NumpyとPandasを超えて:知られざるPythonライブラリの潜在能力の解放
'Unleashing the untapped potential of lesser-known Python libraries beyond Numpy and Pandas'
データプロフェッショナルとして知っておくべき3つの科学計算用Pythonライブラリ

Pythonは世界で最もよく使われるプログラミング言語の一つであり、開発者には様々なライブラリが提供されています。
ところで、データ操作や科学計算に関しては、通常はNumpy、Pandas、またはSciPyなどのライブラリを思い浮かべます。
この記事では、興味を持つかもしれない3つのPythonライブラリを紹介します。
1. Dask
Daskの紹介
Daskは柔軟な並列計算ライブラリであり、大規模データ処理のための分散コンピューティングと並列処理を可能にします。
- ロッテン・トマト映画の評価予測のデータサイエンスプロジェクト:2つ目のアプローチ
- クレジットカードの取引データを使用した顧客セグメンテーションのマスタリング
- Mageを使用してデータパイプラインでの振る舞い駆動開発を実装してください
では、なぜDaskを使用すべきなのでしょうか?彼らのウェブサイトでは次のように述べています:
Pythonは、NumPy、pandas、scikit-learnなどの計算ライブラリのおかげで、データ分析と一般的なプログラミングの両方で主要な言語に成長しました。しかし、これらのパッケージは単一のマシンを超えてスケールするように設計されていませんでした。Daskは、これらのパッケージと周囲のエコシステムをマルチコアマシンと分散クラスタでネイティブにスケールするように開発されました。
ですので、彼らが言うように、Daskの一般的な使用例は次のとおりです:
Dask DataFrameは、通常はpandasが必要とされる状況で使用されます。例えば、以下のような場合です:
– メモリに収まらない大規模なデータセットの操作
– 多くのコアを使用して長時間の計算を高速化する
– groupby、join、時系列計算などの標準的なpandas操作を使用して大規模なデータセットでの分散コンピューティング
ですので、巨大なPandasデータフレームを扱う必要がある場合には、Daskは良い選択肢です。なぜなら、Daskは次のようなことができるからです:
ユーザーがラップトップで100GB以上のデータセットを操作したり、ワークステーションで1TB以上のデータセットを操作したりできます
これは非常に印象的な結果です。
内部では、次のような処理が行われています:
Dask DataFrameは、効率のためにインデックス値に沿って配置された多数のpandas DataFrame/Seriesを調整します。これらのpandasオブジェクトはディスク上や他のマシン上に存在する可能性があります。
つまり、以下のような構造になります:
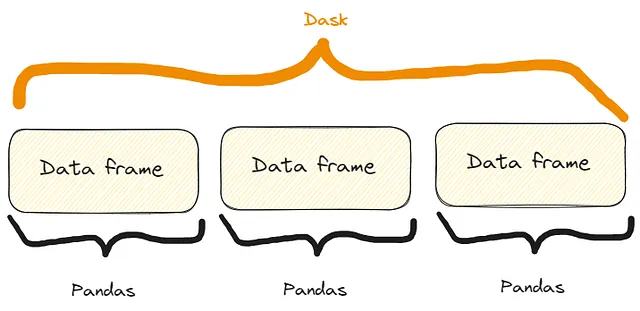
Daskのいくつかの機能
まず、Daskをインストールする必要があります。次のようにpipまたはcondaを使用してインストールできます:
$ pip install dask[complete]または$ conda install dask機能1:CSVファイルの読み込み
Daskの最初の機能は、CSVファイルを開く方法です。次のように行うことができます:
import dask.dataframe as dd# Daskを使用して大規模なCSVファイルを読み込むdf_dask = dd.read_csv('my_very_large_dataset.csv')# Dask DataFrame上で操作を行うmean_value_dask = df_dask['column_name'].mean().compute()上記のコードでわかるように、Daskの使用方法はPandasと非常に似ています。具体的には:
- Pandasと同様に、
read_csv()メソッドを使用します - Pandasと同様に、列をインターセプトします。実際、Pandasのデータフレーム
dfがある場合、列をインターセプトする方法は次のとおりです:df['column_name']。 - Pandasと同様にインターセプトした列に
mean()メソッドを適用しますが、ここではさらにcompute()メソッドも追加する必要があります。
また、CSVファイルを開く方法はPandasと同じですが、Daskは1台のマシンのメモリ容量を超える大規模なデータセットを簡単に処理しています。
つまり、実際の違いは見ることができないということです。ただし、Pandasでは大規模なデータフレームを開くことはできませんが、Daskでは開くことができます。
機能2: マシンラーニングワークフローのスケーリング
