「教師あり学習の理論と概要の理解」
Understanding the theory and overview of supervised learning

教師あり学習は、コンピュータが入力と正しい出力の両方を含むラベル付きデータセットから学習する機械学習のサブカテゴリです。入力(x)と出力(y)の関係を見つけるためのマッピング関数を見つけようとします。これは、異なる動物を認識する方法を自分の弟や妹に教えるのと同じです。いくつかの写真(x)を見せて、それぞれの動物の名前(y)を教えます。ある時点で、彼らは違いを学び、新しい写真を正しく認識できるようになります。これが教師あり学習の基本的な直感です。進む前に、その仕組みをより詳しく見てみましょう。
教師あり学習はどのように機能しますか?
- このAI論文は、自律言語エージェントのためのオープンソースのPythonフレームワークである「Agents」を紹介しています
- 「vLLMに会ってください:高速LLM推論とサービスのためのオープンソース機械学習ライブラリ」
- 「Würstchenをご紹介します:高速かつ効率的な拡散モデルで、テキスト条件付きコンポーネントは画像の高圧縮潜在空間で動作します」
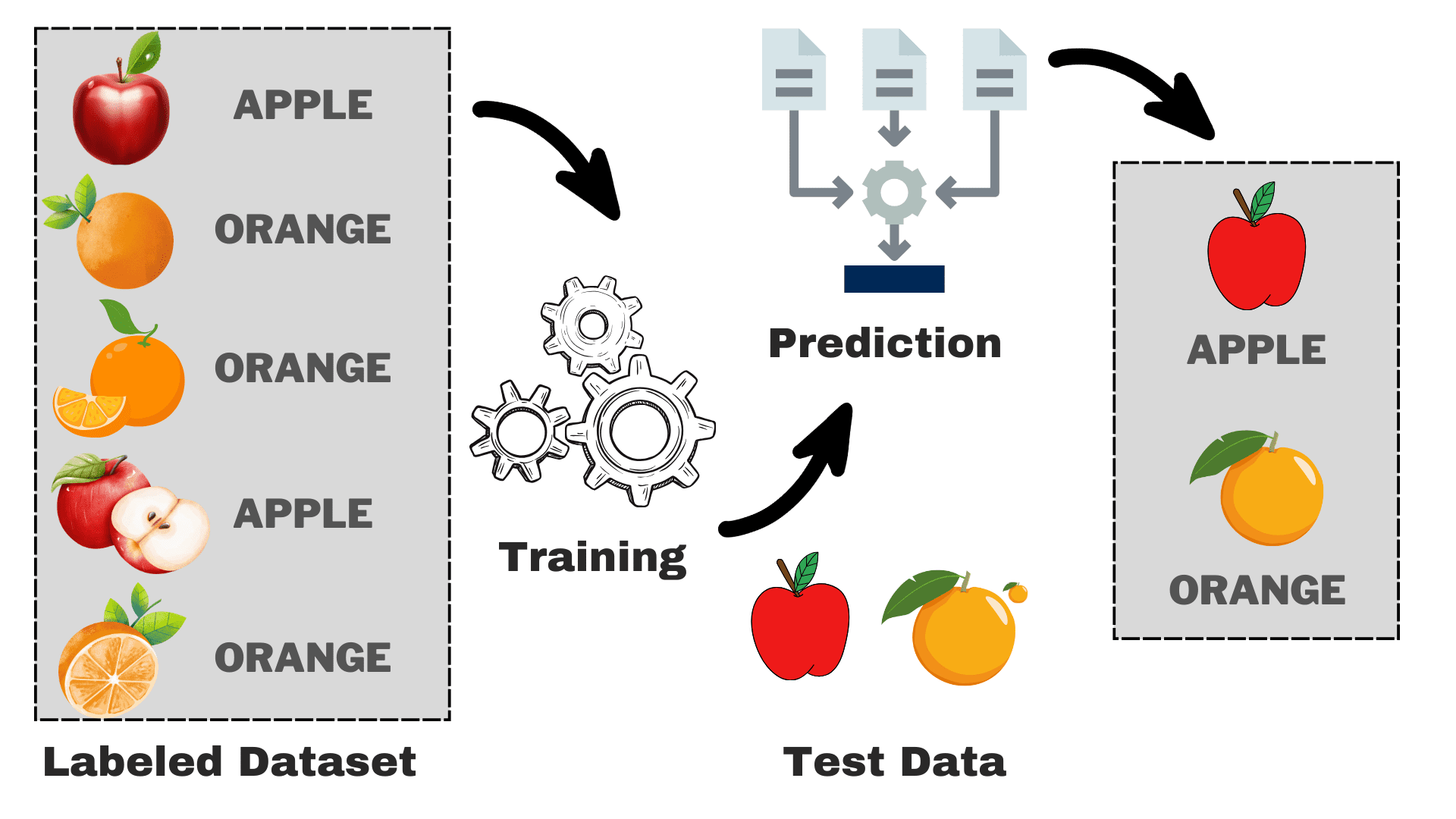
いくつかの特徴に基づいてリンゴとオレンジを区別するモデルを構築したいとします。このプロセスを次のタスクに分解できます:
- データ収集:リンゴとオレンジの写真を含むデータセットを集め、各画像を「リンゴ」または「オレンジ」とラベル付けします。
- モデルの選択:タスクに適した正しい教師あり機械学習アルゴリズム、通常は正しい分類器を選択する必要があります。これは、より良く見えるための適切なメガネを選ぶことと同じです。
- モデルの訓練:ラベル付きのリンゴとオレンジの画像をアルゴリズムに与えます。アルゴリズムはこれらの画像を見て、リンゴとオレンジの色、形状、サイズなどの違いを認識するように学習します。
- 評価とテスト:モデルが正しく機能しているかどうかを確認するために、いくつかの未知の画像を与えて予測と実際の結果を比較します。
教師あり学習の種類
教師あり学習は主に2つのタイプに分けることができます:
分類
分類タスクでは、データポイントを離散的なクラスのセットから特定のカテゴリに割り当てることが主な目標です。 “はい”または “いいえ”、 “スパム”または “スパムではない”、 “受け入れ”または “拒否”などの2つの可能な結果がある場合、バイナリ分類と呼ばれます。しかし、2つ以上のカテゴリやクラスが関与する場合(例:成績に基づいて学生を評価する場合、A、B、C、D、Fなど)、これは多クラス分類の例となります。
