「フィーチャー/トレーニング/推論パイプラインによってバッチとMLシステムを統一する」
バッチ処理とMLシステムを一元化するには、フィーチャー/トレーニング/推論パイプラインを活用しよう
スポンサー付きコンテンツ
Jim Dowling、共同創設者兼CEO、Hopsworks
導入
この記事では、バッチとリアルタイムの機械学習(ML)システムのための統一的なアーキテクチャパターンを紹介します。私たちはそれをFTI(フィーチャー、トレーニング、推論)パイプラインアーキテクチャと呼んでいます。FTIパイプラインは、モノリシックなMLパイプラインを3つの独立したパイプラインに分割し、それぞれのパイプラインには明確に定義された入力と出力があります。各パイプラインは個別に開発、テスト、運用できます。FTIパイプラインアーキテクチャの進化の歴史的な視点については、完全なMLOpsの詳細なメンタルマップ記事をご覧ください。
近年、機械学習オペレーション(MLOps)は、DevOps原則に触発された開発プロセスとして、自動化されたテスト、MLアセットのバージョニング、運用監視を導入し、MLシステムの段階的な開発と展開を可能にするために重要な位置を占めています。しかし、既存のMLOpsのアプローチはしばしば複雑で圧倒的な状況を示し、多くのチームがモデルの開発から本番環境への道筋をたどるのに苦労しています。この記事では、FTIパイプラインの概念を通じてMLシステムの構築に新しい視点を提案します。FTIアーキテクチャは、数多くの開発者が簡単に頑丈なMLシステムを作成し、認知負荷を減らし、チーム間の協力を促進することができました。FTIパイプラインの基本原則について掘り下げ、バッチおよびリアルタイムのMLシステムへの適用を探ります。
- 「金融分野における生成型AI:FinGPT、BloombergGPT そしてその先へ」
- デジタルCXチャンネルの調和:現代の組織におけるチャットボットとChatGPTの四つの四分位相互作用モデル
- 「Pythonをマスターするための無料の5冊の本」
フィーチャー/トレーニング/推論パイプラインとしてのMLシステムの統一的アーキテクチャ
FTIアプローチによるこのアーキテクチャパターンは、数百のMLシステムの構築に使用されています。パターンは次のようになります- MLシステムは、3つの独立して開発および運用されるMLパイプラインで構成されます:
- フィーチャーパイプラインは、生データを取り込み特徴(およびラベル)に変換する
- トレーニングパイプラインは、特徴(およびラベル)を入力として受け取り、訓練されたモデルを出力します
- 推論パイプラインは、新しいフィーチャーデータと訓練されたモデルを入力として受け取り、予測を行います。
このFTIでは、単一のMLパイプラインはありません。MLパイプラインがどのような機能を持つかについての混乱(特徴エンジニアリングとモデルのトレーニングを行うのか、推論も行うのか、それともそれらのいずれかだけか)はなくなります。FTIアーキテクチャは、バッチMLシステムとリアルタイムMLシステムの両方に適用されます。

