「完璧な機械学習アルゴリズムを選ぶための秘訣を解き放て!」
Unlock the secrets to choosing the perfect machine learning algorithm!
データサイエンスの問題を解決する際に重要な決定の一つは、どの機械学習アルゴリズムを使用するかです。
数百もの機械学習アルゴリズムがあり、それぞれに利点と欠点があります。特定の種類の問題やデータセットに対して、あるアルゴリズムの方が他のアルゴリズムよりも優れた結果を出すこともあります。
「No Free Lunch(NFL)定理」によれば、どの問題にも最適なアルゴリズムは存在せず、つまり、すべてのアルゴリズムがすべての可能な問題についての性能の平均化で同じ性能を持つということです。
- YOLOv7 最も先進的な物体検出アルゴリズム?
- AIによるテキストメッセージングの変革:自然言語処理技術の詳細な探求
- 「生成AI、基礎モデル、および大規模言語モデルの世界を探求する:概念、ツール、およびトレンド」
この記事では、問題に適したモデルを選ぶ際に考慮すべき主要なポイントと、異なる機械学習アルゴリズムを比較する方法について説明します。
主要なアルゴリズムの側面
以下のリストは、特定の機械学習アルゴリズムを考慮する際に自分自身に尋ねるかもしれない10の質問を含んでいます:
- アルゴリズムはどの種類の問題を解決できるのか?アルゴリズムは回帰問題や分類問題のみを解決できるのか、それとも両方を解決できるのか?多クラス/多ラベル問題に対応できるのか、それともバイナリ分類問題のみに対応できるのか?
- アルゴリズムはデータセットについて何か仮定をしているのか?例えば、一部のアルゴリズムはデータが線形分離可能であると仮定しています(パーセプトロンや線形SVMなど)。一方、他のアルゴリズムはデータが正規分布していると仮定しています(ガウス混合モデルなど)。
- アルゴリズムの性能について保証はあるのか?例えば、アルゴリズムが最適化問題を解決しようとする場合(ロジスティック回帰やニューラルネットワークなど)、グローバル最適解を見つけることが保証されているのか、それとも局所最適解のみが見つかるのか?
- モデルを効果的にトレーニングするために必要なデータの量はどれくらいか?ディープニューラルネットワークなど、一部のアルゴリズムは他のアルゴリズムよりもデータに敏感です。
- アルゴリズムは過学習しやすい傾向があるのか?もしそうであれば、過学習に対処する方法は提供されているのか?
- アルゴリズムの実行時間とメモリ要件はどれくらいか?トレーニング時と予測時の両方でのアルゴリズムの実行時間について考慮する必要があります。
- アルゴリズムのためにデータの前処理ステップは必要か?
- アルゴリズムはどれくらいのハイパーパラメータを持っているか?ハイパーパラメータが多いアルゴリズムはトレーニングとチューニングに時間がかかります。
- アルゴリズムの結果を簡単に解釈できるか?多くの問題領域(医療診断など)では、モデルの予測を人間の言葉で説明できることが望ましいです。一部のモデルは簡単に可視化できます(決定木など)、一方、他のモデルはブラックボックスのような振る舞いをします(ニューラルネットワークなど)。
- アルゴリズムはオンライン(増分)学習をサポートしているか?つまり、モデルをゼロから再構築せずに追加のサンプルでトレーニングできるのか?