回帰
回帰問題では、連続的な数値値を予測しようとします。たとえば、過去の授業の成績に基づいて最終試験の点数を予測することに興味があるかもしれません。予測されるスコアは、通常、0から100の特定の範囲内の任意の値を取ることができます。
人気のある教師あり学習アルゴリズムの概要
これで、全体的なプロセスの基本的な理解ができました。人気のある教師あり機械学習アルゴリズム、その使用法、および動作方法について探っていきます:
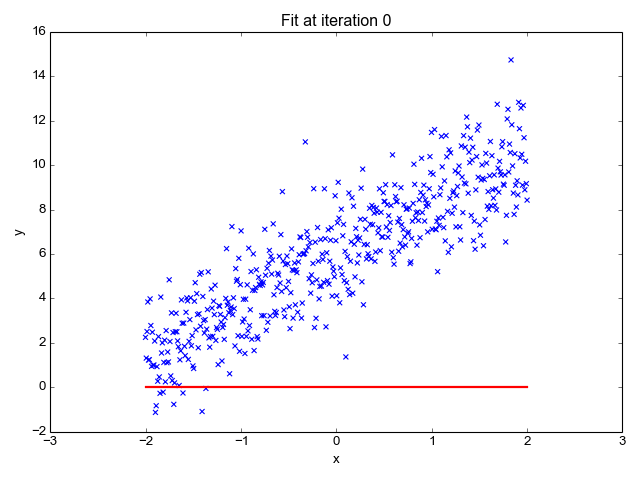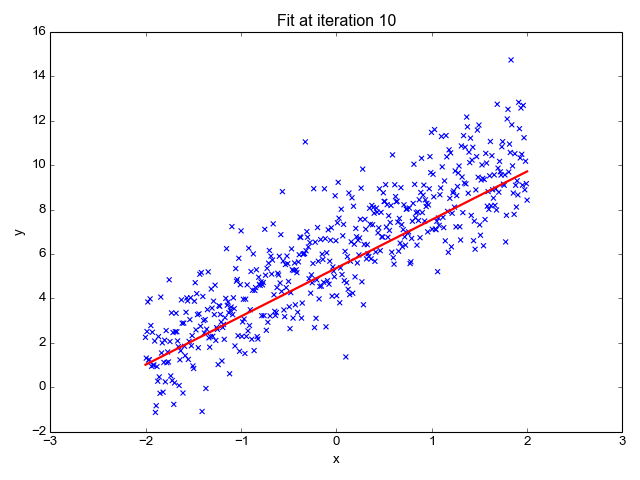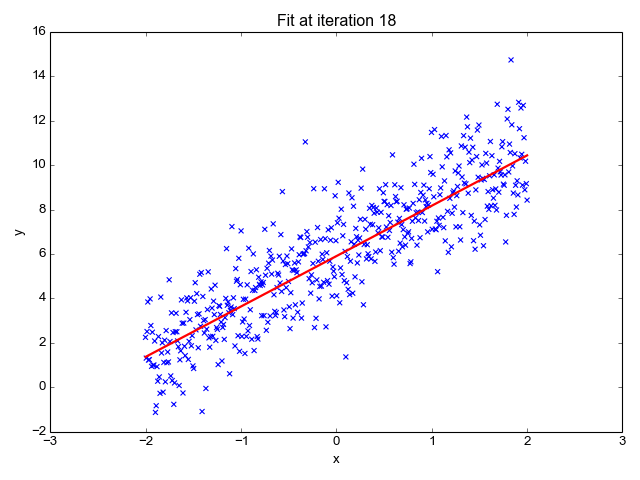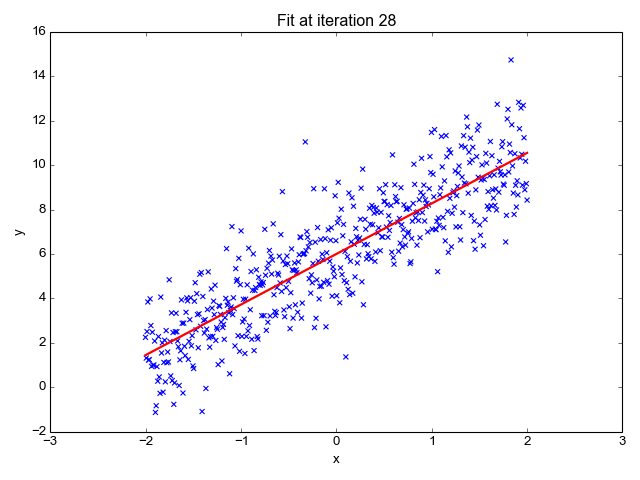
1. 線形回帰
その名前からもわかるように、株価の予測、気温の予測、病気の進行の可能性の推定など、回帰タスクに使用されます。ラベル(独立変数)のセットを使用して、ターゲット(従属変数)を予測しようとします。入力特徴とラベルの間に線形の関係があると仮定します。中心的なアイデアは、実際の値と予測値の間の誤差を最小化することによって、データポイントの最適な適合直線を予測することです。この直線は次の式で表されます:
ここで、
- Y 予測される出力。
- X = 複数の線形回帰の場合の入力特徴または特徴行列
- b0 = 切片(直線がY軸と交差する場所)。
- b1 = 直線の傾きまたは係数。
それは直線の傾き(重み)とその切片(バイアス)を推定します。この直線はさらに予測を行うために使用されます。これは基準線を開発するための最も単純で有用なモデルですが、外れ値に非常に敏感であり、直線の位置に影響を与える可能性があります。
2. ロジスティック回帰
名前に回帰があるものの、基本的には2値分類問題に使用されます。これは、正の結果(従属変数)の確率を予測し、その範囲は0から1です。しきい値(通常は0.5)を設定することで、データポイントを分類します。しきい値よりも確率が高い場合は、正のクラスに属し、それ以外の場合は逆です。ロジスティック回帰は、以下で指定される入力特徴の線形結合にシグモイド関数を適用して、この確率を計算します:
ここで、
- P(Y=1) = 正のクラスに属するデータポイントの確率