Daskを使用して、大量のサンプルを含む分類データセットを作成し、トレインセットとテストセットに分割し、トレインセットをMLモデルにフィットさせ、テストセットの予測を計算することもできます。
以下のように行うことができます:
import dask_ml.datasets as dask_datasetsfrom dask_ml.linear_model import LogisticRegressionfrom dask_ml.model_selection import train_test_split# Daskを使用して分類データセットをロードするX, y = dask_datasets.make_classification(n_samples=100000, chunks=1000)# データをトレインセットとテストセットに分割するX_train, X_test, y_train, y_test = train_test_split(X, y)# ロジスティック回帰モデルを並列でトレーニングするmodel = LogisticRegression()model.fit(X_train, y_train)# テストセットで予測するy_pred = model.predict(X_test).compute()この例では、Daskがマルチコアで計算を分散させることによって、機械学習の問題でも巨大なデータセットを処理する能力が強調されています。
特に、dask_datasets.make_classification() メソッドを使用して分類ケースのための「Daskデータセット」を作成できます。サンプル数とチャンク数(非常に大きいものも含めて)を指定できます。
前と同様に、予測は compute() メソッドを使用して取得します。
注意:この場合、dask_mlモジュールをインストールする必要がある場合があります。次のようにしてインストールできます:$ pip install dask_ml機能3: 効率的な画像処理
Daskが利用する並列処理のパワーは画像にも適用することができます。
具体的には、複数の画像を開き、リサイズし、リサイズ後の画像を保存することができます。
import dask.array as daimport dask_image.imreadfrom PIL import Image# Daskを使用して複数の画像をロードするimages = dask_image.imread.imread('image*.jpg')# 並列で画像をリサイズするresized_images = da.stack([da.resize(image, (300, 300)) for image in images])# 結果を計算するresult = resized_images.compute()# リサイズされた画像を保存するfor i, image in enumerate(result): resized_image = Image.fromarray(image) resized_image.save(f'resized_image_{i}.jpg')したがって、以下のプロセスが行われます:
- 現在のフォルダ(または指定したフォルダ)のすべての「.jpg」画像を
dask_image.imread.imread("image*.jpg")メソッドで開きます。 da.stack()メソッド内のリスト内包表記を使用して、すべてを300×300にリサイズします。- 以前と同様に、
compute()メソッドで結果を計算します。 - forループですべてのリサイズされた画像を保存します。
2. SymPy
Sympyの紹介
数学的な計算と演算を行い、Pythonに固執したい場合は、SymPyを試してみることができます。
実際に、私たちの愛されたPythonを使用できるので、他のツールやソフトウェアを使用する必要はないですよね?
彼らのウェブサイトに書かれている通り、SymPyは次のようなものです:
シンボリック数学のためのPythonライブラリです。シンプルさを保ちながら、フル機能のコンピュータ代数システム(CAS)になることを目指しています。SymPyは完全にPythonで書かれています。
しかし、なぜSymPyを使用するのでしょうか? 彼らは次のように提案しています:
SymPyは…
– 無料です: BSDライセンスの下でライセンスされているため、SymPyはスピーチやビールと同じくらい無料です。
– Pythonベースです: SymPyは完全にPythonで書かれており、その言語としてPythonを使用しています。
– 軽量です: SymPyは任意の浮動小数点演算のための純粋なPythonライブラリであるmpmathにのみ依存しているため、使用が容易です。
– ライブラリです: 対話的なツールとしての使用に加えて、SymPyは他のアプリケーションに埋め込まれ、カスタム関数で拡張することもできます。
それで、それは基本的にPython中毒者に愛される可能性のあるすべての特徴を持っています!