アルゴリズム比較の例
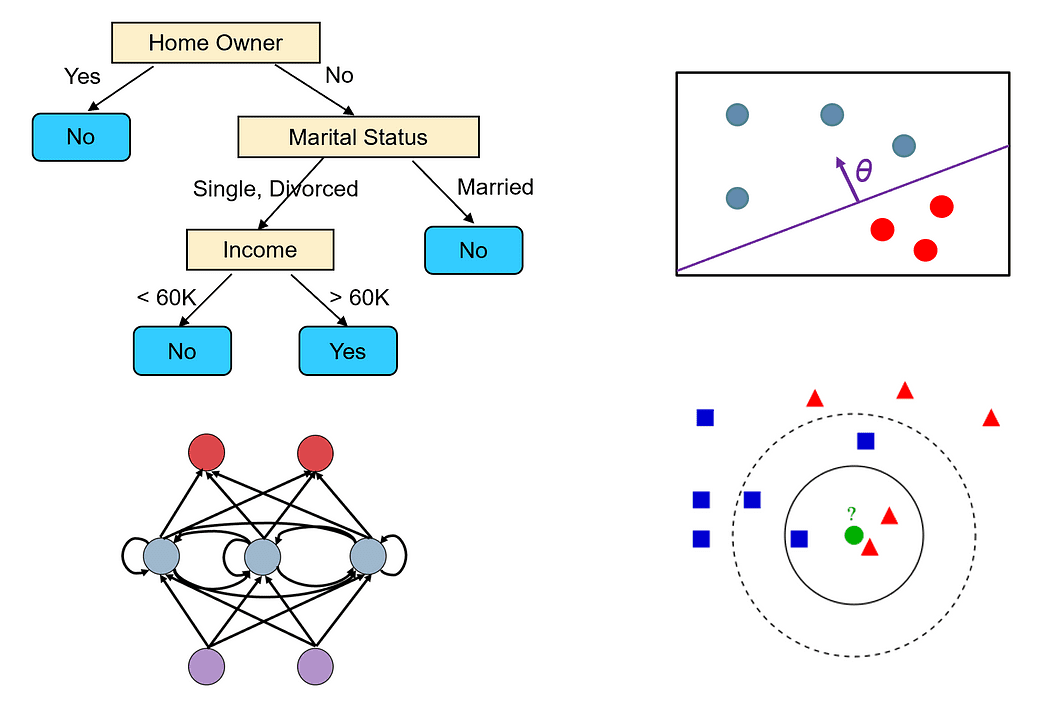
例えば、最も人気のある2つのアルゴリズムである決定木とニューラルネットワークを取り上げ、上記の基準に基づいて比較してみましょう。
決定木
- 決定木は分類問題と回帰問題の両方を扱うことができます。また、多クラスおよび多ラベル問題も簡単に扱うことができます。
- 決定木アルゴリズムにはデータセットに関する特定の仮定はありません。
- 決定木は貪欲アルゴリズムを使用して構築されますが、最適な木(つまり、すべてのトレーニングサンプルを正しく分類するために必要なテストの数を最小化する木)を見つけることは保証されていません。ただし、決定木は、すべての葉ノードのサンプルが同じクラスに属するまでノードを拡張することで、トレーニングセットで100%の正解率を達成することができます。このような木は通常、ノイズを過学習しているため、良い予測モデルではありません。
- 決定木は、小規模またはVoAGIサイズのデータセットでもうまく機能します。
- 決定木は簡単に過学習することがあります。ただし、ツリーの剪定を使用することで過学習を軽減することができます。また、ランダムフォレストなどのアンサンブルメソッドを使用して、複数の決定木の出力を組み合わせることもできます。これらのメソッドは過学習に対してより耐性があります。
- 決定木の構築にかかる時間はO(n²p)です(ここで、nはトレーニングサンプルの数、pは特徴量の数です)。決定木の予測時間は、ツリーの高さに依存しますが、通常はnの対数関数です。なぜなら、ほとんどの決定木は比較的バランスが取れているからです。
- 決定木はデータの前処理を必要としません。数値型やカテゴリカルなど、さまざまなタイプの特徴をスムーズに処理できます。また、データの正規化も必要ありません。
- 決定木には、木の最大の深さやノードの分割方法を決定するための不純度の測定方法など、調整が必要な重要なハイパーパラメータがいくつかあります。
- 決定木は理解しやすく解釈することができ、簡単に視覚化することができます(ツリーが非常に大きくない限り)。
- 決定木は新しいトレーニングサンプルを考慮して簡単に変更することはできません。なぜなら、データセットのわずかな変化がツリーのトポロジーに大きな変化をもたらす可能性があるからです。
ニューラルネットワーク
- ニューラルネットワークは、存在する中で最も一般的かつ柔軟な機械学習モデルの一つです。分類、回帰、時系列解析、自動コンテンツ生成などのほとんどのタイプの問題を解決できます。
- ニューラルネットワークにはデータセットに関する仮定はありませんが、データは正規化する必要があります。
- ニューラルネットワークは勾配降下法を使用してトレーニングされます。したがって、局所最適解しか見つけることができません。ただし、運動量や適応型学習率など、ローカルミニマに陥るのを回避するために使用できるさまざまなテクニックがあります。
- ディープニューラルネットワークは、数百万のサンプルポイントのオーダーでトレーニングするために多くのデータを必要とします。一般的に、ネットワークが大きいほど(隠れ層やニューロン数が多いほど)、トレーニングに必要なデータが増えます。