- X1 ,… ,Xn = 入力特徴
- b0,.…,bn = アルゴリズムが学習中に学習する入力の重み
このシグモイド関数は、どのデータポイントも0から1の範囲内の確率スコアに変換するS字カーブの形をしています。以下のグラフを参照して、より良い理解をしてください。 
1に近い値は、モデルの予測に対する高い信頼度を示します。線形回帰と同様に、単純さで知られていますが、元のアルゴリズムを変更せずに多クラス分類を実行することはできません。
3. 決定木
上記の2つのアルゴリズムとは異なり、決定木は分類および回帰の両方のタスクに使用することができます。それはフローチャートのような階層的な構造を持っています。各ノードでは、いくつかの特徴値に基づいてパスについての決定が行われます。最後のノードに到達するまで、プロセスは続き、最終的な決定を示します。以下は、知っておく必要のあるいくつかの基本用語です:
- ルートノード:データセット全体を含むトップのノードをルートノードと呼びます。次に、データセットを2つ以上のサブツリーに分割するための最適な特徴をいくつかのアルゴリズムを使用して選択します。
- 内部ノード:各内部ノードは特定の特徴と、データポイントの次の可能な方向を決定するための決定ルールを表します。
- 葉ノード:クラスラベルを表す終端ノードは葉ノードと呼ばれます。
回帰タスクでは、連続的な数値値を予測します。データセットのサイズが大きくなると、過学習につながるノイズを捉えます。これは決定木の剪定によって処理することができます。意思決定の精度を著しく向上させない枝を削除します。このようにすることで、最も重要な要素に焦点を当て、詳細に迷うことなく木を維持するのに役立ちます。 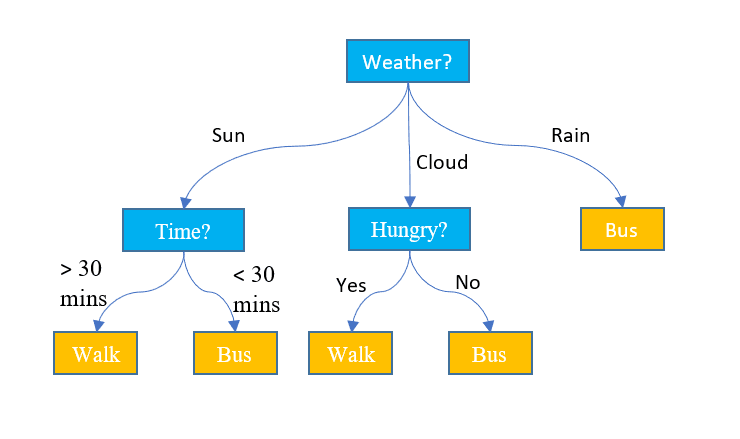
4. ランダムフォレスト
ランダムフォレストは、分類および回帰のタスクの両方に使用することができます。最終的な予測を行うために一緒に動作する複数の決定木のグループです。それは、共同意思決定を行う専門家の委員会と考えることができます。以下はその動作方法です:
- データサンプリング:一度にデータセット全体を取る代わりに、ブートストラップまたはバギングと呼ばれるプロセスを介してランダムなサンプルを取得します。
- 特徴選択:ランダムフォレストの各決定木では、完全な特徴セットではなく、ランダムな特徴のサブセットのみが決定に考慮されます。
- 投票:分類の場合、ランダムフォレストの各決定木は投票を行い、最も多くの投票を得たクラスが選択されます。回帰の場合、すべての木から得られた値の平均を求めます。