フィーチャーパイプラインはバッチプログラムまたはストリーミングプログラムであることがあります。トレーニングパイプラインは、XGBoostモデルからパラメータ効率的に微調整された(PEFT)大規模言語モデル(LLM)まで、さまざまなものを出力する場合があります。最後に、推論パイプラインは、バッチの予測を生成するバッチプログラムであるか、クライアントからのリクエストを受け取りリアルタイムで予測を返すオンラインサービスである場合があります。
FTIパイプラインの主な利点の1つは、それがオープンなアーキテクチャであることです。Python、Java、SQLを使用することができます。大量のデータに対してフィーチャーエンジニアリングを行う必要がある場合は、SparkやDBT、Beamを使用できます。トレーニングは通常、いくつかのMLフレームワークを使用してPythonで行われ、バッチの推論は、データ量に応じてPythonまたはSparkで行われる場合があります。ただし、オンライン推論パイプラインは、通常、モデルがPythonでトレーニングされるため、ほぼ常にPythonで実装されます。
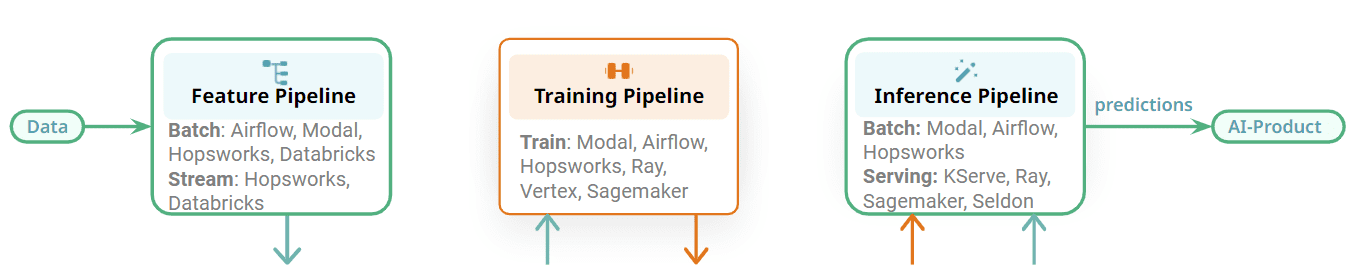
FTIパイプラインはモジュラーであり、異なるステージ間には明確なインターフェースがあります。各FTIパイプラインは個別に運用可能です。 モノリシックなMLパイプラインに比べ、異なるチームが各パイプラインの開発と運用を担当することができます。これにより、たとえば特徴パイプラインには1つのオーケストレータを使用し、バッチ推論パイプラインには別のオーケストレータを使用するといった、オーケストレーションのために異なるチームが異なるオーケストレータを使用することができます。あるいは、バッチMLシステムの3つの異なるFTIパイプラインには同じオーケストレータを使用することもできます。MLシステムで使用できるオーケストレータの例としては、Airflowのような汎用性の高い機能豊富なオーケストレータ、Modalのような軽量オーケストレータ、または特徴プラットフォームで提供される管理されたオーケストレータなどがあります。
一部のFTIパイプラインにはオーケストレーションの必要はありません。トレーニングパイプラインは新しいモデルが必要なときにオンデマンドで実行できます。ストリーミング機能パイプラインとオンライン推論パイプラインはサービスとして連続的に実行され、オーケストレーションは必要ありません。Flink、Spark Streaming、Beamは、Kubernetes、Databricks、Hopsworksなどのプラットフォーム上でサービスとして実行されます。オンライン推論パイプラインは、KServe(Hopsworks)、Seldon、Sagemaker、Rayなどのモデルサービングプラットフォームにそのモデルとともに展開されます。ここからの主なポイントは、MLパイプラインが明確なインターフェースを持つモジュール化されており、FTIパイプラインを実行するための最適な技術を選択できることです。
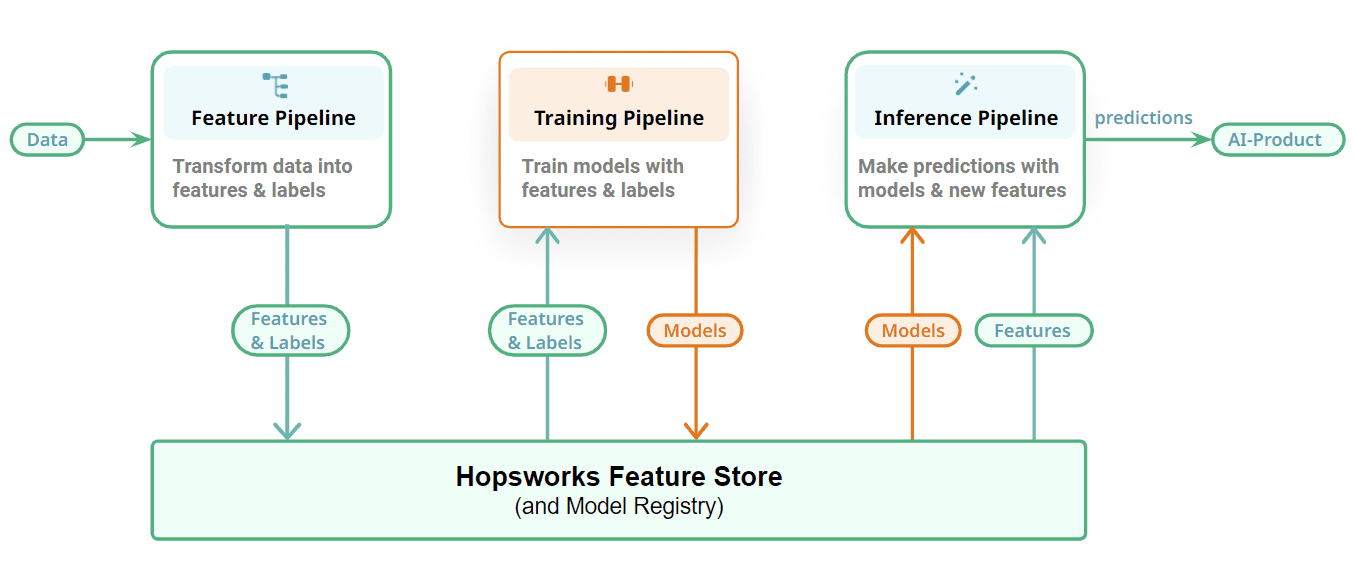
最後に、MLアーティファクト(特徴、トレーニング/テストデータ、モデル)を格納するためのステートフルレイヤーでFTIパイプラインを接続する方法を示します。特徴パイプラインは、特徴をデータソースから読み取り、計算して特徴ストアに格納します。任意の特徴パイプラインに対して回答する必要があるいくつかの質問には以下があります:
- 特徴パイプラインはバッチまたはストリーミングですか?
