スケールを通じた高精度の差分プライバシー画像分類の解除
Unlocking high-precision differential privacy image classification through scaling.
最近のDeepMindの論文では、言語モデルの倫理的および社会的なリスクについて、これらのモデルに取り組む組織が対処する責任があるとして、大規模な言語モデルが訓練データに関する機密情報を漏洩する可能性があると指摘しています。別の最近の論文では、同様のプライバシーのリスクが標準の画像分類モデルでも発生することが示されています。各個別の訓練画像の指紋がモデルパラメータに埋め込まれており、悪意のある者がそのような指紋を利用してモデルから訓練データを再構築する可能性があります。
差分プライバシー(DP)などのプライバシー強化技術は、これらのリスクを軽減するために訓練時に展開することができますが、しばしばモデルの性能の大幅な低下をもたらします。この研究では、差分プライバシーの下で高精度な画像分類モデルの訓練を解放するための大幅な進歩を遂げました。
![図1:(左)GPT-2における訓練データの漏洩のイラスト[引用:Carlini et al. "Extracting Training Data from Large Language Models", 2021]。(右)100Kパラメータの畳み込みニューラルネットワークから再構築されたCIFAR-10の訓練例[引用:Balle et al. "Reconstructing Training Data with Informed Adversaries", 2022]](https://assets-global.website-files.com/621e749a546b7592125f38ed/62ab43e65845e64d1a827c87_Figure.png)
差分プライバシーは、統計的なデータ分析(機械学習モデルの訓練を含む)の過程で個々のレコードを保護する要件を捉えるための数学的なフレームワークとして提案されました。DPアルゴリズムは、所望の統計量またはモデルの計算中に注意深くキャリブレーションされたノイズを注入することによって、個々の特徴を一意にする要素に関する推測(完全または部分的な再構築を含む)から個人を保護します。DPアルゴリズムの使用は、理論的にも実践的にも堅牢で厳密なプライバシー保証を提供し、公共および私的な組織の数で事実上の標準となっています。
深層学習のための最も人気のあるDPアルゴリズムは、差分プライバシー確保確率的勾配降下法(DP-SGD)であり、個々の例の勾配をクリッピングし、各モデル更新における各個別の寄与をマスクするために十分なノイズを追加することによって標準的なSGDを修正したものです。
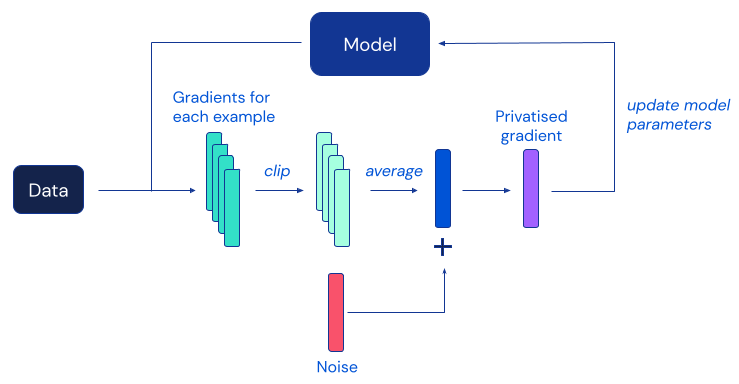
残念ながら、これまでの研究では、DP-SGDによるプライバシー保護は、実践的にはしばしば正確性の低下というコストを伴うことが分かっており、これは機械学習コミュニティにおける差分プライバシーの広範な採用を妨げる大きな障害となっています。以前の研究からの経験的な証拠によると、DP-SGDにおけるこのユーティリティの低下は、より大きなニューラルネットワークモデル(難しい画像分類ベンチマークで最高の性能を達成するために定期的に使用されるモデルを含む)ではより深刻になる傾向があります。
私たちの研究では、この現象を調査し、訓練手続きとモデルアーキテクチャの両方に対する一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの精度を大幅に改善しました。私たちの研究から得られた最も驚くべき観察結果は、モデルの勾配が適切に制御されている限り、DP-SGDを使用してこれまで考えられていたよりもはるかに深いモデルを効率的に訓練できるということです。私たちは、研究によって達成された性能の大幅な向上が、形式的なプライバシー保証を持つ画像分類モデルの実用的な応用の可能性を開くと考えています。
以下の図は、私たちの主な2つの結果をまとめたものです:追加データなしでのプライベートトレーニング時のCIFAR-10での約10%の改善と、別のデータセットで事前にトレーニングされたモデルをプライベートにファインチューニングした場合のImageNetでのトップ1の精度が86.7%であり、最高の非プライベートパフォーマンスにほぼ追いついています。

これらの結果は、機械学習アプリケーションにおける差分プライバシーの提供力を調整するための標準設定である𝜺=8で達成されました。このパラメータに関する議論や、他の𝜺の値や他のデータセットでの追加の実験結果については、論文を参照してください。論文と共に、私たちの実装もオープンソース化しており、他の研究者が私たちの結果を検証し、それを基にさらなる研究を行うことができるようにしています。この貢献が実用的な差分プライバシーのトレーニングを実現したい他の人々のお手伝いになることを願っています。
GitHubで私たちのJAXの実装をダウンロードしてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