個々の決定木によって引き起こされる過学習の効果を減らす一方、計算コストが高いです。文献では頻繁にランダムフォレストがアンサンブル学習手法であると言われており、これは複数のモデルを組み合わせて全体の性能を向上させることを意味します。
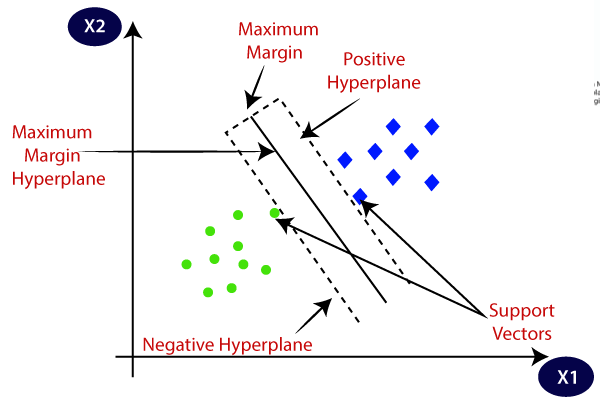
5. サポートベクターマシン(SVM)
主に分類問題に使用されますが、回帰タスクも処理できます。統計的なアプローチを用いて、異なるクラスを区別するための最適なハイパープレーンを見つけようとします。これはロジスティック回帰の確率的なアプローチとは異なります。線形SVMは線形分離可能なデータに使用することができます。しかし、ほとんどの現実世界のデータは非線形であり、クラスを分離するためにカーネルトリックを使用します。これがどのように機能するかについて詳しく見ていきましょう:
- ハイパープレーンの選択:2クラス分類では、SVMはクラスを区別するための最適なハイパープレーン(2次元の直線)を見つけ、同時にマージンを最大化します。マージンとは、ハイパープレーンとハイパープレーンに最も近いデータポイントとの距離です。
- カーネルトリック:線形分離不可能なデータに対しては、カーネルトリックを使用して元のデータ空間を高次元空間にマップし、そこで線形に分離できるようにします。一般的なカーネルには、線形、多項式、放射基底関数(RBF)、シグモイドカーネルなどがあります。
- マージンの最大化: SVMはまた、マージンを最大化することでモデルの一般化を改善しようとします。
- 分類:モデルがトレーニングされたら、予測はハイパープレーンとの相対的な位置に基づいて行われます。
SVMにはCというパラメータもあり、マージンの最大化と分類エラーを最小限に抑えるというトレードオフを制御します。高次元および非線形データをうまく処理できるものの、適切なカーネルとハイパーパラメータの選択は思ったよりも簡単ではありません。
 Javatpointの画像
Javatpointの画像
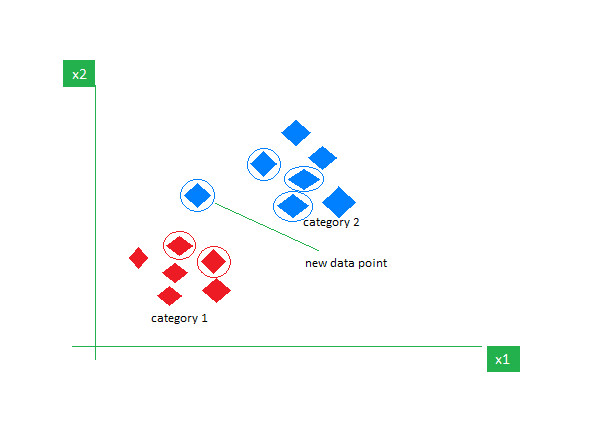
6. k最近傍法(k-NN)
