポイントを識別し、外れ値を検出することもできます。
以下は、アルゴリズムの概要(主要なステップを含む)です:
- データポイントを選択し、指定された半径内の近傍を見つけます。
- ポイントに十分な近傍がある場合、近傍の近傍を含めてクラスタを拡張します。
- すべてのポイントに対して繰り返し、密度によって接続されたクラスタを形成します。
次元削減アルゴリズムの概要
次元削減は、データセット内の特徴量(次元)の数を減らしながら、重要な情報を保持するプロセスです。高次元データは複雑で計算コストが高く、過学習しやすい傾向があります。次元削減アルゴリズムは、データの表現と可視化を単純化するのに役立ちます。
主成分分析(PCA)
主成分分析(PCA)は、データを新しい座標系に変換して主成分に沿って分散を最大化します。データの次元を削減しながら、できるだけ多くの分散を保持します。
以下に、次元削減のためにPCAを実行する方法を示します。
- 入力データの共分散行列を計算します。
- 共分散行列に対して固有値分解を行います。共分散行列の固有ベクトルと固有値を計算します。
- 固有値に基づいて固有ベクトルを降順でソートします。
- データを固有ベクトル上に射影して、低次元表現を作成します。
t-分布確率的近傍埋め込み(t-SNE)
t-SNEを初めて使用したのは、単語の埋め込みを可視化するためでした。t-SNEは、高次元データを低次元表現に変換することで、局所的なペアごとの類似性を保ちながら可視化に使用されます。
t-SNEの動作は以下の通りです。
- 高次元空間と低次元空間のデータ点間のペアごとの類似性を測るための確率分布を構築します。
- 勾配降下法を使用して、これらの分布間のダイバージェンスを最小化します。低次元空間のデータ点を反復的に移動させ、コスト関数を最小化するためにその位置を調整します。
さらに、次元削減に使用できるオートエンコーダーなどのディープラーニングアーキテクチャもあります。オートエンコーダーは、データをエンコードしてデコードするように設計されたニューラルネットワークであり、入力データの圧縮表現を効果的に学習します。
教師なし学習のいくつかの応用例
教師なし学習のいくつかの応用例を探ってみましょう。以下にいくつかの例を示します。
顧客セグメンテーション
マーケティングでは、教師なし学習を使用して顧客ベースを似たような行動と嗜好を持つグループにセグメント化します。これにより、マーケティング戦略、キャンペーン、製品提供をカスタマイズすることができます。例えば、小売業者は「予算派のショッパー」、「高級品購入者」、「時折購入者」といったグループに顧客を分類します。
ドキュメントクラスタリング
文書コーパスにクラスタリングアルゴリズムを実行することができます。これにより、類似した文書をグループ化し、文書の整理、検索、取得を支援します。
異常検知
教師なし学習は、データの中で稀な異常パターンを識別するために使用することができます。異常検知は、不正検出やネットワークセキュリティでの異常な挙動の検出に応用されます。異常な支出パターンを特定することで、不正なクレジットカード取引の検出が実際の例です。
画像圧縮
クラスタリングは、画像圧縮に使用することができます。これにより、類似したピクセル領域を単一の重心で表現することで、高次元のカラースペースからはるかに低次元のカラースペースに画像を変換します。これにより、画像の保存および送信サイズが削減されます。
ソーシャルネットワーク分析
ユーザーの相互作用に基づいたソーシャルネットワークデータを分析することができます。コミュニティ、インフルエンサー、および相互作用のパターンを明らかにします。
トピックモデリング
自然言語処理では、トピックモデリングのタスクがテキスト文書のコレクションからトピックを抽出するために使用されます。これにより、大規模なテキストコーパス内の主要なテーマ(トピック)を分類し理解することができます。
例えば、ニュース記事のコーパスがあり、事前に文書とそれに対応するカテゴリがない場合、ニュース記事のコレクションに対してトピックモデリングを実行して、政治、技術、エンターテイメントなどのトピックを特定することができます。
ゲノムデータ解析
教師なし学習は、バイオメディカルおよびゲノムデータ解析にも応用されます。例えば、発現パターンに基づいて遺伝子をクラスタリングし、特定の疾患との関連性を発見することがあります。
結論
この記事が教師なし学習の基礎を理解するのに役立てば幸いです。次に実世界のデータセットで作業する際に、対象の学習問題を見つけ出し、それが教師あり学習の問題なのか、教師なし学習の問題なのかを評価してみてください。
高次元の特徴を持つデータセットで作業している場合、機械学習モデルを構築する前に次元削減を適用してみてください。学び続けてください! Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点で働くのが好きです。彼女の興味と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーを楽しんでいます!現在、彼女はチュートリアル、ハウツーガイド、意見記事などを執筆して、開発者コミュニティとの知識共有に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「教師付き学習の実践:線形回帰」
- 「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
- 「InstaFlowをご紹介します:オープンソースのStableDiffusion(SD)から派生した革新的なワンステップ生成型AIモデル」
- マルチAIの協力により、大規模な言語モデルの推論と事実の正確さが向上します
- 自己対戦を通じてエージェントをトレーニングして、三目並べをマスターする