- 特徴インジェスションはインクリメンタルまたはフルロード操作ですか?
- 特徴パイプラインを実装するためにどのフレームワーク/言語が使用されますか?
- 特徴データのインジェスション前にデータ検証が実行されますか?
- 特徴パイプラインのスケジュールはどのように設定されますか?
- 一部の特徴はすでに上流システム(たとえばデータウェアハウス)によって計算されている場合、そのデータの重複を防ぐ方法と、トレーニングまたはバッチ推論データを作成する場合にのみその特徴を読み取る方法は何ですか?
トレーニングパイプラインにおいては、ダブルクリックで確認できる以下の詳細があります:
- トレーニングパイプラインを実装するためにどのフレームワーク/言語が使用されますか?
- 実験トラッキングプラットフォームは何を使用していますか?
- トレーニングパイプラインはスケジュール実行されますか(もしそうなら、どのオーケストレータを使用しますか)、それともモデルのパフォーマンス低下に応じてオンデマンドで実行されますか?
- トレーニングにはGPUが必要ですか?必要な場合、それらはどのようにトレーニングパイプラインに割り当てられますか?
- どの特徴にどのような特徴エンコーディング/スケーリングが行われますか?(通常、特徴データは特徴ストアに非エンコードで保存され、EDA(探索的データ解析)に使用されます。エンコーディング/スケーリングはトレーニングと推論パイプラインで一貫して行われます)。特徴エンコーディングの例としては、scikit-learnパイプラインまたは< a href=”/?s=feature views”>特徴ビュー(Hopsworks)での宣言的な変換があります。
- どのようなモデル評価および検証プロセスが使用されますか?
- どのモデルレジストリがトレーニング済みモデルを保存するために使用されていますか?
推論パイプラインでは、アプリケーションがAIを活用する方法に応じて多様なパイプラインがあります。推論パイプラインでは、ダブルクリックで確認できる以下の詳細があります:
- 予測コンシューマーはダッシュボード、オンラインアプリケーションなどですか?そして、予測をどのように利用しますか?
- バッチまたはオンライン推論パイプラインですか?
- どのような特徴エンコーディング/スケーリングがどの特徴に対して実行されますか?
- バッチ推論パイプラインの場合、どのフレームワーク/言語が使用されますか?スケジュール実行するためにどのオーケストレータが使用されますか?予測結果を消費するためにどのシンクが使用されますか?
- オンライン推論パイプラインの場合、デプロイされたモデルをホストするためにどのモデルサーバーが使用されますか?オンライン推論パイプラインは予測クラスとして実装されるのか、別のトランスフォーマーステップとして実装されますか?推論にはGPUが必要ですか?予測リクエストへの応答にかかる時間についてSLA(サービスレベル契約)がありますか?
MLOpsの原則
既存の教義は、MLOpsが機械学習(ML)システムの継続的統合(CI)、継続的デリバリー(CD)、および継続的トレーニング(CT)の自動化に関するものであると言われています。しかし、それは多くの開発者にとって抽象的すぎます。MLOpsは、時間とともに進化するML対応製品の継続的開発について実際にはです。利用可能な入力データ(特徴)は時とともに変わり、予測しようとしている対象も時とともに変わります。ソースコードを変更する必要があり、変更した場合にMLシステムが壊れたりパフォーマンスが低下したりしないようにしたいです。また、それらの変更を自動的に本番環境にデプロイする前に行われる変更の所要時間を短縮したいです。
ですので、私たちの視点から見ると、時間と共に安全に進化するMLシステムを実現するMLOpsのより簡潔な定義として、最低限、MLアーティファクトの自動化されたテスト、バージョニング、および監視が必要であるということです。MLOpsは、MLアーティファクトの自動化されたテスト、バージョニング、および監視に関するものです。
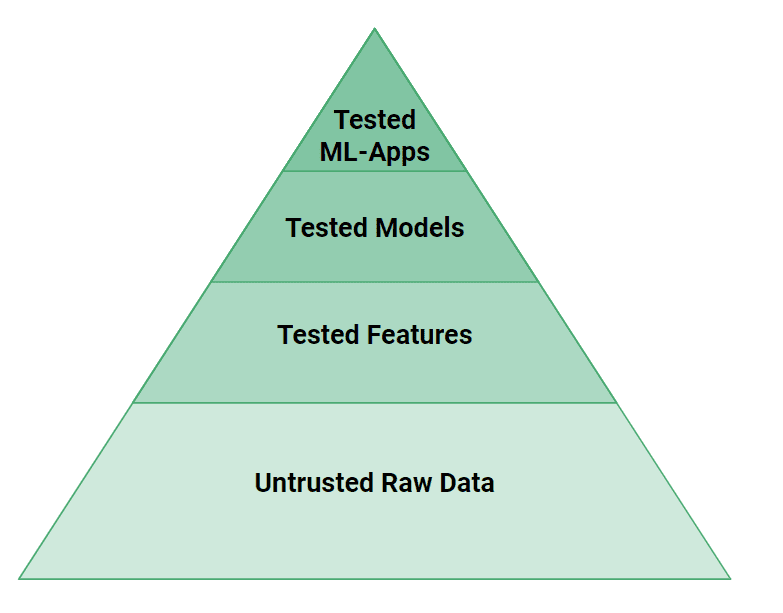
図4では、MLシステムでは従来のソフトウェアシステムよりも多くのテストレベルが必要とされることがわかります。データやコードの細かなバグがMLモデルが間違った予測を行う原因になりやすいです。テストの観点から言えば、ウェブアプリケーションがプロペラ駆動の飛行機であるなら、MLシステムはジェットエンジンです。MLシステムは安全性を確保するために、テストと検証に対して大きなエンジニアリング努力を必要とします!大まかな観点から言えば、MLシステムのソースコードとデータの両方をテストする必要があります。フィーチャーパイプラインで作成された特徴は、ユニットテストでそのロジックをテストし、データの検証テストで入力データをチェックする必要があります(例:Great Expectations)。モデルはパフォーマンスだけでなく既知の脆弱なユーザーグループへの偏りのないこともテストする必要があります。最後にピラミッドの頂点で、MLシステムは新しいモデルを使用する前にA/Bテストを行う必要があります。
最後に、MLアーティファクトにバージョンを付ける必要があります。これによって、MLシステムのオペレーターが展開されたモデルのバージョンを安全に更新およびロールバックできるようになります。モデルは予測を行うために特徴を必要とするため、モデルバージョンは特徴バージョンに関連付けられ、モデルと特徴は同期してアップグレード/ダウングレードされる必要があります。幸いにも、モデルのアップグレード/ダウングレードを簡単に行うためには、Google SREのローテーションで1年間の経験は必要ありません – バージョン管理されたMLアーティファクトのプラットフォームサポートにより、これは容易なMLシステムのメンテナンス操作となるでしょう。
サンプルMLシステム
以下は、FTIアーキテクチャ上に構築されたいくつかのオープンソースのMLシステムのサンプルです。これらは主に実践者や学生によって作成されました。
バッチMLシステム
- 電力需要予測(452のGitHubスター)
- NBAゲーム予測(152のGitHubスター)
- プレミアリーグのサッカースコア予測(101のGitHubスター)
- 離脱予測(113のGitHubスター)
リアルタイムMLシステム
- オンラインクレジットカード詐欺(113のGitHubスター)
- 仮想通貨価格予測(65のGitHubスター)
- ローン申請承認(113のGitHubスター)
まとめ
本記事では、MLOpsのためのFTIパイプラインアーキテクチャを紹介しました。このアーキテクチャにより、多くの開発者が効率的にMLシステムを作成し維持することが可能となりました。私たちの経験に基づくと、このアーキテクチャは従来のMLOpsアプローチと比較して、MLシステムの設計や説明に関連する認知負荷を大幅に軽減します。企業環境では、明確なインターフェースを確立し、チーム間のコミュニケーションを向上させ、高品質なMLシステムの開発を促進することで、チーム間のコラボレーションを促進します。総合的な複雑さを簡素化する一方で、個々のパイプラインの詳細な探索も可能とします。FTIパイプラインアーキテクチャの目標は、チームワークの向上とより迅速なモデル展開を容易にし、AIによる社会的変革を迅速化することです。
FTIパイプラインアーキテクチャを構成する基本原則と要素については、私たちの完全なMLOpsのための詳細なメンタルマップを読んでください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