k-NNは、主に分類タスクに使用される最も単純な教師あり学習アルゴリズムです。データについて何の仮定もせず、新しいデータポイントを既存のデータポイントとの類似性に基づいてカテゴリに割り当てます。トレーニングフェーズでは、データセット全体を参照点として保持します。次に、新しいデータポイントとすべての既存のポイントとの距離を距離メトリック(例:ユークリッド距離)を使用して計算します。これらの距離に基づいて、これらのデータポイントのk個の最近傍を特定します。次に、k個の最近傍内の各クラスの発生回数をカウントし、最も頻繁に現れるクラスを最終的な予測とします。
 GeeksforGeeksの画像
GeeksforGeeksの画像
kの適切な値の選択には試行錯誤が必要です。ノイズの多いデータには頑健ですが、高次元のデータセットには適しておらず、すべてのデータポイントからの距離の計算による高いコストがかかります。
まとめ
この記事を締めくくるにあたり、読者にはさらにアルゴリズムを探求し、それらをゼロから実装してみることをお勧めします。これにより、裏ではどのように動いているかの理解が深まります。はじめるのに役立つ追加のリソースは以下です:
- Machine Learning Algorithms – Second Editionのマスタリング
- Machine Learning Course – Javatpoint
- Machine Learning Specialization – Coursera
Kanwal Mehreenは、データサイエンスと医療へのAIの応用に強い関心を持つ、将来有望なソフトウェア開発者です。 KanwalはGoogle Generation Scholar 2022としてAPAC地域で選出されました。 Kanwalは、トレンディなトピックに関する記事を書くことで技術的な知識を共有することが大好きで、テック業界における女性の表現力向上に情熱を持っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AutoMLのジレンマ
- 「CodiumAIに会ってください:開発者のための究極のAIベースのテストアシスタント」
- スタビリティAIが安定したオーディオを導入:テキストプロンプトからオーディオクリップを生成できる新しい人工知能モデル
- 「リソース制約のあるアプリケーションにおいて、スパースなモバイルビジョンMoEsが密な対応物よりも効率的なビジョンTransformerの活用を解き放つ方法」
- 機械学習、イラストで解説:インクリメンタル学習
- 「SIEM-SOAR インテグレーションによる次世代の脅威ハンティング技術」
- 「NExT-GPTを紹介します:エンドツーエンドの汎用的な任意対任意のマルチモーダル大規模言語モデル(MM-LLM)」