さて、その特徴のいくつかを見てみましょう。
SymPyのいくつかの特徴の実例
まず、それをインストールする必要があります:
$ pip install sympy
注意:もし $ pip install simpy と書くと、別の(完全に異なる!)ライブラリがインストールされます。したがって、2番目の文字は「i」ではなく「y」です。特徴1:代数方程式の解法
もし代数方程式を解く必要がある場合、SymPyを以下のように使用できます:
from sympy import symbols, Eq, solve# シンボルを定義するx, y = symbols('x y')# 方程式を定義するequation = Eq(x**2 + y**2, 25)# 方程式を解くsolutions = solve(equation, (x, y))# 解を出力するprint(solutions)>>>[(-sqrt(25 - y**2), y), (sqrt(25 - y**2), y)]以上がプロセスです:
symbols()メソッドで方程式のシンボルを定義します。Eqメソッドで代数方程式を記述します。solve()メソッドで方程式を解きます。
私が大学にいたときは、この種の問題を解くためにさまざまなツールを使用しましたが、SymPyは非常に読みやすく使いやすいことを言わざるを得ません。
しかし、実際には:それはPythonのライブラリですので、どのようにして違うことができるでしょうか?
特徴2:導関数の計算
導関数の計算も、データの解析時にさまざまな理由で数学的に必要とされるタスクです。Sympyを使用すると、次のように計算できます。
from sympy import symbols, diff# シンボルを定義するx = symbols('x')# 関数を定義するf = x**3 + 2*x**2 + 3*x + 4# 導関数を計算するderivative = diff(f, x)# 導関数を出力するprint(derivative)>>>3*x**2 + 4*x + 3したがって、プロセスは非常にシンプルでわかりやすいです:
symbols()メソッドで関数のシンボルを定義します。- 関数を定義します。
diff()メソッドで導関数を計算します。計算する関数と導関数を計算するシンボルを指定します(これは絶対導関数ですが、xとy変数を持つ関数の場合は部分導関数も実行できます)。
テストしてみると、結果が2〜3秒で出力されることがわかります。したがって、非常に高速です。
特徴3:積分の計算
SymPyが導関数を計算できるなら、積分も計算できます。以下のように行いましょう:
from sympy import symbols, integrate, sin# シンボルを定義するx = symbols('x')# 積分を計算するintegral = integrate(sin(x), x)# 積分を出力するprint(integral)>>>-cos(x)したがって、ここでは integrate() メソッドを使用し、積分する関数と積分変数を指定します。
もっと簡単になりませんか?!
3. Xarray
Xarrayの紹介
Xarrayは、NumPyの機能と機能を拡張し、ラベル付きの配列とデータセットで作業できるようにするPythonのライブラリです。
実際には、彼らのウェブサイトで次のように述べています:
Xarrayは、Pythonでのラベル付きの多次元配列での作業をシンプルで効率的かつ楽しくします!
そしてまた:
Xarrayは、NumPyのような多次元配列の上に次元、座標、属性の形でラベルを導入し、より直感的で簡潔でエラーの少ない開発者体験を可能にします。
言い換えると、NumPy配列の機能を拡張し、配列の次元にラベルまたは座標を追加します。これらのラベルはメタデータを提供し、多次元データのより高度な解析と操作を可能にします。
例えば、NumPyでは、配列は整数ベースのインデックスを使用してアクセスされます。
一方、Xarrayでは、各次元に関連付けられたラベルを持つことができるため、意味のある名前に基づいてデータを理解し、操作することが容易になります。
例えば、Xarrayではarr[0, 1, 2]の代わりにarr.sel(x=0, y=1, z=2)を使用することができます。ここでx、y、zは次元のラベルです。
これにより、コードがより読みやすくなります!