- ネットワークが大きすぎると、トレーニングサンプルをすべて記憶して一般化できなくなる場合があります。多くの問題では、小さなネットワーク(たとえば1つまたは2つの隠れ層のみを持つ)から始めて、トレーニングセットが過学習するまで徐々にサイズを大きくすることができます。過学習に対処するために正則化を追加することもできます。
- ニューラルネットワークのトレーニング時間は多くの要素に依存します(ネットワークのサイズ、トレーニングに必要な勾配降下法の反復回数など)。しかし、予測時間は非常に速いです。ラベルを取得するためにネットワークを前方に一度だけ通過すればよいからです。
- ニューラルネットワークは、すべての特徴が数値であり正規化されていることを必要とします。
- ニューラルネットワークには調整する必要のある多くのハイパーパラメータがあります。層の数、各層のニューロン数、どの活性化関数を使用するか、学習率などが含まれます。
- ニューラルネットワークの予測は、多数のニューロンの計算に基づいているため、解釈が難しいです。各ニューロンは最終的な予測に対してわずかな寄与しか持ちません。
- ニューラルネットワークは、インクリメンタルな学習アルゴリズム(確率的勾配降下法)を使用して追加のトレーニングサンプルを簡単に組み込むことができます。
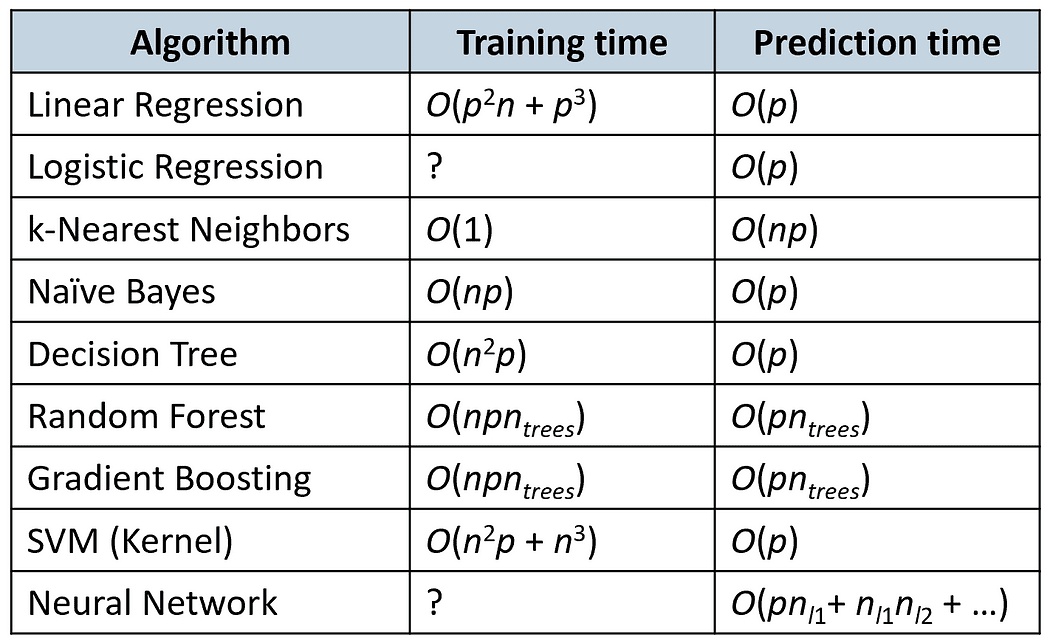
時間計算量
以下の表は、いくつかの人気のあるアルゴリズムのトレーニングと予測の時間を比較しています(nはトレーニングサンプルの数、pは特徴の数です)。
Kaggleコンペティションで最も成功したアルゴリズム
2016年に行われた調査によると、Kaggleコンペティションの優勝者が最も頻繁に使用したアルゴリズムは、勾配ブースティングアルゴリズム(XGBoost)とニューラルネットワークです(この記事を参照)。
2015年のKaggleコンペティションの29の優勝者のうち、8人がXGBoostを使用し、9人がディープニューラルネットワークを使用し、11人が両方のアンサンブルを使用しました。
XGBoostは主に構造化データ(関係データベースなど)を扱う問題で使用され、ニューラルネットワークは非構造化の問題(画像、音声、テキストなどの問題)の処理により成功しています。
これが今でも状況が同じか、トレンドが変わったのかを確認するのは興味深いでしょう(誰か挑戦しますか?)
お読みいただきありがとうございます!
Dr. Roi Yehoshuaは、ボストンのノースイースタン大学で教鞭を執り、データサイエンスの修士プログラムを構成するクラスを教えています。彼のマルチロボットシステムと強化学習の研究は、AIのトップリーディングジャーナルや会議で発表されています。彼はまた、VoAGIソーシャルプラットフォームでトップライターでもあり、データサイエンスと機械学習に関する記事を頻繁に公開しています。
オリジナル。許可を得て再掲載されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles