「ディープラーニングの謎を解明する:CIFAR-10データセットを用いたCNNアーキテクチャの秘密の解明」
Unraveling the Mystery of Deep Learning Exploring the Secrets of CNN Architecture using the CIFAR-10 Dataset

人工知能の絶えず進化する世界で、畳み込みニューラルネットワーク(CNN)は革新的な技術として登場し、コンピュータビジョンや画像認識の分野を再構築しています。画像の中のパターンを自動的に学習し識別する能力を持つCNNは、自動運転車から医療診断まで、数々のアプリケーションで新たな可能性を開拓しています。本記事では、CNNのアーキテクチャの仕組みについて探求し、テストのために人気のあるCIFAR-10データセットを使用します。
ここでは、理論の部分を完了した後、実際のTensorFlowのコードを示すことで、理論と実践のアイデアを適用する目標を持っています。
畳み込みとは実際には何ですか?
ステップ1:画像とフィルタの理解:
まず、グレースケールの画像から始めましょう。それは各ピクセルの強度がグレースケールの値に対応する2Dグリッドとして表されるものです。簡単のため、小さな3×3のグレースケール画像を取りましょう:
- 「LangChain、Activeloop、およびDeepInfraを使用したTwitterアルゴリズムのリバースエンジニアリングのためのプレーンな英語ガイド」
- 「ゴミを入れればゴミが出る:AIにおけるデータ品質の重要な役割」
- 「パート1:ステップバイステップでWindowsベースのシステム上でデータパイプラインを実行するための仮想環境の作成」
画像:[ 1 2 3 ][ 4 5 6 ][ 7 8 9 ]次に、2×2のフィルタを使用します:
フィルタ:[ 1 0 ][ 0 1 ]ステップ2:畳み込みの適用:フィルタを画像の左上の角に配置して、畳み込み操作を行います。
畳み込み操作は次のようになります:
(1*1) + (2*0) +(4*0) + (5*1) = 1 + 0 + 0 + 5 = 6したがって、出力特徴マップの左上のピクセルの値は6です。
ステップ3:フィルタのスライド:次に、2×2のフィルタを画像全体にスライドさせ、フィルタの各位置で畳み込み操作を行います。
出力特徴マップ:[ 6 8 ][ 3 5 ]畳み込みのモードは?
画像処理や信号処理の文脈では、畳み込みは入力データの境界で畳み込み操作がどのように処理されるかを決定する異なるモードで実行することができます。最も一般的な畳み込みのモードは次のとおりです:
1. Sameモード
「Same」モードでは、畳み込みの出力は入力と同じ空間次元を持ちます。これを実現するために、通常、畳み込み操作を適用する前に、入力データは境界部分にゼロでパディングされます。
2. Validモード
「Valid」モードでは、畳み込みはフィルタが入力データと完全に重なる場所でのみ行われます。つまり、フィルタは入力の境界ピクセルには中心に配置されないため、出力特徴マップは入力と比べて空間次元が縮小されます。
3. Fullモード
「Full」モードでは、フィルタは入力の境界を超えることが許され、フィルタと入力データが重なる可能なすべての場所で畳み込み操作が行われます。その結果、出力特徴マップは入力よりも大きな空間次元を持ちます。
畳み込みにおけるフィルタの本質とは何ですか?
畳み込みニューラルネットワーク(CNN)におけるフィルタの本質は、入力データから意味のある特徴を検出し学習する能力にあります。特に、画像処理やコンピュータビジョンのタスクの文脈では、フィルタはパターン検出器として機能します。
フィルタは、ネットワークが入力データの中の特定のパターン、テクスチャ、構造を識別するのを助ける役割を果たします。トレーニングプロセス中に適切なフィルタを学習することにより、CNNは生の入力から関連性のある独特な特徴を抽出し、画像認識、物体検出、セグメンテーションなどの複雑なタスクの解決に重要な役割を果たします。
フィルタは、モデルのトレーニングプロセス中に調整される重みとして想定できます。
2Dから3Dへ:畳み込み層の次元の解読
畳み込みニューラルネットワークの問題は、画像とカーネル(フィルタ)の畳み込みが出力が2Dであるため、3Dの入力を受け入れる他の層に渡すための非互換性の問題が発生することです。
では、この問題はどのように解決されるのでしょうか?
この問題を解決するために、複数のフィルタ間で畳み込みが行われ、その結果が積み重ねられることによって、この新しい3Dの入力を次の層に供給することができます。
畳み込みニューラルネットワークの神秘を解き明かす:構造と動作
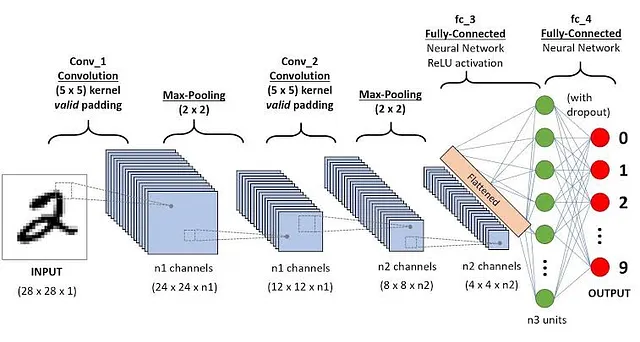
アーキテクチャ:
CNNは、視覚認識プロセスの特定のタスクに合わせて調整された異なる層で構成されています。CNNの基本的な層は次のとおりです:
a) 入力層:
CNNの最も前面にある層は、生の入力画像を受け入れる責任があります。それは画像をピクセル値の行列に変換し、各ピクセルが色情報(赤、緑、青など)を保持するようにします。
b) 畳み込み層:
次の畳み込み層では、入力画像に対して小さなフィルタ(カーネル)が畳み込まれます。これらのフィルタは、エッジやテクスチャなどの局所的なパターンを識別し、特徴マップを生成します。特徴マップの深さは、適用されるフィルタの数に対応しています。
c) 活性化層:
畳み込みステップが完了すると、活性化関数(ReLUなど)が非線形性を導入し、特徴と抽象的な表現を効果的に学習するCNNの能力を向上させます。
d) プーリング層:
プーリング層は、特徴マップの空間的な次元削減に貢献します。最大プーリングや平均プーリングなどの技術は、隣接するピクセルから最大値または平均値を選択します。このダウンサンプリングにより、重要な特徴を保持しながら計算量が削減されます。
e) 全結合層:
CNNの特徴抽出プロセスの最終段階には、完全に接続された層が関与します。これらの層は、学習された特徴を解釈し、伝統的なニューラルネットワーク層と同様の機能を果たします。抽出された特徴に基づいて分類の決定を行う上で重要な役割を果たします。
畳み込みニューラルネットワークの動作:
CNNの動作は、次のステップを通じて理解することができます:
ステップ1:入力画像の受け入れ:
CNNは、ピクセル値の行列として表される入力画像を受け取ることから始まります。各ピクセルは色チャンネル(赤、緑、青など)をエンコードします。
ステップ2:特徴抽出:
畳み込み層に移ると、フィルタが入力画像上をスキャンし、画像内の重要なパターンや特徴をハイライトする特徴マップが作成されます。
ステップ3:非線形性の導入:
活性化層は、特徴マップに非線形性を導入し、CNNが特徴間の複雑な関係を学習することが可能となります。
ステップ4:空間次元の削減:
プーリング層は、特徴マップの空間次元を減らし、重要な情報を保持しながら計算負荷を最小限に抑えます。
ステップ5:分類:
最終段階では、完全に接続された層が学習された特徴を処理し、それに基づいて予測を行います。CNNの出力は、その分類の決定を表します。
完全に接続された層の問題
完全に接続された層は1次元の入力を受け取りますが、先ほど述べたように出力は3Dです。したがって、特徴マップを積み重ねることで1次元に変換するために、TensorFlowのflatten()関数を使用します。
コード:-
Google Colaboratory
colab.research.google.com
記事が既に長すぎるため、上記のリンクにコードを含めました。
使用されたデータセット:CIFAR-10
CIFAR-10 – 画像の物体認識
60,000枚のラベル付き画像の対象を特定する
www.kaggle.com
また、バッチ正規化とデータ拡張を行い、結果を改善しました。できるだけ短く簡潔に説明します。
バッチ正規化
簡単に説明すると、値を特定の範囲(例:0から1)に変換することです。例えば、A=2、B=2000の2つの値がある場合、機械学習モデルはこれらを受け入れません。両方の値は近くになければならず、これが正規化の背後にある主な概念です。バッチ正規化は、畳み込みの後にバッチに正規化を適用するだけです。
データ拡張
データ拡張は、既存のデータにさまざまな変換を適用することで、トレーニングデータセットのサイズを人工的に拡大するプロセスです。これらの変換には、回転、スケーリング、反転、クロッピングなどの画像操作が含まれます。データを拡張することにより、モデルはより堅牢になり、未知の例に対してもより優れた一般化能力を持ち、パフォーマンスが向上し、過学習が減少します。
結論
畳み込みニューラルネットワークは、コンピュータビジョンと画像認識を変革し、現実世界のアプリケーションの可能性を解き放ちました。そのアーキテクチャと機能の明確な理解は、正確で効率的な視覚認識システムを作成するために彼らの能力を活用するために不可欠です。CNNの力を受け入れることにより、視覚データに隠された謎を解き明かす画期的な旅に乗り出すことができます。

この記事をお読みいただき、貴重なお時間をいただき、ありがとうございました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