それでは、Xarrayのいくつかの機能を見てみましょう。
Xarrayのいくつかの機能
通常通り、以下のようにインストールします:
$ pip install xarray機能1:ラベル付き座標での作業
温度に関連するデータを作成し、緯度や経度のような座標でラベル付けしたい場合を考えてみましょう。以下のように行うことができます:
import xarray as xrimport numpy as np# 温度データの作成temperature = np.random.rand(100, 100) * 20 + 10# 緯度と経度の座標配列の作成latitudes = np.linspace(-90, 90, 100)longitudes = np.linspace(-180, 180, 100)# ラベル付き座標を持つXarrayデータ配列の作成da = xr.DataArray( temperature, dims=['latitude', 'longitude'], coords={'latitude': latitudes, 'longitude': longitudes})# ラベル付き座標を使用してデータにアクセスsubset = da.sel(latitude=slice(-45, 45), longitude=slice(-90, 0))そして、それらを出力すると:
# データの出力print(subset)>>><xarray.DataArray (latitude: 50, longitude: 25)>array([[13.45064786, 29.15218061, 14.77363206, ..., 12.00262833, 16.42712411, 15.61353963], [23.47498117, 20.25554247, 14.44056286, ..., 19.04096482, 15.60398491, 24.69535367], [25.48971105, 20.64944534, 21.2263141 , ..., 25.80933737, 16.72629302, 29.48307134], ..., [10.19615833, 17.106716 , 10.79594252, ..., 29.6897709 , 20.68549602, 29.4015482 ], [26.54253304, 14.21939699, 11.085207 , ..., 15.56702191, 19.64285595, 18.03809074], [26.50676351, 15.21217526, 23.63645069, ..., 17.22512125, 13.96942377, 13.93766583]])Coordinates: * latitude (latitude) float64 -44.55 -42.73 -40.91 ... 40.91 42.73 44.55 * longitude (longitude) float64 -89.09 -85.45 -81.82 ... -9.091 -5.455 -1.818以上のように、以下のステップで処理を行っています:
- 温度値をNumPy配列として作成しました。
- 緯度と経度の値をNumPy配列として定義しました。
- すべてのデータをラベル付き座標を持つXarray配列に
DataArray()メソッドを使用して保存しました。 sel()メソッドを使用して、サブセットに使用する緯度と経度の一部を選択しました。
結果も読みやすくなっており、ラベル付けは多くの場合に非常に役立ちます。
機能2:欠損データの扱い
年間の気温に関連するデータを収集しているとします。配列内にいくつかのヌル値があるかどうかを知りたいです。以下に、その方法を示します:
import xarray as xrimport numpy as npimport pandas as pd# ヌル値を含む気温データを作成temperature = np.random.rand(365, 50, 50) * 20 + 10temperature[0:10, :, :] = np.nan # 最初の10日をヌル値に設定# 時間、緯度、経度の座標配列を作成times = pd.date_range('2023-01-01', periods=365, freq='D')latitudes = np.linspace(-90, 90, 50)longitudes = np.linspace(-180, 180, 50)# ヌル値を含むXarrayデータ配列を作成da = xr.DataArray( temperature, dims=['time', 'latitude', 'longitude'], coords={'time': times, 'latitude': latitudes, 'longitude': longitudes})# 時間次元でのヌル値の数をカウントmissing_count = da.isnull().sum(dim='time')# ヌル値を出力print(missing_count)>>><xarray.DataArray (latitude: 50, longitude: 50)>array([[10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], ..., [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10]])Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0これにより、10個のヌル値があることが分かります。
また、コードを注意深く見ると、isnull.sum()のようにPandasのメソッドをXarrayに適用できることがわかります。この場合、ヌル値の総数を数えることができます。
FEATURE ONE: 多次元データの処理と分析
配列にラベルを付けることができる場合、多次元データの処理と分析を行う誘惑は高いです。では、試してみましょう。
例えば、特定の緯度と経度に関連する気温データをまだ収集しているとします。
平均気温、最高気温、中央値気温を計算したい場合、以下のように行うことができます:
import xarray as xrimport numpy as npimport pandas as pd# 合成気温データを作成temperature = np.random.rand(365, 50, 50) * 20 + 10# 時間、緯度、経度の座標配列を作成times = pd.date_range('2023-01-01', periods=365, freq='D')latitudes = np.linspace(-90, 90, 50)longitudes = np.linspace(-180, 180, 50)# ヌル値を含むXarrayデータセットを作成ds = xr.Dataset( { 'temperature': (['time', 'latitude', 'longitude'], temperature), }, coords={ 'time': times, 'latitude': latitudes, 'longitude': longitudes, })# 気温データに対して統計分析を実行mean_temperature = ds['temperature'].mean(dim='time')max_temperature = ds['temperature'].max(dim='time')min_temperature = ds['temperature'].min(dim='time')# 値を出力 print(f"平均気温:\n {mean_temperature}\n")print(f"最高気温:\n {max_temperature}\n")print(f"最低気温:\n {min_temperature}\n")>>>平均気温: <xarray.DataArray 'temperature' (latitude: 50, longitude: 50)>array([[19.99931701, 20.36395016, 20.04110699, ..., 19.98811842, 20.08895803, 19.86064693], [19.84016491, 19.87077812, 20.27445405, ..., 19.8071972 , 19.62665953, 19.58231185], [19.63911165, 19.62051976, 19.61247548, ..., 19.85043831, 20.13086891, 19.80267099], ..., [20.18590514, 20.05931149, 20.17133483, ..., 20.52858247, 19.83882433, 20.66808513], [19.56455575, 19.90091128, 20.32566232, ..., 19.88689221, 19.78811145, 19.91205212], [19.82268297, 20.14242279, 19.60842148, ..., 19.68290006, 20.00327294, 19.68955107]])Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0最高気温: <xarray.DataArray 'temperature' (latitude: 50, longitude: 50)>array([[29.98465531, 29.97609171, 29.96821276, ..., 29.86639343, 29.95069558, 29.98807808], [29.91802049, 29.92870312, 29.87625447, ..., 29.92519055, 29.9964299 , 29.99792388], [29.96647016, 29.7934891 , 29.89731136, ..., 29.99174546, 29.97267052, 29.96058079], ..., [29.91699117, 29.98920555, 29.83798369, ..., 29.90271746, 29.93747041, 29.97244906], [29.99171911, 29.99051943, 29.92706773, ..., 29.90578739, 29.99433847, 29.94506567], [29.99438621, 29.98798699, 29.97664488, ..., 29.98669576, 29.91296382, 29.93100249]])Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0最低気温: <xarray.DataArray 'temperature' (latitude: 50, longitude: 50)>array([[10.0326431 , 10.07666029, 10.02795524, ..., 10.17215336, 10.00264909, 10.05387097], [10.00355858, 10.00610942, 10.02567816, ..., 10.29100316, 10.00861792, 10.16955806], [10.01636216, 10.02856619, 10.00389027, ...,
そして、望んだ結果を明確に読み取れる方法で得ることができました。
そしてまた、以前と同様に、温度の最大値、最小値、および平均値を計算するために、Pandasの関数を配列に適用しました。
結論
この記事では、科学的な計算と処理のための3つのライブラリを紹介しました。
SymPyは他のツールやソフトウェアの代わりになり得るものであり、Pythonコードを使用して数学的な計算を行うことができます。DaskとXarrayは他のライブラリの機能を拡張し、データ分析と操作について他のよく知られているPythonライブラリで困難な状況で役立ちます。
無料のPython EBOOK:
Pythonデータサイエンスを学び始めましたが、苦労していますか? ニュースレターに登録し、無料のebookを入手してください。これにより、Pythonデータサイエンスを実践的な経験を通じて学ぶための適切な学習パスが得られます。
このストーリーを楽しんだら、私の紹介リンクを通じてVoAGIメンバーになってください:追加料金なしで私には小さな手数料が発生します:
私の紹介リンクでVoAGIに参加する - Federico Trotta
VoAGIメンバーとして、あなたの会費の一部はあなたが読んだライターに支払われ、すべてのストーリーに完全アクセスできます...
federicotrotta.medium.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
